基于Meta分析和气象因子驱动的苏豫皖小麦籽粒蛋白质含量地理空间分布特征
2021-10-23夏树凤江广帅胡诗琪仲迎鑫
夏树凤,江广帅,赵 鸿,方 乾,胡诗琪,王 凡,蔡 剑,王 笑,周 琴,仲迎鑫,姜 东
(南京农业大学农业农村部小麦区域技术创新中心,江苏南京 210095)
小麦是中国最重要的主粮作物之一,与人们日常生活息息相关。现阶段我国小麦供应总量已能满足需求,但随着人们生活水平的提高和饮食习惯的改变,优质专用小麦、特别是优质的强筋和弱筋小麦供应明显不足,严重依赖进口[1-2]。小麦分成强筋、中筋和弱筋三种品质专用类型,分别适合制作面包、蒸煮类和糕点饼干类食物。籽粒蛋白质含量是决定小麦籽粒烘焙品质的关键因素,也是评判上述三种品质专用类型小麦最重要的指标之一,受品种特性、气候、土壤、耕作栽培措施等因素的共同影响[3-4]。苏豫皖是我国小麦主产区之一,也是我国小麦未来发展最重要的区域。但该区域空间跨度、局域小气候差异很大,造成了在常规栽培条件下不同区域、不同年份小麦籽粒蛋白质含量变异较大。明确苏豫皖籽粒蛋白质含量的区域分布规律,开展品质区划,对于该区域优质小麦产业可持续发展具有重要意义。
有关中国不同区域小麦品质的区划,前人已有较多的报道。何中虎等[5]将我国小麦种植区初步划分为3个品质区域,并根据气候、土壤和耕作栽培条件进一步划分出各个亚区。孙丽娟等[6]利用2010—2015年冀鲁苏晋中筋小麦品种济麦22的品质数据建立GIS最优模型,发现蛋白质含量总体呈东北高西南低分布,6年间多呈带状分布,北方整体高于南方。王大成等[7]采用神经网络的方法研究了影响冬小麦蛋白质含量的关键生态因子及其变化趋势。Jie等[8]基于南京、徐州、泰安、保定的小麦蛋白数据建立了可预测不同气候环境下不同冬小麦品种蛋白质含量的简化回归模型。但受试验点数、年份、描述方法等的局限,尚无法进行更为细致、准确的品质生态区划。
Meta分析是对具有相同研究目的的多个独立研究结果进行系统分析、定量综合的研究方法[9],近几年来在农学领域的应用逐渐增多。韩天富等[10]对1988—2017年全国水稻土长期监测点的水稻产量、施肥、土壤数据进行Meta分析,发现适量的肥料投入是提高和维持水稻高产的重要措施,有机肥与无机肥配合施用增产效果更加显著。Miguez等[11]对1999-2010年阿根廷潘帕斯省46个大田试验中氮肥施用和小麦籽粒蛋白质、产量数据进行Meta分析,发现早期施氮对籽粒蛋白含量影响不显著,临近开花期的叶片施肥处理的籽粒蛋白质含量比对照提高了 1.14%。目前基于Meta分析方法开展生态环境对作物产量或品质影响的研究尚未见报道。
综上所述,已有小麦品质生态区划多限于文字描述,或基于部分生态试验点和少数年份与品种的试验结果分析,尚缺少对同类研究进行综合分析。同时,基于回归模型和神经网络模型等的研究结果,尚缺少对评估区域品质性状的可视化分析。因此,本研究收集了常规栽培条件下 1999-2019年间苏豫皖包含小麦籽粒蛋白质含量相关信息的文献和相关气象数据,运用Meta回归分析并结合ArcGIS反距离插值法,综合多年份、多试验点小麦籽粒蛋白质含量数据,明确影响小麦籽粒蛋白质含量的关键气候指标,构建苏豫皖小麦籽粒蛋白质含量定量分析模型,在时空尺度评估该区域小麦籽粒蛋白质含量分布规律,并进行小麦品质生态区划。
1 材料与方法
1.1 数据来源
首先,以“小麦”和“蛋白质”为主题词,对中国知网中的文献及硕博士论文分别进行检索,为减少品种更新换代等的影响,发表年份限制在1999—2019年,共检索到5 387篇文献(含学位论文)。进而根据如下条件对所检索到的文献进行筛选:(1)研究结果为大田试验且包含明确的试验年份;(2)研究地点在江苏、河南和安徽3省;(3)试验施氮量介于150~270 kg·hm-2之间的处理;(4)包含测定指标“籽粒蛋白质含量”。符合筛选条件的290篇文献包含2 260条蛋白质含量数据,分布频数如图1所示。对上述文献中籽粒蛋白质含量的平均值、标准差(误)、样本量(处理重复数)及相应试验年份进行提取。在中国气象数据网(http://data.cma.cn/)下载相应地点和年份的气象数据,包括气温、光照时数和降水量,用于后续分析。
对于文献中蛋白质含量的平均值及标准差(误),一般情况下,文献数据以表格和柱状图两种形式呈现。对表格形式呈现的数据直接进行提取;对于以柱状图呈现的数据,用GetData软件(http: //getdata-graph-digitizer.com/)进行数字化转换。对仅提供标准误的数据,将其转换为标准差(SD=SE×sqrt(N))。对于标准差(误)缺失的数据,依照如下方法进行估计:首先,计算出整个数据集的变异系数;其次,以平均值乘以变异系数来估计缺失的标准差[12]。
1.2 数据处理
将提取到的蛋白质数据按经纬度和年份进行归类,同一经纬度同一年份的蛋白质含量进行平均值和标准误的计算。用STATA软件先进行异质性检验,若纳入的各研究结果无异质性(I2<25%),采用固定效应模型进行分析;相反,则采用随机效应模应[13]。
根据小麦生育特点,将全生育期划成播种—拔节、拔节—孕穗、孕穗—开花、灌浆前期、灌浆中期和灌浆后期6个生育阶段。一般小麦孕穗期至成熟期的持续时间变异较小,孕穗前因播期和年际差异有一定的波动,因而文献中如有物候期详细记录,则按试验年度对应地点的气象数据进行准备计算。但大部分文献缺少物候期记录,而所研究区域纬度跨度不大,生产中生育期进程较为接近,故所有年份和地点小麦全生育期统一设定为11月1日至5月31日,并按播种—拔节(11月1日—3月20日)、拔节—孕穗(3月21日—4月10日)、孕穗—开花(4月11日—4月20日)、灌浆前期(4月21日—5月5日)、灌浆中期(5月6日—5月20日)和灌浆后期(5月20日—5月31日)划分,并分别统计累计降水量、日照时数及积温数据。运用SPSS18.0进行初步相关分析,筛选出相关性极显著的指标后,将所得指标数值变化范围进行三等分,形成1、2、3三个等级。
将各地点分级后的生态因子和相对应蛋白质含量数据输入STATA软件运用多水平分析策略进行Meta分析。
1.3 图像拟合及模型验证
使用ArcGIS将不同气象等级条件下分别对苏豫皖三省拟合出的籽粒蛋白质含量,按地点经纬度进行反距离插值得出苏豫皖蛋白质含量分布图。分省拟合和整体拟合苏豫皖三省的籽粒蛋白质含量,并根据模型公式转换为2019年气象等级条件下的籽粒蛋白含量,按地点经纬度进行反距离插值得出2019年苏豫皖小麦品质区划图。采用本团队于2019年在江苏省各地进行的大规模抽样测定数据(施氮量含介于 150~270 kg·hm-2之间的处理)作为验证集,利用ArcGIS按验证集数据的经纬度信息从两个模型中提取预测值,并计算相对误差。
相对误差=(预测值-真实值)/真实值
数据整合采用MySQL进行,图形绘制采用R-3.6.1 软件实现,地图利用ArcGIS map10.2采用反距离插值法进行插值绘制。
2 结果与分析
2.1 苏豫皖小麦籽粒蛋白质含量21年概况
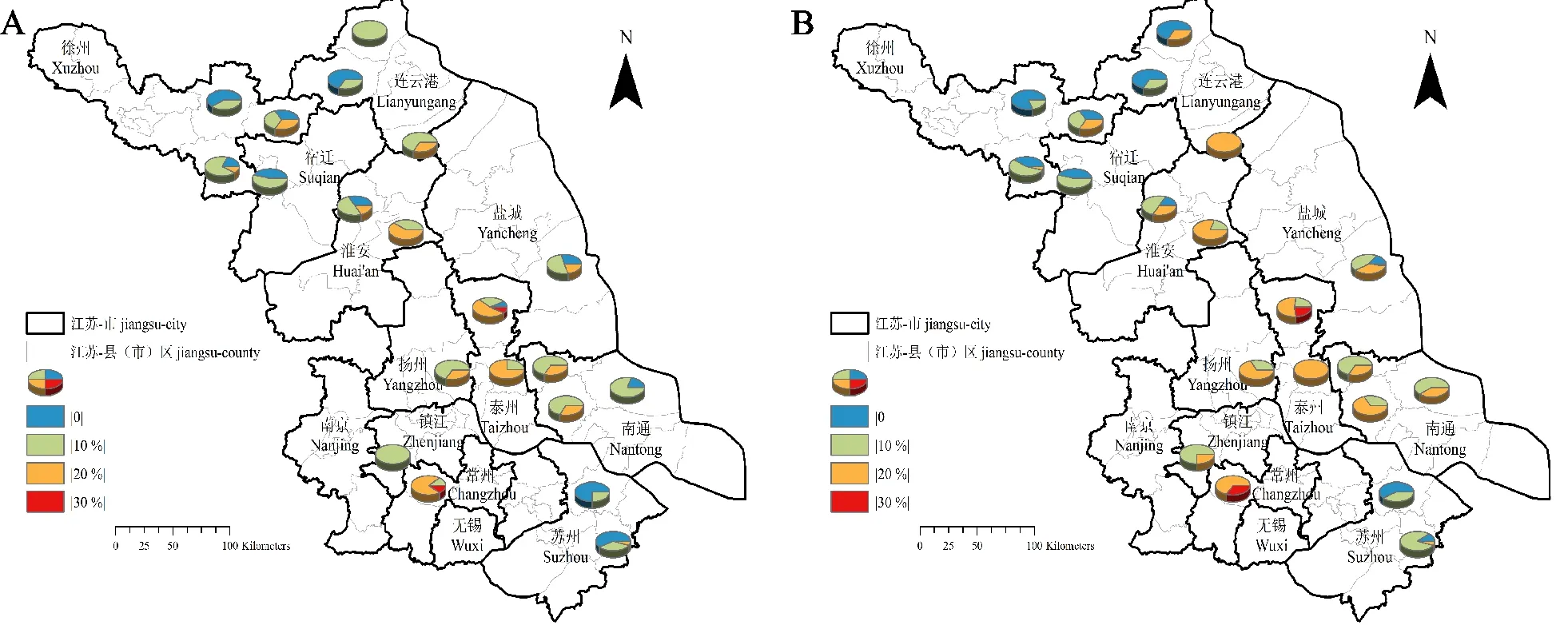
本研究最终选出的290篇文献涉及35个地级市,其中河南15个,江苏11个,安徽9个(图1)。其中,江苏扬州的样品数最多,其次是河南郑州、江苏南京。根据GBT 17320-2013《小麦品种品质分类》标准,文献中江苏苏州试验点的籽粒蛋白质含量始终低于12.5%,达到弱筋小麦水平;河南许昌始终高于12.5%,达到中筋小麦标准以上水平;安徽蒙城、河南开封、河南偃师始终高于13%,达到中强筋小麦标准以上水平;河南三门峡始终高于14%,达到强筋小麦标准以上水平;其余地点的籽粒蛋白质含量变异系数较大,弱筋、中筋、中强筋、强筋小麦样品均有分布(图2)。
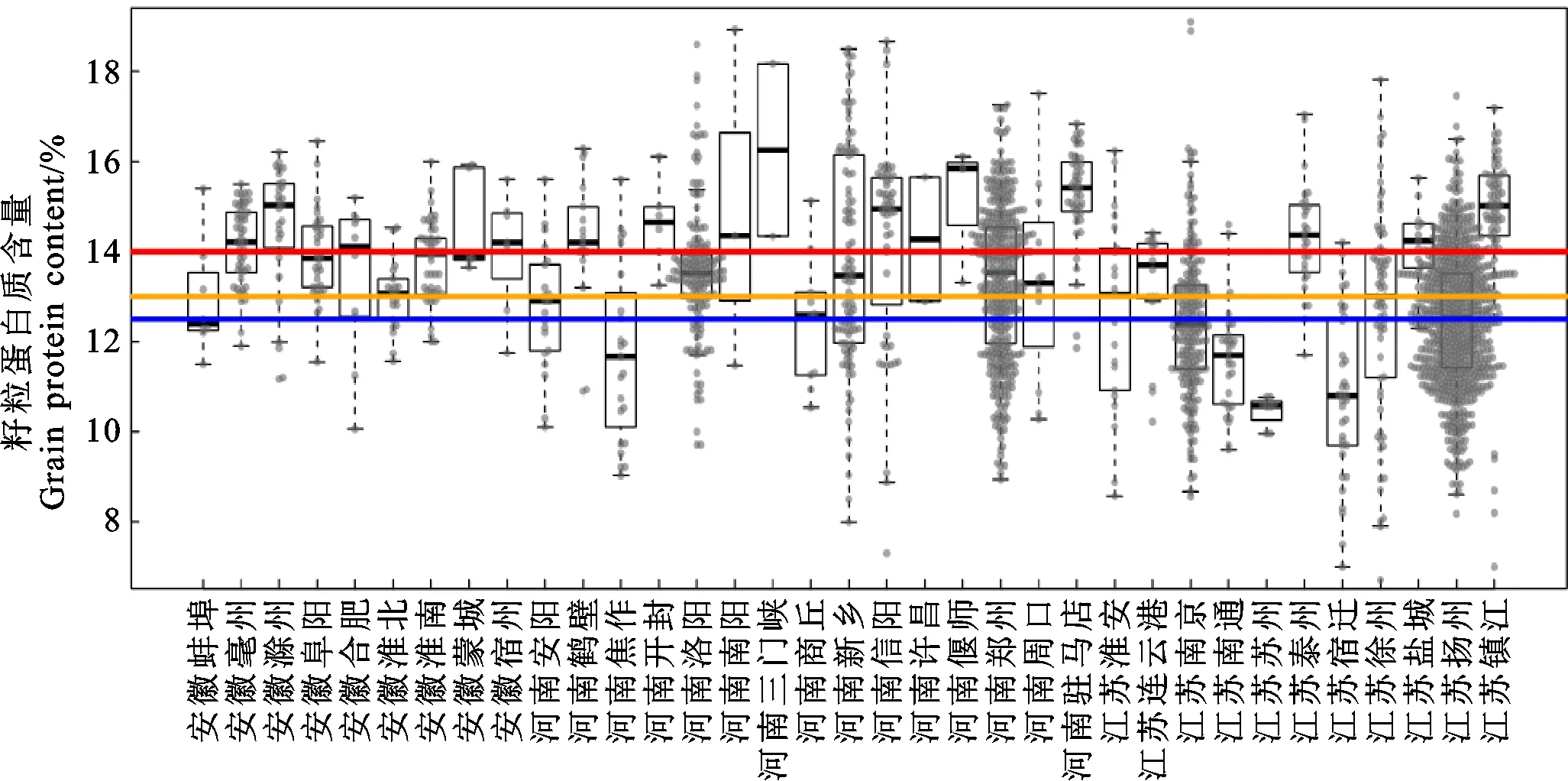
图2 各地级市籽粒蛋白质含量概况
2.2 影响小麦籽粒蛋白质含量的关键气象因子
经对播种—拔节、拔节—孕穗、孕穗—开花、灌浆前期、灌浆中期和灌浆后期6个生育时段的累计降水量、日照时数及积温数据与蛋白质含量进行相关性分析,播种—拔节、拔节—孕穗期、灌浆前期、灌浆中期4个时间段的降水量与蛋白质含量均呈显著负相关(表1),因此将播种—孕穗、灌浆前中期的降水量分别合并处理。
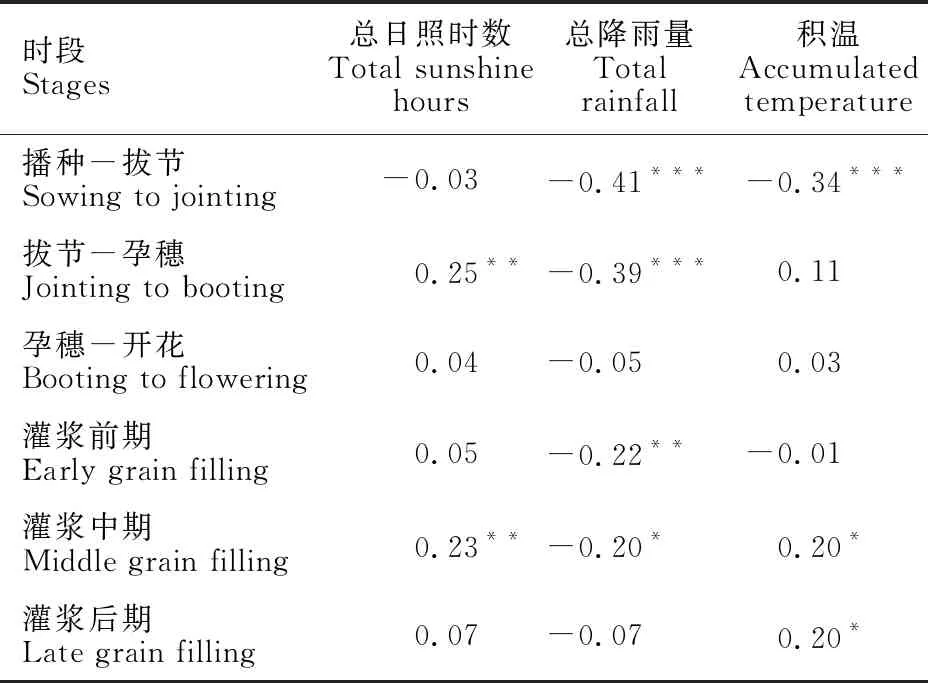
表1 各时间段气象因子与籽粒蛋白质含量的相关性
从表2可以看出,籽粒蛋白质含量与播种—孕穗总降水量(R1)、播种—拔节期积温(T)、灌浆前中期的总降水量(R2)呈现极显著负相关,与灌浆中期的总日照时数(S)呈现显著正相关。播种—孕穗总降水量(R1)与播种—拔节期积温(T)呈极显著正相关,与灌浆前中期的总降水量(R2)和灌浆中期的总日照时数(S)分别呈极显著正相关和极显著负相关。其余气象因子指标与蛋白质含量相关性不显著。播种—拔节期积温与灌浆前中期的总降水量(R2)呈极显著正相关,与灌浆中期的总日照时数(S)不相关。此外,灌浆前中期的总降水量(R2)与灌浆中期的总日照时数(S)呈现极显著强负相关。因此,根据R1、R2、T和S进行等级划分并进行Meta分析。

表2 小麦籽粒蛋白质含量与气象因子之间的相关性
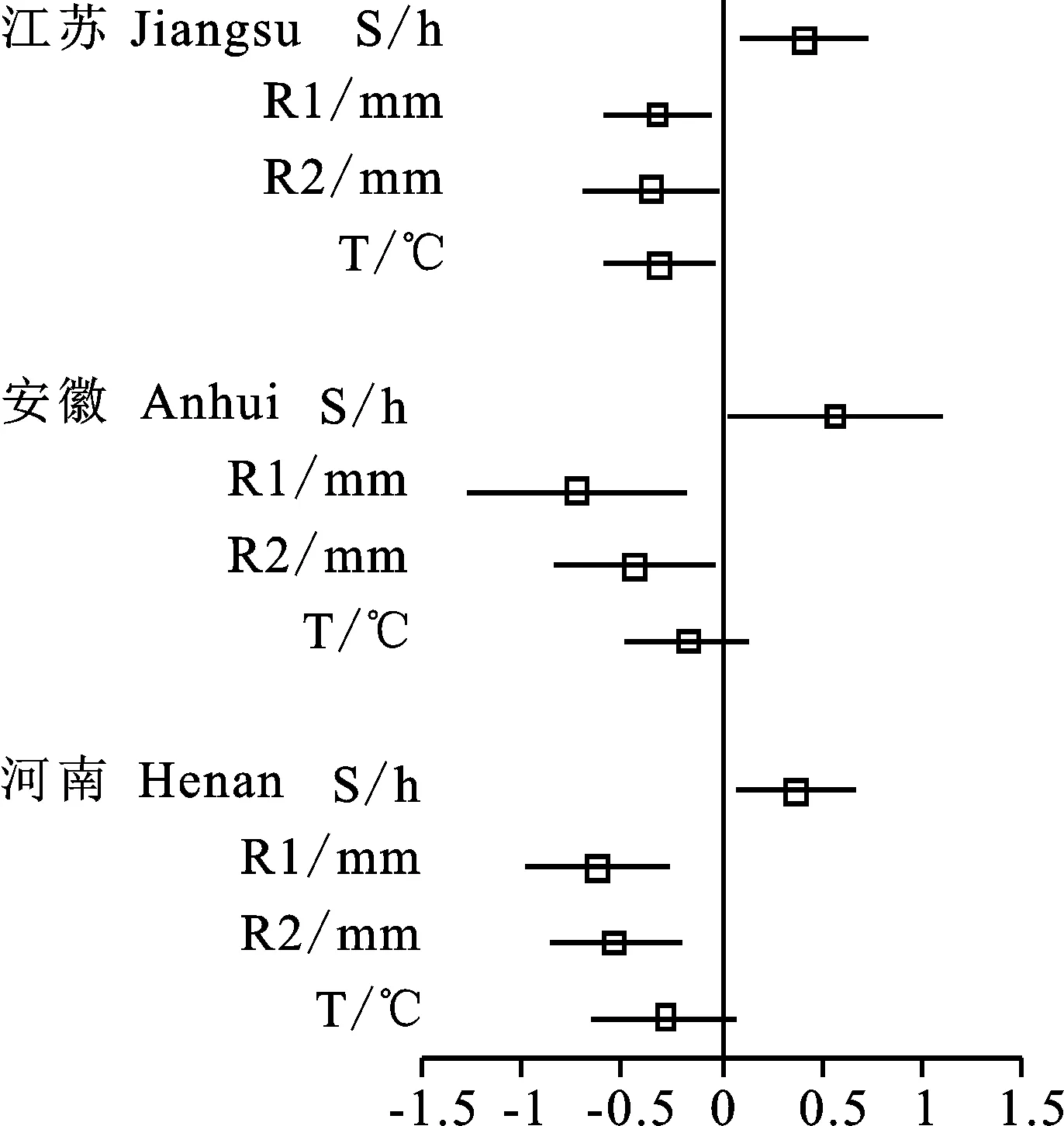
2.3 气象因子影响系数评估分析
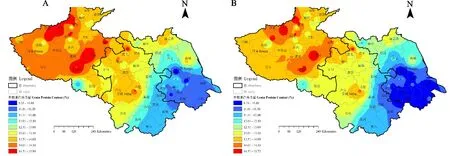
检查各个独立研究的结果是否具有可合并性,首先对不同研究所得的蛋白质含量进行了异质性分析。大多数研究落在95%可信区间线之内(图3),25% 以标准化估计值相对于标准误的倒数作图,每个点(b/se(b))代表一个独立的研究,若位于可信区间线(Fitted values)内,说明研究间同质;反之则存在异质性。 采用Meta分析中的多水平分析策略,对不同省份四个气象因子的回归参数进行了预估(图4)。以省份为单位进行回归,发现灌浆中期的总日照时数(S)的平均回归参数和置信区间均大于0,表明其对小麦籽粒蛋白质含量具有正效应,而播种—孕穗(R1)和灌浆前中期(R2)的总降水量则相反。小麦籽粒蛋白质含量在安徽省受到播种—孕穗(R1)总降水量的负效应及受到灌浆中期(S)总日照时数的正效应大于河南省和江苏省。由于播种—拔节期积温(T)的置信区间与中线交叠,其效应存在不显著的情况,因此后续的分析将其舍去。 R1:播种-孕穗(11月1日—4月10日)总降水量;R2:灌浆前中期(4月21日—5月20日)总降水量;T:播种-拔节期(11月1日—3月20日)积温; S:灌浆中期(5月6日—5月20日)总日照时数。 为了将不同省份籽粒蛋白质含量分别进行拟合,首先将文献调研的籽粒蛋白质含量平均值标准化。江苏、安徽、河南三省标准化公式依次 如下: Pr1=Pr0-(n1-1)*0.33-(n2-1)*(-0.41)-(n3-1)*(-0.43) ① Pr1=Pr0-(n1-1)*0.52-(n2-1)*(-0.87)-(n3-1)*(-0.43) ② Pr1=Pr0-(n1-1)*0.35-(n2-1)*(-0.73)-(n3-1)*(-0.61) ③ 其中,Pr0为文献调研的蛋白质含量平均值,n1为实际灌浆中期的总日照时数(S)等级,n2为实际播种—孕穗总降水量(R1)等级,n3为实际灌浆前中期的总降水量(R2)等级。 将三省标准籽粒蛋白质含量转为任意目标气象条件下的蛋白质含量的公式依次如下: Pr=Pr1-(x1-1)*0.33-(x2-1)*(-0.41)-(x3-1)*(-0.43) ④ Pr=Pr1-(x1-1)*0.52-(x2-1)*(-0.87)-(x3-1)*(-0.43) ⑤ Pr=Pr1-(x1-1)*0.35-(x2-1)*(-0.73)-(x3-1)*(-0.61) ⑥ 其中,Pr1为标准化蛋白质含量平均值,x1为预测目标的灌浆中期的总日照时数(S)等级,x2为预测目标的播种—孕穗总降水量(R1)等级,x3为预测目标的孕穗前中期的总降水量(R2)等级。 灌浆中期的总日照时数的1、2、3等级分别对应S<88.2 h、88.2 h 基于公式①~⑥构建苏豫皖模型。由图5可知,在同一气象条件下,苏豫皖地区的籽粒蛋白质含量整体上呈现从西向东呈下降趋势。当S<88.2 h、R1<140 mm、R2<50 mm(图5A)时,籽粒蛋白质含量≤12.5%的小麦主要分布在江苏的中南部和南部;籽粒蛋白质含量在12.5%~13%之间的小麦主要分布在江苏的中北部以及安徽的东南部;籽粒蛋白质含量在13%~14%之间的小麦主要分布在江苏的北部、安徽的南部以及河南的北方少部分区域;籽粒蛋白质含量>14 %的小麦主要分布在安徽的中部、西部和河南的绝大部分区域。随着灌浆中期的总日照时数(S)的增加,苏豫皖各地区的籽粒蛋白质含量增高。在S>115.3 h、R1<140 mm、R2<50 mm(图5D)的区域,籽粒蛋白含量大多超过弱筋小麦品质要求;河南和安徽的大部分区域以及江苏的北部和东北部区域籽粒蛋白质含量>14%;江苏中部和南部区域小麦处于中筋水平。随着播种—灌浆总降水量(R1)的增加,苏豫皖各地区的籽粒蛋白质含量降低。常规气象条件下即S>115.3 h、140 尽管分省拟合可以考虑到每个省的气象因素及种植情况,但两省交界处采用不同的计算模型可能会产生较大误差。因此,本研究将苏豫皖所收集到的全部数据整体进行Meta分析,所得模型如下(注释同2.3部分): Pr1=PPr0-(n1-1)*0.53-(n2-1)*(-0.67)-(n3-1)*(-0.29) ⑦ Pr整体=Pr1+(x1-1)*0.53+(x2-1)*(-0.67)+(x3-1)*(-0.29) ⑧ 从2019年三省分别和整体拟合出苏豫皖蛋白质含量分布图(图8)中提取2019年江苏省259个小麦样品点(经纬度)的蛋白质预测值。与真实值相比大部分预测值比实际值小,整体上的相对误差表现为弱筋<中筋<中强筋<强筋,且由于相对误差的公式定义原因,模型对弱筋小麦的预测效果更好。分省拟合所得的模型的相对误差比整体拟合所得的模型小。分省拟合所得的模型相对误差主要集中在-10%和0,占样品的 62.16%,其中相对误差为0%的占比 25.48%(图6 A)。整体拟合所得的模型相对误差主要集中在 -20%和-10%,占比67.95%(图6 B)。 A为分省拟合模型,B为整体拟合模型。 选择样品点≥3的县区,从区域分布观察其相对误差分布,结果发现,江苏东南部和北部相对误差绝对值主要集中在0和10%,比较准确。江苏中部地区籽粒蛋白质含量预测相对误差绝对值较其他区域大,兴化地区出现了30%的相对误差绝对值,但仍以20%的相对误差绝对值为主。一些区域出现30%相对误差绝对值的原因可能是该区域缺少历史籽粒蛋白质值,从而难以准确预测蛋白含量。因此,整体模型对于预测江苏东南部以及北部的准确度大于中部地区(图7)。分省拟合的模型其东部的相对误差绝对值小于整体拟合的模型,30%的相对误差绝对值也较少,然而针对两省交界的城市(如徐州、连云港),整体模型更为适用。 A为分省拟合模型,B为整体拟合模型。 基于整体拟合公式⑦和⑧,将文献调研的籽粒蛋白质含量平均值转为2019年气象等级条件下的籽粒蛋白质含量,并用反距离插值法进行模型的构建,进行苏豫皖小麦区划。依据GB/T 17320-2013《小麦品种品质分类》标准,从图8、图9可知,在苏豫皖区域弱筋小麦主要分布在江苏省的南部和中部、安徽省的东南部,中筋小麦主要分布在江苏省的中北部、安徽省中部少部分地区,中强筋小麦主要分布在江苏省的北部、安徽省的北部、中西部和西南部、河南省的东北部,强筋小麦主要分布在河南省东部、西北部和西南部。所在区域播种—灌浆和灌浆前中期的总降水量越小,灌浆中期的总日照时数越大,籽粒蛋白质含量越高。弱筋小麦优势区的灌浆中期的总日照时数(S)≤88.2 h,播种—孕穗的总降水量(R1)>140 mm,灌浆前中期的总降水量(R2)三个等级均有分布;中筋小麦优势区灌浆中期的总日照时数(S)≤88.2 h,播种—孕穗的总降水量(R1)>140 mm,灌浆前中期的总降水量(R2)<100 mm;中强筋小麦优势区灌浆中期的总日照时数(S)三个等级均有分布,播种—孕穗的总降水量(R1)<276 mm,灌浆前中期的总降水量(R2)<100 mm;强筋小麦优势区的灌浆中期的总日照时数(S)<115.3 h,播种—孕穗的总降水量(R1)<276 mm,灌浆前中期的总降水量(R2)<50 mm。 A为分省拟合模型,B为整体拟合模型。 图9 苏豫皖蛋白质品质分类区域分布示意图(依据2019年气象条件) 前人研究显示,环境因素对小麦籽粒蛋白质含量的影响大于基因型,其中地点效应大于年份效应[14-16]。本研究采用21年苏豫皖地区小麦籽粒蛋白质含量文献数据及试验地的气象数据,进行皮尔逊相关性分析和Meta回归发现,小麦籽粒蛋白质含量与播种—孕穗前总降水量、灌浆前中期总降水量呈极显著负相关,与灌浆中期的总日照时数呈显著正相关。前人研究也认为,小麦籽粒蛋白质含量一般与降水量呈负相关[17]。这可能与大量降雨导致土壤剖面速效氮素流失有关,特别对沙质土壤的影响更大,不利于后期氮素的吸收及其在籽粒中向蛋白质的转化[18]。此外,小麦籽粒蛋白质所合成的氮源70%以上来自于开花前在营养器官贮藏的氮化合物向籽粒的再转运,播种出苗至开花期经历时间很长,土壤氮源的流失可能从“源”的角度不利于籽粒蛋白质的积累。这也与本研究中孕穗前总降水量对籽粒蛋白质含量的负效应大于孕穗后总降水量的结论相吻合。 同时,因阴雨天气导致的光照不足也可能影响籽粒蛋白质的积累。光照可通过日照时数和光照强度两个方面来影响光合作用,从而调控小麦籽粒蛋白质积累。光合作用为同化产物形成提供碳源和能量,日照时数越长,可为作物提供更长的光合时间,累积更多的有机物。较长的日照可促进小麦籽粒中氨基酸的积累[19]。小麦籽粒中的游离氨基酸绝对含量在花后16~32 d(灌浆中期)处于较高水平,可为籽粒贮藏蛋白质合成提供充足的氮化物[20]。然而,生育后期充足的光照会使籽粒饱满,增加粒重,这也可能会“稀释”小麦籽粒蛋白质含量。与此同时,不同地区的光照强度不同,而强光对C3作物小麦会产生光抑制作用,降低光合速率[21],不利于有机物的形成。因此,日照时数对小麦籽粒蛋白质含量的影响研究结论尚不统一。赵春等[22]研究表明,播种至拔节期长日照有利于小麦籽粒蛋白质含量的提高,开花至成熟期日照时数的减少会提高蛋白质含量。而曹广才等[23]认为,小麦蛋白质含量、湿面筋含量与抽穗—成熟期间的平均日照时数呈正相关,这与本研究中灌浆中期、拔节—孕穗的总日照时数与籽粒蛋白质含量呈正相关的结论一致。 采用在江苏2019年批量随机取样测定分析的小麦籽粒蛋白质含量,对本研究中利用Meta回归分析建立的小麦籽粒蛋白质含量预测模型进行检测,分省拟合所得的模型相对误差主要集中在-10%~0,其中25.48%(66个)的点相对误差为0,预测准确性较高。需注意的是,模型构建所采用数据集与检验数据集在时间和空间上都有很大的跨度,能获得如此较为准确的结果,表明该研究采取的Meta分析方法完全可用于作物生态区划布局,至少在作物品质生态区划模型构建方面表现出很好的适用性。进一步分析部分取样点(7个,占2.7%)相对误差较大的原因,可能与其所在区域缺少历史籽粒蛋白质值有关。从本研究收集的文献可以发现,江苏西南部、安徽南部、河南中南部存在大量空白有待填补,可加强对该区域小麦品质空间变异的研究,以进一步提升本模型的准确度。 基于分省拟合的2019年苏豫皖模型模拟显示,江苏南部沿海沿湖地区可种植出籽粒蛋白质含量达到弱筋小麦标准的小麦,随纬度升高,籽粒蛋白质含量升高。这一点与黄芬等[24]建立的模型趋势相同。然而本研究发现,同一纬度江苏北部沿海地区籽粒蛋白质含量相对于西北部地区并不低,可达到强筋小麦标准,这可能与江苏东北部沿海地区地处滨海盐碱区,土壤盐碱影响小麦生长,导致籽粒蛋白质含量上升,同时植株吸收的盐离子有利于促进面筋蛋白聚集有关。Borrelli等[25]研究表明小麦蛋白质含量随土壤中盐浓度升高而显著提高,而Zhang等[26]也发现小麦麦谷蛋白大聚体(GMP)含量随着土壤盐含量的增加而显著提高。因此,除了气候因素,部分土壤理化性状也是影响籽粒品质区划的重要因素。 本研究发现苏豫皖地区弱筋小麦优势区主要集中在江苏、安徽和河南省的南部,此处降水量较其他区域多;中筋小麦主要集中在江苏和安徽的北部等地区,降水量适中,这一结论与何中虎等[5]研究相同。而强筋小麦的分布有所不同,但也主要集中在河南省。王绍中等[27]研究同样表明,豫东平原由于气候较为干旱,相较于淮南春雨丰沛区更利于小麦籽粒蛋白的积累。总言之,苏豫皖地区籽粒蛋白分布特征的形成主要是因为该地区由西向东、由北向南,灌浆中期的总日照时数减少,播种—孕穗的总降水量增加,灌浆前中期的总降水量增加。 由于绝大多数文献并未提及小麦的生育期,本研究拟定小麦生育期为11月1日—5月31日,并按照月和日的结点对其进行了6个时段的划分。然而,各地区受当地气象以及耕作制度的不同,播收时间不同,生育期划分的误差对探究小麦不同生育时期气象与籽粒蛋白质含量的关系仍存在影响。但是,以月和日为时间结点变量可以使得模型在较大的时空范围内具有普适性,同时基于文献调研所获取的大数据量可以在一定程度上消除误差,在未来的小麦生产中,所得模型可用于通过当年的气象因子对蛋白含量进行预测。此外,土壤数据和一些历史蛋白数据的缺失可能导致区划结果不够精准,但整体来看与前人研究基本相符,可为苏豫皖的小麦品质及品种区划提供参考。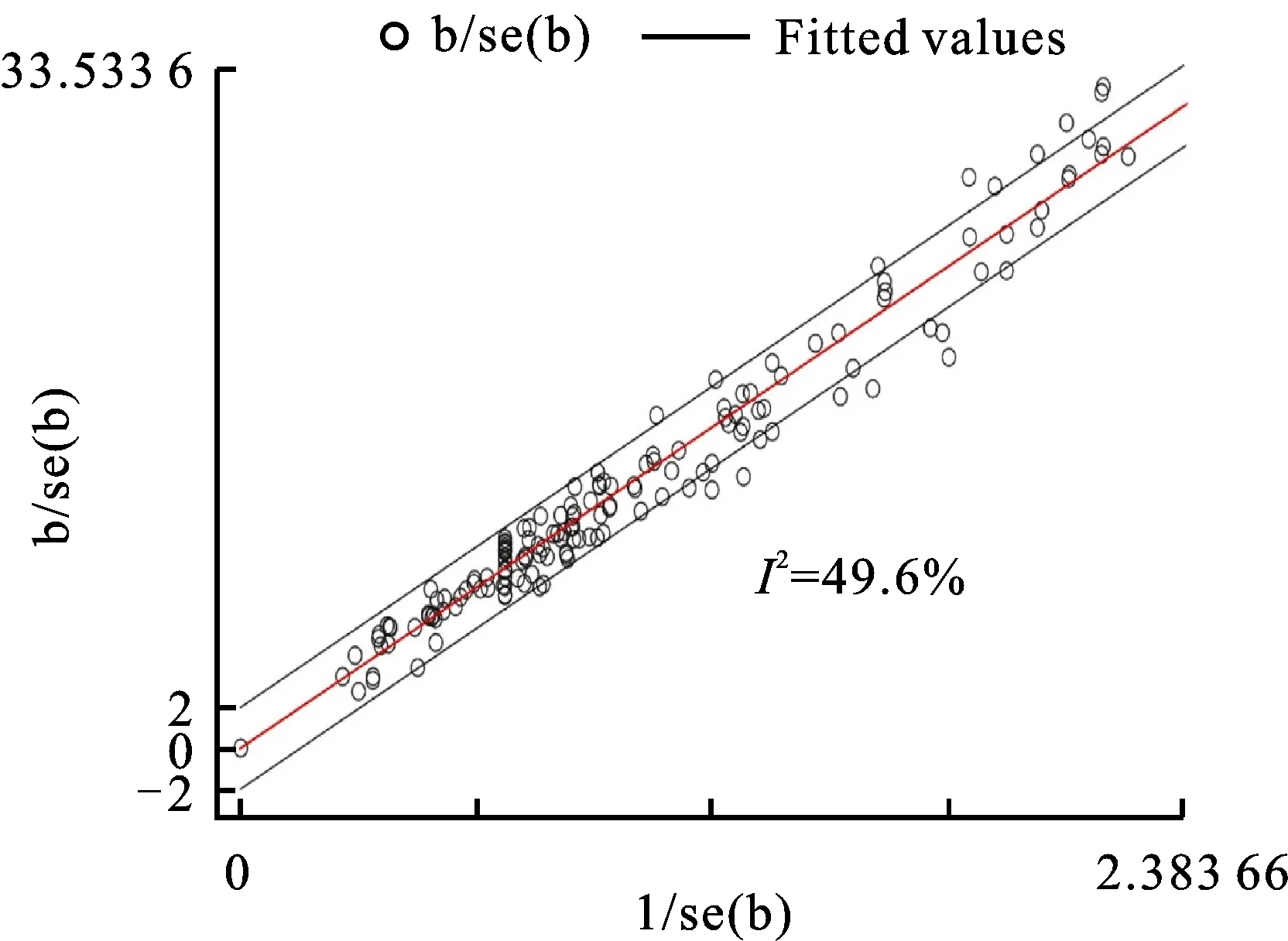
2.4 苏豫皖小麦籽粒蛋白质含量的区域分布
2.5 小麦籽粒蛋白质含量预测模型验证

2.6 苏豫皖小麦品质区划
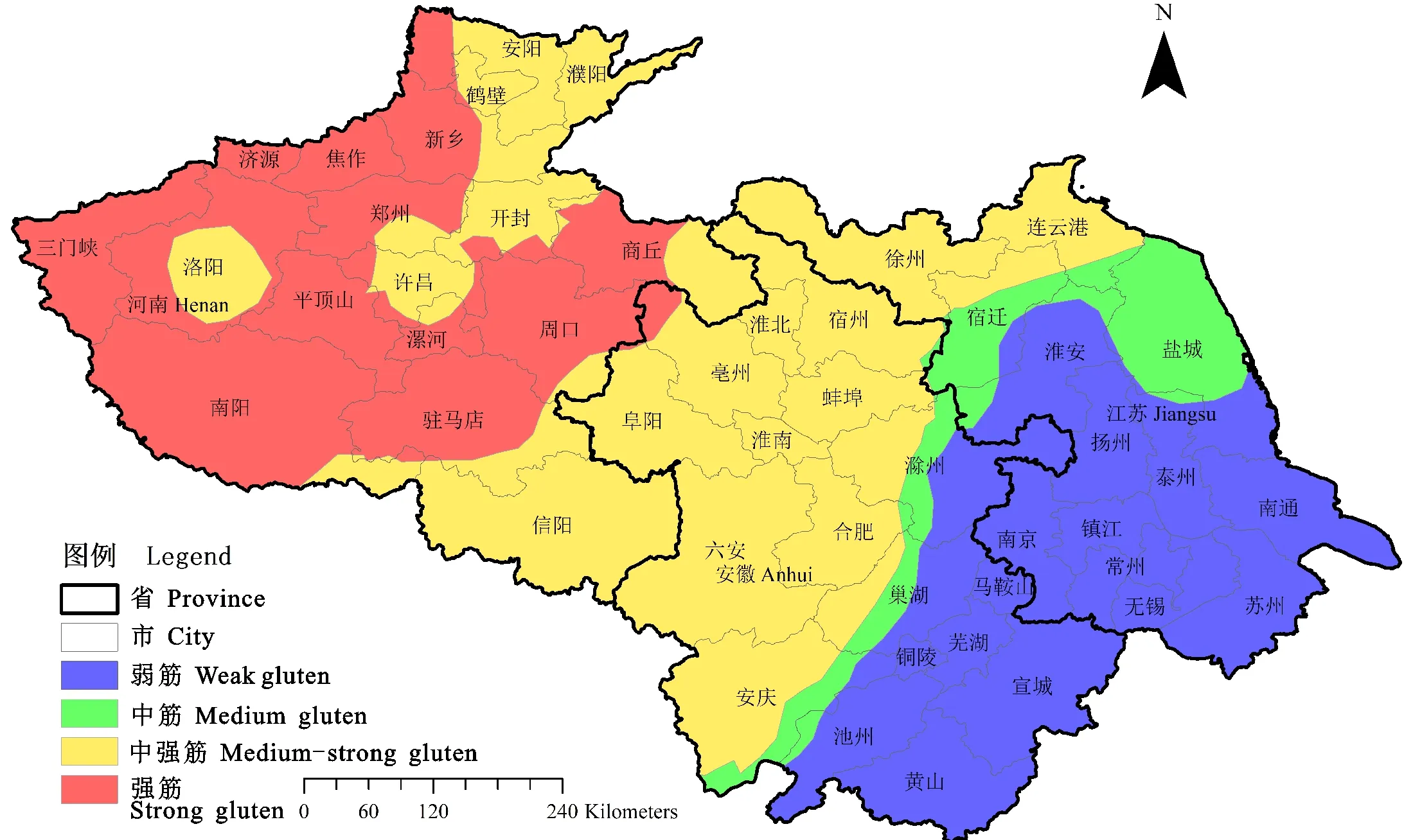
3 讨 论
3.1 气象因子对小麦籽粒蛋白质含量的影响
3.2 苏豫皖模型及区划分析
