基于多尺度特征迁移学习的步态识别研究
2021-10-28陈倩倩吴曙培西安工程大学电子信息学院西安710048
徐 健,黄 磊,陈倩倩,陆 珍,吴曙培西安工程大学 电子信息学院,西安 710048
随着我国智慧城市建设的深入,我国视频监控市场继续保持快速增长的态势。行人作为公共监控视频中的核心,如何在视频监控中对行人进行准确检测与有效识别成为当今研究热点。
人体步态识别作为一种新型生物识别技术,根据各人独特的行走方式来标记、描述和确定行人个体的身份。近代医学研究表明,步态是一种复杂的人类行为特征,人类的步态中存在24种不同的影响因素,如果将所有因素都考虑起来,则可以唯一地确定一个人[1],此项医学研究为步态识别提供了可能。
步态识别与人脸识别和指纹识别等其他生物识别技术相比较而言,步态识别的优势在于不需要当事人同意且无需身体直接或间接接触的情况下即可进行识别行人身份。同时,步态识别高度依赖于人体的全身身体特征和行走姿态,因此步态作为识别特征也很难被隐藏或改变。随着图像处理、模式识别及计算机技术不断发展,近些年一部分研究学者采用传统机器学习方法实现通过行人步态达到识别行人身份的目的。李凯等[2]提出用步态能量图作为步态的特征图像,利用受限玻尔兹曼机自动获取步态特征,并选取支持向量机、孪生支持向量机、神经网络与k近邻识别方法对使用受限玻尔兹曼机方法的提取的特征进行了研究。赵喜玲等[3]提出基于静态能量图和动态群体隐马尔可夫模型的步态识别方法,最后采用近邻法进行识别,极大程度减少了角度变化和噪声带来的影响,达到了较高的识别率。
近些年来,深度学习[4]发展迅速,在语音识别、机器视觉、图像识别等诸多领域取得了巨大成功。卷积神经网络(Convolutional Neural Network,CNN)是深度学习中一种端到端的人工智能模型,CNN在海量的Imagenet数据集上识别和检测达到了比人眼更高的识别率与准确率,但在实际学习工作中,由于往往不具备官方数据集那么大的数据量,因此应用于实际样本集时效果很差,通常表现为训练集识别率和测试集识别率相差甚大,也经常导致过拟合现象发生。Sinno等[5]提出迁移学习的思想,解决了样本数据量不够的问题,并且还可避免大量昂贵的数据标注工作。基于迁移学习的思想,龙满生等[6]将AlexNet模型在ImageNet图像数据集上学习到的知识迁移到油茶病害识别任务中,对于常见的5种油茶病害都达到了极高的识别率。罗娟等[7]采用深度卷积神经网络通过迁移学习分别训练植物的单个器官,并且结合多个神经网络的多线索进行植物识别,对传统植物都可以有效地自动进行识别。关胤[8]采用152层残差网络结构,在花卉数据集上对模型进行迁移学习训练,对于用户自主上传的花卉照片达到了较高的识别率。
针对当前公布的步态数据集,如果使用步态能量图作为网络输入,会导致样本集偏小易产生过拟合的问题。因此本研究引入深度迁移学习思想,利用VGG-16网络模型作为特征提取器,考虑到原网络提取图像特征时仅针对单一尺度这样会导致丢失部分图像细节信息,故在网络模型上融合空间金字塔池化网络(SPP)[9]优化算法,提取行人步态中的多尺度信息特征。最终提出一种基于融合空间金字塔池化微调VGG-16网络模型的行人步态识别方法。通过对比现有多种识别方法,该方法不仅避免过拟合现象发生,而且测试集识别率有所提升。
1 步态能量图
步态能量图是一种混合步态轮廓序列中静态和动态信息的运动模板,通过计算一个步态周期中步态轮廓图像素的平均强度得到模板中每个像素点的能量[10]。步态能量图提取方法简单,并且能较完整地表现步态的形状、速度等特征,因此行人步态识别过程中获取完整的步态能量图对整个识别过程至关重要。
1.1 步态周期
人体的步态被认为是具有周期性的循环运动,一个完整的步态周期是从一侧足的足跟着地到同一侧足跟再次着地为止的连续过程所用的时间。
步态周期常用的检测方法是基于人体侧影的宽高比法[11],对于一个连续的步态过程,人体的高度和宽度会随着身体的运动不断变化。
如图1(a)所示,当两腿分开的角度逐渐变大时,人体的宽度变大,高度变小,此时宽高比变大,当两腿逐渐靠近时,人体的高度变大,宽度变小,此时宽高比变小,因为整个步态周期呈现周期变化,因此宽高比变化也呈现周期变化。
图1(b)中的x点、z点与p点对应双腿并拢时所对应的宽高比曲线,y点、w点分别对应左脚迈出最大步伐时与右脚迈出最大步伐时所对应的宽高比曲线,由x点到p点即为一个完整的步态周期。
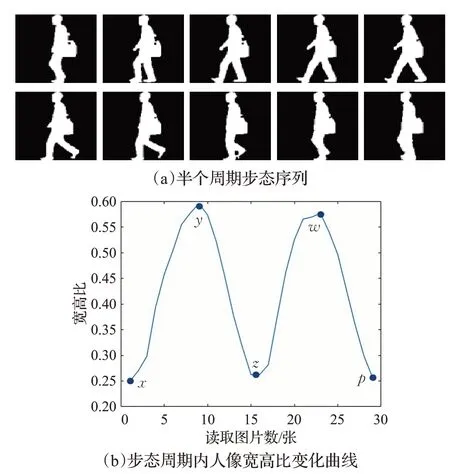
图1 步态宽高比变化曲线Fig.1 Variation curve of gait aspect ratio
1.2 提取步态能量图
相较于将步态轮廓图或者步态序列作为深度网络的输入,步态能量图将整个步态过程用一幅特征图像进行表示,保留了运动过程中的绝大部分特征信息,同时对于因某一帧轮廓图出现的轮廓分割变形而产生的噪声有很强的鲁棒性,并且卷积神经网络对于彩色图像十分敏感,网络会被彩色特征吸引,行人衣服变更会极大影响识别准确率,步态能量图能够忽视衣物背包和协变量的特征干扰,只关注步态特征本身,包括关节、身高、体型、行走的姿态等,因此选择将步态能量图作为深度神经网络的输入。GEI的定义如下:其中,N为单个步态周期内目标图像的总帧数,B t(x,y)是步态周期中的t时刻的二值步态图像序列,t代表步态周期中的第t帧。

一个完整周期内的人体目标图像合成步态能量图的过程如图2所示。

图2 合成步态能量图Fig.2 Synthetic gait energy map
2 识别算法模型结构
2.1 卷积神经网络
传统的机器学习识别方法,主要分为三个步骤:目标图像预处理、特征提取、特征处理,然后利用分类器等方法对特征向量进行分类操作。这种方法的弊端是每个过程需要人为参与费时费力且特征提取的好坏直接影响分类结果,而提取特征时需要工作人员丰富经验,且最终识别率有待提高。
而深度学习大大减少了发现特征的成本,其本质是可以利用庞大丰富的数据,自主学习图像深层特征,完成模型的训练,泛化能力更强,更容易应用于实际场景。卷积神经网络(CNN)是一种经典的深度学习模型,常见的卷积神经网络由输入层、卷积层、激活层、池化层、全连接层和最后的输出层构成,此网络可以有效地从大量样本中学习到相应的特征,避免了复杂的特征提取过程。
VGG-16[12]是2014年提出的一种经典卷积神经网络模型,相比之前其他网络模型,通过增加更多的卷积层来增加网络的深度,卷积层全部采用3×3小卷积核代替以往网络中的5×5大卷积核,多卷积核串联与池化层共同作用使得网络结构简单性能良好。其结构如图3所示。

图3 VGG-16网络模型Fig.3 VGG-16 network model
原网络输入采用224×224的RGB彩色图像,其中隐藏层主要由13个卷积层、5个池化层和全连接层组成。卷积层通过卷积运算完成特征提取工作,卷积核通过滑动窗口形式在输入图像中以确定的步长从左到右从上到下进行扫描,计算卷积核中的参数与输入图像卷积后的结果,每扫描完一张输入图像后输出一张特征图,再通过激活函数进行非线性映射后输出作为下一层卷积层的输入。卷积层的表达式为:

其中,为第n+1层第i个输出特征,f()为激活函数,M j为从第n层选取的若干个作为第n+1层输入特征图的集合,为第n层第i个输出特征为第n+1层的权值参数,为n+1层的偏置,∗代表卷积操作。
池化层又称为下采样层,对每个卷积后的特征图进行下采样操作,不仅减少了模型参数,加快网络运算速度,还能滤除部分图像信息,起到特征选择的作用,以此来提升网络泛化能力。
经过若干次卷积+激励+池化后,网络对前面提取的特征图进行“平展拉伸”,将其转换为一维特征向量,通过全连接层进行相互连接。为防止出现过拟合现象,采用Dropout方法随机丢弃网络中的部分神经元,稀疏全连接层,最后通过Softmax激活函数分类得到最终的输出,Softmax函数表达式为:

式中,z j表示第j个神经元的输入,n为输出节点的个数即样本类别数;j=1,2,…,n。
2.2 网络模型结构的改进
一方面由于经过一系列卷积池化操作后得到的特征信息较为单一,另一方面因为VGG网络需要输入特定尺寸图像,在检测其他大小的图片的时候,图像需要进行裁剪或者缩放,但是裁剪缩放会减少图像的全局特征信息,降低识别检测的精度。因此为了有效提取行人步态图像中的多尺度特征,本文通过将空间金字塔池化层融合到VGG-16网络结构中,对卷积特征进行不同尺度最大池化操作,并提取出每个尺度下的特征,然后将生成的多尺度特征根据网络需要聚合成特定维度,从而提高特征的空间尺度不变性。
本文融合的空间金字塔池化网络结构如图4所示。

图4 空间金字塔池化结构Fig.4 Space pyramid pooling structure
此池化结构将VGG-16最后一个卷积层(conv5)输出的512张特征图作为空间金字塔池化层的输入,此时对于每一张m×m的特征图可以划分为n×n的区域块,对于每一个区域块采取最大池化方式进行池化,其中池化层滑动窗口大小为ceiling(m/n×m/n),步长为floor(m/n)。本文中n分别取4、2、1,即将特征图分别划分为4×4、2×2、1×1共21个不同大小的区域块,将每个区域块中的最大值保留进行级联融合得到21×512的多尺度特征,最后将这个多维特征“平展拉伸”成一维向量送入全连接层用于后续分类工作。
2.3 深度迁移学习
迁移学习的初衷是节省样本标注时间,把处理源任务获取的知识,应用于新的目标难题。随着卷积神经网络的兴起迁移学习逐渐引起研究者的关注,并得到广泛应用。深度迁移学习即采用深度学习的方法进行迁移学习,相较于采用非深度学习方法拥有两个优势:自动化地提取更具表现力的特征;满足实际应用中的端到端(End-to-End)需求。其优点是可以对已有的知识进行利用,解决目标领域中标签数据匮乏的问题起到举一反三的效果,并且明显减少训练时间提高精度。结合本文步态识别过程中训练样本数据量较少的现状,将深度迁移学习思想用于本次研究,即可克服过拟合现象发生,提升识别率,加快训练速度。
迁移学习有域D和任务T之分,以小数据量的样本集作为目标域,以大量标注的数据集作为源域,针对不同的任务,常规的卷积神经网络都需要利用要识别的目标数据集从头训练,这是个很耗时间的任务且在数据集数量较小时极容易产生过拟合现象。因此可以根据源域与目标域的极大相似性,先利用源域数据训练神经网络,将学到的能力通过某种方式共享迁移至新模型,缩短目标域训练时间且提升识别率。迁移学习的方式有很多种,根据迁移内容的不同主要分为基于实例的迁移、基于特征的迁移和基于参数的迁移等。本文采用基于参数的迁移方式,将Imagenet数据集作为源域,行人步态数据集作为目标域,在融合SPP网络的VGG-16神经网络模型上进行预训练,迁移参数,目标域微调参数,达到最后步态识别的目标。基于改进VGG-16网络的迁移学习模型结构如图5所示。
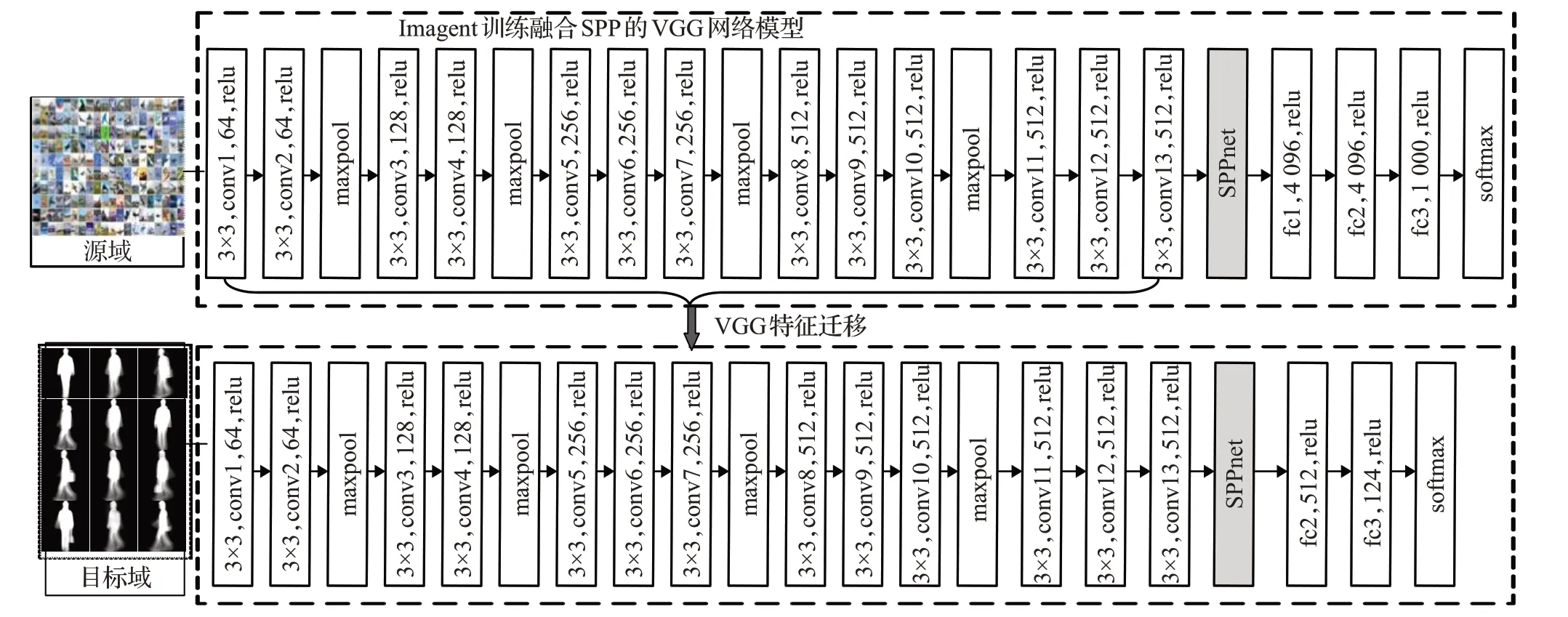
图5 迁移学习模型Fig.5 Transfer learning mode
首先将VGG-16网络模型最后的最大池化层去掉,用空间金字塔池化(SPP-Net)代替,且此时输入图像相比于原VGG网络不要求必须是224×224的RGB彩色图像,可以输入任意尺寸大小的图像以获得多尺度信息且维度固定的特征,其他网络参数不变,用于源域的预训练操作。将加入SPP的网络称为sppvgg网络模型。待该网络在Imagenet数据集上得到的损失函数值与准确率趋向稳定时保存全连接层前面的特征提取层权值参数。将改进的VGG网络结构中的全连接层神经元个数按本研究需要进行修改,第一层全连接层由4 096改为512,第二层根据行人步态分类需要改为124,去除了第三层全连接层,经过softmax函数得到124类行人结果的输出,将其称为Im-sppvgg网络模型。将该网络作为行人步态图像识别最终模型,在训练测试过程中由于神经网络中的卷积层和池化层主要承担着提取图像特征的作用,因此先将由源域训练获得的提取特征能力由sppvgg网络迁移至识别行人的Im-sppvgg网络中,然后将Im-sppvgg网络中卷积层池化层的权重参数“冻结”使其处于不被训练状态,再输入小数据量的行人步态数据集至Im-sppvgg网络中,微调网络中的全连接层参数使其具有分析识别行人的能力。
3 实验与分析
本文算法实验在Windows10操作系统下,CPU为Intel i7-7700K,GPU为NVIDIA gtx1080,16 GB内存,基于Tensorflow1.14深度学习框架,编程语言为python3.6。
3.1 实验数据集
本文采用的数据集是中国科学院自动化研究所提供的CASIA步态数据库Dataset-B数据库[13](多视角库)。此数据库提供了124位受测者在11种视角(0°,18°,36°,…,180°),在三种行走条件下(普通条件、穿大衣、携带包裹条件)的行人步态序列。此每种视角选取1个完整步态周期作为样本数据集,每一位行人包含110张图像,一共13 640张行人数据集图像。数据集存储了行人步态序列的二值图像,因为本文选择步态能量图作为深度网络的输入,所以对人体步态序列的预处理(目标检测、图像分割、图像归一化等操作)本文将不再论述。
按照前述获取步态能量图的方法获取每个行人样本的步态能量图,每位行人样本包含10个行走条件(2个穿大衣状态、2个携带包裹条件、6个普通行走条件),每种状态包含11种视角。部分样本如图6所示。

图6 行人样本集Fig.6 Pedestrian sample set
3.2 实验流程及实验参数设置
实验流程如图7所示,首先使用Imagenet数据集预训练改进VGG后的网络模型(sppvgg),然后保存在源域上学习到的权重参数,迁移预训练的权重参数并修改网络的全连接层,初始化参数后用行人步态图像样本训练修改后的网络模型(Im-sppvgg),微调全连接层的参数,经过softmax函数输出识别结果。在整个迁移学习过程中冻结的是预训练模型的低层网络参数,虽然Imagenet数据集中的图像和行人步态图像不一样,但是它们都是具有相似性的彩色图像,从大数据集学习得到的低层滤波器往往描述了各种不同的局部边缘和纹理信息,随着卷积层数增加学习的特征信息越来越抽象化,因此得到的图像滤波器更具有普适性。而最终本文只根据研究对象需要,修改全连接层,使其具备识别行人的能力。
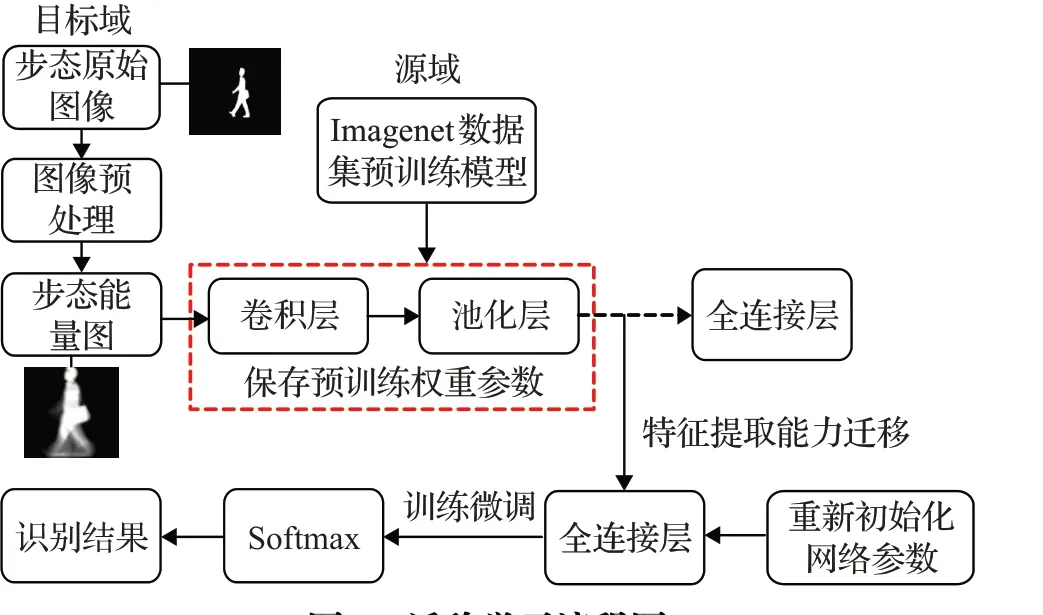
图7 迁移学习流程图Fig.7 Process map of transfer learning
本实验对迁移特征后的Im-sppvgg网络使用样本集共13 640张行人步态图像进行训练微调。
训练过程中,网络超参数如表1所示。表1中各参数具体含义如下:

表1 网络超参数Table 1 Hyper-parameter of netwrok
Epoch:网络训练迭代周期数,整个样本集数据被训练一次计为一个Epoch,一般取的数值能确保损失函数值和准确率值趋于最终稳定。
Batch_Size:每次输入神经网络的数据大小,每Batch_Size个数据输入后,进行一次梯度下降法对权重参数更新。
Optimizer:优化器,在比较SGD(随机梯度下降)等优化器所得效果后,最终选择了AdamOptimizer优化器。
Dropout:用于使全连接层的部分神经元失效,丢失一些信息,避免过拟合现象。本实验设置为0.8。
损失函数:训练过程中通过Softmax函数将神经网络的输出变成一个概率分布,使用交叉熵(CrossEntropy)作为网络的损失函数,交叉熵刻画了两个概率分布之间的距离,是分类问题中常用的评判方法之一。
当p表示正确答案,q表示网络预测值时,交叉熵可以表示为:

3.3 实验结果及分析
图8是使用本文所提出的深度迁移学习网络模型在源域学习到的特征提取能力应用在行人步态上所得到的部分卷积特征图。
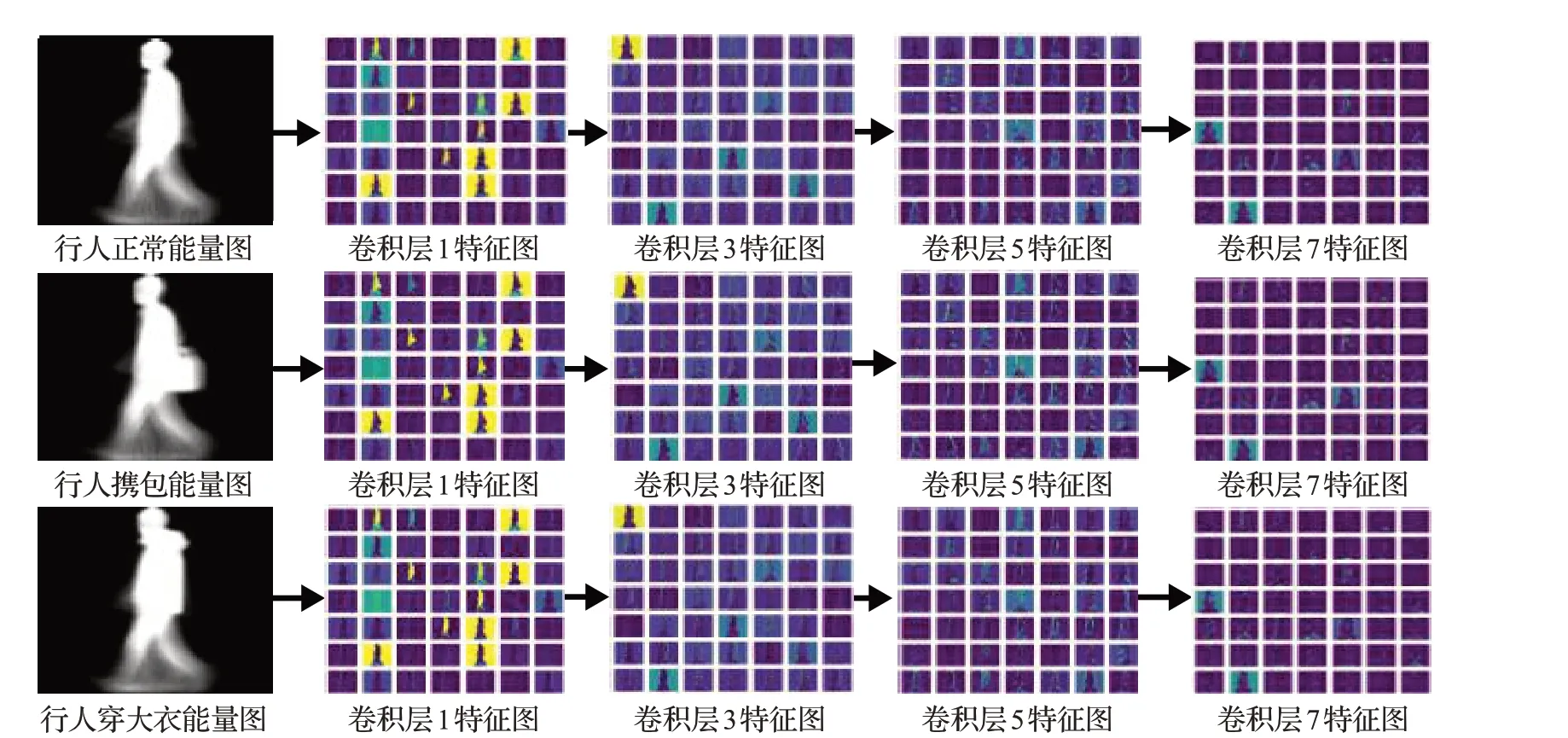
图8 卷积特征图Fig.8 Convolution feature maps
从图8中看出,随着卷积层不断加深,得到的特征图不断抽象化,在低层特征图可以明显看出行人具体纹理、边缘、形状等特征。在高层次特征图中行人图像已经很抽象,人眼无法看出具体内容,用来滤除不相关内容,提取重要特征。低层卷积核和高层卷积核的局部细节信息表明,卷积神经网络的低层特征抽象能力是可以共享的,因此使用ImageNet的大量数据训练基于VGG网络改进的Im-sppvgg网络能够更详尽、精准地学习到样本的抽象特征。总的来说,将已在ImageNet数据集上训练好的模型迁移到行人步态识别问题上能有效地提取图像的抽象特征,进而提高模型的泛化能力。
为直观描述网络模型的有效性,使用行人步态能量图样本集对模型进行训练,得到损失函数值及准确率曲线如图9所示。因本文网络利用改进的VGG网络在结合深度迁移学习思想构建而成。为客观比较本文所提网络的性能,对原VGG-16网络模型进行迁移学习,其损失函数值及准确率曲线如图10所示。其中针对本文Im-sppvgg网络输入图像无尺寸要求,而VGG-16需对输入图进行尺寸裁剪至224×224×3大小以满足网络要求。

图9 Im-sppvgg网络损失函数值和准确率曲线图Fig.9 Loss function value and accuracy graph of Im-sppvgg network

图10 VGG-16网络损失函数值和准确率曲线图Fig.10 Loss function value and accuracy graph of VGG-16 network
结果表明,图9的Im-sppvgg网络损失函数值下降很快,大约第300 iteration时损失函数值就趋向于0,准确率曲线大概在第300 iteration时趋向稳定,图中红色曲线代表行人步态图像训练集准确率,稳定后基本保持在100%左右,蓝色曲线代表行人步态图像测试集准确率,稳定后保持在95%左右。而基于VGG-16网络得到的图10中损失函数值下降较慢,大约在400 iteration才趋向于0。而在准确率曲线图中大约450 iteration时趋向稳定,此时代表训练集的红色曲线保持在100%左右,代表测试集的蓝色曲线保持在91%左右。直观上来看本文提出的Im-sppvgg网络模型在行人步态图像样本集上精度表现更佳,收敛速度更快。这是因为本文修改VGG-16网络时去掉网络最后的最大池化层用空间金字塔池化网络代替。正是由于这种结构上的改进,在Imsppvgg网络输入样本图像时,能够获取多尺度信息特征,使得识别精度提升。而在最后卷积层输出时,原VGG16网络设置三个全连接层,第一个全连接层FC1有4 096个节点,第二个全连接层FC2层有4 096个节点,第三层全连接层FC3有1 000个节点,因为原VGG网络输出的卷积特征共7×7×512=25 088个节点,而全连接层权重参数数目计算方法:前一层节点数×本层的节点数。所以原VGG16全连接层参数为:7×7×512×4 096=1 027 645 444,4 096×4 096=16 781 321,4 096×1 000=4 096 000共1 048 522 756个权重参数。
而本文在改进的VGG16网络中,经过空间金字塔池化后输出(1+4+16)×512共10 752个参数,所以修改后2层全连接层的权重参数10 752×512=5 505 024,512×124=63 488共5 568 512个权重参数。
较多的权重参数在小样本集上会产生过拟合现象,同时会导致训练时间过长,内存消耗量大,存储容量大等问题。正是不丢失特征信息的参数减少使得网络收敛更快且提高行人步态的分类性能。
本文将实验数据随机打乱分为训练集、测试集及验证集,随机打乱以消除过拟合现象,其中70%作为训练集,10%作为验证集,20%作为测试集。评价指标使用平均识别率(ARR)。ARR表示正确识别的目标人物数占总数的比例,ARR的值越大表明识别率越高,算法性能越好。

为了客观对本文算法进行分析,将本文算法与其他步态识别算法进行比较,表2列出了不同方法平均识别率。

表2 不同算法性能比较Table 2 Comparison of performance of different algorithms %
从表2对比其他几种文献针对行人步态识别的正确识别率可以看出,本文提出的算法识别性能总体较好,识别率更高。文献[14]采用融合策略将通过数据降维后的步态能量图、梯度直方图、小波描述子和部分图像信息熵特征进行融合后完成步态识别任务,虽然与单一步态特征的识别方法相比,步态识别率有明显提高,但是融合后的特征权重仍通过融合前的单一特征的识别率决定,缺乏特征之间的关联性以及特征个异性在识别过程中的体现。文献[15]采用分解能量图与频谱分析构建步态特征,此方法提取的特征降低了数据复杂度并且能较完整表达行人个体的步态信息,在CASIA步态数据库上达到较好的识别性能。文献[16]在步态能量图的基础上分三层求得目标图像的局部二值模式(LBP)与方向梯度直方图(HOG),使用特征融合的方法每一层的LBP特征和HOG特征进行融合得到最终的特征进行实验验证,在CASIA与USF数据集上都达到较好的识别率。根据分析可知这些方法都是基于传统机器学习方法,采用融合策略融合几种行人步态的图像特征,对融合后的特征进行分类。
传统机器学习方法避免了深度学习大规模参数运算弊端,使得测试时间较短。但在整个提取特征信息时需要人为时刻参与费时费力,并且这种基于单一特征或多种特征的识别算法丢失了大部分步态过程中的信息。算法4采用的是原始VGG-16神经网络模型,从训练集和测试集识别精度可以看出,在不加修改的经典网络模型上直接用小数据量的能量图作为输入极易产生过拟合现象,这也符合实验之初的设想,因此本文提出采用深度迁移学习的方法。算法5是在VGG-16网络模型结构上采用深度迁移学习方法,相比于算法4消除了过拟合现象,使得测试集精度大幅度提升。而本文算法在算法5基础上,进一步改进,结合空间金字塔池化思想,摆脱VGG-16网络模型对于输入图像尺寸要求的束缚,不仅获得多尺寸多维度信息特征提升识别精度,还使得全连接层权重参数减少,加快算法训练和测试时间。
4 结语
针对使用步态能量图作为深度卷及网络的输入,会导致样本集偏小易产生过拟合的问题。本文在VGG-16网络结构基础上进行改进,将大规模数据集训练该网络后将学习得到提取能力迁移,再用行人步态样本集微调网络,用于识别研究。根据行人步态训练集精度和测试集精度曲线,证明该网络识别的有效性。通过对比其他识别算法精度,本文算法的识别率均高于其他算法,证明该网络的优越性。本文算法的提出,不仅克服了传统机器学习方法识别率低,需要人为时刻参与的弊端,而且解决了深度学习在小数据集上产生过拟合现象的问题,在CASIA跨视角跨穿着步态数据库上对本文算法进行实验,结果表明此方法是一种有效的步态识别方法。
