采用隐式跳转的控制流混淆技术
2021-10-28陈耀阳
陈耀阳,陈 伟
南京邮电大学 计算机学院,南京 210023
近年来,随着计算机技术的发展,针对软件本身的保护逐渐引起人们的关注。对于软件的攻击形式有很多种,一般而言,软件保护技术主要对以下三种类型[1]的攻击进行防护:软件盗版、逆向工程以及软件篡改。在这几种攻击中,逆向工程是相对比较基础同时也是危害性最大的一种攻击形式。
逆向工程[2]是指对一项目标产品进行逆向分析和研究,在无法轻易获得必要产品信息的情况下,直接从成品分析,推导产品的设计原理。在计算机领域中,特别是针对程序的二进制代码进行的逆向工程也称“代码逆向工程”。一次成功的逆向,对于竞争者而言可以轻易获取产品中的敏感数据、算法以及设计思想;而对于恶意攻击者来说,则可以获取到软件中漏洞,从而加以利用,造成严重后果。
静态分析往往是逆向分析的第一步。以Java为代表的语言,需要编译成与平台无关的字节码形式,所以可以通过解析字节码文件轻易还原出源程序的实现信息。而对于以C语言为代表的需要编译成机器码的语言,也可以通过翻译机器码从而转化为汇编指令来进行代码分析。所以,通过静态分析可以轻易地构建软件的控制流信息,未经保护的控制流信息暴露了包括源程序静态结构、代码逻辑在内的大量信息,因此对于许多逆向工具而言,控制流图都是必须构造的数据结构。本文研究的主要目的是抵御静态代码分析。
抵抗静态代码分析特别是控制流分析的主要技术是代码混淆,这个概念最早由Collerg等[3]提出并加以分类及实现。代码混淆技术是将一些结构良好、易于理解的代码转换为难以阅读分析的代码,但是还能完整地保留其所实现的功能,著名的国际C语言混乱代码大赛[4]就是典型的例子。一般而言,混淆技术可以分为4类:结构混淆、数据混淆、控制流混淆以及动态混淆。其中控制流混淆的主要目的就是抵御逆向工具对代码控制流信息的分析,目前应用比较广泛的控制流混淆技术有指令替换、虚假控制流、控制流平坦化等。但是目前这些技术都存在一些缺点,如通用性差、性能消耗过大、控制流信息隐藏不彻底等。
鉴于这些现状,本文提出一种通用的、轻量级的、细粒度代码保护方案。通过对代码的控制流信息进行分析并建立原始控制流图,之后从基本块跳转、函数调用与变量引用入手,隐藏这些敏感信息,减少静态分析时所能获取到的有价值信息,实现对程序的保护。同时通过构建状态转移模型和实施基于环境密钥的两阶段加密方案,解决了密钥安全和密文重复出现问题,弥补了其他方案的不足,提高了软件保护的能力。
1 相关工作
代码混淆的概念由来已久,在20世纪90年代末这个概念就已经被提出。它的形式有很多,其中最简单的一种形式是符号混淆,它通过将源码中的函数名、类名以及变量名替换成一些无意义的符号,来增加攻击者的理解难度,具有代表性的项目是ProGuard[5],由于其并不改变原代码的结构,其抗逆向能力非常差,所以现在多作为一种优化工具或者其他混淆技术的辅助工具来使用。
由于简单的符号混淆并不能满足代码保护的要求,一些研究人员又提出了结构混淆的概念。结构混淆是从代码的类、函数等组成入手,破坏其整体结构,增加静态分析的复杂度。这方面比较典型的是Foket等人[6]的研究成果,他们以Java语言为例阐述并实现了包括类继承结构平坦化、方法合并、接口合并以及对象创建工厂化在内的多种结构混淆技术。虽然结构混淆能起到一定的抗逆向效果,但是其混淆的粒度较大,实际的逆向工程中,攻击者很少会逆向全部代码,一般都是从一部分关键代码入手,也被称为“局部攻击”,这时就需要更细粒度的混淆。
控制流混淆是目前较为流行的方案,它通过修改程序控制流来阻碍攻击者对代码进行静态分析。常用的控制流混淆技术主要有同义指令替换、不透明分支以及控制流平坦化以及等。
同义指令替换[7]多是将一些简单的指令替换为有相同功能但形式非常复杂的指令,来增大代码理解难度,如公式(1)所示;但是这种混淆方法有很大的局限性:首先并不是所有的指令都可以替换,多用在算术运算上;其次一般所替换的指令都比较复杂,也降低了程序的性能。

虚假控制流又称为插入不透明谓词[8],它通过在程序的控制流中插入一些结果恒定的布尔表达式来引入虚假分支,如图1所示;由于被插入的布尔表达在运行过程中值恒等不变,所以虚假分支并不影响程序运行,所以这是一种低成本高收益的混淆技术。生成虚假控制流的不透明谓词可以分为静态不透明谓词[9]、上下文不透明谓词[10]以及动态不透明谓词[11]等。但是由于不透明谓词插入后的特征比较明显,现在已有很多方案[12]可以去识别和去除。虚假控制流混淆虽然改变了代码的控制流信息,但只是在局部上的修改,难以全局应用,并且过多的不透明谓词也会大幅降低程序性能。

图1 虚假控制流Fig.1 Bogus control flow
控制流平坦化[13]混淆如图2所示,是通过构造分发器,将原本控制流重构为一个类似switch-case的结构,由分发器在运行时决定下一个将要执行的基本块。这样可以彻底打乱原有的控制流图,具有很强的反逆向能力,但是这种方法只是将控制流信息从形式上打乱,其实际的控制流信息还是不变,通过分析case的值,也可以局部或者整体还原代码的控制流信息,重构原始的控制流图。

图2 控制流平坦化Fig.2 Control flow flattening
前面介绍的控制流混淆方案大多都是通过引入额外基本块来修改源程序控制流图中基本块之间的关系,从而实现代码混淆。除此之外,还可以通过修改基本块的跳转形式来实现这个目的,也就是将显示跳转改为隐式跳转。隐式跳转又称间接跳转,是将源程序中的直接跳转形式改为间接形式,这样无论是反编译工具还是人为分析,都不能轻易分析任意基本块的前后关系,这样也就阻止了静态分析,实现了程序保护。这方面比较典型的是Hikari[14]项目,它通过将程序中跳转指令的目标地址由明文改为数组匹配的方式来实现隐式跳转。但作为一种混淆策略,其实现形式过于简单而导致安全性较差(详见2.1节分析),同时也仅处理了基本块之间的跳转,对于其他敏感信息并未做相关的安全保护,所以在实际应用中价值较低。
2 基于隐式跳转的混淆技术
前一章介绍的几种代码保护技术中,都只是在宏观上对控制流进行修改,实际各个基本块之间的跳转关系还会保留,而且也不能保护函数调用以及变量引用这些敏感信息。因此,本文通过隐藏基本块之间的跳转关系,并在此基础上对程序其他敏感信息如函数的调用以及变量引用也加以隐藏,从而实现程序的控制流混淆,以此来保护程序。
2.1 基本概念
控制流图是一个程序的抽象表示,最早由Frances E.Allen提出,它利用图的形式将一个程序的所有可能执行路径表示出来,不仅是静态分析的重要工具,也是现代编译器所需要维护的一种重要数据结构。一个控制流图可以表示为
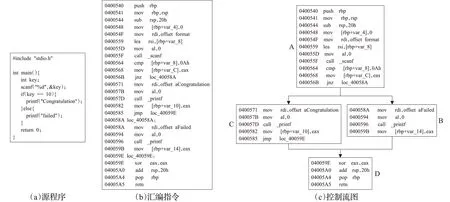
图3 控制流图示例Fig.3 Example of control flow graph
在控制流图中,控制流从一个基本块到另外一个基本块的转移多是通过一系列跳转指令实现,所要跳转的目标地址在原始情况下是以明文方式作为指令的操作数出现的,这样的跳转形式称之为显示跳转,以图3(b)为例,一共出现了两个跳转指令,分别是地址为040056B处的条件跳转指令和地址为0400585处的无条件跳转指令,这两条指令的操作数都是直接的明文地址(图中显示的是LABEL伪指令,表示的是某个地址,目的是便于阅读),由于是明文地址,无论从哪一个基本块开始都可以轻松地推断出程序接下来的流程。
与显示跳转对应的是隐式跳转,这种形式下,跳转的目的地址需要通过一系列计算得出,图4所示的是图3(a)中的代码经过Hikari的间接分支处理后的部分汇编代码,对应的就是图3(c)中的基本块A,但是与之不同的是图4中的基本块最后的跳转指令的操作数并不是一个直接地址,而以一个寄存器表示,根据寄存器中存储的值,去跳转的相应地址,至于寄存器中所存储的地址则是在跳转前计算出来的,这就是隐式跳转的一种形式。这里所做的处理是将某个基本块的所有可能后继基本块插入一个全局跳转表中,然后修改原始基本块的内容,将原来的明文地址替换为数组寻址的方式,如图4中地址0400575处所示。这种隐式跳转方法,由于隐藏了目标地址,所以一些工具如IDA Pro[15]就不能通过静态分析去构建程序的控制流图,仅能显示如图4所示的控制流图的第一个基本块。

虽然这种形式的隐式跳转虽然能在一定程度上阻碍控制流图被构建,但是若对跳转前部分指令的含义进行简单分析还是可以推断出该基本块的后继。以图4为例,在输入值与10做减法之后,根据EFLAGS寄存器的ZF标志位的情况,在_LcondInBrTable数组中取不同的值存入rsi寄存器中进行跳转,由此知道当输入等于10时,取数组中第二个元素,否则取第一个元素。而_LcondInBrTable数组中存储的都是明文地址,由此还是可以构建出局部或者全局的控制流图。
2.2 控制流的隐式跳转
前一节中Hikari实现了较为初级的隐式跳转,但是依旧是将地址明文存储到全局跳转表中,这样的效果等同于做了一次稍微复杂的间接寻址,虽然可以欺骗一些静态分析工具,但是并没有达到理想的保护效果。本文通过对地址加密来增强保护,但是由于对软件的静态分析是处于一种MATE[16](Man At The End)环境下,此时攻击者完全掌握软件运行环境,可以对软件进行彻底的反编译和监控,传统的加密并不能明显提升保护效果,所以本文通过构建状态转移模型来确保密钥安全,利用二者的结合来实现代码保护。
S:状态集合;
S0:初始状态;
I:输入集合;
O:输出集合;
T:转移函数,描述系统中各个状态之间转移的规则;
G:输出函数,描述系统在状态转移后的输出。
首先定义一个程序控制流图由n个基本块构成:,控制流图的入口为BB0。假设控制流内部的跳转是根据基本块的地址定位的,第i个基本块的地址表示为Ai,该地址对应的加密后密文表示为,其对应的密钥表示为key i,密钥是在编译期随机生成的,不直接存储在代码中。
系统的各部分定义如下:系统的状态集合即为全体密钥的集合S={}key i|0≤i≤n,当程序要从BB i跳转到BB j时,系统的当前状态即为k eyi,将来状态为key j,系统的初始状态为key0;系统某次状态转移时的输入由两部分组成,一部分用于计算新状态,定义为k ij,该值直接存储在BB i中;另一部分用于计算输出,即BB j的密文;故系统的输入可以用如下二元组的集合表示,系统在转移后的输出即基本块地址的集合,O={A j|0≤i≤n}。
系统的输出函数描述的就是状态转移后系统产生的一个输出,这里以输入的密文以及当前状态为参数并输出基本块地址,所以输出函数就是解密函数,它和编译时的加密函数互为反函数。若加密函数定义为如下形式:

则输出函数的形式为:

关于加解密函数的具体实现没有特殊要求,但是由于需要在指令层面进行运行时解密,为了保证运行时性能,要尽量选择运算量少的算法,如异或运算。
系统的转移函数描述了状态转移规则,其形式如下:

转移函数实际上是以迭代的形式描述了如何从一个状态转移到下一个状态,这种形式的定义可以保证在静态分析时中间状态的隐蔽性,从而间接保证目标地址的安全。攻击者在对程序进行静态分析构建控制流图时,由于完整的控制流图一般都比较庞大,构建起来耗时耗力,所以攻击者一般更愿意从某个感兴趣的基本块入手,构建局部的控制流图,此时需要完成的目标有如下两点:
(1)确定某个基本块的所有直接后继块;
(2)确定某个基本块的所有直接前驱块。
在未处理之前,指令中所有目标地址都是明文出现的,所以目标1可以通过分析基本块中的跳转指令及相邻基本块的逻辑关系而实现,目标2可以通过匹配全局的绝对跳转地址和相对跳转地址来实现。在使用本文方案之后,联合转移函数与输出函数,若从BBi转移到BB j,目标基本块地址需要经过如下计算:

当攻击者从控制流图中某一基本块开始静态分析时,所能获取到的信息只有该基本块的地址A i,以及所有可能的k ij和。由公式(5)可知,还缺少参数keyi,而keyi是系统的当前状态,它在程序中的表现是一个可读写的全局变量,它随着控制流的转移而更新,而直接从中间某一基本块入手时,是无法直接获得当前基本块对应状态值,所以不能计算出下一基本块的地址,这样目标1就很难完成。另外,由于在基本块中,原始状态下所有目标地址都是以密文形式呈现的,当攻击者知道某一基本块的明文地址,而要计算对应的密文地址时需要进行如下式的运算(假设BB k是BBi的一个前驱块):

根据系统的状态转移模型,key k是在执行到基本块BB k时的状态,k ki的值也仅存在于BB k内部的,所以在前驱块未知的情况下,想要计算当前基本块对应的密文信息,以及以此为基础去寻找所有前驱块是比较困难的,所以目标2也难以实现。
前文分析了模型在抵御静态分析时的能力,证明了当从控制流图的非起始位置入手时,并不能有效地还原出程序的控制流图。但是,当从控制流入口开始静态分析时,系统状态能否安全地初始化决定了程序控制流图能否被顺利构建。目前,程序中类似的安全初始化问题依旧是亟待解决的,不过一些现有的方法可以在一定程度上解决这个问题,如白盒加密、外部输入以及从环境元素生成状态信息等。即使在无法保证安全初始化的情况下,在经过本方案处理过之后,攻击者也只能从控制流图的入口开始分析,当程序足够庞大时,这将是一个漫长的过程。另外本方案关注于隐藏控制流的跳转信息,所以可以通过增加冗余的虚假基本块、对基本块进行分裂或者结合已有的控制流混淆技术来增大静态分析的难度。
2.3 隐式调用与隐式引用
除了控制流信息是抵抗静态分析时需要保护的信息,函数的调用与变量的引用也是一类需要保护敏感信息。例如通过对关键函数的调用及特殊字符串的搜索可以快速定位到关键部分,提高静态分析的效率。传统的关于这两类信息的保护都注重于内容的保护,如对函数进行包装、对字符串内容加密等。这样的处理不仅有较大性能损耗,同时也并不能达到理想的效果。本文在隐式跳转的基础上从对象与指令间的关系入手对这两类信息进行保护。
与基本块的跳转类似,在指令层面函数的调用与变量的引用都是以地址为基础。如图3(b)中的几处call指令和包括0400571地址在内的几处变量引用指令,都是把目标对象的地址直接作为操作数放在指令后。所以可以推广隐式跳转的思想,将对应的地址加密隐藏,实现函数的隐式调用和变量的隐式引用。同样在上一节构建的状态转移系统的基础上,依赖系统当前状态与输入参数在运行时解密出真实地址,而不直接存储密钥,使得静态分析时无法确定真实地址,以此切断相关对象和程序的关联,也就无法利用特殊的函数和变量去定位关键逻辑。另外,也可以插入相似的冗余函数和变量,进一步干扰攻击者的静态分析。
2.4 环境密钥与两阶段加密
前文介绍的模型虽能较好在静态分析时保护程序各种敏感信息,但是各种加密行为都是在编译期完成的,所以在后续的指令修改中,同样的密文可能多次出现,这样做是有一定风险的。如在基本块的隐式跳转中,若BB j是BB i的直接后继,虽然在BB i中无法直接计算出BB j的实际地址,但是将会出现在所有BB j的前驱块中,此时通过搜索可以找到BB j的所有前驱节点。同样的问题也出现在函数隐式调用与全局变量隐式引用的处理中,利用对密文的全局搜索可以找到调用相同函数或引用相同变量的所有指令,再结合一些统计学的知识,还是可以获取一些有价值信息。
为了解决这个问题,这里引入环境密钥与两阶段加密的概念,基本思路是在不同环境中(即不同的基本块中)表示出不同的密文。以基本块隐式跳转为例,除了使用主密钥keyi,还需要一个环境密钥ckeyi,每个基本块对应一个环境密钥,为了保证唯一性,比较简单的就是取基本块的地址作为环境密钥。在编译期进行加密时使用两个加密函数进行两阶段加密,分别是使用环境密钥进行的预加密和使用主密钥进行的正式加密,这里定义预加密函数如下:

预加密函数需要保证在给出相同的A i,对于任意两个ckey j,其结果一定不相同。此时结合2.2节中定义的加密函数,完整的加密运算如下所示(表示BBi的地址在BB j环境下所对应的密文):
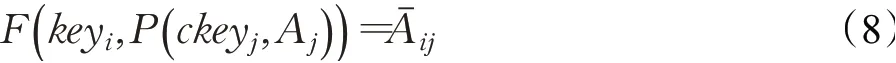
注意这里选取的预加密函数P可以和F一样,但要保证函数对解密顺序敏感,也就是解密时若先用环境密钥再用主密钥时不能获得正确结果,以防静态分析时可以对密文进行预处理。在公式(8)中对于同一明文A j,对应不同的ckey j则有不同的结果,也就实现同一个基本块在不同的环境下展示不同的密文。
同样对于函数的隐式调用和全局变量的隐式引用,也可以使用环境密钥和两阶段解密实现密文不重复出现。但是对于这两者,还存在一种特殊情况,也就是在同一个基本块内多次调用同一个函数或引用同一个全局变量,这样仍然会出现密文重复,有效的解决方法是对基本块进行分裂,在两个相同的函数调用或者变量引用之间插入无条件跳转指令,将一个基本块分裂为多个基本块,保证两次相同的调用或引用不出现在一个基本块内,再进行隐式转换,就可以保证密文的唯一。
利用环境密钥的两阶段加密没有必要对全部对象都使用,在使用前可以统计对象在源程序中的出现次数,若仅出现一次,就可以省去两阶段加密以减少性能损耗。
3 实验分析
为了评估本文所提出的方案,这里选取了一些样本进行测试,并与原始程序和其他已有方案进行比较从而得出结论,本文的方案实现是基于OLLVM[17]实现的。
3.1 测试样本与实验环境
本文从编译后程序的空间开销和时间开销两个维度进行测试。这两个维度使用不同的样本集,分别是GNU Coreutils[18]内的部分模块以及排序、散列、加密以及压缩等领域中有代表性的程序,样本源码语言都为C语言。另外关于方案的正确性与通用性可以通过观察样本是否能正确编译以及正确执行来判断。具体样本信息如表1所示。
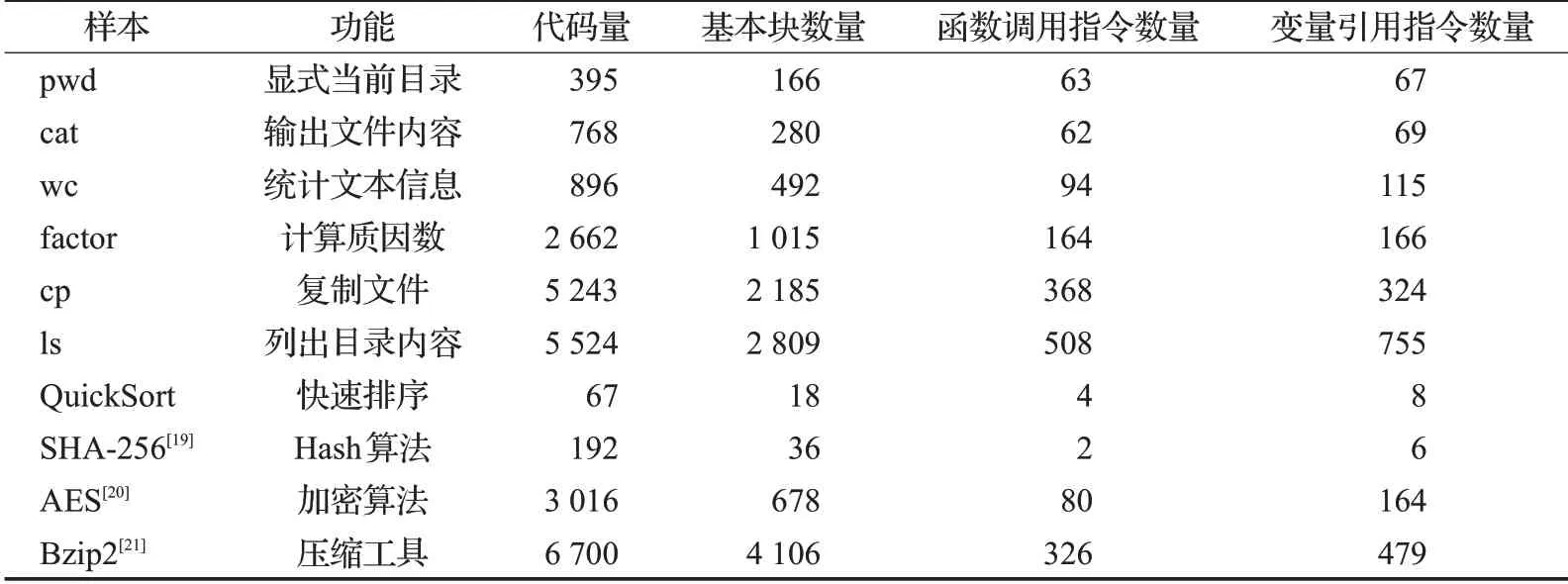
表1 样本详情Table 1 Sample details
在实验中分别对每个样本都进行如表2所述的几组实验。

表2 实验内容Table 2 Experiment details
其中实验B、C因为可以实现类似效果,所以有较直观的对比。本次实验的环境如表3所示。

表3 实验环境Table 3 Experimental environment
3.2 结果与分析
按表2描述的四种处理方法对10个样本进行编译,首先各个样本均能通过编译并正常运行,这一点说明本文方案对一般源代码程序的处理具有较好的通用性和正确性,具体编译后可执行文件的大小如表4所示。

表4 可执行文件大小Table 4 Executable file size Byte
通过表4可以看出,任何一种处理手段都会伴随出现文件体积增大现象。其中,仅做控制流隐式跳转处理的对照组中,文件体积平均增大29%左右,在此基础上若对函数调用与变量引用也做处理,文件体积再增加15%左右。
通过分析编译后程序的汇编指令,可以得出文件增大的原因。以实验B为例,若要实现一个简单的无条件跳转指令从显式到隐式的转换,需要在基本块中添加:当前系统状态读取、辅助变量读取与密钥计算、密文读取与解密、系统状态更新以及跳转指令替换等操作,在实际转换中,这些操作将在原基本块中增加约10条指令。另外,对于有条件跳转指令及函数调用指令等一些较为复杂的指令,在实际转换将会增加更多指令。其次,随着基本块数量的增多,控制流图中边的数量也越多,要转换的指令也越多,所以编译后文件体积会有一定的增加。
虽然本文方案最后文件体积会有一定增加,但相比控制流平坦化而言,在达到类似效果的基础上,实际实验中二者文件的体积上并没有明显的差异。而且原始的控制流平坦化方案只是在形式上打乱了控制流,若要更加安全地保护控制流信息则需要对分发器的逻辑复杂化,这样只会进一步增加文件体积。
实验的第二项内容是测试经过处理后程序的性能对比,关于性能可以通过程序运行时间得到直观的表现。这里对后四种样本进行测试,其中每组实验之后得到的二进制文件都执行如表5所示的一定操作并记录执行时间,重复执行100次,最后取平均时间。

表5 操作详情Table 5 Operation details
各个样本的最终运行时间如图5所示。

图5 运行时间Fig.5 Execution time
通过图5可知,在经过控制流扁平化处理之后的程序耗时是最多的,本文所提供的方案中,若只进行控制流隐式跳转,则平均增加了44%的耗时,若全部处理,则再增加约15%的耗时,虽然最后运行时间相对原始程序都有一定增加,但是相对于控制流平坦化,执行耗时上平均减少约23%,有较大的提升。
通过前面的分析可知由于增加了额外指令,所以在运行时不可避免地增加了运行时间。虽然本文所提方案与控制流平坦化方案都是通过增加额外指令实现控制流混淆,但是本文所增加的额外指令都直接插入到原始的基本块中,而且与原基本块内的指令在地址上是相邻的,同时大多数是一些简单的数据存储指令。而控制流平坦化方案中由于汇编指令无法直接实现类似switch结构的分发器,所以只能通过增加大量子分发器将控制流图转为一个多层的树型结构,这样控制流从主分发器出发,要通过大量子分发器经过层层比较与跳转才能到达源程序的有效逻辑块,另外这些子分发器在地址上多数都是不相邻的,也会造成一定影响。所以相比较来看控制流平坦化方案比本文的方案会造成更大的影响。
通过上面两方面的实验可以得出,不管何种保护方法都是有一定负面效应的,不过这也是不可避免的,由于在实验中默认对全部代码都进行保护处理,所以影响比较明显,实际过程中可以有选择性地对关键代码进行保护处理,从而降低对性能的影响。
4 结束语
本文提出并实现了一种采用隐式跳转的控制流混淆方案,它不仅能隐藏程序的控制流信息,同时也能保护包括函数调用及变量引用在内的多种敏感信息,增强程序的抗静态分析能力。由于是建立在抽象的控制流图基础上,所以该方案不受具体编程语言及代码结构的限制,也不需要对源码进行任何修改,是一种通用的控制流混淆方案。并且还能结合已有的混淆方案保护实现更好的保护效果。未来的研究工作将从如下两点进行:首先是优化状态转移系统进一步减小编译后文件体积的大小;其次是优化转移函数和输出函数,使性能损耗降到最低。
