面向过程的海洋时空数据分布式存储与并行检索❋
2021-10-30谭凯中何亚文
谭凯中 , 秦 勃, 何亚文
(1. 中国海洋大学信息科学与工程学院, 山东 青岛 266100; 2. 中国石油大学(华东)海洋与空间信息学院, 山东 青岛 266580)
近年来,台风、飓风、风暴潮等各类海洋现象和灾害发生日益频繁。如何利用已有的大量海洋现象特征数据对各类海域中海洋现象的生成、演变进行分析、预测和追踪,从而达到海洋现象过程的可视化分析、灾害预警等目的是目前研究的热点。实现海洋现象过程时空数据的组织与高效表达,是达到上述目标以及后期海洋时空数据分析、海洋时空模式挖掘等相关需求的基础。
实现海洋现象过程时空数据的组织与高效表达,需要建立针对海洋现象过程的对象数据组织模型。连续渐变的时空现象的组织与表达一直是地理信息科学领域的热点和难点问题,文献[1]提出了一种模拟地理过程的数据模型开发手段,对现有的动态建模方法进行补充,更详细地描述了系统在每个时间步长中的状态。文献[2]提出了时空变化追踪查询地理现象动态交互框架,该框架将动态现象的信息组织为静态结构、过程和场景的层次结构。文献[3]提出了过程思想的“事件-过程-状态”地理现象的时空分级表达结构,实现了纵向时间尺度上地理动态信息的表达。文献[4-5]对时空过程进行了不同角度的语义描述,建立了多种时空过程信息表达与组织模型。文献[6]提出了过程对象的BNF范式组织,基于海洋时空过程模型构建了原型系统。除去数据模型之外,可扩展标记语言XML等独立的数据交换格式和管理方法作为信息的载体,可用于数据库、地理空间数据之间的数据交换和数据编码[7-8],美国环境系统研发公司开发shapefile空间数据开发格式借助点、线、面刻画地理空间数据对象,也是目前业界的一个开放标准。
除了数据入库前的预处理以外,还需要对信息多元结构复杂的海洋时空数据建立空间数据索引。常见的空间索引技术包括二叉树类型空间索引、基于B树的空间索引以及空间目标填充曲线等索引技术。其中R树类型的空间索引是B树在多维空间的扩展,具有结构平衡、空间利用率和查询效率高等特点。在R树的分布式并行构建方面,文献[12]设计了非共享并行环境下的Master-client R树空间数据索引结构,通过搜索Master R树叶子节点包含的空间数据对象所在clientR树的client id 进行进一步空间查询,同时在现有的云平台和分布式技术上也提出了一些并行构建R树的方法[13-14]。文献[15-16]提出了利用混合空间数据索引管理高密度点云数据的方法,以满足大量点云数据的高效处理需求。文献[17]针对NoSQL数据库的时空查询问题,提出了一种适用于HBASE的双层架构的时空索引STEHIX, 并基于此结构设计并优化了空间范围查询和KNN查询。
由于现有的时空数据研究大多局限于二维地理空间数据的存储与查询,在三维时变过程数据处理方面探索较少。本文针对海洋现象过程时空数据的高效检索与数据组织问题,首先设计了海洋现象过程的对象数据组织模型。基于此数据组织模型,提出了一种面向过程的海洋时空数据检索算法。为保证算法的检索效率,设计了三维空间海洋时空数据分片策略,并在数据分片策略之上构建分布式R树空间数据索引,以实现基于云平台的海洋现象过程时空数据存储与检索系统。
1 海洋现象过程对象表达与组织
1.1 海洋现象过程时空数据的组织与处理
海洋现象具有时刻变化的动态特征,因此海洋现象过程是一个连续渐变的时空过程。由于数据采集技术的限制,目前发布的海洋观测数据是按照某一长度的时间间隔进行采集的,所采集的时空数据是离散时变的。因此,为了支持后续数据的高效检索,在数据组织阶段以一系列海洋现象状态对象的变化过程模拟海洋现象的连续渐变过程。海洋现象过程对象的BNF范式组织如下:
ProcecessID标识海洋现象过程,ProcecessType标识海洋现象过程类型,Time标识海洋现象从生成到消亡的时间周期,SubProcess标识海洋现象过程所包含的子过程。从数据检索的语义上描述,海洋现象过程可以进一步分解为一系列子过程。海洋现象过程对象的子过程具有类似的组织结构,其BNF范式组织如下:
其中SubProcess唯一标识海洋现象过程的子过程,Time用于描述子过程的时态,Space描述空间信息及其随时间t的变化关系,
海洋现象的各阶段有着固定的时间顺序,所以除了ID标识符等属性外,还需记录前一个以及下一个要发生的海洋现象阶段对象,分别使用PreviousStageID、NextStageID记录。
海洋现象状态对象可用于组织海洋现象过程或子过程对象,主要包含空间描述和时态描述,且空间特征不随时间变化。其BNF范式表示如下:
StatusID标签唯一标识一个海洋现象状态对象,Space标签为空间属性,Time标签描述时态,Attributes标签用于表示其他属性特征。SquID用于标志海洋现象状态对象所属的子过程。
1.2 海洋现象过程对象数据组织模型XML描述方式
海洋现象过程时空数据的存储与分布式检索系统以XML作为海洋现象过程的对象数据组织模型的表述语言,本文以台风为例对时空过程进行组织。
海洋现象台风的时空过程或子过程对应状态集合S,S={S1,S2,S3…Sn}。当抽取台风的中心位置、风圈半径等信息为主要特征时,每个海洋现象状态Sn包含了时间属性tn,中心位置On以及一组分层的空间形态特征集合,每一层可近似看作以On为中心的一定半径范围内的区域Cl。因此tn时刻状态对应的空间特征可描述为:
海洋现象台风的特征数据包括台风中心,近中心最大风速、各级风圈半径,层高与气压变化等特点,其中时间、中心位置空间特征、层数等为海洋现象状态对象检索前需提供的键属性。台风的状态对象XML描述如图1所示,台风的时空过程对象XML描述如图2所示。

图1 状态对象XML描述

图2 台风时空过程对象XML描述
数据模型中以每个采样时间点对应一个海洋现象状态对象,台风的各海洋现象状态对象除时间属性外还包含位置信息和空间结构信息,位置信息以台风中心经纬度坐标(lat,lon)表示,每一时刻的台风中心位置可构成完整的台风路径信息。空间结构则是一个三维体模型。数据采样是分层且离散的,因此三维体模型采用面模型表示。每一层对应的二维平面形状表示待检索的区域。由于台风边界信息不规则且极为复杂,为了在检索阶段保证数据的完整性并为后续的海洋现象特征数据分析提供可靠的数据支撑,以距离台风中心7级风圈半径以内区域表示待查询范围,以一百公里作为距离单位,完成每一层的空间结构信息组织。
2 海洋现象过程时空数据相关索引设计
2.1 三维空间海洋时空数据分片策略
海洋时空数据处理在时间和空间上存在一定的连续性,并且海洋时空数据检索查询有一个重要特点:存储的海洋时空数据集规模很大,但是待检索的数据结果集规模不大。因为海洋时空数据处理通常计算量很大,例如某条台风路径上的风场、气压和降雨量等数据的实时计算和可视化等应用,如果输入的数据检索结果集规模太大则难以满足数据处理的时效性。因此设计一种合理的空间数据对象分片策略,通过划分空间区域对海洋时空数据场进行分片可以更好的支持海洋现象过程时空数据的检索工作。
三维空间区域的划分工作最终会以海洋时空数据分片的方式将数据预处理阶段得到的海洋时空数据输出到云平台。因此三维空间区域的划分方式需要综合考虑数据分片文件大小和分区划分依据两方面问题。分片数据量大小可以结合具体系统考量,尽管区域划分阶段形成的网格较细,可以降低后续数据检索阶段带来的数据冗余,检索查询效率较高。但由于数据存储平台的限制,大量小文件会引发数据存储平台效率低下的问题,例如HDFS分布式文件系统中常见的数据块设置大小为64MB、128MB等。当分片文件大小远大于系统数据分块大小时,也会引发存储端的数据冗余。因此数据分片文件的大小最好接近于具体数据存储系统的文件分块大小,且文件分块不宜过大,应根据具体的应用需求加以调整。
算法首先输入海洋时空数据对象的分区数量,根据经度方向和纬度方向的分区数量分别计算每个分区跨越的经纬度latInterval、lonInterval,然后计算待分区数据对象的三维索引信息grid3DIdx,grid3DIdx包含了数据对象的经度、纬度和高度信息。由于海洋现象过程时空数据的检索是一个分层查询的过程,所以需要根据数据对象所在层数划分区域。最后通过空间数据对象的三维索引信息及每个方向上的分区数量计算传入数据对象的分区ID。
区域划分的依据主要是数据的时间信息和空间信息。海洋时空数据以时间为最外层进行组织,由于海洋现象过程时空数据的检索时间跨度不会太长,因此可以以年为单位划分在最上层,也就是同一区域的海洋时空数据对应的年份相同。下层子区域则以数据所在层数为单位进行第二次划分,然后按照经纬度划分得到最终的数据分片文件。空间区域划分是连续的,数据分区阶段的主要工作则是按照数据对象的经度、维度和层数三个维度加以分区。下面是三维空间海洋时空数据分片过程中数据分区的算法描述,其中经纬度的两个方向以均匀网格的形式加以划分,算法1给出了数据分区算法的描述。
算法1:数据分区算法
输入:point,partitionNum,levels
输出:partitionID
1./*计算分区跨越的经纬度*/
2.latInterval= 180/partitionNum.x
3.lonInterval= 360/partitionNum.y
4./*计算数据对象所在分区的索引*/
5.grid3DIdx.x= (90+point.x)/latIntervel
6.grid3DIdx.y=point.y/lonIntervel
7.grid3DIdx.level=point.level
8./*计算分区ID*/
9.partitionID=grid3DIdx.level*partionNum.x*partionNum.y+grid3DIdx.x*partionNum.y+grid3DIdx.y。
2.2 基于空间数据分区的R树分布式空间索引算法
本文结合面向过程的海洋时空数据检索算法思想设计基于空间数据分区的R树分布式空间索引算法。以全球风场为例,构建的索引结构如图3所示。
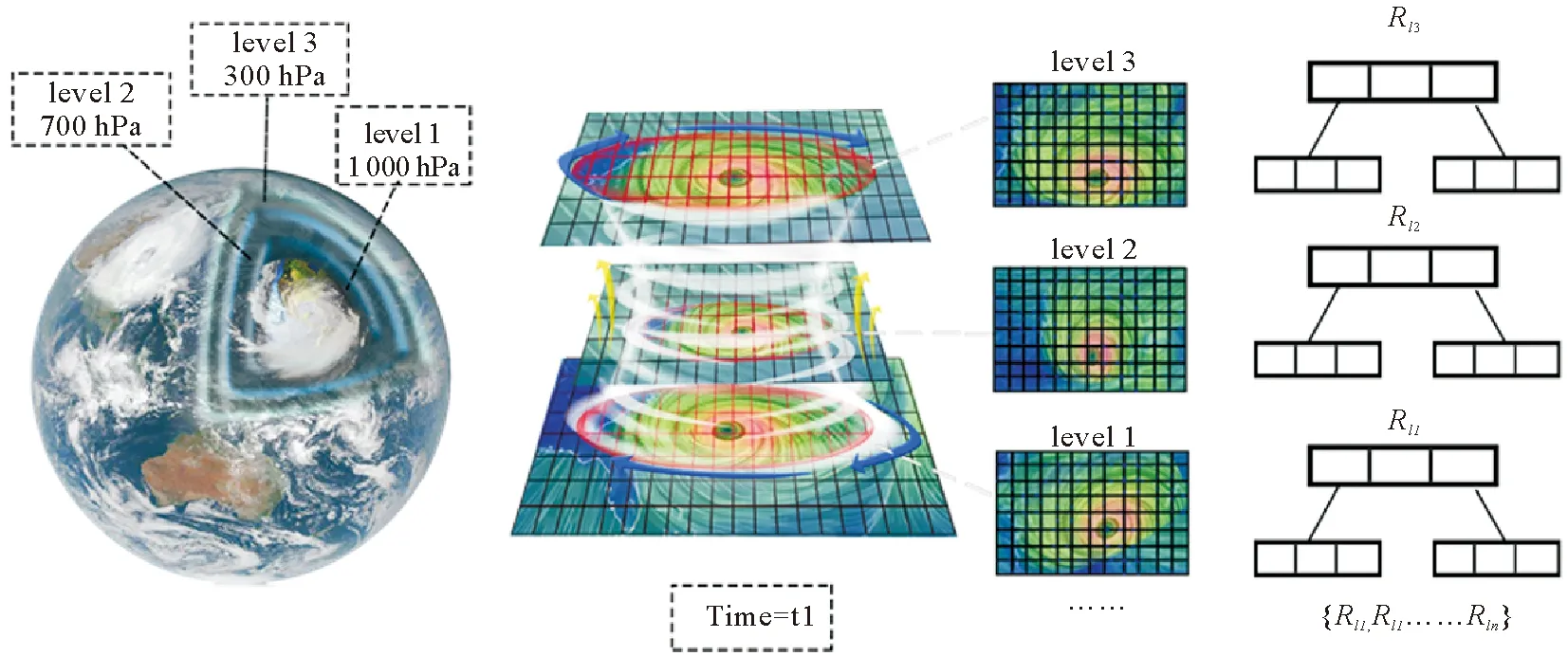
图3 基于数据分区的R树索引
索引构建的核心思想是基于三维空间海洋时空数据分片设计R树分布式空间索引的基本数据结构,构造的空间数据索引是一种单级的时空数据索引。在分区边界信息分布式统计阶段中,首先要分布式统计每个数据分片内的海洋时空数据空间属性信息,计算出数据分片的各维度边界信息,建立最小外接矩形。使用数据分片在分布式存储平台上的文件查找路径作为数据索引描述,将数据分片的最小外接矩形和文件查找路径(I0,I1,Path)作为数据分片的索引信息描述。每个数据分片代表一个分区,因此数据分片内存储的海洋时空数据对象每个空间维度的最大值和最小值就构成了当前数据分区的最小外接矩形。
索引信息收集阶段主要对上述数据索引描述进行收集并构建索引信息描述集。遍历索引信息描述集中的每个索引信息描述,并作为空间数据对象插入到R树中,基于STR算法[18]构建当前层的全局R树空间数据索引。构建完成后分布式统计下一层的海洋时空数据分片文件信息,重复执行上述过程。
图3标注了近地面的3层大气,全球风场数据共分为17层标准大气,三维空间数据分片策略根据数据的经度、维度和层数进行区域划分,通过分区阶段形成的网格完成R树索引的分层构建。
3 面向过程的海洋时空数据检索
3.1 面向过程的海洋时空数据检索算法的设计
海洋现象过程时空数据的检索操作可以转换为时空数据集合到时空过程数据集合的映射。由于海洋现象过程时空数据实际上是特定时间和空间区域范围的海洋时空数据集合,因此数据的检索包含空间属性信息过滤和时间属性信息过滤两个过程,空间和时间属性信息的过滤条件来自待检索海洋现象过程对象所包含的一系列海洋现象状态对象的空间和时态特征信息。海洋现象状态对象的空间特征信息属于不随时间变化的静态空间信息,时态信息的时间区间范围较短或者仅包含某个时间采样点。海洋时空数据经过两个阶段的过滤筛选最终得到海洋现象过程时空数据。因此海洋现象过程时空数据的分布式检索可以采用单机-单机并行-分布式并行-单机的模式执行,这里以Master-worker并行模式为例,总体上分为如下几个过程:
(1)加载海洋现象过程的对象数据模型信息,将各个状态的描述信息读取到主节点的内存中,根据海洋现象状态的描述信息首先生成一个空间属性约束条件。
(2)主节点进程根据空间属性约束条件查找空间数据索引,筛选出需要读取的海洋时空数据分片。
(3)Worker节点进程根据空间属性约束条件分布式并行过滤每个分片内的海洋时空数据。
(4)Worker节点进程根据时间属性约束条件分布式并行过滤海洋时空数据。
(5)主节点进程收集满足约束条件的海洋时空数据,并进行排序。最终合并构造成完整的海洋现象过程数据对象并保存至分布式存储平台。
算法2描述了三维空间下海洋现象过程时空数据的检索流程,由于不同时间的海洋现象状态数据相对独立,其中数据分片的筛选过程可以在主节点内存中并行查找数据分片,以多核多线程的方式搜索R树索引。数据过滤过程在具体实现过程中以分布式并行的方式完成。
算法2:海洋现象过程时空数据检索
输入:最大层数level,时空过程对象Process,R树空间数据索引
输出:结果集result
1.result← {}
2.forl← 1tolevel
3.forstate∈Process
4.range←getRange(state,l)
5.RangeSet←
6.endfor
7.splits←Query(Rtree,RangeSet)
8.dataset←LoadData(splits)
9.filterResult←spaceFilter(dataset,rangeSet)
10.result←timeFilter(dataset,rangeSet)
11.endfor
12.sort(result)
3.2 面向过程的海洋时空数据检索算法的实现
本文以海洋现象台风为例描述海洋现象过程时空数据的检索过程,如图4所示。

图4 台风时空过程数据检索
海洋现象过程对象的时空特征预先组织在XML数据模型文件中,在元数据信息加载阶段首先读取各个海洋现象状态对象在当前层的空间特征,以台风路径上的台风中心和风圈半径构成空间距离数据对象。算法的空间属性信息过滤阶段可通过分布式距离连接查询(将一组较小的数据点集和另一组空间数据对象集合以距离为约束条件进行连接的查询操作)实现,其中的空间距离数据对象即距离连接操作的左集。集合构建完毕后进入数据分片筛选阶段。
在分片筛选阶段分区数据集的规模远小于海洋时空数据集,此过程不会超出单机的处理能力,因此可采用单机并行方式利用多核多线程实现数据分区的并行查询。主节点各线程根据传入的坐标点及相应的空间距离调用R树分布式空间索引,筛选出与满足空间查询区域相交的海洋时空数据分片并获取描述信息,应用程序主线程将分片描述与空间距离数据对象传入到距离约束查询阶段。
距离约束查询是一个数据的分布式过滤过程,通过传入的分片索引描述读取分布式文件系统的存储路径,构造海洋时空数据对象集合即距离连接操作的右集。此时集群系统的任务调度器根据待处理的数据分区向worker节点分发任务,worker节点进程在过滤过程中利用空间距离数据对象生成数据过滤的判定条件,通过多任务并行处理的方式实现海洋时空数据对象的空间属性信息过滤,将满足判定条件的数据对象传递到时间属性信息过滤阶段。
时间属性信息过滤的完成需要构造一个时间属性过滤器。在距离连接查询之后海洋时空数据对象会与海洋现象状态的ID关联。在具体实现中可以在过滤操作之前构建一个海洋现象过程的时空关系集合,数据集合不包含海洋现象状态的具体信息,以元组(id,position,time)的形式存储,从而减少了内存占用空间。由于集合信息是只读的,主节点以共享变量的方式将集合数据广播到各Worker节点。根据当前海洋现象状态的时间属性信息生成过滤判定条件构造时间属性过滤器。Worker节点进程在接收到数据处理任务和广播变量后,提取传入到时间属性过滤器的时间属性信息,若对应的时刻与当前海洋现象状态的时间属性信息不一致,则海洋时空数据对象不符合过滤判定条件。经过两步过滤可以收集到各海洋现象状态对象的海洋时空数据集。所有符合过滤判定条件的海洋时空数据对象将进入到数据的收集过程。
主节点进程的收集过程负责收集经过空间和时间属性信息过滤之后属于各个海洋现象状态的海洋时空数据对象。若当前检索的层数并未达到最大层,则需要加载海洋现象过程对象在下一层的信息描述,直至各层数据收集完毕,进入合并与排序过程。先进行数据对象集合的合并工作,再依据所属状态进行数据集的划分,按照层数、纬度、经度的顺序进行排序,最后将得到的海洋现象过程对象数据写入到分布式存储平台中。
由于全球范围的海洋时空数据集合以数据分片的方式均匀分布在各节点,台风的运动轨迹是连续的,经过筛选后的数据分片所代表空间范围则是多个在经度和纬度上保持连续的地理空间区域,这些子区域的数据分片分布式存储在集群中的各个节点。当采用计算节点和存储节点统一部署时,每个Worker节点处理的数据分区规模差距不大,从而在一定程度上保证了分布式并行处理过程中的负载均衡。
在基于GeoSpark的算法实现过程中,主要通过PointRDD抽象来实现数据集的筛选。通过读取数据模型中的时空特征信息构造空间距离数据对象,可利用Geometry抽象的Circle子类实现构造,并对生成的空间距离数据对象进行划分。在距离约束查询中向PointRDD的构造函数中传入数据分片文件路径构造海洋时空数据集,根据空间距离数据对象集合设计一个空间属性判定器并代入到RDD中的fillter算子中进行分布式过滤,也可将连接操作的左右集直接代入到JoinQuery内置的空间连接查询算子中实现过滤,并在后续数据的收集过程中分离空间距离数据对象。时间属性过滤可将构造好的时间属性过滤器代入到filter算子中实现。操作完成后进行一次collect操作,将分布在各个节点上的数据汇聚到主节点上进行收集。
3.3 海洋现象过程时空数据存储与检索系统
海洋现象过程时空数据存储与检索系统提供了海洋时空数据预处理与组织、海洋时空数据存储与索引构建以及海洋现象过程时空数据分布式并行检索与存储等基本功能,并最终为相关的海洋现象过程时空数据应用系统提供数据服务,系统总体架构如图5所示。

图5 系统架构图
系统包含三层架构,最下层的处理对象为不同来源的海洋数据,例如卫星遥感数据、观测数据与海洋模拟数据等。系统针对不同类型的海洋时空数据进行统一的整理和组织,并将用户抽取的海洋现象过程时空特征集组织为XML格式的数据模型信息,上传至海洋时空数据存储系统,为数据存储系统提供数据来源。存储层包含三个方面的数据:海洋现象过程数据组织模型(XML文件)、不同种类不同年份的海洋时空数据(TSV文件)以及存储于数据仓库的海洋现象过程对象数据。存储平台以分布式内存文件系统HDFS与多级异构存储介质为核心构建,并利用基于Raft一致性算法的分布式协调服务ZooKeeper实现高可用支持模块,满足数据存储的可靠性以及高可用性。最上层为海洋现象过程时空数据检索系统,系统通过数据存储接口完成与存储平台的访问控制和交互。当系统接收到检索客户端发来的索引建立或更新请求时,索引构建模块根据收到的索引构建参数对海洋时空数据进行分区,并基于数据分区构建R树空间数据索引。当系统接收到检索客户端发送的数据检索请求时,检索系统将检索参数传递给分布式检索引擎,实现对海洋现象过程时空数据的分布式并行检索,最后调用数据持久化模块将检索结果集导入至数据仓库。
4 实验
4.1 实验设计
实验通过测试海洋现象过程时空数据存储与检索系统的相关功能模块,以台风的海洋现象过程时空数据检索为基础,设计了对照实验组,分别测试了海洋现象过程时空数据查询在基于海洋时空数据对象构建的R树空间数据索引和基于空间数据分区构建的R树空间数据索引上的执行效率。基于海洋时空数据对象构建的R树空间数据索引将每个采样点记录的海洋时空数据对象的空间属性信息作为叶节点中存储的空间索引描述信息,根据数据的分区分布式构建多个R树空间数据索引,在算法执行过程中将每个数据分区内的R树空间数据索引读取到内存缓存中,通过汇总每个分区内的查询结果实现所有海洋时空数据对象的过滤功能。
实验使用的海洋时空数据主要来自于NOAA的NCEP再分析数据集,地理网格经度分别为2.5°,1.25°与0.83°,共分为17层,数据量大小为37.4、147.9和332.0 GB,经过解析处理和插值加密等预处理操作以TSV文件格式预先存储在分布式文件系统中。实验使用的台风中心、路径、7级风圈半径等参数信息汇总了中国气象网以及各地海洋预报台网站发布的公开数据,其中的2018年第22号台风山竹的参数信息整合为本次实验的XML数据模型信息。实验集群共包含12个物理节点,Spark集群包含1个Master节点与11个Worker节点,每个Worker节点使用了6 GB内存存储。高可用模块使用了3个节点存储日志和相关配置信息。
4.2 实验结果与分析
实验设计了两种不同的索引方案对台风的海洋现象过程时空数据查询进行测试,方案一使用了基于海洋时空数据对象构建的R树空间数据索引,方案二使用了基于空间数据分区构建的R树空间数据索引。检索对象为台风山竹的时空过程,检索的时间区间范围为2018年的9月11日6 时—15日8时,气压范围为300~1 000 hPa。实验结果如表1,2所示。

表1 方案一检索效率

表2 方案二检索效率
表1记录了方案1的查询时间和效率,指标中的1v1~lv7为检索算法在查询1~7层数据所消耗的时间。方案一在37.4 GB数据集上的分层平均查询时间为8.2 s,检索结果集大小为378.0 kB,检索速率为6.6 kB/s;在147.9 GB数据集上的分层平均查询时间为49.3 s,检索结果集大小为1 525.8 kB,检索速率为4.4 kB/s;在332.0 GB数据集上的分层平均查询时间为95.7 s,检索结果集大小为3 461.1 kB,检索速率为5.2 kB/s。
表2记录了方案2的查询时间和效率。方案二中算法在37.4 GB数据集上的分层平均查询时间为1.0 s,检索结果集大小为378.0 kB,检索速率为51.7 kB/s;在147.9 GB数据集上的分层平均查询时间为3.7 s,检索结果集大小为1 525.8 kB,检索速率为58.4 kB/s;在332.0 GB数据集上的分层平均查询时间为8.8 s,检索结果集大小为3 461.1 kB,检索速率为56.1 kB/s。
在海洋现象过程时空数据的查询实验中,数据检索的总查询时间为实验的核心指标,总查询时间的增长趋势如图6所示。在对照组1中,方案一总查询时间为57.5 s,方案二为7.3 s,方案二的查询速度比方案一快了7.85倍。在对照组2中,方案一总查询时间为345.4 s,方案二为26.1 s,方案二的查询速度比方案一快了13.2倍。在对照组2中,方案一总查询时间为669.6 s,方案二为61.6 s,方案二的查询速度比方案一快了10.9倍。横向对比来看,方案二的查询速度明显较快,且随着数据量增大查询效率进一步拉大。

图6 查询时间增长趋势图
经过分析可知,方案一的查询时间相对数据量的增长速率较高,不过总体上趋近于线性增长。主要原因是该查询方案构建的索引策略在空间属性信息过滤阶段需要访问各个数据分区内的R树,如果数据集的规模超过了集群Worker节点的内存缓存限制时,部分数据分区需要保存在硬盘上,数据量增大时磁盘内的数据分区所占比例越来越高,从而逐步降低查询性能。方案二的查询时间增长率较低,原因在于该方案通过R树空间数据索引查询海洋时空数据对象所在分片文件的位置,因此在数据过滤的效率主要与分片筛选阶段搜索到的分片文件数量以及每个分片文件的数据量有关。当数据精度提高,而分片文件数据量大小保持不变,将使得空间区域的划分更加细致。这样使得分片筛选得到的数据冗余更小,存储和检索效率也得到进一步提升。
图7为两种方案在不同数据集上的索引构建时间对比图。对比可得,方案一的索引构建效率较高,但两者索引构建效率的比率并未拉开明显差距,因此在保证数据检索效率的前提下,方案二的索引构建效率可以接受。虽然方案二因数据分区降低了索引构建效率,但查询效率稳定高效,能够应对海洋现象过程时空数据的检索和处理需求。
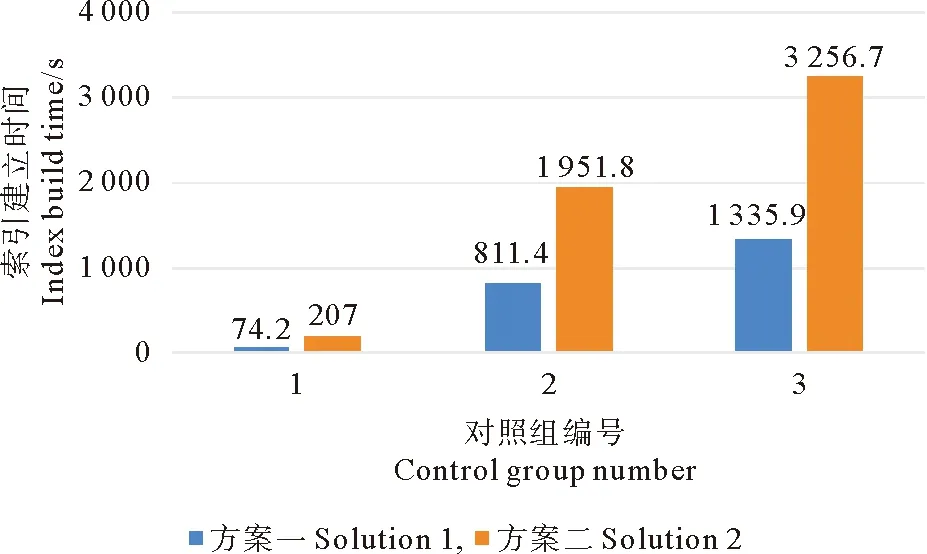
图7 索引建立时间对比图
5 结语
针对海洋现象过程时空数据的组织与检索问题,首先根据检索查询的语义提出了一种海洋现象过程对象数据组织模型,以支持后续数据检索。在面向过程的海洋时空检索算法中结合了分布式计算与R树空间数据索引等技术,实现了检索阶段的空间属性信息过滤和时间属性信息过滤,同时为了更好的优化算法执行效率,设计了三维空间数据分片策略对海洋时空数据场进行空间区划划分,形成的每个海洋时空数据分片做为数据分区,并基于空间数据分区构建R树空间数据索引,通过查找R树筛选海洋时空数据分片。实验结果表明,面向过程的海洋时空数据检索算法能够实现海洋现象过程时空数据的快速有效检索。由于实验所使用的数据量和数据种类有限,后续的研究中有待于收集更为完备的数据,在更大规模的数据集上测试,进一步提高和优化数据检索的效率。
