基于LSTM和功率信息的大型工件加工过程监控
2021-10-26念志伟林正英朱圣杰
念志伟,林正英,朱圣杰
(福州大学 机械工程及自动化学院,福建 福州 350108)
0 引言
大型工件,特别是结构复杂的加工件,加工时间长,生产组织难度大。对于大型工件而言,监控加工过程,掌握加工进度信息,既能够确保加工任务的完成,提高加工效率,又能够根据生产进度的情况来进行调度优化。
机床加工的过程中能量的消耗会反映出机床的加工情况,大型工件的实时加工过程对应着机床加工功率数据的实时变化。一些学者针对工件加工过程中能耗变化的状况展开研究。WANG Q L等对连续功率信号进行重复分析并在加工过程中进行能效的多状态建模,实现加工过程异常的检测[1]。CAI Y等提出了一种连续小波变换和快速独立分量分析相结合的方法,提取铣削过程中能效状态的特征[2]。单东日等系统分析了柔性作业车间的工件加工过程中各阶段的机床能耗与时间特性,通过遗传算法和功率信息建立工件批量加工调度模型[3]。贺晓辉等通过分析工件加工过程功率变化特征,提出一种结合工件加工功率信息特征分析及支持向量机分类的工件在线识别和统计方法[4]。顾文斌等设计了一种以嵌入式技术为基础的数控机床能耗监控系统,可实时采集和监控机床加工过程中的能耗状态[5]。
目前大多数文献能耗与加工过程的研究,部分是针对工件加工过程中总体能耗数据的特征进行分析,部分是针对能耗监控方法研究,但是未考虑工件加工过程中的功率变化。为此,针对现有研究的不足和问题,本文针对大型工件加工过程中的功率变化进行分析,实现对加工过程的监控。
1 大型工件加工进度状态信息采集方法
1.1 工件加工过程功率状态曲线的分析
刘飞等[6]对功率曲线进行分析后得出结论,工件的每一个加工过程,都有着一个确定的功率状态曲线与其相对应;反之,功率状态曲线上的每一点,对应着工件某一时刻的加工进度状态信息。以实际铣削过程为例,图1所示为机床铣削铝合金过程中的功率数据曲线。根据功率数据曲线与实际加工过程的工步变化,可将数据分成空载进刀、铣刀接触、铣削表面、铣刀离开以及空载运行五个部分。
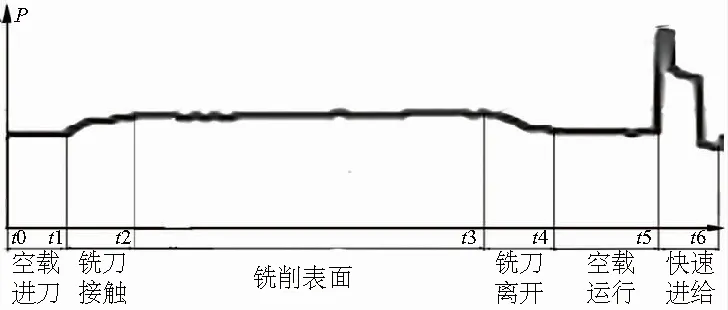
图1 铣削铝合金的功率数据曲线
以加工工件前事先获取的功率数据作为训练数据,建立工件工步识别模型,然后根据加工过程中实时采集的功率数据,将其输入模型从而得出实时工步结果,监控工件加工过程。
1.2 长短时记忆神经网络
长短时记忆(LSTM)神经网络设计的初衷是为了解决神经网络的长期依赖问题,避免像循环神经网络RNN在处理长序列数据上会产生梯度消失的情况[7]。LSTM主要由遗忘门ft、输入门it、记忆单元C以及输出门Ot组成,单元结构如图2所示[8]。
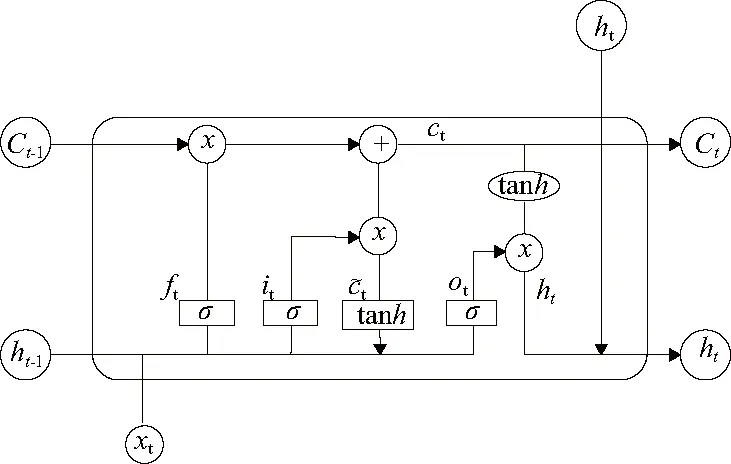
图2 LSTM的细胞结构
LSTM的关键就是记忆单元,在单元上方从左至右贯穿单元,它能够将上一个单元的信息传输到下一个单元。
LSTM的单元更新主要由3个门控制,其中控制神经单元决定其需要遗忘哪些信息,遗忘门为
ft=σ(Wf·[ht-1,xt]+bf)
(1)
负责更新细胞状态的输入门为
it=σ(Wi·[ht-1,xt]+bi)
(2)
(3)
决定当前时刻细胞输出的输出门为
Ot=σ(Wxo·Xt+Who·ht-1+bo)
(4)
ht=Ot·tanh(Ct)
(5)
LSTM的细胞状态为
(6)
2 基于LSTM的大型工件工步识别模型
2.1 数据预处理
数据之间的差异性会对模型的学习能力产生负面影响。由于模型的数据来源是采集大型工件加工过程中的功率数据,功率数据的大小随着工件加工工步的变化而变化,不同工步之间数值差距可能过大。因此为了保证模型的参数能够稳定收敛,需对数据进行归一化处理。
另外为了使功率数据能够符合LSTM框架中的输入层和输出层要求,需要将输入的加工工件的功率数据转化为可监督数据,将功率数据打上标签,以便进行分类识别。
2.2 模型构建
由于仅使用单变量功率数据实现大型工件工步识别,其数据的特征有限,因此本文所构建的LSTM网络只有三层,第一层为输入层,第二层为LSTM层,第三层为Dense层。模型损失函数选用交叉熵损失函数(binary_crossentropy),优化选取基于梯度下降的ADAM算法。
在构建LSTM神经网络的过程中,隐藏神经元数目、初始学习率大小以及输入量长度等重要参数会直接影响到模型识别效果,必须对模型中的这些参数进行优选,提高模型识别的精度。这里采用大型工件工步判断的准确率(accuracy)作为检验识别模型效果的指标:
(7)
其中TR为工步判断正确的数量。
网格搜索法(grid search method,GSM)是一种比较常用的优化算法,通过指定超参数,对训练集进行穷举训练,最后选出最优模型的超参数。采用网格搜索法对输入量长度、隐藏神经元数目和初始学习率大小进行参数优化,根据3个参数训练不同模型,再通过模型的准确率得分确定最优的参数。
模型主要流程图如图3所示。
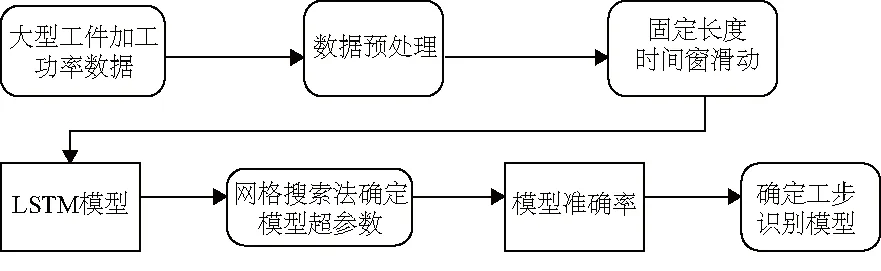
图3 模型流程图
3 某大型工件模拟验证
3.1 模拟实例
以主轴箱加工为例,对加工工步功率进行模拟验证,工件结构图如图4所示。
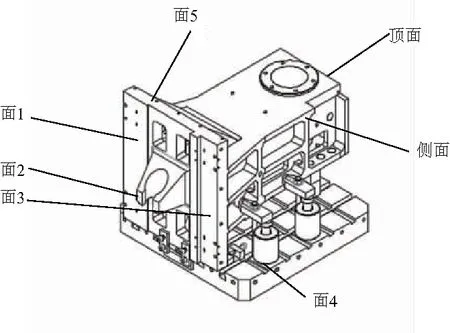
图4 主轴箱结构图
根据工件的加工工艺流程,以其中一道工序为例,该道工序的工艺规划如表1所示。表中,转速单位为r/min;尺寸单位为mm。

表1主轴箱加工的某道工序工步
当材料为灰铸铁时,铣削功率、铣削力的经验公式[9]如下:
(8)
(9)
其中:Pc为铣削功率;Fc为铣刀切削力;ap为切削深度;ae为加工表面宽度;fz为每齿进给量;d0为铣刀直径;Z为铣刀齿数;n为铣刀转速。
根据公式建立加工工件功率数据集,模拟大型工件加工的参考功率曲线如图5所示。
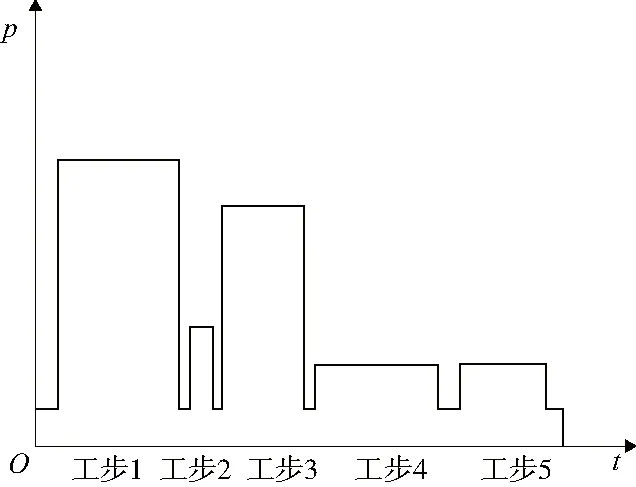
图5 参考功率曲线
因为功率数据是由加工工件时以10s为一次采集频率,相邻数据的时间点接近,所以设定窗口长度的取值范围取[30,40,50],隐藏层神经元个数的取值为[50,100,150,200],初始学习率设置[0.001,0.01,0.1]。
取网格搜索法对于超参数的模型得分,记录了不同参数条件下的结果。表2-表4列出了输入时间窗长度为30、40、50的得分数。
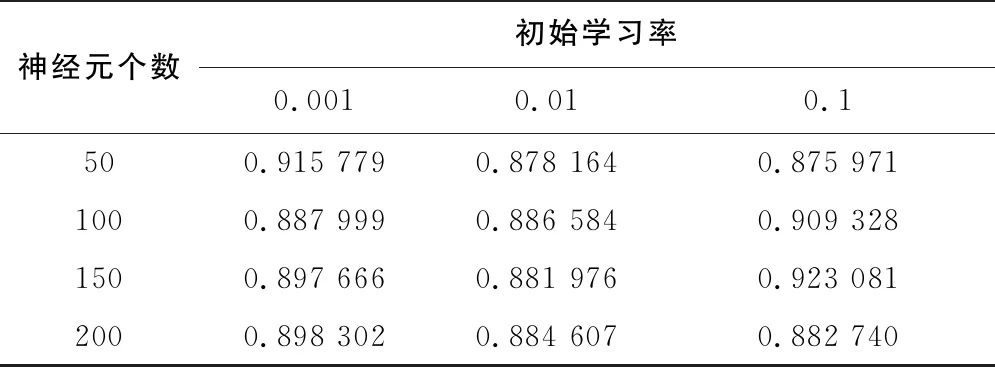
表2 窗口长度为30的参数寻优
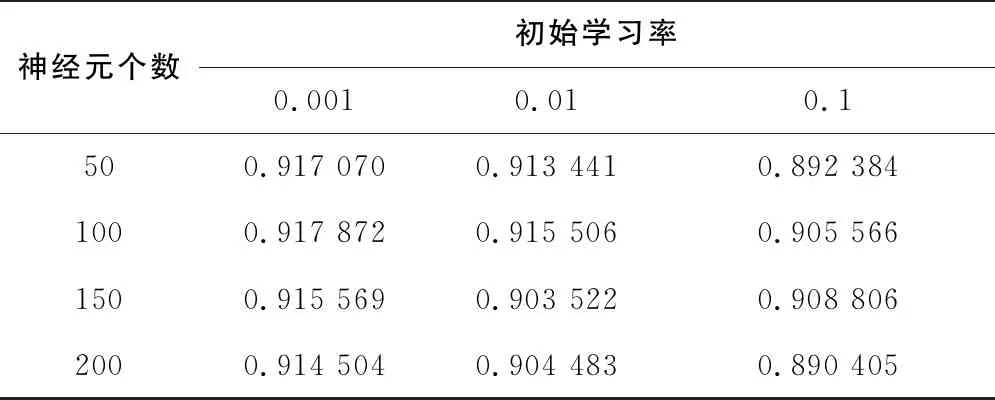
表3 窗口长度为40的参数寻优

表4 窗口长度为50的参数寻优
从表2-表4可以看出,使用网格搜索法对于超参数进行遍历,得到窗口长度为50,学习率为0.001,隐藏神经元数量为50的情况下网格搜索法的分类得分最高,模型的精度更好。
3.2 实验与结果
为了体现本模型在数据集上的表现,实验中,在相同数据集的情况下分别采用了LSTM、SVM和KNN 3种不同的方法对数据集进行分类,并计算准确率(表5)。

表5 不同方法的准确率
由表5可知,LSTM神经网络的准确率远高于另外两种方法,这是因为对于加工过程可能会出现功率相近的情况,SVM和KNN无法识别工步的区别,因此LSTM更有优势。
依照网格搜索法选取的超参数建立工步识别模型。工步识别的模型结果如图6-图7所示。图6是模型在训练集上的预测准确率(accuracy)的变化情况,图7是模型在训练集上的损失率(loss)变化情况。

图6 准确率变化图

图7 损失率变化图
LSTM模型在训练集上的准确率达到0.988 4,损失率为0.014 8。
将训练好的模型用在测试集上测试,准确率达到99.13%,损失率为0.013 6。模型在测试集上的表现优秀,分类结果与实际工步结果相差小,能够起到监控大型工件加工过程的作用。
4 结语
本文根据机床加工大型工件时功率数据具有的非线性和非平稳性的特征,提出了基于网格搜索法优化的LSTM大型工件工步识别模型,通过识别工件工步实现监控大型工件加工过程。通过对于大型工件的模拟实验,证实了模型的有效性,同时通过功率信息数据监控大型工件加工过程,为工厂在调度、加工管理方面的优化提供了一定的参考。
