动态加权条件互信息的特征选择算法
2021-10-31陈小波
张 俐 陈小波
①(江苏理工学院计算机工程学院 常州 213001)
②(北京邮电大学可信分布式计算与服务教育部重点实验室 北京 100876)
③(中国人民银行常州市中心支行 常州 213001)
1 引言
在过去几十年里,新型计算机和互联网技术正在以前所未有的速度产生着大量高维数据[1,2]。在这些高维数据中包含着许多无关和冗余特征。因为不相关和冗余特征不仅会增加模型训练时间而且也使得模型的可解释变得很差。如何处理这些不相关和冗余特征是数据分析和知识发现中所面临的重大挑战。特征选择不同于其他数据降维技术(如特征提取)[3],它可以删除无关和冗余特征,保留相关原始物理特征,从而降低数据维数。这样有利于提高数据质量和分类性能,并使得模型的训练时间大幅缩小而且也使得模型的可解释性变得更强[4,5]。
通常特征选择技术又分为分类依赖型[6](包装器方法和嵌入式方法)和分类器无关型(过滤式方法)。基于信息论的过滤式特征选择方法优点[7–11]为:(1)它可以直接从数据中提取有价值的知识,而且这些知识对于问题真正的解决又起到至关重要作用。(2)它的计算成本低且与具体分类器无关。(3)目前该方法应用领域广泛,包括基因表达数据、文本分类和网络入侵检测等多个领域。因此基于信息论的过滤式特征选择方法逐渐成为特征选择技术的研究热点[12–16]。
常见基于信息论的特征选择算法[5,17–19]可分为两类。最小化冗余特征的算法(maxMIFS[8],MRMR[20],CIFE[8],CMIM[8]和JMI[10]等)和最大化新分类信息的算法(DCSF[12]和JMIM[16])。maxMIFS和MRMR通过去除特征之间冗余特征来提高最优特征子集(S)整体识别质量。但是它们却忽视两个特征与类标签之间的冗余性问题。因此,产生许多经典的多信息去除冗余性的算法,例如JMI,CIFE和CMIM等。然而它们却忽视最大化新分类信息来提高S集合整体识别的质量。随着特征选择算法的发展,如何将减少冗余的特征选择算法和最大化新分类信息的特征选择算法进行融合逐渐成为研究的新热点。代表性的算法有MRI[13],CFR[14]和DISR[21]等。以上这些算法都是基于信息论特征选择框架[7]的具体实现。Brown等人[7]认为选择不同的参数就是选择不同的特征选择算法。它们存在的问题是参数设置过大还是过小都会对特征选择过程造成影响,即存在对无关特征和冗余特征的忽略与误判。
在大数据环境下,针对数据多样性和高维性的特点,寻找一种动态的非预先设置参数的特征选择方法就成为目前需要解决的问题。本文提出一种新的过滤式特征选择算法(Weighted Maximum Relevance and maximum Independence,WMRI)。本文主要贡献为:(1)利用条件互信息衡量特征与类标签之间的相关性以及特征之间冗余性;(2)提出通过均值和标准差来动态调节新分类信息和保留类别信息的权重与平衡问题;(3)通过对10个基准数据集进行实验对比,实验结果表明,该算法(WMRI)优于其他特征选择算法(DCSF,MRI,CFR,IG-RFE[15]和JMIM)。
2 WMRI算法的提出
Brown等人[7]提出基于信息论特征选择框架,具体为
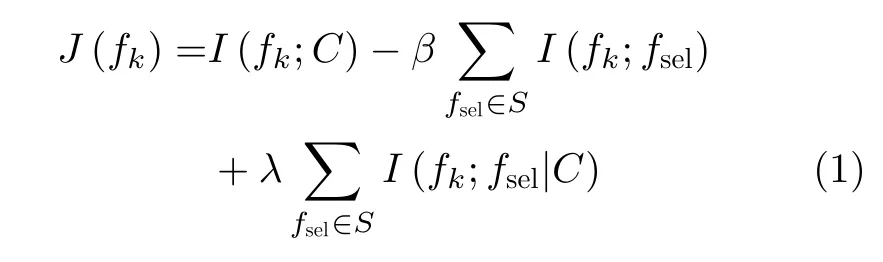
其中,设F是原始特征集合,|S|是最优特征子集数,S ⊂F,J(·)代表评估标准,fk表示候选特征,fsel表示已选特征,fsel∈S,fk∈F-S,C表示类标签集合,|C|是类标签数。
Wang等人[13]在Brown的研究基础上提出MRI算法,具体评估标准为

从式(2)中可知,在MRI算法中,独立分类信息由新分类信息项I(C;fk|fsel)与保留类别信息项I(C;fsel|fk)构成,并且这两种分类信息同等重要,存在问题是在实际中I(C;fk|fsel)与I(C;fsel|fk)之间存在差异性。同时,结合式(1)和式(2)又可知该算法存在预先设置参数β和λ的问题,即λ=。
那么,如何在不增加计算量和复杂度的情况下,动态区分新分类信息和保留类别信息之间的重要程度。以适应在大数据环境下,数据多样性和高维性的特点,并提高S集合整体数据的质量,就成为目前在特征选择领域中需要研究的一个问题。
本文提出一种新的过滤式特征选择算法(WMRI)。该方法通过引入标准差方法来分别计算I(C;fk|fsel)与I(C;fsel|fk)之间的权重。因为标准差[2]是一种常见的测量系统稳定程度的度量方法。标准差值越高,表示分散度越高;反之亦然。因此,通过标准差可以动态平衡新分类信息项与保留类别信息项之间的重要程度。WMRI算法评估标准具体为
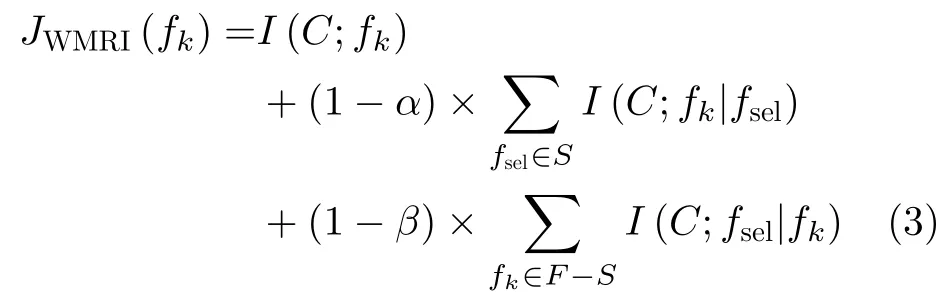
从式(3)可以得出,α和β可以分别动态测量新分类信息项I(C;fk|fsel)与 保留类别信息项I(C;fsel|fk)的重要程度。通过这样,WMRI算法可以解决I(C;fk|fsel)项与I(C;fsel|fk)项之间平衡和权重问题。其中,式(3)中α和β分别由式(5)和式(7)表示,它的伪代码如表1所示。
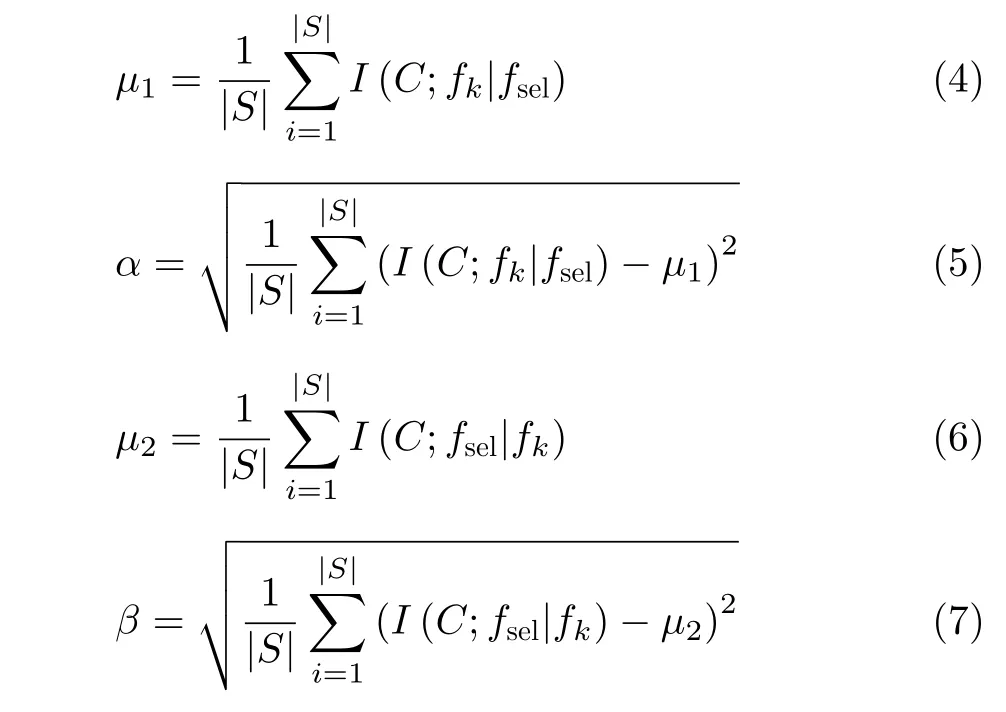
从式(3)可以知道,WMRI算法与MRI算法相类似,都采用前向顺序搜索特征子集。通过表1可知,WMRI算法主要分为3部分。第1部分(第(1)~(6)行)主要包括:(1)初始化S集合和计数器k;(2)计算集合F中每个特征的互信息,选择出最大的特征fk,将该特征fk从F集合中删除,并将特征fk加入S集合,这时候选特征fk变成已选特征fsel。第2部分(第(7)~(15)行)主要是分别计算I(C;fk|fsel),I(C;fsel|fk),μ1,α,μ2和β的值。在第3部分(第(16)~(20)行),根据式(3)的选择标准,选择出最大JWMRI(fk)值所对应的特征fk,并将该特征fk存入S并从F中删除该特征fk,然后一直循环到用户指定的阈值K就停止循环。

表1 WMRI算法的伪代码
WMRI算法包括2个“ for”循环和1个“while”循环。因此,WMRI算法的时间复杂性是O(Kmn)(K代表已选特征数,n代表所有特征数,m代表所有样本数,K≪n)。WMRI算法复杂性高于MRI算法,IG-RFE算法,CFR算法,JMIM算法和DCSF算法。主要原因在于WMRI算法还需计算μ1,α,μ2和β的值。
3 实验分析与讨论
3.1 数据集描述
为了验证所提出WMRI算法的有效性,在实验中使用10个不同数据集进行验证。这些数据集来自不同的领域,同时它们可以在UCI[13]和ASU[19]中找到。这些数据集包括手写数字数据(Semeion和Mfeat-kar)、文字数据(CANE-9)、语音数据(Isolet)、图像数据(COIL20和USPS)、生物学数据(WPBC和ALLAML)和其他类数据(Madelon和Musk2)。更详细的描述可以在表2中找到。
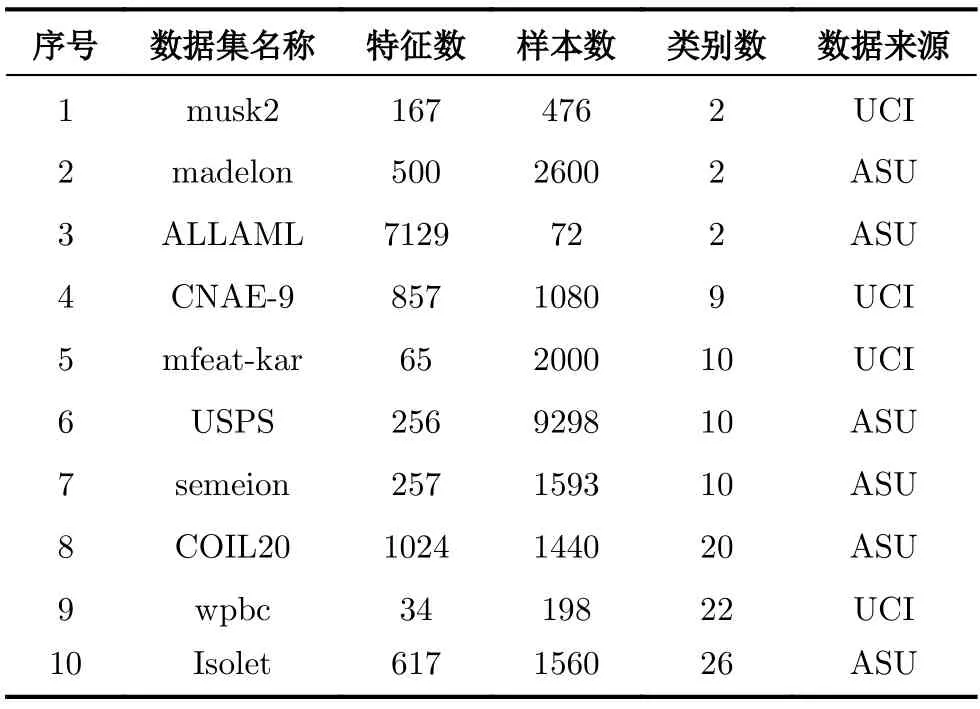
表2 数据集描述
3.2 实验环境设置
在实验中,使用K近邻(KNN)[19]、决策树(C4.5)[13]和随机森林(RandomForest)[22]来评估不同的特征选择算法。本文的实验环境是Intel-i7处理器,使用8 GB内存,仿真软件是Python2.7。
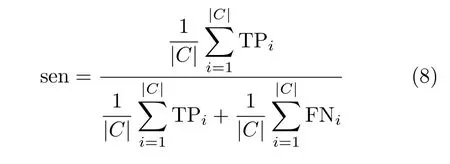
实验由3个部分组成。第1部分是数据预处理。为保证实验的公正性,整个实验过程采用6折交叉验证方法进行验证,就是将实验数据集均匀分成6等份,5份作为训练数据集,1份作为测试数据集。第2部分是特征子集的生成。在实验中,采用不同特征选择方法生成特征子集。特征子集的规模设为30。第3部分是特征子集评价。在这个部分中,用fmi来评估分类器在特征子集上的分类准确率。分类准确率是指正确分类的样本数占样本总数的比例。设TP(True Positive)指正类判定为正类的个数;FP(False Positive)指负类判定为正类的个数;TN(True Negative)指负类判定为负类的个数;FN(False Negative)指正类判定为负类的个数。sen,prc和fmi定义分别为

3.3 实验结果与讨论
表3—表5分别选择KNN,C4.5和Random Forest这3种分类器,同时以fmi分类准确率作为评价指标对WMRI,IG-RFE,CFR,JMIM,DCSF和MRI进行统计分析。表中每行中最大值用黑体字标识。命名为“平均值”的所在行表示平均fmi值。通过使用“+”,“=”和“–”表示WMRI算法分别“优于”、“等于”和“差于”其他特征选择算法。命名为“W/T/L”的所在行,分别表示WMRI算法与其他特征选择算法的胜/平/负的次数。
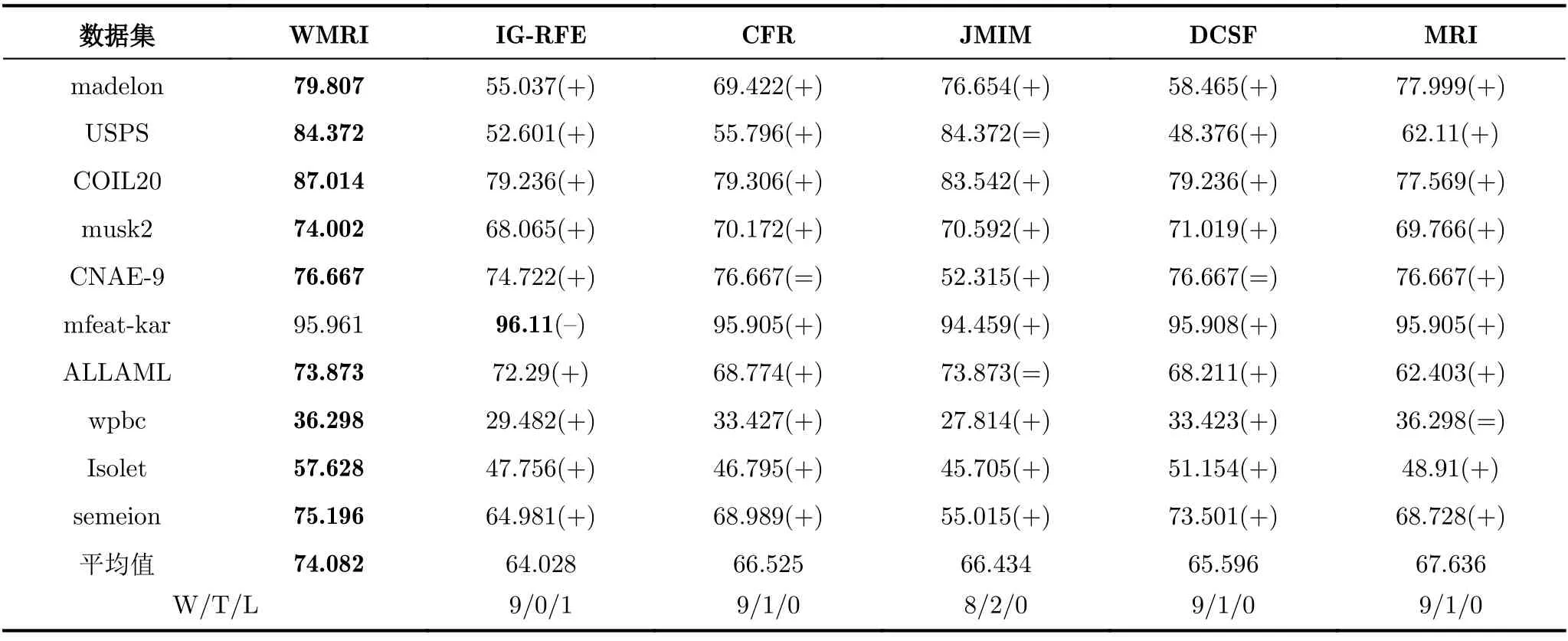
表3 KNN分类器的平均分类准确率fmi(%)

表4 C4.5分类器的平均分类准确率fmi(%)

表5 Random Forest分类器的平均分类准确率fmi(%)
从表3可以得出,WMRI算法在10个数据集的平均fmi值是最高(74.082%)。同时,WMRI分别优IG-RFE,CFR,JMIM,DCSF和MRI为9,9,8,9和9次。在表4中,WMRI算法在10个数据集的平均fmi值也是最高(70.258%)。同时,WMRI分别优IG-RFE,CFR,JMIM,DCSF和MRI为10,8,9,9和8次。在表5中,WMRI算法在10个数据集的平均fmi值也是最高(76.524%)。同时,WMRI分别优IG-RFE,CFR,JMIM,DCSF和MRI为10,10,10,10和10次。
通过对表3—表5分析可以得出,不同分类器表现出的分类结果也不相同。但是,WMRI算法的平均fmi值都是最高。这说明WMRI算法优于其他特征选择算法(IG-RFE,CFR,JMIM,DCSF和MRI)。
为了进一步观察特征子集对fmi值的影响,图1,图2和图3分别给出部分不同数据集的fmi性能比较。从图1、图2和图3可以看出,当数据的维数不断增加时,由于WMRI算法通过平均值和标准差动态调整新分类信息项I(C;fk|fsel)与保留类别信息项I(C;fsel|fk)的重要程度。结果显示,WMRI算法明显优于MRI算法。例如在图1(b)和图2(b)中,JMIM算法优于MRI算法,而WMRI算法优于JMIM算法。图3(a)和图3(b),DCSF算法优于MRI算法,而WMRI算法优于DCSF算法。这些充分说明WMRI算法对分类效果的提升非常明显。并且,WMRI明显优于IG-RFE,CFR,JMIM,DCSF和MRI。
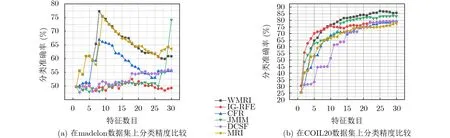
图1 KNN在高维数据集上的性能比较
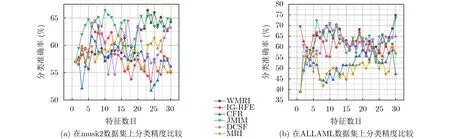
图2 C4.5在高维数据集上的性能比较
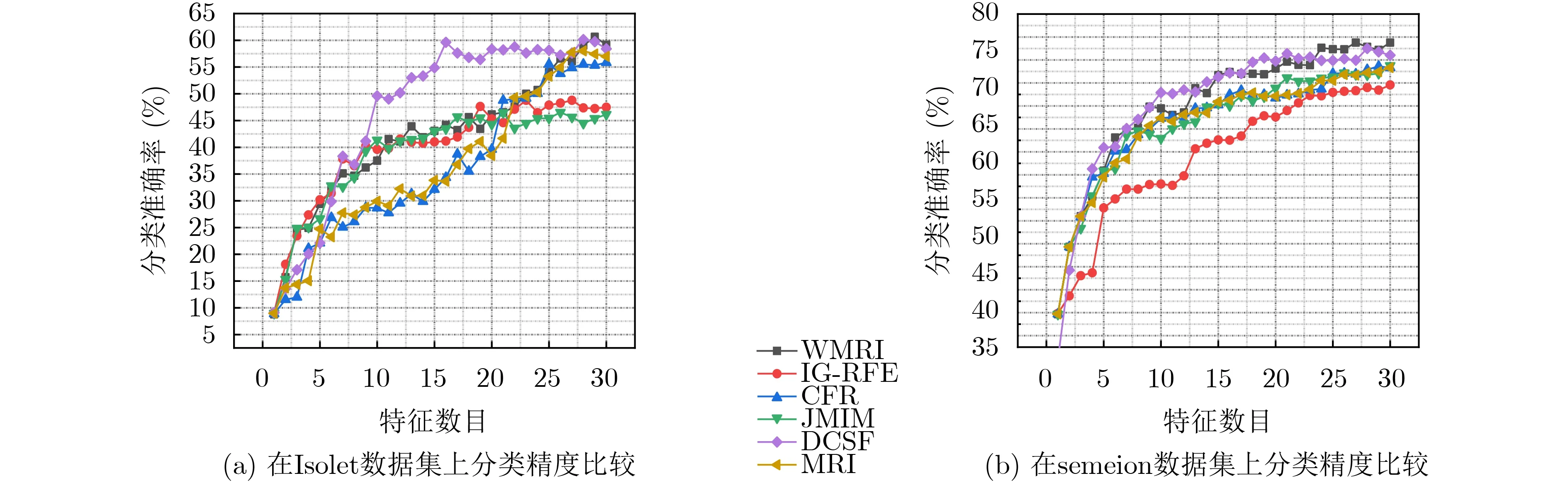
图3 Random Forest在高维数据集上的性能比较
4 结束语
本文提出一种基于过滤式的特征选择方法:动态加权的最大相关和最大独立分类特征选择算法(WMRI)。该算法旨在解决新分类信息和保留类别信息不同重要度的问题并提高特征子集的数据质量。为了全面验证WMRI算法的有效性,实验在10个数据集上进行。通过使用分类器(KNN,C4.5和Random Forest)和分类准确率指标(fmi)全面评估所选特征子集的质量。实验结果证明WMRI明显优于MRI,CFR,JMIM,DCSF和IG-RFE等5种特征选择算法,但WMRI算法有时也会导致特征选择的结果不理想。未来的工作包括进一步改进新分类信息项和保留类别信息项的动态平衡问题并优化WMRI算法,同时在更广泛的领域中验证所提出的方法。
