面向实景的单图三维重建算法研究
2021-10-28韩煌达张海翔马汉杰蒋明峰
韩煌达,张海翔,马汉杰,蒋明峰,冯 杰
(浙江理工大学 信息学院,浙江 杭州 310000)
0 引言
在计算机视觉领域,基于图像的三维重建十分具有挑战性。目前,研究者使用的方法可分为多目图像重建和单图三维重建。前者需要从多个角度对物体进行测量,因此成本较高;而后者只需要单幅图像作为输入,十分便捷,可用于机器人、无人驾驶等诸多领域。随着深度学习的快速发展,一系列基于不同三维表示方法的单图三维重建网络被提出,这些网络能较准确地重建出物体的三维形状,但是它们都是在如ShapeNet 这样的合成基准上开发的[1]。ShapeNet 数据集的渲染图像由孤立、处于中心位置的物体组成,并且图像没有背景。因此,这些网络在面对更为复杂的实景图像中的物体时无法重建出令人满意的三维模型。
面对实景图像中的物体,Yao 等[2]使用从目标检测网络中获得的掩膜图和包围框,通过预测物体的三维属性对基础三维网格进行形变,从而生成和操控三维模型,这些研究的重心在于对物体的三维操控;Wu 等[3]训练一个3DVAE-GAN 进行三维模型重建,但所用图像经过人工裁剪,使物体处于图像中心位置。此外,生成的模型分辨率较低;Gkioxari 等[4]结合目标检测网络,提出了Mesh R-CNN。该网络首先预测出一个粗糙的体素表示,之后将其转化为初始网格,再通过Scarsellif 等[5]提出的图卷积网络对初始网格进行形变从而生成三维模型。该网络能准确地从实景图像中重建三维模型,是目前较为有效的方法。然而,由于体素表示法的固有缺陷,该网络重建出的三维物体分辨率仍然较低,并且视觉质量不高。
基于这些问题,本文提出IM-RCNN,该网络可以准确地检测出实景图像中的多个物体,并重建出高分辨率、高视觉质量的三维形状。本文的主要贡献在于:①面向实景图像,结合Mask R-CNN[6],提出一种基于隐函数的单图三维重建网络结构;②IM-RCNN 经过训练,在CD(Chamfer distance)、NC(Normal consistency)、AP(Average Precision)指标上的表现优于目前最好的方法,且重建的三维模型具有更加平滑的表面和丰富的细节。
1 相关工作
主要阐述目标检测网络和单图三维重建方法研究进展情况。
1.1 二维目标检测
近年来二维目标检测技术快速发展,Girshick 等[7]首先提出了R-CNN,在PASCAL VOC 2012 数据集上,将目标检测指标mAP 提升到了53.3%,超越了之前的目标检测算法。随后又在R-CNN 基础上提出了Fast R-CNN[8],在提高训练和测试速度的同时获得了更高的mAP;Ren 等[9]提出了Faster R-CNN,针对Fast R-CNN 网络在提取候选区域时出现的计算瓶颈,提出一个区域建议网络(RegionProposal Network,RPN),该网络与目标检测网络共同使用输入图像的卷积特征图,能够几乎无成本地输出候选区域;Redmon等[10]提出YOLO。与Faster R-CNN 等基于候选框的目标检测算法不同,这里将目标检测看成一个回归问题,输入的图像经过一个单独的端到端网络便能输出包围框和类别;Mask R-CNN 对Faster R-CNN 已有的包围框分支进行扩展,增加了一个预测物体掩膜的分支。这些目标检测网络能够准确地识别物体并使用包围框、掩膜等进行定位,但它们的输出仅仅局限在二维空间中。本文网络不仅能够输出物体的类别、包围框、掩膜,还能够输出实景图像中多个物体的三维模型。
1.2 单图三维重建
与二维图像不同,三维形状不局限于一种表示方法,因此近年来出现了各种基于不同三维形状表示方法的单图三维重建网络,如体素表示法、八叉树表示法、点云表示法、隐函数表示法等。
Choy 等[11]使用3D 卷积长短期记忆网络,从单视图或多视图图像中重建三维体素;Wu 等[3]将生成的对抗网络用于三维体素,使用对抗思想来训练3D GAN,实现从隐向量生成三维体素模型。这些工作使用体素作为三维形状的表示方法,与二维图像像素类似,研究者便把二维图像处理方法迁移到三维形状处理上。但是,随着体素模型分辨率的提高,体素表示法的内存占用也呈立方式地增长。因此,这种表示法对内存要求较高,常常因为GPU 内存空间不足而产生低分辨率(如323或643的体素)的重建结果。
对此,Häne 等[12]、Tatarchenko 等[13]使用八叉树来表示三维形状,实验表明八叉树表示法更具有内存效率,可以产生更高分辨率的三维模型。尽管如此,这些方法实现起来仍较困难,而且仅限于得到分辨率为2563的体素模型。
相对来说,点云表示法简单且灵活。Fan 等[14]设计了一个点集生成网络PointOutNet。该网络可以从单幅图像中预测出点云坐标,所生成的点集近似于真实的三维形状。Qi 等[15-16]先后提出PointNet、PointNet++,使用对称函数来达到点的排列不变性。
Groueix 等[17]将正方形面变形成目标曲面;Wang 等[18]提出Pixel2Mesh,使用图卷积神经网络逐步变形椭球体模板以对应图像;张豪等[19]通过预测图像深度信息并结合球形图来重建三维形状。
Mescheder 等[20]、Chen 等[21]、Park 等[22]用隐函数方法学习三维曲面,以点坐标和特征向量作为隐函数解码器的输入。对于每个点,隐函数解码器都会为它分配一个值,该值可以指示这个点是在三维曲面外还是在里面,之后采用Lorensen 等[23]的等值面提取算法生成三维形状。实验表明,最终所生成的三维形状具有较高的分辨率且内存效率较高。
这些三维形状表示法都有各自的优缺点。然而,这些表示法所对应的单图三维重建网络主要是在如ShapeNet这样的合成基准上开发的,该数据集的渲染图像由孤立的、处于中心位置的物体组成,并且图像没有背景。因此,面对现实世界处在不同场景、不同光照、不同遮挡下的物体,这些网络无法取得令人满意的效果。
2 网络设计
本文目标是对输入的单张实景图像进行检测,输出检测物体的类别、包围框、掩膜以及三维网格。结合二维目标检测网络Mask R-CNN 来搭建网络。在该网络中,输入图像首先通过一个由ResNet-50-FPN构成的基础网络,之后区域建议网络给出物体的候选框建议,再通过包围框和掩膜分支进行处理[24]。
本文网络称为IM-RCNN,如图1 所示,下文对隐函数分支进行说明。

Fig.1 IM-RCNN图1 IM-RCNN
2.1 隐函数分支
表1 展示了隐函数分支的架构。隐函数分支主要由使用卷积层f1获取z 特征向量和使用隐函数解码器获得实数值v两部分组成。
(1)获取z 特征向量。z 特征向量的作用是对物体三维形状进行编码,目标是从实景图像中重建出多个物体的三维形状,因此需要这些物体在整幅图像中所对应区域的特征图。Ren 等[9]使用ROI Pooling 操作粗略地实现,He 等[6]使用双线性差值提升输入图像与最终使用的区域特征图之间的对齐程度。因此,本文沿用这样的操作,获得图像中物体对应区域的特征图,即图2 中的X∈RH′×W′×C′。H′、W′、C′分别是特征图X的高、宽和通道数。通过一个卷积层对它进行映射,即:

式(1)中,f1是经过卷积核卷积映射,Sigmoid 激活函数处理的映射过程参数如表1 所示。

Table 1 Network details of implicit function branch表1 隐函数分支的网络细节
(2)隐函数解码器。假设有一个水密的三维形状,点p∈[-0.5,0.5]3是单位三维空间中的任意点,F是一个处于单位三维空间中的连续隐函数,用公式表示为:
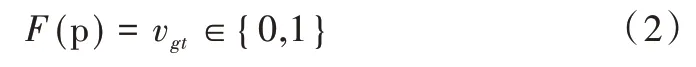
式(2)中,F所输出的值vgt表示点p在三维形状的内部还是外部。
本文目标是通过深度神经网络找到一个参数为θ的函数fθ,该函数以式(1)中得到的特征向量z和三维空间中的点p∈[-0.5,0.5]3为输入,最终输出实数v。根据图2 和表1,网络将维度为256 的特征向量z和维度为3 的三维空间上的点p相连接,得到z′。将z′送入fθ中,公式表示为:

关于fθ的结构,Hornik 等[25]认为,理论上多层的前向网络可以在任意精度上拟合出一个连续的形状函数。因此,根据Pix3D 数据集特征[26],使用8 个全连接层并搭配ReLU 激活函数搭建fθ。
2.2 网络训练
在表示学习领域人们常常使用由编码器加解码器组成的网络。研究人员为了得到给定输入对应的最优特征向量,首先完整地训练一个自编码器,之后把其中的解码器部分单独拿出来用作推断[27-28]。本文的目标是重建出三维模型,为此使用三维卷积网络搭建编码器,如表2 所示。使用fθ作为隐函数解码器构建一个体素自编码器。在训练隐函数分支之前先对它进行训练,如图3 所示。该体素自编码器的作用是将编码器部分用于生成标注的特征向量z,以及提供用作推断的隐函数解码器fθ。隐函数分支和包围框分支、掩膜分支共同训练。
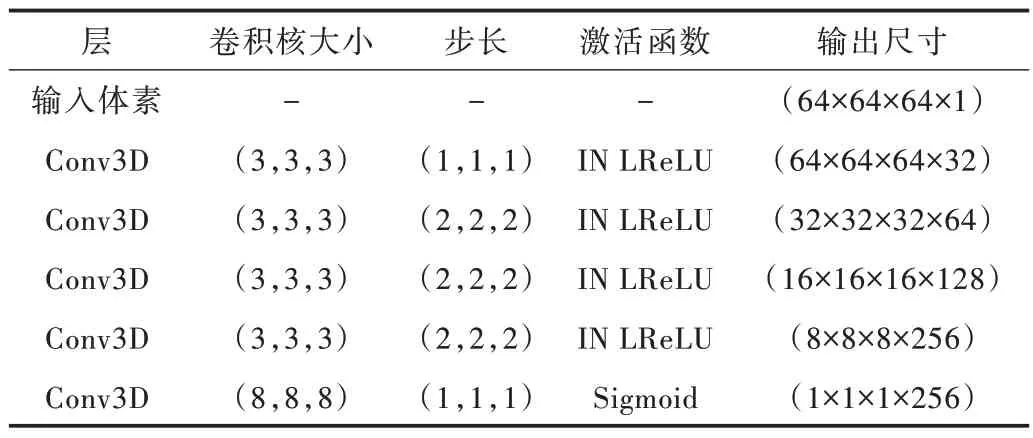
Table 2 Structure of encoder表2 编码器结构
2.2.1 体素自编码器训练
(1)数据预处理。根据图3,在训练体素自编码器时,除了三维体素模型还需要事先从该体素模型中采集三维点坐标p 和对应的实数值vgt作为约束。首先,为了方便采样,需要获得初始的体素模型。参考体素表示法的相关工作,使用binvox 将Pix3D 数据集中的所有CAD 模型体素化[29]。由于CAD 模型一般不是水密网格,所以需要对初始体素模型进行漫水填充,最后进行均匀采样,从上一步得到的分辨率为163、323的Pix3D 体素模型中采样三维点坐标p 和对应的实数值vgt。
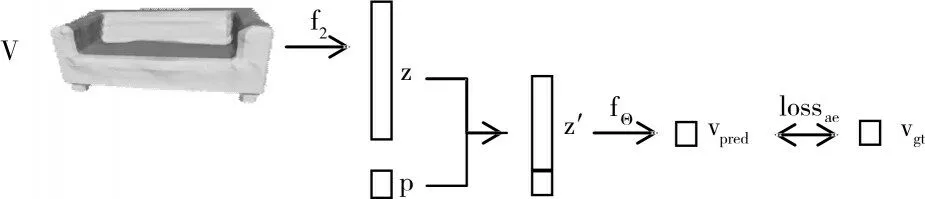
Fig.3 Training voxel auto-encoder图3 训练体素自编码器
(2)体素自编码器的损失函数与训练。如图3 所示,V是一个三维体素模型。通过编码器f2来提取该三维体素的特征向量z,然后将特征向量z与三维空间中的采样点p相连接,送入隐函数解码器fθ,最终预测出p点对应的实数值vpred。
在体素自编码器中,损失函数L是每个三维空间采样点所对应的标注值和预测值之间的均方误差。令P是从三维体素模型V 中采样出来的点集,共有N个点,pi是点集P中的一个点,则:
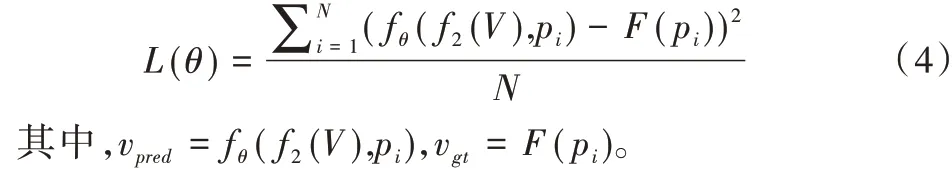
训练时,首先使用从163分辨率的体素模型中采样的数据训练300 个循环,之后保持网络结构不变,使用从323分辨率的体素模型中采样的数据对上一步网络参数模型进行微调,得到最终的网络模型。
2.2.2 隐函数分支训练
当完成上一步训练后,对隐函数分支进行训练。如图4 所示,训练时对预测特征向量和标注特征向量之间的均方误差进行优化,损失函数为:
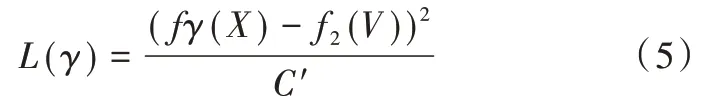
式(5)中,X是物体对应的区域特征图,fγ是带参数γ的卷积层,zpred=fγ(X),zgt=f2(V),f2是上一步训练好的编码器。

Fig.4 Training implicit function branch图4 训练隐函数分支
3 实验结果与分析
3.1 实验环境
在Pix3D 数据集上进行实验,该数据集包含10 069 张实景图像、395 个三维模型。由于Pix3D 数据集没有提供官方的训练集和测试集,因此沿用之前训练数据集和测试数据集的划分,即在Pix3D_S1 和Pix3D_S2 两个版本的数据集上分别进行训练和测试。
Pix3D_S1 版本随机分配了7 539 张实景图像用作训练,2 530 张图像用作测试。其中,训练和测试数据集的三维模型相交,即某一个三维模型会以不同的颜色和纹理,或者以不同的方位、在不同的光照条件下出现在训练数据集以及测试数据集的实景图像中。
Pix3D_S2 版本比Pix3D_S1 版本更具挑战性,训练和测试数据集的三维模型互不相交,即在训练数据集中出现的三维模型不会出现在测试数据集中,在测试数据集中出现的三维模型也不会出现在训练数据集中。
本文实验环境如表3 所示。
3.2 实验参数配置
在单张GeForce RTX 2080 Ti GPU 上进行训练,总共迭代315 000 次,每次迭代输入一张图像。对于优化器使用带动量的随机梯度下降算法,在前32 000 次迭代中,学习率 从0.002 5 到0.02 线性增加,之后在256 000 到315 000 次迭代中,以10 倍数进行衰减。在训练时,预训练模型是COCO 实例分割模型,损失权重λimplicit是3,使用的权重衰减率是10-4。另外,对于二维目标检测相关的损失权重 沿用Mask R-CNN 的默认数值。

Table 3 Experimental environment表3 实验环境
3.3 实验结果分析
3.3.1 测试数据集评估
为验证IM-RCNN,在Pix3D_S1 和Pix3D_S2 数据集上进行训练,并将测试结果与目前一些较有效的方法进行对比。其中,Pixel2Mesh 和Sphere-Init 经Gkioxari G等改进后拥有更好的效果。为了公平对比,这些网络使用相同的训练参数配置,在单张GeForce RTX 2080 Ti GPU 上从头训练。
大多数基于图像的三维重建方法使用CD 和NC 作为评估指标,其中,CD 越小越好,NC 越大越好。因此,本文从预测的网格表面和标注的网格表面分别采样10 000 个点,以此计算出这两个指标的值。
根据表4可知,在pix3d_s1上,无论是CD还是NC指标,本文网络在各个类别上的表现均优于前人方法。最终,IM-RCNN 的平均CD 比效果次之的Mesh R-CNN 小0.226,提升大约23.9%,平均NC 比它大0.054,提升大约7.6%。
表5 是pix3d_s2 上的结果:①由于训练数据集与测试数据集的三维模型互不相交,数据集本身难度增加,因此整体来看,这些网络的表现不如在pix3d_s1 上的表现;②除了消防栓、箩筐所在的“其他”类别,IM-RCNN 的表现均优于前人的方法;③由于工具类和其他类的三维模型形状在训练数据集和测试数据集中差别较大,并且用于训练的模型数量较少,因此这些网络在这两个类别上的指标表现并不是很好。最终,IM-RCNN 的平均CD 要比效果次之的Mesh R-CNN小0.157,提升大约14.0%,平均NC比它大0.035,提升大约5.1%。
在目标检测相关工作中,研究人员常常使用AP 指标来衡量检测到的包围框、2D 掩膜的平均精确度,使用AP_Mesh 来衡量重建的三维模型平均精确度,本文也使用这些指标对IM-RCNN 进行测试。如表6 所示,在pix3d_s1,IM-RCNN 在AP_BB、AP_Mask、AP_Mesh 三项指标上的表现均优于以往的方法。在pix3d_s2,尽管在二维目标检测性能上IM-RCNN 略逊于其他方法,但是在三维重建方面却拥有最高的AP_Mesh。
图5 展示了IM-RCNN 的一些重建结果。与Mesh RCNN 相比,IM-RCNN 可以重建出例如转椅的椅脚这样更丰富的细节。对于像书柜、床背、茶几这样有洞的物体也能更加清晰生动地重建。同时,根据图6 的展示,IMRCNN 可以准确地检测出一张实景图像中的多个物体,并且具有更好的视觉效果。
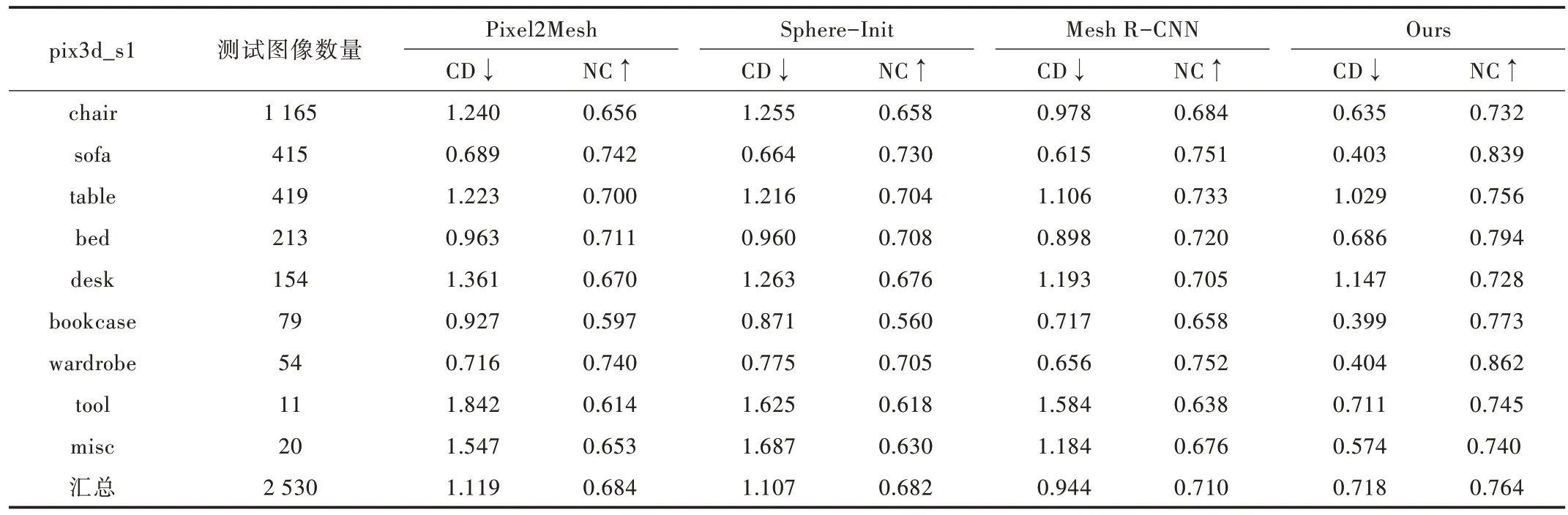
Table 4 Performance on pix3d_s1表4 pix3d_s1 上的表现

Table 5 Performance on pix3d_s2表5 pix3d_s2 上的表现

Table 6 Comparison of AP_Box、AP_Mask、AP_Mesh metrics表6 AP_Box、AP_Mask、AP_Mesh 指标比较

Fig.5 Reconstruction results of IM-RCNN图5 IM-RCNN 的重建结果

Fig.6 Output of IM-RCNN图6 IM-RCNN 的输出结果
3.3.2 多分辨率重建
由于体素表示法需要占用较大的内存,在Pix3D 数据集上,Mesh R-CNN 只能重建出243分辨率的三维形状。相反,如图7 所示,IM-RCNN 使用隐函数作为三维形状的表示方法,它不仅可以重建出低分辨率(如243、643)的三维形状,甚至可以重建出5123这样高分辨率的三维形状。

Fig.7 Multiresolution reconstruction图7 多分辨率重建
4 结语
针对当前面向实景图像的三维重建方法重建结果分辨率低、视觉质量不佳等问题,本文基于隐函数方法,结合Mask R-CNN,提出了IM-RCNN。网络在Pix3D 数据集上进行训练和测试,实验证明IM-RCNN 在各项指标上的表现均优于以往的方法。IM-RCNN 能够准确地检测出实景图像中的多个物体,输出物体的类别、包围框、掩膜,并重建出相应高分辨率、高视觉质量的三维模型。本文方法还存在不足之处,如将网络分为两阶段训练未免有些繁琐,如何在不降低模型效果的前提下将网络训练简化是后续优化方向。此外,从实景图像中重建出带有纹理的三维模型也是未来工作重点。
