考虑线网结构的 LightGBM 轨道交通短时客流预测模型
2021-11-01徐圣安
韩 皓,徐圣安,赵 蒙
(上海海事大学 交通运输学院,上海 201306)
0 引言
综上分析,结合复杂网络理论对轨道交通网络开展结构分析[7-10],不仅能从宏观层面观察车站在整个轨道交通网络中的作用[11],也可进一步探索车站分布情况对客流的影响。通过分析轨道交通线网结构特性,定量描述车站在线网结构中的差异性,将线网结构特征纳入数据集中,并基于LightGBM[12]算法构建城市轨道交通短时客流预测模型。相比同为集成算法的XGBoost[13],LightGBM 算法不仅节约内存消耗,缩短训练时间,且拥有更高的模型精度,同时支持并行学习,在海量数据的处理上表现更为优异。因而,将LightGBM 算法应用于轨道交通客流回归预测,并结合特征工程,构造包含线网结构特征的数据集,优化模型精度,提高算法效率,为运营组织及分析掌握城市轨道交通客流活动分布提供更加准确的技术手段。
1 原始数据处理
原始数据来源于github 项目(https://github.com/ivechan/PVCGN),涵盖上海市轨道交通288 个车站进出站客流,时间跨度为2016 年7 月1 日至8 月31 日每天5 : 30 ~ 23 : 30,并以15 min 的粒度按时间顺序排列呈现,具体数据项为时间、车站号、进站客流量及出站客流量。
1.1 线网结构特征构建
车站客流量是车站所处区域的地理、人口、经济及其他属性的综合反映,基于这些属性构建特征存在以下难点:一是量化方式上存在困难;二是巨大的数据获取成本。因此,将车站在空间维度上的差异转换为对轨道交通线网结构的量化统计,引入复杂网络理论中的统计物理量及社团划分理论描绘车站之间的差异性。
1.1.1 节点统计指标
以车站为节点,以相邻车站间的可达路径为连边构建上海市城市轨道交通网络。将节点作为研究对象,通过复杂网络理论中的统计物理量展开分析,分别取以下统计指标。
(1)集聚系数。在二元关系C中,如果存在1C2,2C3,1C3,则称C为传递关系。在城市轨道交通网络中C可延展为以下定义:拥有同一相邻车站的2 个车站彼此相邻,该性质为网络的聚类性(Clustering)。定义节点i的聚类系数Ci如公式 ⑴ 所示。
对公共图书馆招聘信息中需求专业出现的频次进行统计,结果如图3所示。公共图书馆专业需求排前三位的是图情档、其他专业以及人文社科类,占比分别为 28.1%、23.8%、17.3%。 其他专业主要是传媒、会计以及外语等专业。统计分析显示,随着近年来公共图书馆在免费开放政策下业务范围的扩大,人文社科类和传媒类等专业与图情档专业形成竞争关系。对计算机学科的人才需求集中在省级以及沿海地区公共图书馆,县级以及偏远地区图书馆由于公共文化服务体系建设尚不完善、资金投入不足等原因对数字资源建设的关注力度较小,从而对计算机学科人才的需求较低。总之,公共图书馆对人才的专业需求呈多样化趋势。

(2)度。在无向网中,节点i的度ki是指节点i与其他节点之间存在的路径数,而延伸到城市轨道交通网络上,车站i的度ki表示车站i与相邻车站之间的路径数。
(3)流介数中心性。节点i的流介数中心性为网络中所有路径σst总数与经过该节点路径数σst(i)的比值,在城市轨道交通网络中可反映车站作为“桥梁”的重要程度,节点i的流介数中心性CB(i)如公式 ⑵ 所示。

根据上述分析可得,车站网络结构特征名及解释如表1 所示。

表1 车站网络结构特征名与解释Tab.1 Network structure features and explanations
1.1.2 线网模块划分
车站编号作为离散型分类变量,如果采用传统的独热编码处理,288 个车站将产生288 维度特征,特征维度过高会对数据集的结构产生较大的破坏,造成模型精度的下降。因而,为更好地挖掘车站在客流空间分布上的规律,除使用表1 中所提到的节点统计指标外,进一步引入Louvain 算法对线网划分模块,在尽可能减少新增特征维度的同时实现车站节点分类。
Louvain 算法是一种基于聚类法思想的模块划分算法,可以高效辨别大型网络的层次及社区结构,且划分精准度高,能够划分出内部联系紧密、外部联系稀疏的节点模块。
Louvain 算法以模块度(Modularity,记为Q)和模块度增量(Delta Modularity,记为ΔQ) 为主要参数对轨道交通网络进行划分,通过参数Q计算模块内部节点的紧密程度,模块度Q如公式⑶所示。
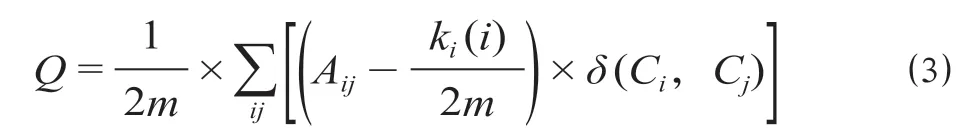
式中:m为网络中边的总数量;ki表示所有指向节点i的连边权重之和,kj同理;Aij表示节点i,j之间的连边权重;δ(Ci,Cj)为0-1 变量,用于判断节点i和节点j所在社区是否相同,相同为1,不同为0。
在将某一新节点划分至某社区后,重新计算模块度,模块度增量ΔQ如公式 ⑷ 所示。
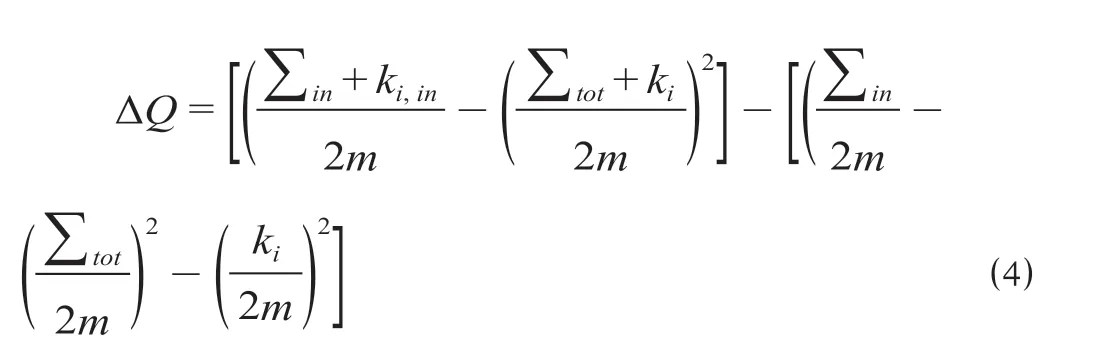
式中:in和tot分别代表节点所在模块边权重之和以及所有与模块内部连边权重之和;ki,in表示节点i加入到社区C时的权重和。以最大化模块度为目的,基于Louvain 算法将上海城市轨道交通网络划分为18 个模块,模块划分学习曲线如图1 所示,上海市轨道交通模块划分网络如图2 所示。
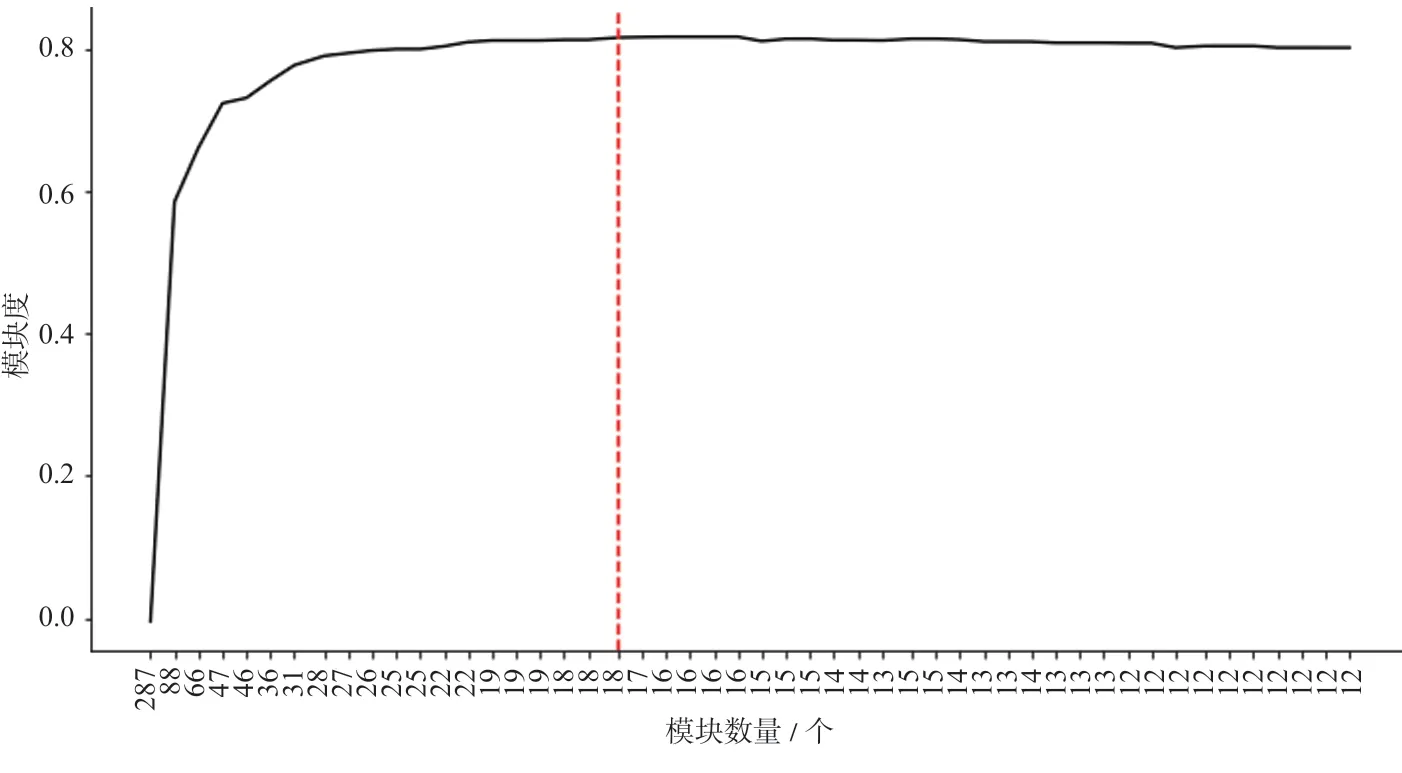
图1 模块划分学习曲线Fig.1 Learning curve of module partition
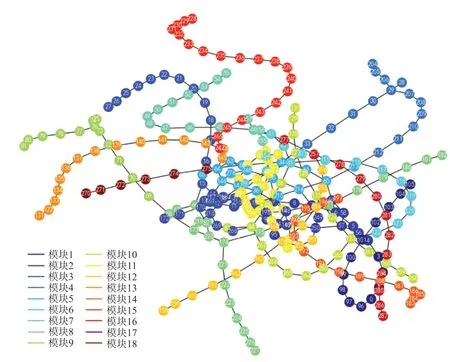
图2 上海市轨道交通模块划分网络Fig.2 Network of rail transit module partition in Shanghai
划分车站所属的网络模块后,采用独热编码处理,独热编码即采用N位状态寄存器对N个状态进行编码,每个状态都有独立的寄存器位,并且在任意时候只有一位有效。编码后的特征名以Community1~18表示,用于描述车站节点i在独热编码后的所属模块。
1.2 时间维度特征构建
根据地铁线路运营时间,按照原始数据时间粒度,统计进出站客流量。在时间维度抽取特征[14],将其分为小时(hour)、分钟(minute)。为进一步分析客流在时间上的相关性,经统计,0 号车站在2016 年7 月内进站客流(30 d)如图3 所示,0 号车站在2016 年7 月内出站客流(30 d)如图4 所示。
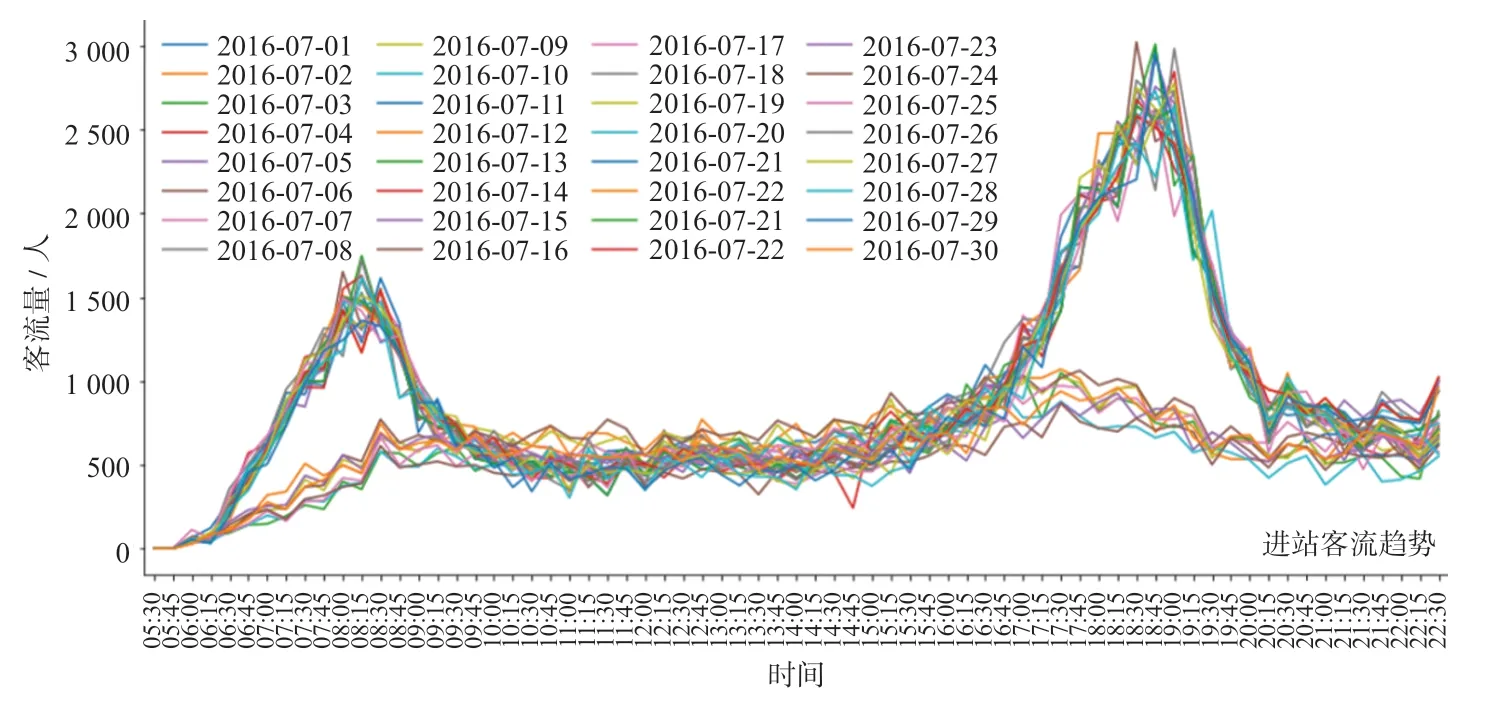
图3 0 号车站2016 年7 月内进站客流(30 d)Fig.3 Passenger inflow of No.0 station in July (30 d), 2016
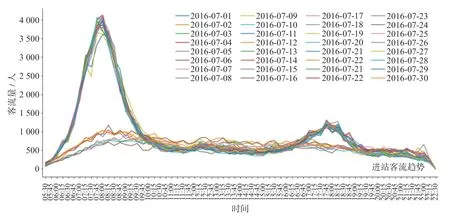
图4 0 号车站2016 年7 月内出站客流(30 d)Fig.4 Passenger outflow of No.0 station in July (30 d), 2016
通过计算皮尔逊相关矩阵,并绘制热力图可视化表示进出站客流在时间维度上的相关性。进站客流热力图如图5 所示,出站客流热力图如图6 所示。
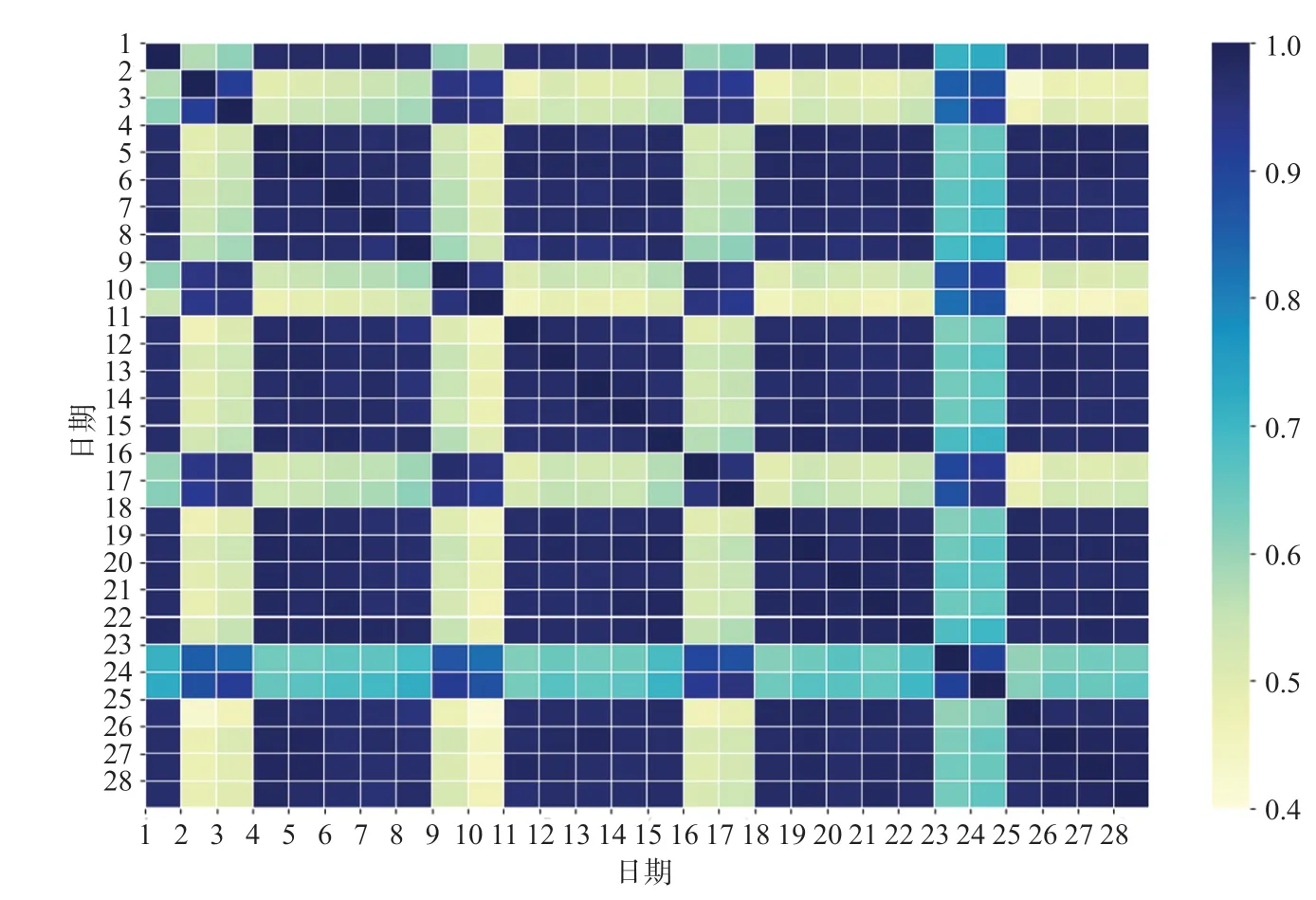
图5 进站客流热力图Fig.5 Heat map of passenger inflow
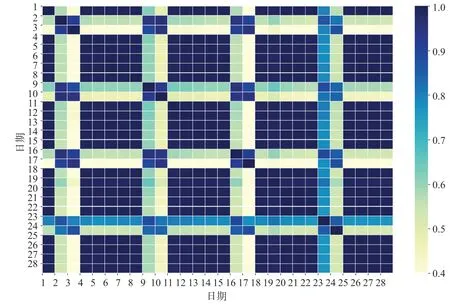
图6 出站客流热力图Fig.6 Heat map of passenger outflow
可视化结果表明,该车站进出站客流以7 d 为周期表现出强周期性,因而提取一周前同时段客流作为数据集特征,同时对哑变量“星期几”作独热编码处理。综上分析可知,时间维度抽取特征名与解释如表2 所示。
综上分析,对数据集进行构建。考虑上海地铁全线路平均运营起止时间,以及根据前述特征工程和原始数据集的数据属性,最终将时间拆分点设置为6 : 30 和22 : 30,其中以2016 年7 月8 日 至8 月30 日共计55 d 共1 010 800 个样本作为训练数据,以8 月31 日共18 720 个样本为测试数据。特征向量由线网特征和时间维度特征共35 维构成。其中线网特征共21 维,包括车站节点的“度”“流介数中心性”“集聚系数”3 维,“车站所属网络模块的独热编码”18 维;时间维度特征共14 维,包括“星期几”7 维,“小时”与“分钟”2 维,“前周同时段进出站”1维,“前15~60 min 进出站客流量”4 维。
2 基于LightGBM算法的轨道交通短时客流预测模型
2.1 LightGBM算法
LightGBM 是一个分布式boosting框架,因其训练速度快且性能优秀,被广泛应用于回归、分类等机器学习任务。将其应用于地铁客流量的建模与预测,其优点主要有3 方面。①高效的训练效率;②较低的内存消耗;③支持平行学习和GPU 学习。假设生成了具有N个样本的原始数据集和具有T颗树(基学习器)的LightGBM 模型,在经历t次迭代后的预测值y(t)prei如公式 ⑸ 所示。

LightGBM 是梯度提升决策树(GBDT)的有效实现算法,也是一种基于XGBoost 的优化算法,LightGBM能够找到最佳特征分割点,减少样本和特征数目。与XGBoost 相比,LightGBM 具有2 个主要优点:基于梯度的单边采样(GOSS)和决策树中按叶子生长策略(Leaf-wise)。
从减少样本数角度出发,GOSS 根据梯度绝对值对样本进行排序,保留前a%样本,并从剩余样本中选择b%,后续计算中将小梯度样本的信息增益放大(100 -a) /b倍,实现样本梯度越大,计算增益时的贡献越大。GOSS 无需遍历数据集以检查GBDT 中可能的分裂节点,这在很大程度上减少了计算的复杂性。在树的生长策略上,大多数决策树算法均采用分层策略Level-wise,该策略不考虑分裂增益,分裂增益较低的叶子会过度消耗计算资源,Leaf-wise 可从所有叶子中找到分裂增益最大的叶子节点进行分裂并迭代。因此,在相同的条件下,Leaf-wise 可以减小误差,并最终表现出更高的预测精度。然而,当样本量很小时,Leaf-wise 存在过度拟合的问题。利用参数max_depth 限制树的深度,可有效避免过拟合现象。2 种生长树策略如图7所示。
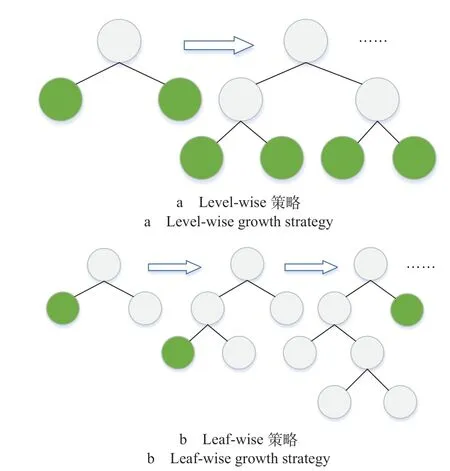
图7 2 种生长树策略Fig.7 Two tree growth strategies
2.2 模型构建与参数标定
将数据集拆分为训练集(7 月8 日至8 月25 日)、验证集(8 月25 日至8 月30 日)和测试集(8 月31 日),按前述流程处理后的训练集输入LightGBM 模型。对参数进行调整是模型训练过程中的一个重要环节,包括主要参数、基学习器数量和其他参数3部分。
(1)主要参数。考虑训练数据量及LightGBM 参数调整范围,采用贝叶斯优化方法hyperopt 进行调参,该方法用于串行和并行优化,优化输入参数以最小化目标函数值,实现重要参数在一定范围空间的高效调参。此外,在训练过程中,采用K折交叉验证(KCV)方法,避免模型出现过拟合,并提高模型的泛化能力。K折交叉验证将原始数据集经KCV 后平均划分为c组,每个子集作为一个验证集,其余c-1 个子集作为训练集。最终实现算法控制与LightGBM 参数优化,LightGBM主要参数如表3 所示。
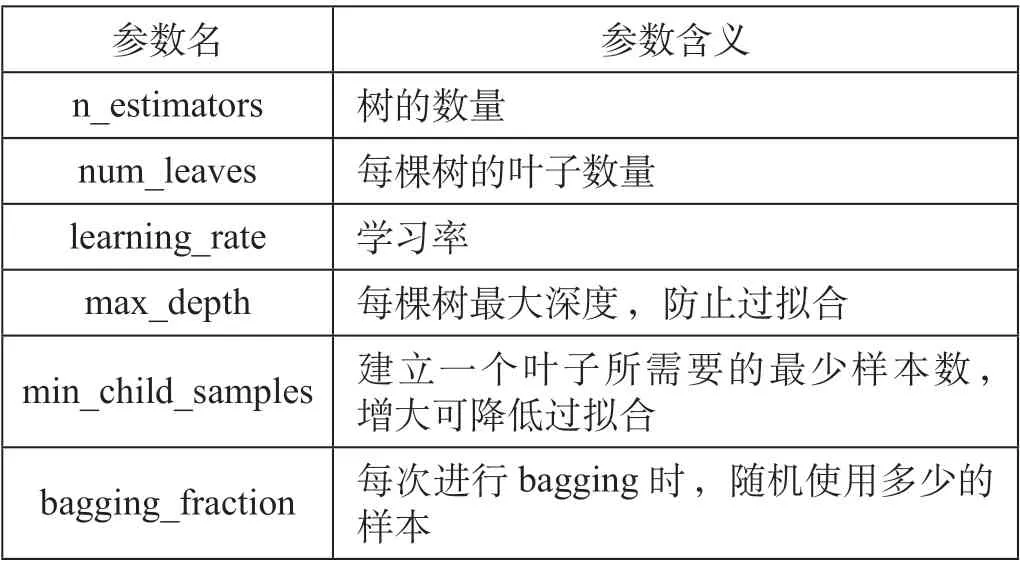
表3 LightGBM 主要参数Tab.3 Main parameters of LightGBM
(2)基学习器的数量。作为集成算法,Light-GBM 中的基学习器数量直接影响最终的模型精度,可通过调整基学习器数量以避免模型训练中出现过拟合和欠拟合问题。以平均绝对误差(MAE)为指标,5 折交叉验证基学习器数量学习曲线如图8 所示。经图8 分析可知,基学习器取值如表4 所示。
表4 基学习器取值Tab.4 Values of base learners
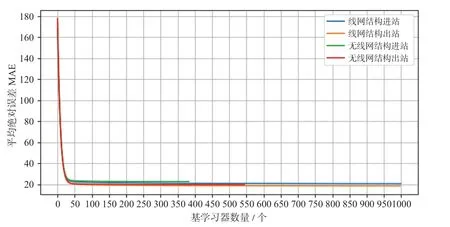
图8 5折交叉验证基学习器数量学习曲线Fig.8 Learning curve of base learners by 5-CV
(3)其他参数。通过贝叶斯优化方法hyperopt迭代获取模型的最优参数组合,调节参数取值。预测模型参数如表5 所示。
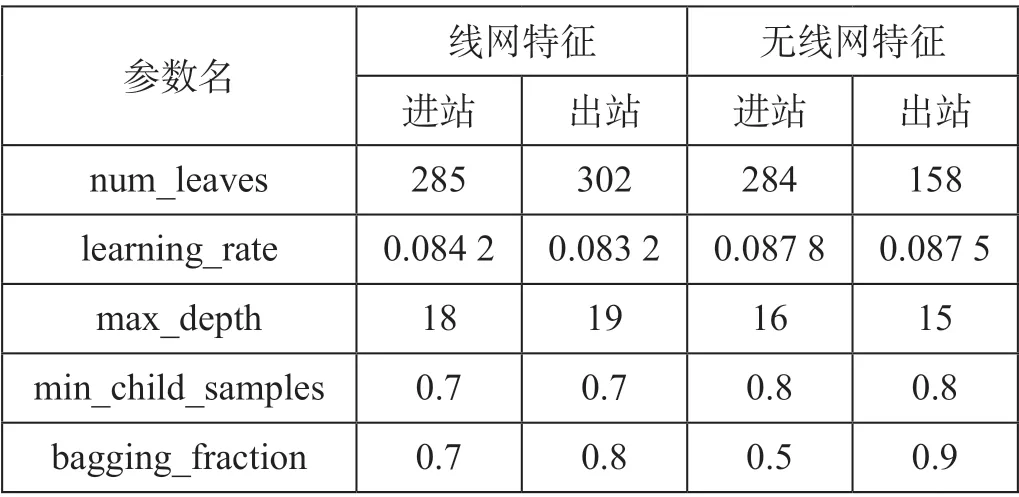
表5 预测模型参数Tab.5 Parameters of the passenger flow prediction model
3 模型结果分析
3.1 模型评估
评估回归模型常采用的指标有均方误差(MSE)、平均绝对误差(MAE)、平均绝对百分比误差(MAPE)、均方根误差(RMSE) 和决定系数R2_score。由于数据粒度为15 min,评估指标选取MAE如公式 ⑼、MAPE如公式 ⑽ 、RMSE如公式 ⑾ 所示。
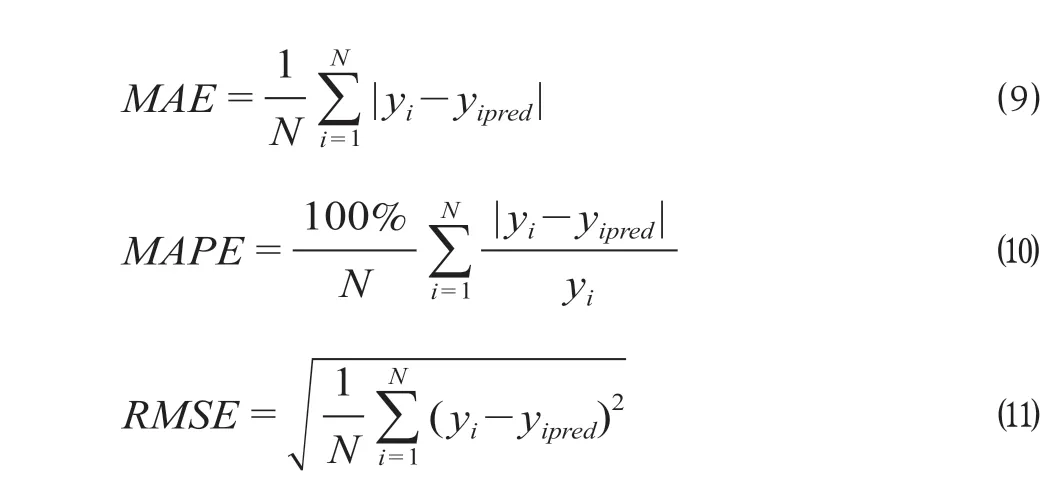
式中:yi,yipred分别代表第i个样本的真实值和预测值。考虑到LightGBM 属于机器学习中的集成模型,为验证其在客流预测上的优势,选取同为集成算法的XGBoost、随机森林、CatBoost,以及多层感知机MLP 进行对比。进站模型对比评估如表6 所示,出站模型对比评估如表7 所示。
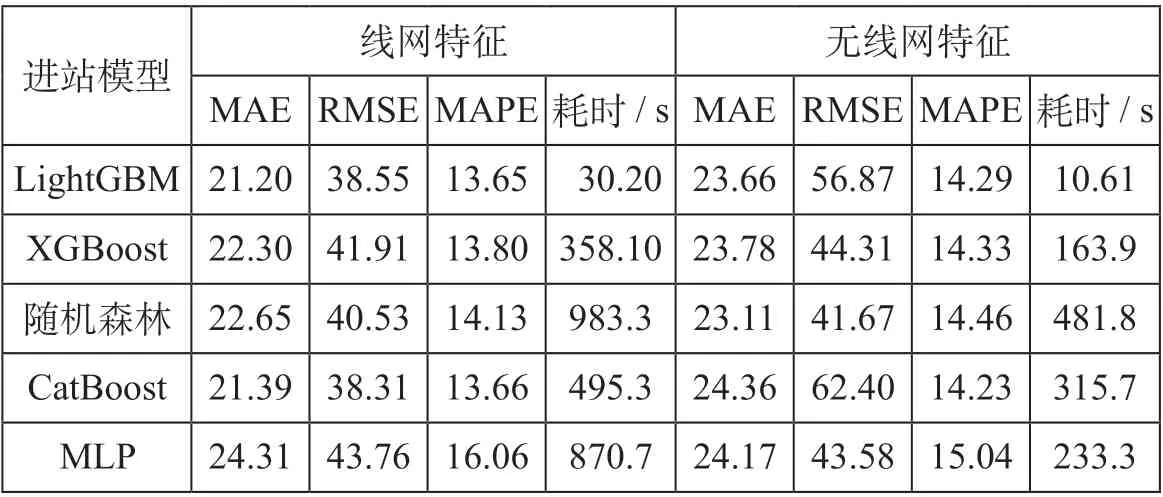
表6 进站模型对比评估Tab.6 Comparison among prediction models in passenger inflow
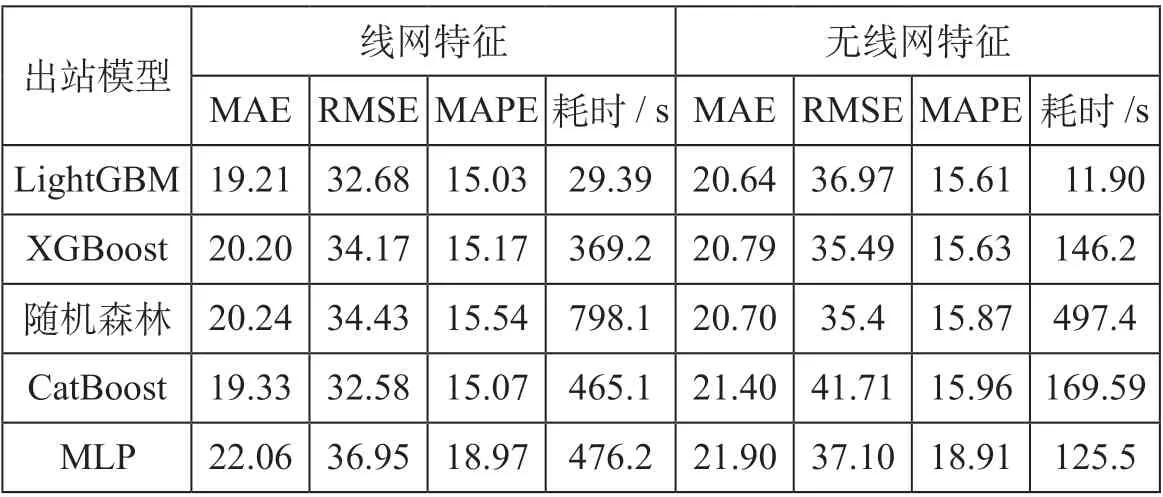
表7 出站模型对比评估Tab.7 Comparison among prediction models in passenger outflow
通过模型评估结果分析,在特征表现上,线网结构特征能够提升不同算法的回归效果以实现更高的预测精度。其中对于进站客流模型,LightGBM 在低维数据集上表现出较高的RMSE,结合线网结构特征后,LightGBM 将RMSE降低约35%。在算法效果上,LightGBM 在各数据集上的预测精度均优于MLP、XGBoost 与CatBoost,但在低维进站数据集上的表现略低于随机森林。从总体看,所提出的考虑线网结构的LightGBM 模型在确保预测精度的同时,大幅降低了模型训练消耗的时间成本,训练速度较XGBoot、随机森林、CatBoost 和MLP 分别提升约10 倍、25 倍、15 倍和10 倍。
3.2 特征重要性分析
特征在基学习器中出现的次数反映了特征对模型的贡献程度,由于最终数据集涵盖特征数量较多,选取特征重要性排序较前的特征展开分析。进站客流预测模型特征重要性如图9 所示,出站客流预测模型特征重要性如图10 所示。
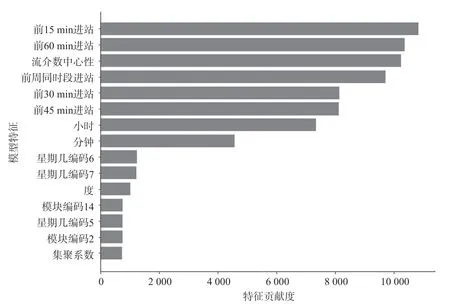
图9 进站客流预测模型特征重要性Fig.9 Feature importance of the prediction model in passenger inflow
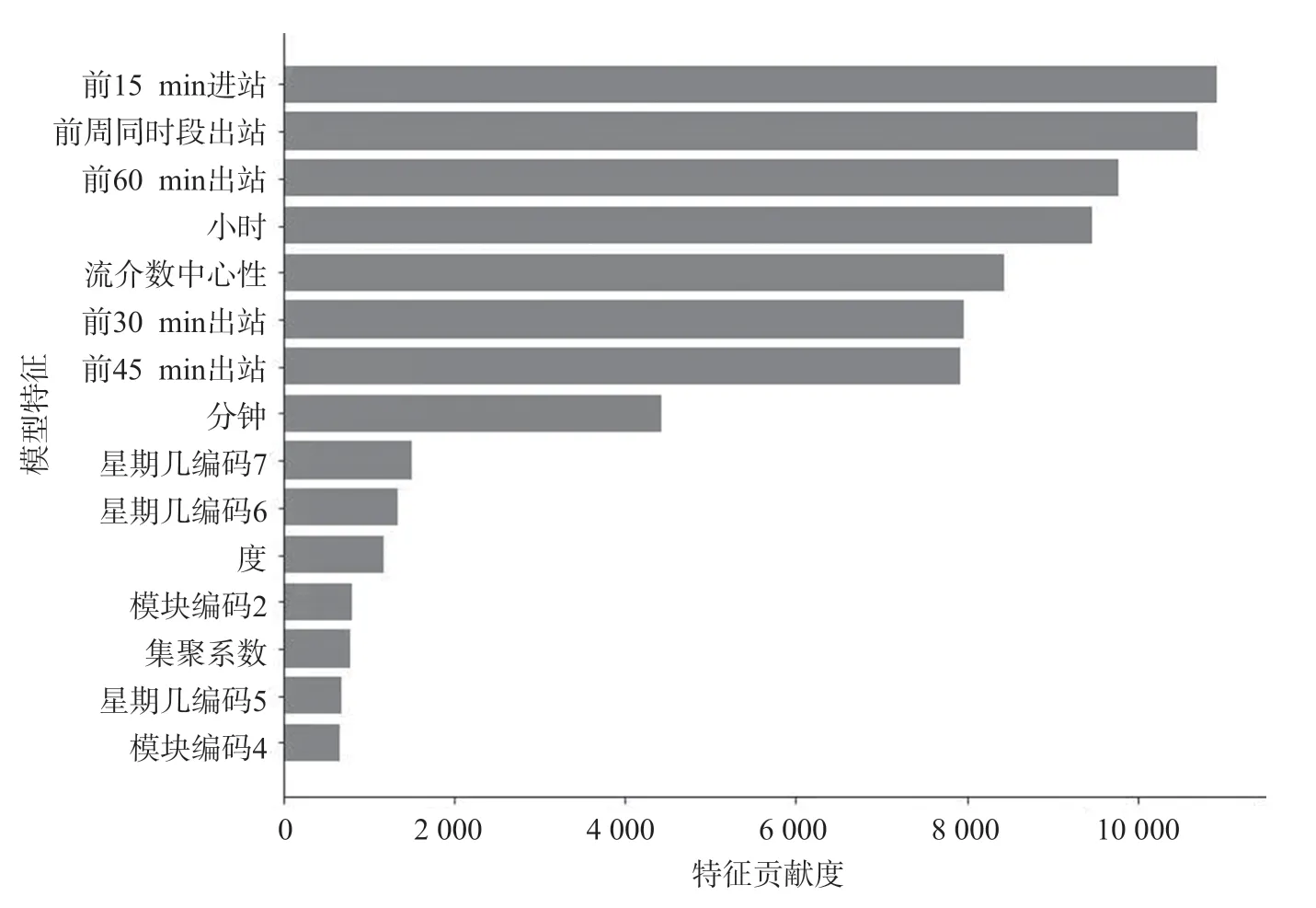
图10 出站客流预测模型特征重要性Fig.10 Feature importance of the prediction model in passenger outflow
在时间维度特征中,“当天前时段客流量”在特征重要性排序上位置靠前,其中“当天前15 min客流量”对模型贡献最大。“前周同时段进出站客流量”次之,代表周六周日的独热编码在“星期几编码”中排序较前,呈现出轨道交通客流所具备的强周期性。在线网结构特征中,“流介数中心性”特征重要性明显,其他统计指标“度”“集聚系数”及车站所在模块的分类特征均对回归模型有一定影响。综上分析可知,时间维度特征在特征重要性上高于线网结构特征,另外,线网结构特征也对模型有不可忽视的贡献,可有效提升模型的预测精度。
4 结束语
利用复杂网络理论对轨道交通客流数据开展线网结构层面的数据挖掘,通过分析轨道交通网络属性和网络节点统计量及划分网络模块的方式定义客流数据在空间维度上的特征,所构建的考虑线网结构特征的LightGBM 客流预测模型在减少预测误差的同时,大幅缩短了训练时间,降低训练成本,同时证明线网结构特征对模型的预测精度有正向贡献。在后续研究中,可基于完整客流OD 数据计算客流驱动下的客流网络中心性等统计指标,将静态网络转换成动态网络以更好地捕捉轨道交通线网结构在加载客流下的动态特性,提高算法对客流数据的学习效果。
