一种基于LSTM的端到端多任务老挝语分词方法
2021-10-19郝永彬周兰江
郝永彬,周兰江,刘 畅
(1. 昆明理工大学 信息工程与自动化学院,云南 昆明 650504;2. 西南交通大学 信息科学与技术学院,四川 成都 611756)
0 引言
老挝是与我国接壤的国家,也是一带一路沿线国家,老挝语作为老挝的官方语言,是一种无空格切分的连续字母语言,同中文等无分割语言一样需要进行分词处理。老挝语有65个字母,包括元音、辅音、音调和数字字母,其文本构成为“由数个字母构成音节,由音节构成单词,进而构成完整的句子”[1]。老挝语分词是进行翻译等其他自然语言处理研究的前提,具有重要研究意义。
1 相关研究
面向老挝语的自然语言处理研究较少,现有分词任务的研究成果不多。前期研究中,主要以字符为基础处理元素,基于字符进行老挝语分词。传统的老挝语分词方法主要有基于字典的分词方法和基于传统机器学习的方法两类。基于字典的分词方法局限于字典的大小和匹配方法,难以处理字典中未登录的词,在同一语句中可能存在具有歧义的不同切分,依赖于人工指定的规则,难以真正实现老挝语分词。
随着机器学习在自然语言处理领域的广泛使用,机器学习算法为分词带来了新思路。机器学习是目前自然语言处理最常用的工具,其方法主要为通过流水线处理方式,将分词问题转化为序列标注问题[2],通过n-tag的方法,将词中不同位置的字符加以区分标注,再经过模型训练,建立起机器学习模型,通过模型对更多的序列进行标注分词。
n-tag标注为现在分词方法中最常用的标签标注方法,n可取值有2,4,6等。n-tag标注中最常见的为4-tag标注,即BMES标注,在老挝语分词过程中有较好的实际表现。在4-tag标注中,B(Begin)标签标注单词开始元素,M(Middle)标签标注单词非开始和结束的中间元素,E(End)标签标注单词结束元素,S(Single)标签标注独立成词的元素。通过n-tag标注的方法,可以将分词问题转化为序列标注问题,进而转化为针对每个元素的标签分类问题,再进而交由不同算法进行分词处理。
机器学习算法可分为传统的机器学习和神经网络两大类。可用于分词的传统机器学习方法有HMM、最大熵模型和条件随机场等,这几种模型在中文分词等分词领域已有较多的实现和改进,如基于半监督CRF的实现[3]等。在老挝语分词研究中,杨蓓等实现了基于HMM的老挝语分词方法[4],Vanthanavong等实现了基于CRF的老挝语分词方法[5],其准确率达到了80.29%。
神经网络中循环神经网络(Recurrent Neural Network,RNN)及其改进模型在自然语言处理领域具有良好表现并等得到广泛使用。长短期记忆网络(Long Short-Term Memory,LSTM)克服了循环神经网络中的梯度消失问题,同时还有可以对前序序列数据进行记忆和状态保存的优点,解决了其他方法处理范围局限于滑动窗口的问题。双自长短期记忆网络(Bi-directional Long Short-Term Memory,BiLSTM)继承了LSTM的优点,由于还进行了双向循环遍历,达到了记忆和关联上下文信息的效果,因此成为当下自然语言处理领域最常用的方法。
在中文分词中,Xu和Sun等实现了基于BiLSTM的中文分词[6],还有诸多基于神经网络的改进模型被应用于中文分词中,如同时进行多种粒度的切分[7]或同时基于多个语料集进行训练[8]等。而何力等同样实现了基于BiLSTM的老挝语分词模型[9],在此研究中,对基于音节的神经网络分词进行了探讨。
在已有研究中,音节的划分主要由人工归纳的语言规律产生,即老挝语音节以一个辅音为中心,周围由尾辅音、元音和音调加以修饰而形成,有辅音从“元音、声调、活闭音节、死闭音节”序列中从前到后依次增加的音节基本拼写规则,同时还有辅音与特定元音组合时不加尾辅音,存在死闭音节时不能加声调等额外规则。

综上,在已有的根据老挝语音节进行分词的研究中,均先使用分音节软件进行分音节处理,再进行分词处理的流水线操作,存在分音节不准、累计误差和错误传递的问题,而多任务联合学习[11]则可以进行多结果联合标注处理并结合多种特征。本文受上述研究启发,提出端到端的老挝语分词模型,即在同一模型中联合进行分音节和分词处理,以避免已有分步模型中存在的问题。
2 分词模型结构及流程
2.1 整体结构及流程概述
端到端的老挝语分音节及分词过程,可以视为一个序列的标注处理过程,即将一个输入的老挝语序列,经过全流程的神经网络处理及分类,得出4-tag标记的分词结果序列和分音节结果序列。本文所述的端到端神经网络老挝语分词模型主要由以下4部分组成:①预处理; ②分音节; ③分词;④输出。具体的流程框架如图1所示。

图1 老挝语分词模型流程图
对于输入的老挝语字符序列,首先经过预处理步骤,得到数字索引序列;然后通过分音节处理,获得音节标记序列输出,通过该辅助输出对应的神经网络损失函数,增强分音节部分模型训练效果,达到联合学习的目的;然后将字符索引序列和音节标记序列输入到分词神经网络中,通过音节标记增强分词效果,最终获得分词标记序列结果。
该模型每部分具体结构及处理流程如2.2到2.5节所述。
2.2 老挝语预处理

图2 老挝语字母对应Unicode编码
2.3 老挝语分音节
在模型中,将老挝语索引序列输入到分音节处理部分进行分音节处理。该部分将老挝语索引序列作为张量数据输入到神经网络中,先后通过Embedding层、BiLSTM层、Drop层和Dense层,将老挝语音节按照4-tag标记概率输出,输出每字符对应的4-tag标记的概率。在该部分中,为提高模型效果,构建出多输出神经网络模型,使用老挝语音节4-tag标签序列作为辅助输出,为模型的分音节部分的神经网络提供辅助损失,提高训练效果,该部分模型结构如图3所示。

图3 分音节部分模型结构
在本结构中,首先使用了Embedding层,将输入字符索引序列的One-hot表示进行张量映射;然后使用了BiLSTM对输入序列张量进行了处理,其中,单向LSTM的每个单元对于序列中一个时刻的元素输入xt、序列中上一个时刻的输出ht-1,有以下几个门和状态如式(1)~式(3)所示。
输入门it:
it=σ(Wi·[ht -1,xt])+bi
(1)
遗忘门ft:
ft=σ(Wf·[ht -1,xt])+bf
(2)
(3)
其中,σ()为sigmoid()激活函数,tanh()为tanh激活函数。
形成当前时刻的单元状态Ct,即LSTM中的长时记忆,如式(4)所示。
Ct=ft*Ct -1+it*Ct
(4)
输出门ot,如式(5)所示。
ot=σ(Wo·[ht -1,xt])+bo
(5)
输入门结合当前单元状态Ct,形成LSTM中的短时记忆,即输出ht,如式(6)所示。
ht=ot*tanh(Ct)
(6)
yt=σ(W*ht+b)
(7)
模型中权值矩阵W和偏置矩阵b通过交叉熵损失函数反向传播更新参数。
2.4 老挝语分词
在模型的分词部分,通过多输入神经网络结构,将老挝语字符索引序列及音节4-tag标记序列作为输入,在每字符位上进行字符索引及音节标记张量的concatenate拼接,在分词模型中增加音节标记序列表述的音节特征,其中,音节标记序列的使用相当于复用了分音节部分的神经网络,然后通过BiLSTM层、Dropout层、Dense层和CRF层,输出4-tag老挝语分词标签序列,至此完成神经网络模型“字符串-(音节序列,单词序列)”端到端结构。该部分具体结构如图4所示。
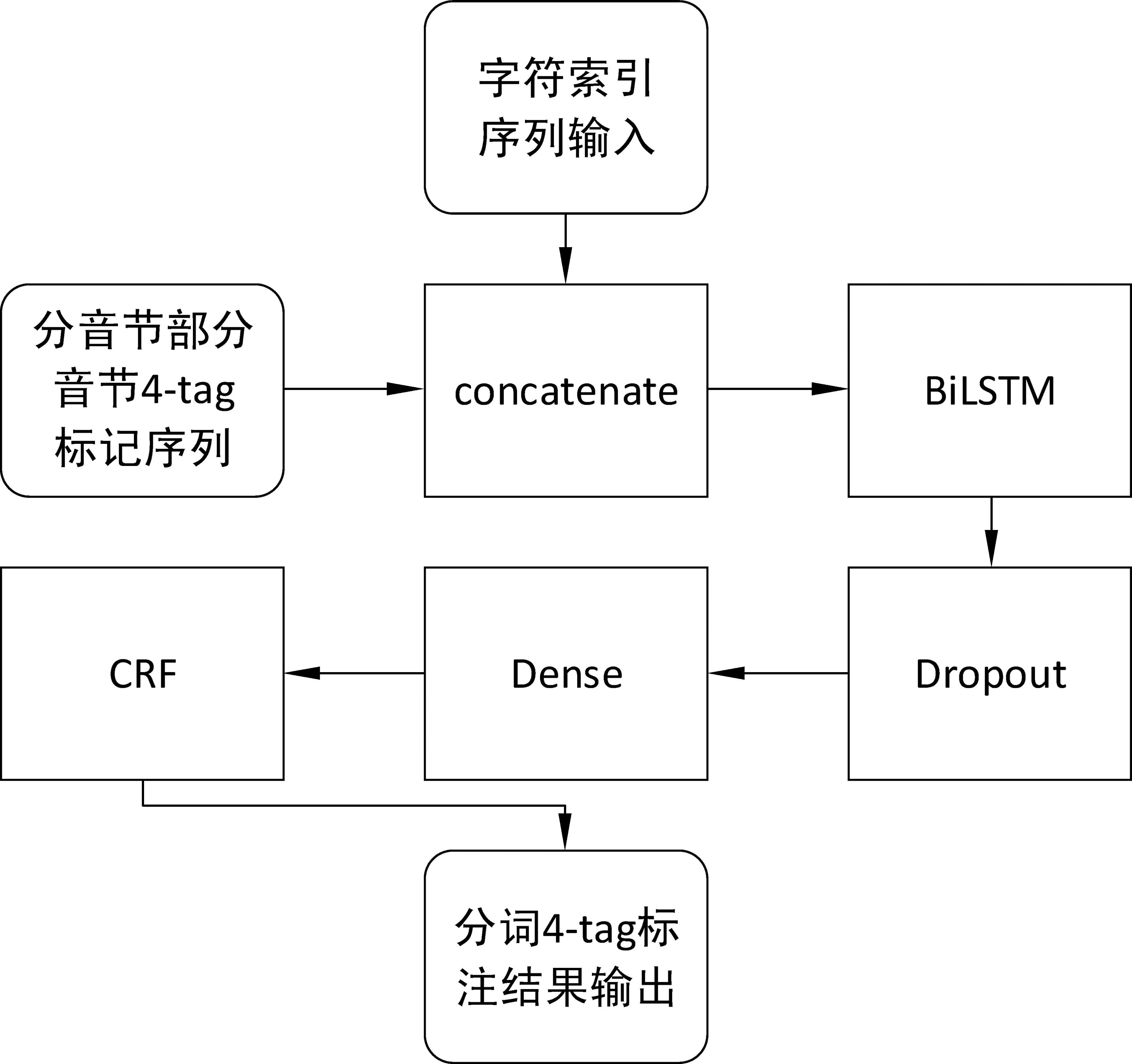
图4 分词部分模型结构
在该部分中,使用了与分音节部分相同的BiLSTM神经网络进行特征提取及分类,由于神经网络在对每个字符进行运算后,分别产生一个4-tag标签概率张量,即每个字符的标签。该标签仅考虑当前上下文该字符各分类标签的概率,而不考虑BMES标签的规则,可能会出现BBME、BSM等非法标签组合。为消除这种违反规则的标签输出,获取最大可能的正确序列,本模型加入CRF模型对输出标签进行推断,即针对长度为h的输入序列X(x1,x2,…,xh)和输出标记序列Y(y1,y2,…,yh),求得序列中的k个全局特征函数fk(Y,X)和分别对应的权重系数wk,由式(8)和式(9)得出条件概率P(Y|X),进而由维特比算法求解产生概率最高的标签序列,以提升分词模型整体效果。
2.5 模型输出
通过循环将模型输出的4-tag标记序列与输入老挝语字符序列相匹配,在E和S标签后输出空格,产生空格分隔的老挝语分词输出。
3 实验及分析
本模型基于Python语言和Keras(TensorFlow后端)机器学习库进行了实现,经过实验调试,在有限硬件及时间条件下获得较好结果的模型及关键结构层的超参数如表1所示。

表1 端到端分词模型及关键结构层超参数
3.1 语料预处理
由于老挝语自然语言处理研究较少,没有成规模的权威语料,本文模型训练依赖于由老挝门户网站搜集的,经多名老挝语专家人工分词及分音节标注的7.49MB大小的老挝语语料,共40 965行、67 784句、913 487词。在语料获取过程中,进行了原始语料爬取、/u200b等不可见字符及多余换行符去除、单词划分、音节划分、结果交叉验证等步骤,获取了质量较为可靠的老挝语分词及分音节语料。
3.2 实验设计与评估指标
本文将老挝语分音节及分词语料,按照90%训练集和10%测试集的划分方式,划分为两个集合,使用训练集对模型进行训练,并使用测试集进行结果测试验证。
实验方案一:为对比本文所述端到端分音节及分词模型与已有研究的性能差异,将本文所述模型使用训练集进行30次训练,输入测试集获得输出分音节及分词结果,与专家人工分音节及分词结果进行对比验证,并使用已有研究提供的工具或数据进行横向对比。
实验方案二:为了解本文多任务联合学习模型分词性能受分音节结果及特征的影响,将规则方法分音节、BiLSTM神经网络方法对音节分词[9]、多任务联合模型中抽取分音节部分和多任务联合模型中抽取分词部分作为四个流水线模块,交叉组合进行分词对比实验,获取实验结果,并与人工分词结果进行对比。在将分音节结果作为多任务模型分词模块输入时,根据流水线方式要求,进行4-tag特征概率0/1二值化赋值处理。
本文所做分音节及分词工作,模型性能可由分音节及分词的准确率(precision),召回率(recall)和F1值进行评判。
3.3 实验结果及分析
执行实验方案一得到分音节实验结果(表2)和分词实验对照结果(表3)。

表2 端到端模型分音节结果与已有研究对比

表3 端到端模型分词结果与已有研究对比
通过实验方案一的结果可知,本文所述模型较传统基于规则的分音节方法,分音节准确率提升了1.72%,达到了99.34%,F1值达到了99.31%,近似达到人工分音节水平,在处理外来音译词等不符合音节规则的词语时亦有良好表现。
本文所述端到端的分词模型,与基于音节的HMM模型、基于音节的CRF模型这两种传统机器学习方法相比获得了较为显著的性能提升。与基于规则方法分音节再使用BiLSTM方法分词的流水线方法相比,准确率提升了1.54%,F1值提高了1.42%。
以上实验结果说明,本研究较已有研究在分词性能上有所提升,在分音节性能方面已达到较高水平。
执行实验方案二得到的模型交叉组合对比结果如表4所示。

表4 模型交叉组合实验结果
通过实验方案二结果可知:
(1) 在流水线方案下,在使用规则方法进行分音节处理时,本文联合学习模型的分词部分性能较单纯BiLSTM模型分词性能(方法1、3比较)在准确率上提升0.61%,在F1值上提升0.57%;在使用本文模型的分音节部分进行分音节处理时,本文模型的分词部分性能较单纯BiLSTM模型分词性能(方法2、4比较)在准确率上提升0.53%,在F1值上提升0.54%。
(2) 在流水线方案下,本文联合学习模型的分词部分性能在接受本文联合学习模型分音节部分的输入时,较规则分音节输入(方法3、4比较)在准确率上提升了0.38%,F1值提升了0.26%。
(3) 本文所述端到端联合模型较去除了音节4-tag特征概率的同结构流水线模型相比(方法4、5比较),在准确率上提升了0.55%,在F1值上提升了0.59%。
以上实验结果说明,本文模型分音节性能的提升对于各分词方法性能提升均有所帮助。本文多任务联合学习模型的分词部分较以往BiLSTM分词模型性能有所提升,本文模型分音节部分的音节4-tag特征概率对分词部分性能有所提升,分音节及分词多任务联合学习训练的方法对提升模型分词性能有所帮助。以上对比说明本研究具有一定实际应用价值。
4 结束语
本文根据老挝语语言特点,在不进行人工特征指定的情况下,提出“字符串-(音节序列,单词序列)”的端到端老挝语分词及分音节神经网络联合学习模型,在同一模型中进行了基于BiLSTM的分音节和分词处理,提高了分音节结果的准确率,达到了近乎人工的标准,还减少了以往先分音节再分词的流水线操作造成的累积错误,在分词过程中增加了老挝语音节特征,实现了超越以往的表现效果,分词准确率达到了89.02%。
本文所做工作受限于老挝语可用分词语料的规模较小,远低于中文分词sigHan等其他语言数据集规模,难以达到更好的实验效果,在以后的研究中,应增加可用语料的积累,以期达到更好的分词效果。
