下一代互联网活跃地址的多分类识别方法
2021-10-29焦飒镧
王 禹,焦飒镧,周 鉴
(1.河南工程学院 软件学院,河南 郑州 451191;2.中国移动通信集团郑州分公司 网络部,河南 郑州 450000;3.中原动力智能机器人有限公司 信息技术部,河南 郑州 450000)
随着物联网、云计算和人工智能的飞速发展,IPv6作为下一代互联网应用解决方案,已经得到快速普及[1-2]。据2020年CNNIC发布的《中国互联网络发展状况统计报告》[3],截至2019年12月,我国IPv6地址数量为50 877块/32,和2018年同期相比增长了15.7%,相对的IPv4地址仅增长了0.4%。从全球视角来看,2019年上半年IPv6地址分配数量为17 865块/32,已分配地址总数为282 222块/32。
在实际应用中,IPv6通过网络运营商实施分配和管理,以保持网络正常通信。由于其天然具有海量空间,不同情况下IPv6的配置模式不尽相同。发展至今,IPv6配置模式主要包括人工配置模式、有状态地址自动配置模式、无状态地址自动配置模式及其子模式(出自RFC 4941[4]、RFC 4862[5]和RFC 7217[6]等的定义)。吴伊杰等[7]对IPv6地址配置策略进行分析并设计了识别算法,但未提及隐私扩展模式地址的处理方法。Foremski等[8]基于聚类算法和信息熵对IPv6地址结构特征进行分析研究,对于随机化地址分类识别给出了较好的方法,然而并未涵盖所有的IPv6地址分配模式。
针对IPv6地址进行分类识别,能够有效挖掘IPv6地址的配置策略和部署规律,为后续地址探测和网络监管等打下基础。本研究分析了已有下一代互联网地址分配/生成规范,提出了一种融合多种特征的IPv6地址分类识别方法,并基于真实的活跃地址数据集验证了该方法的有效性。
1 IPv6地址结构
IPv6地址空间巨大,根据互联网数字分配机构(the internet assigned numbers authority,IANA)的规划方案,可分为以下几类,具体情况如表1所示。其中,2000::/3为全球单播地址空间,其他地址段可用于保留地址、组播、链路内单播等。

表1 IANA指定的IPv6地址范围Tab.1 IPv6 address allocation range designated by IANA
图1展示了全球单播IPv6地址的结构,其中全球路由前缀占据n比特,为IPv6地址的最高序位部分;随后的子网ID即子网前缀,占据m比特,用于判定子网地址;最后的接口标识符(Interface ID),简称接口ID或IID,占据最后的部分(128-n-m比特)。

图1 全球单播IPv6地址Fig.1 Global unicast IPv6 address
默认情况下,每个互联网服务供应商(internet service provider, ISP)能够实际利用的地址块至少包含约296个地址,负责分配IPv6地址,然而分配策略的差异导致不同ISP生成的IPv6地址结构较为复杂。
2 IPv6地址生成
2.1 IPv6地址生成模式
IPv6地址中的全球路由前缀可通过请求相邻路由器获得,用来识别某个站点的地址范围;子网ID用以识别站点中的某个链路;接口标识符部分,用来定位该链路上唯一的网络节点。IPv6地址的生成,可以分为手动地址配置和自动地址配置。前者适用于少量地址的单独配置,然而难以广泛实施;后者可分为有状态地址自动配置(以DHCPv6为代表)和无状态地址自动配置(stateless address auto-configuration,SLAAC)。
有状态地址自动配置模式下,主要采用动态主机配置协议(Stateful DHCPv6)。由DHCPv6服务器负责统一管理,节点通过Client/Server方式从DHCPv6服务器地址池中得到地址,并给节点提供了DNS服务器地址、域名等信息。利用DHCPv6,网络管理员能够知道网络上连接着哪些节点设备及其地址等信息,从而实施精确管理。
无状态地址自动配置模式下,主机通过接收邻接路由器宣告的全球路由前缀,结合接口标识符,从而生成一个全球单播地址。无状态地址自动配置方式在IPv6客户端上实现,方法是侦听这些本地路由器通告(router advertisement,RA),然后将通告的前缀形成可在网络上使用的唯一地址。为此,路由器宣告的网络前缀必须公布明确的前缀长度(如64位);之后,SLAAC将动态地形成一个长度为64位的接口标识符,并且在宣告的前缀末尾予以添加以形成一个IPv6地址。
最初,在无状态地址自动配置模式下,接口标识符是使用EUI-64规则形成的(与形成链路本地地址的规则相同),当前部分IPv6设备仍使用此方法。目前EUI-64方法已被逐步弃用,这是因为MAC地址会暴露节点隐私,存在一定的安全隐患。当前很多操作系统,例如Microsoft等都已不再使用EUI-64方法,而是主要利用RFC 4941等定义的额外隐私扩展方法。
2.2 无状态地址自动配置的EUI-64模式
若按照EUI-64规范流程,主机(以H1命名为例)将按以下方式生成EUI-64接口地址:
首先,前缀信息2000:1234:5678::/64将从所在链路上的路由器R1的RA消息中学习,并成为初始前缀。然后,客户端标识符将从分配给H1的MAC地址中创建,此处假定MAC为0200:5555:7777。EUI-64转换的第一步是将MAC地址分成两半,并在中间放置FF:FE,结果为0200:55FF:FE55:7777。然后,第7位将被翻转,在这种情况下,前8位是00000010(0x02)。接下来,第7位被翻转并且该位变为0,导致00000000(即0x00),得出0000:55FF:FE55:7777的最终主机标识符。将前缀和主机标识符放在一起时,获得H1的IPv6地址为2000:1234:5678:0000:0000:55FF:FE55:7777,可以将其缩短为2000:1234:5678::55FF:FE55:7777。由此可知,根据EUI-64生成的IID(以16进制表示)特征较为明显,即IID[6:10]部分为“FF FE”。
2.3 无状态地址自动配置的隐私扩展模式
RFC 7217 IPv6更新指定了算法来生成IPv6接口标识符及IPv6地址,在相同网络内保持稳定,但会随着节点从一个网络移动到另一个网络。该算法可用表达式IPv6_IID=Hash(Net_Prefix, Net_ID, Net_Iface_ID, Secret_Key)来总结和体现。其中:Hash()为加密安全哈希函数;Net_Prefix为本地路由器发布的IPv6前缀;Net_ID为可选网络标识符,例如Wi-Fi网络的服务集标识符;Net_Iface_ID为底层网络接口的标识符(例如网络接口名称);Secret_Key为秘密键值,通常在系统安装期间作为随机值初始化,并在重新启动时保持不变。
由此可知,这种情况下IPv6接口标识符是通过对多个参数连接计算安全散列获得的,最常见的是本地路由器(Net_Prefix)和密钥(Secret_Key)公布的网络前缀。只要节点保持在相同网络,它将维护和配置相同的IPv6地址,这是因为散列函数的所有参数保持不变。另外,由于网络前缀会改变,所以一旦节点连接到不同的网络,IPv6接口标识符就会改变。同时,如果节点返回之前的链路,它将配置与之前相同的IPv6地址,因为用于计算该IPv6接口标识符的所有参数都与原来相同。
3 融合多特征的IPv6地址识别
针对当前主要存在的人工分配、EUI-64、隐私扩展和有状态DHCPv6等地址生成模式的差异,提出了融合多特征的IPv6地址分类识别方法。
3.1 幻数
幻数(magic numbers)属于特征标识,通常存在于计算机处理器、操作系统、调试器和文件中,一般用来标记文件或者协议的格式。截至目前,计算机网络领域的幻数已有很多,例如0x8BADF00D,意义为“bad food”,在iOS系统中用来标识某个应用长时间未响应;0xB16B00B5,标识“big boobs”,微软Hyper-V需要Linux客户将其作为“客户签名”;0xBAADF00D,即“bad food”,是LocalAlloc函数用来指示未初始化分配的堆内存;0xBADDCAFE,代指“bad cafe”,是动态链接库Libumem用来指出未被初始化的内存区域;0xDEADBEEF,即“dead beef”,通常表示软件崩溃或嵌入式系统陷入死循环。
IPv6地址应用16进制表示法时,包含32个16进制字符,故在语义表达上具有相当明显的优势。根据对幻数的统计归纳与特征识别,对于IPv6人工分配的地址能够有效予以筛选。
3.2 信息熵
虽然当前操作系统所采用的隐私扩展方式不尽相同,但其本质仍以散列计算方法为核心。依据散列算法的特性,对于大量输入,其计算结果符合均匀分布,生成的散列值具备良好的随机性。
熵用以衡量系统的混乱程度或紊乱程度。Shannon[9]借鉴熵的概念,将排除冗余之后的平均信息量定义为信息熵,用以表征一个信源的不确定性、分散性、无序性和变异性等,即涵盖信息量的多少,公式如下:
(1)
式中:X代表信源的n种不同取值x1,x2,…,xi,…,xn,对应的概率为p(x1),p(x2), …,p(xi), …,p(xn)。由式(1)可知,若信源样本差异较大,则信息熵的值相应较大。换言之,变量的不确定性越大,则信息熵值越大。据此,利用信息熵的特性,IPv6地址的随机程度和无序程度能够通过信息熵的计算得以体现。
3.3 IPv6地址分类识别
由于人工分配、EUI-64、隐私扩展和DHCPv6方法在生成模式上有相对显著的差异,故IPv6地址的生成阶段拟采用融合多种特征的识别方法对活跃IPv6地址进行分类。
按照难度递增的规则,首先,EUI-64方法中针对接口识别符中的“FFFE”设置较为明确,所以可以率先筛出;然后,通过统计和编制幻数表,将IPv6地址与计算机网络领域典型的幻数进行比对,如果IPv6地址中存在幻数则应归类为人工配置地址;最后,针对接口标识符空间进行信息熵的计算,根据熵值大小予以判定。
需要指出,有状态DHCPv6目前包含顺序生成模式和随机生成模式,顺序生成模式往往相对固定,通常从低位到高位依次赋予地址;而随机生成模式针对整个IID空间进行计算,结果呈现类似隐私扩展的无规则。因此,无状态地址自动分配中隐私扩展模式与DHCPv6随机模式的计算结果,符合相对理想的随机性和无序性,此种情况下其信息熵值一般相对较大。
IPv6地址分类流程见图2。本研究从IPv6地址生成的原理出发,融合上述特征模式对活跃IPv6地址进行分类。其中,利用信息熵实施判断时,其判定阈值需要根据已有的地址数据集进行迭代测算,从而获得有效阈值。
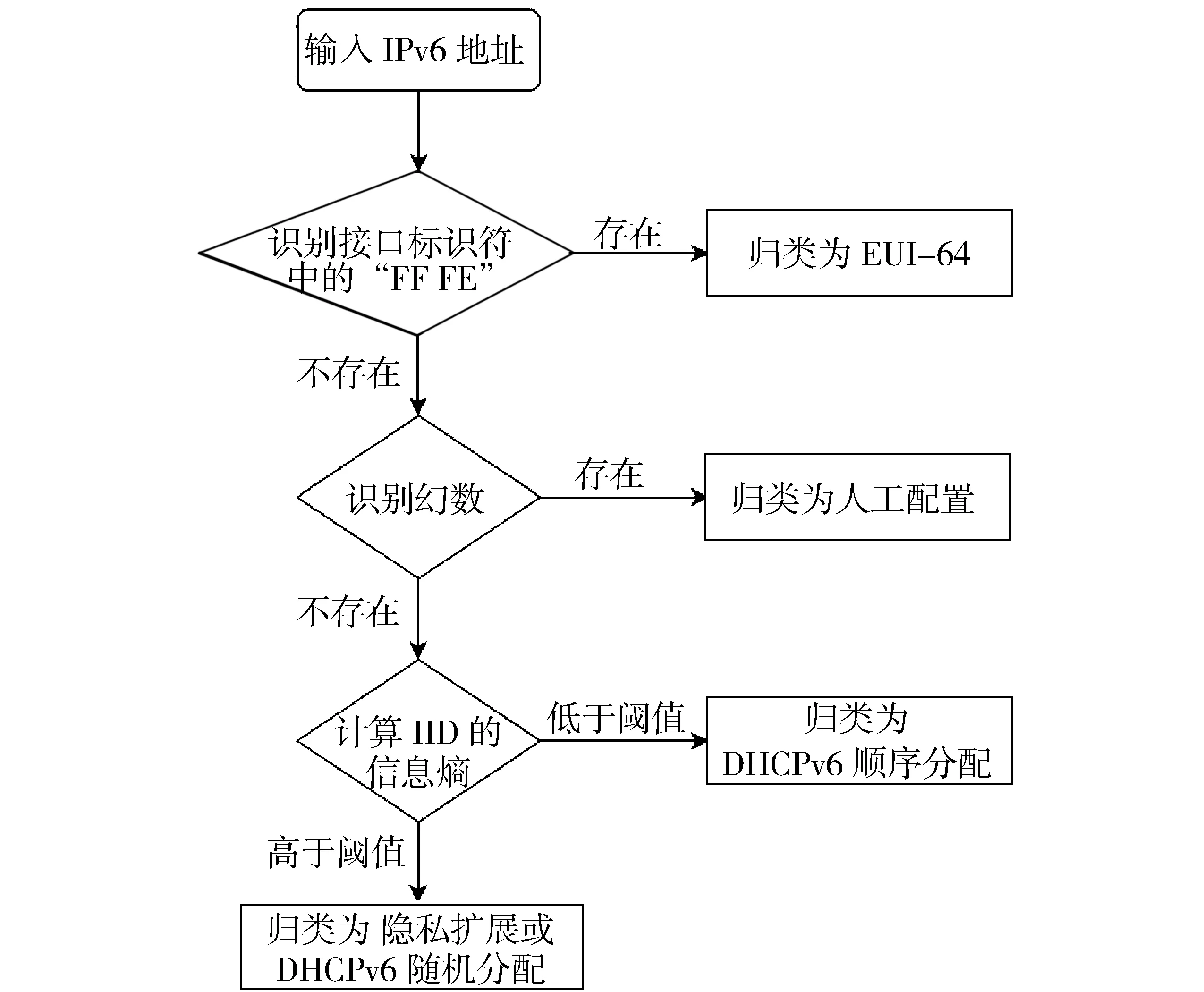
图2 IPv6地址分类流程Fig.2 IPv6 address classification process
4 实验
为了测试方法的有效性,本研究利用真实活跃的IPv6数据集[10]予以验证,该数据集包含的IPv6地址数为2 510 209。依照本研究设计的分类识别方法,验证流程如下:
第一步,人工抽取样本,对基于EUI-64的IPv6地址数据集(称为A类)和基于幻数的IPv6地址数据集(称为B类)进行标注。其中,利用“FF FE”字段匹配EUI-64地址生成特征,而后通过自建常用幻数集,筛选出含有幻数字符串的IPv6地址。
第二步,识别SLAAC隐私扩展类型与DHCPv6类型地址。考虑到有状态DHCPv6包含顺序生成和随机生成两种模式,而DHCPv6随机生成的IPv6地址与隐私扩展的生成地址特征相似,故将二者作为同类(称为C类)进行处理。与之对应,DHCPv6顺序生成的IPv6地址(称为D类),其有序性较为显著。
计算接口标识符部分的信息熵可知,C类地址与D类地址的熵值存在部分交叉。故此,通过逐步缩短步长的方式发掘最优阈值。分析显示当熵值逼近2.65时,对上述两类地址的区分效果最佳,所以将接口标识符熵值大于2.65的部分地址归为C类地址、小于2.65的归为D类地址。需要指出,根据前期实验,针对不同的IPv6地址集,建议在[2.63,2.65]寻找最优熵值。除此之外,考虑到服务器节点或路由节点的重要影响,也存在部分人工配置地址同样符合此种情况的信息熵判定结果。
真实IPv6地址数据集分类占比情况如图3所示。由于基于幻数的数据集(B类)占比仅有0.01%,故在图3中近似于不可见。比例最高的地址分类为有状态DHCPv6顺序分配(D类),其次为SLAAC隐私扩展/DHCPv6随机化类型(C类)。基于EUI-64的地址分类占比为13.18%(A类),然而考虑到内嵌MAC地址存在信息泄露的问题,可以预见未来A类地址的生成数量会越来越少。

图3 IPv6地址分类占比Fig.3 Proportions of IPv6 address classification
将分类结果同手动构建的数据标注集进行正确率统计,具体如图4所示。B类地址最终的分类正确率为98.76%,其原因为在自建的幻数集之外仍发现了新的字符串,使得正确率低于预期,故需要不断挖掘并扩充幻数集合。将新的幻数增补至集合之后,能够完全予以识别。C类和D类地址在当前熵值为2.65的情况下,存在少量的误分类,其分类正确率分别为99.48%和98.63%。
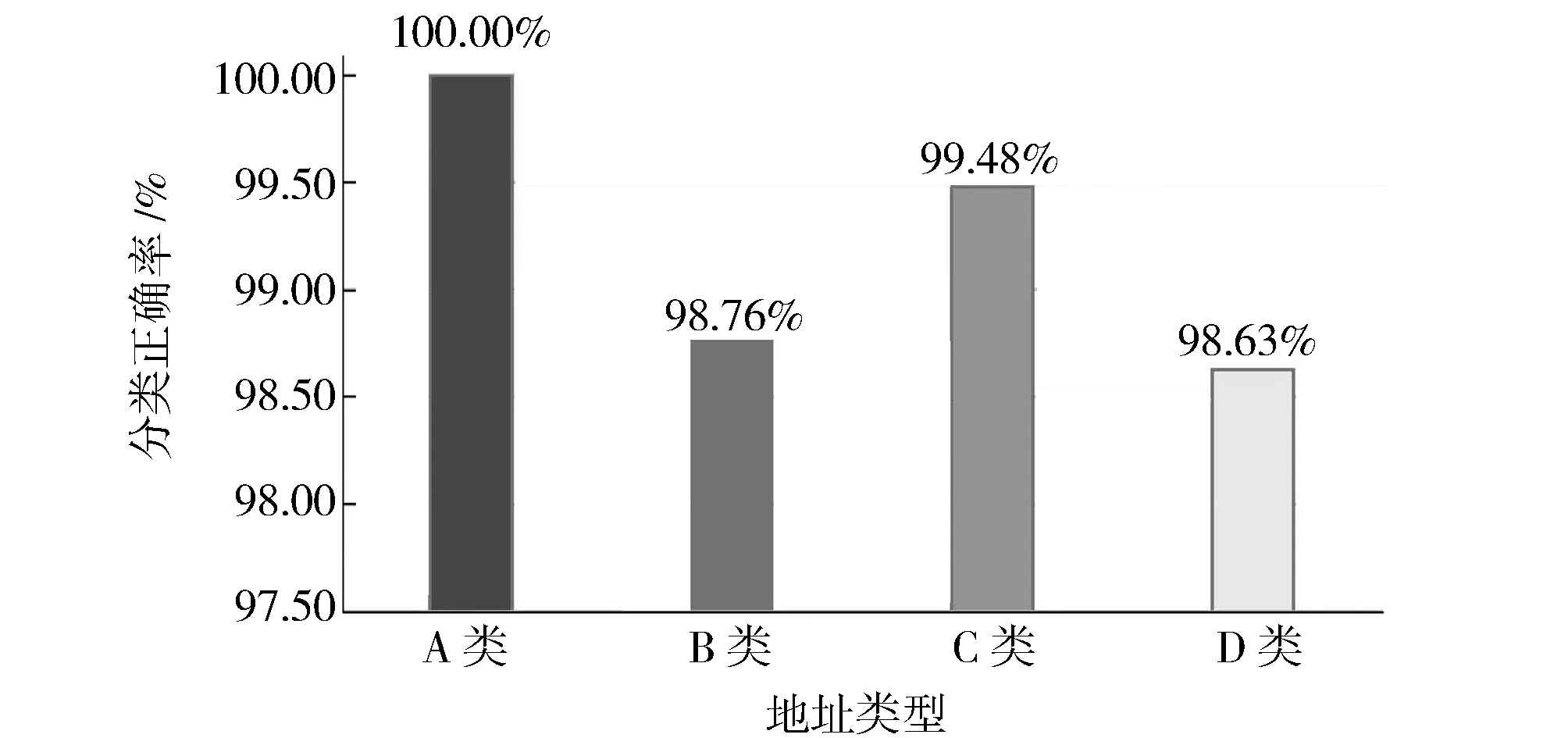
图4 IPv6地址的分类正确率Fig.4 Accuracy statistics of IPv6 address classification
5 结语
作为下一代互联网通信解决方案,基于IPv6的网络部署与应用已在迅速落地实施。鉴于地址生成方式的多样性,开展对IPv6地址分类识别的研究有助于未来的网络监管、安全评测等。本研究从地址生成模式入手,设计并实现了融合多特征的IPv6地址分类识别方法,并通过真实活跃的IPv6数据集证明了其有效性。
