基于自适应遗传粒子群算法的配电网故障定位
2021-10-19杨洪杰赵梦琪张尚德
张 莲,宫 宇,杨洪杰,李 涛,赵梦琪,张尚德,贾 浩
(1.重庆市能源互联网工程技术研究中心, 重庆 400054; 2.重庆理工大学 电气与电子工程学院, 重庆 400054)
当配电网节点发生故障时,故障快速准确定位是排除配电网故障以及恢复故障处供电的前提,也是保证整个配电网乃至整个电力系统稳定运行的重要环节[1]。随着全球分布式发电技术的迅速发展,大量的分布式电源(distributed generator,DG)接入配电网,传统配电网变为结构更复杂、潮流方向不单一的含分布式电源的有源配电网(active distribution network,AND)[2]。因此,寻求一种新的定位方法对有源配电网进行故障定位成为亟需解决的问题[3]。
随着馈线终端设备(feeder terminal unit,FTU)的大范围使用,在开关节点处可实时获取配电网电压、过电流等运行信息,利用运行信息进行配电网的故障区段定位成为当前主流的方式[4]。目前,主流的方法包括遗传算法、人工蚁群算法、粒子群算法、免疫算法、蝙蝠算法等智能算法。杜红卫等[5-7]利用遗传算法解决配电网故障定位问题,取得全局最优值,但准确度不高;陈歆技等[8-9]分别利用人工蚁群算法和蝙蝠算法进行配电网故障定位,但对畸变信息的容错率低;马少飞等[10-11]利用免疫算法和粒子群算法进行故障诊断,但当存在故障信息缺失时,不能准确判断故障区段。以上算法均只适用于传统配电网中,因为当含分布式电源接入配电网后,过电流信息就发生了改变。
针对以上不足,提出了一种基于自适应遗传粒子群算法(adaptive genetic algorithm-adaptive binary particle swarm optimization,AGA-ABPSO)的有源配电网故障定位方法。并对0~1整数规划模型进行了改进,使之适用于含DG的有源配电网模型。利用Matlab进行仿真测试,对所提方法的可行性进行验证,并与其他算法进行对比。结果表明,该算法能够准确定位故障区段,收敛速度快,且当故障信息畸变或缺失时,具有很高的容错性。
为表述方便,本文中的混合算法均表示自适应遗传粒子群算法。
1 有源配电网故障整数规划模型
馈线终端设备的大量应用使电力人员能够在开关节点处实时获取配电网的运行信息,利用这些信息快速便捷地进行故障区段定位[12]。而智能算法具有高容错性,能够对离散变量进行快速地处理分析。馈线终端设备和智能算法结合能够对有源配电网进行相对于传统方式更具优势的故障区段定位。
当发生故障时,根据FTU上传的开关节点处的过电流信息,可利用有源配电网故障整数规划模型将复杂的配电网故障信息转化为由整数表述的故障向量。
1.1 传统配电网故障整数规划模型
在不含分布式电源的传统配电网中,通常使用0~1整数规划模型进行计算。简单配电网网络如图1所示。图1中,G为系统电源,S1~S6为开关节点,L1~L6为相对应的馈线区段。
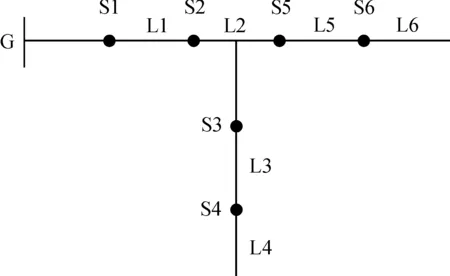
图1 单电源配电网络示意图
以图1为例,由于配电网中只有1个电源接入,其中的过电流一直由系统电源流向负载处,当区段发生故障时,区段所在的开关节点有故障过电流流过,此时开关节点的状态值为“1”,而没有故障过电流流过的开关节点的状态值为“0”。即对单个开关节点来说,只需要考虑下游区段是否发生故障[13]。即开关的状态值可由式(1)表达。

(1)
1.2 配电网故障整数规划模型的改进
由于分布式发电技术的迅速发展,分布式电源也大量接入配电网中,导致故障后有源配电网的潮流方向发生了改变,馈线之间的上下游关系受到 DG 接入的影响[14]。基于此,对传统配电网故障整数规划模型进行改进,构建了适用于有源配电网的故障整数规划模型。
改进的故障整数规划模型包括“0”“1”“-1” 3种参量。本文中规定系统电源流向负载处的过电流方向为正方向,以避免不同位置分布式电源接入带来的影响。当馈线终端设备上传的故障电流方向与正方向一致时,取Ij=1;若检测到的故障电流方向与正方向相反时,取Ij=-1;若未检测到故障电流,则取Ij=0。即开关的状态值可由式(2)表达。

(2)
以图2所示有源配电网中的开关节点为例,当区段L7处发生故障时,流过开关节点S7的故障电流方向为系统电源G流向负载,与正方向相同,则S7的状态值为“1”;当区段L6发生故障时,流过开关节点S7的故障电流方向为DG1流向负载,与正方向相反,则S7的状态值为“-1”。
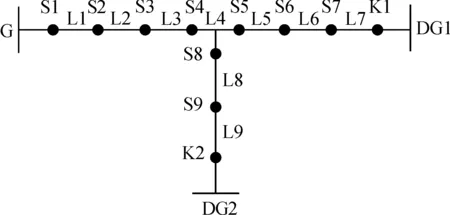
图2 有源配电网络示意图
1.3 开关函数的构造
开关函数是根据开关节点处监测到的故障过电流信息和线路区段本身的状态之间的关系而构造的函数[15]。开关函数能使自适应遗传粒子群算法更好地利用和分析开关节点处的过电流信息,进而判断出故障点的位置。
在传统配电网中,开关函数较为简单,表述为该开关节点下游所有馈线区段状态的逻辑或运算,即:
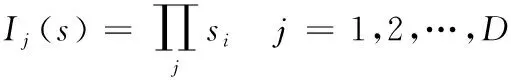
(3)
式中:Ij(s)为开关函数值;si为开关节点j下游第i个馈线区段的状态值;∏表示逻辑或运算。若开关节点j下游任意一个馈线区段发生故障,则开关函数值为1,无故障发生则开关函数值为0。
在有源配电网中,要考虑不同位置的分布式电源的接入与否。对于一个开关节点来说,不仅需要考虑下游的馈线区段,由于同时存在着上游馈线区段带来的影响,因此上述的开关函数不能继续使用,需要构造一个新的开关函数,如式(4)~(6)所示。
Ij(s)=Iju(s)-Ijd(s)
(4)
(5)
(6)
其中,以开关节点j为分界线,将有源配电网分为上游和下游两部分:上游和下游分别为含有系统电源和分布式电源的部分。开关函数值为上游函数值Iju(s)与下游函数值Ijd(s)的差值。Sj,Gu、Sj,Gd分别表示开关节点j到上游系统电源Gu和下游分布式电源Gd之间的馈线区段的状态值;Sj,u、Sj,d分别表示上游部分和下游部分所有馈线区段的状态值;M1、N1分别为上游部分与下游部分电源的数量;M2、N2分别表示上游部分与下游部分所有馈线区段的总数;∏表示逻辑或运算;Ku、Kd则表示上游与下游部分电源的接入系数,当有电源接入配电网中时,其值为“1”,无电源时,取值为“0”。
2 AGA-ABPSO算法的原理
2.1 自适应遗传算法的原理
遗传算法(genetic algorithm,GA)是由霍兰德[16]以基因的自然选择和遗传变异为理论依据,在20世纪70年代提出的全局性概率型搜索优化模型。传统的遗传算法里,交叉概率、变异概率为固定值,使取值较为困难。取值太大在算法后期会破坏优秀个体,太小则使算法前期搜索能力较差[17]。针对此问题,利用文献[18]中所提出的方法对交叉概率和变异概率进行相应改进,使其能够基于每个个体相对应的适应度函数值自适应地调整交叉概率、变异概率,提升其寻优的快速性。改进后的交叉概率、变异概率为:

(7)

(8)
其中:fmax代表种群中最大适应度函数值;favg代表每代种群的平均适应度函数值;f代表进行交叉操作的2个个体中较大的适应度函数值;f′代表进行变异操作的个体的适应度函数值。另外,k1=0.9,k2=0.6,k3=0.1,k4=0.01。
2.2 自适应粒子群算法的原理
粒子群优化算法(particle swarm optimization,PSO)[19]作为近年来发展较好的智能算法之一,最早在1995年由Kennedy和Eberhart提出。它是一种根据对鸟类捕食行为的研究而提出的智能算法。粒子群算法通过不断更新速度和位置来寻找全局最优值[20]。其速度和位置更新表示为:
(9)
(10)

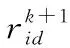
(11)
通常,为了防止sigmiod函数的饱和,将粒子的速度限定在区间[-4,4]。sigmiog函数为
(12)
为了更好地平衡粒子的搜索行为,克服粒子群算法容易过早收敛、陷入局部极值的缺点,利用文献[22]中提出的基于适应度值的自适应惯性权重的方法。方法如下:
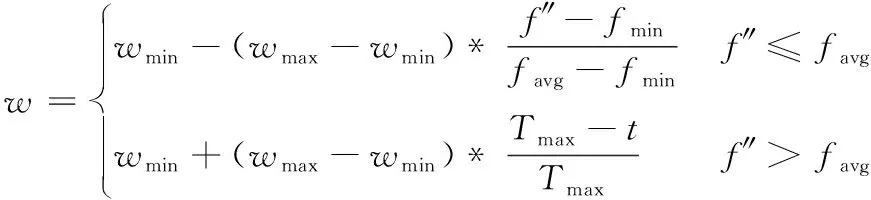
(13)
其中:wmax和wmin分别为惯性权重的最大值和最小值,通常取wmax=0.9,wmin=0.4;f″、fmin、favg分别为粒子的当前适应度、最小适应度和平均适应度;t和Tmax分别表示当前迭代次数和最大迭代次数。
另外,根据粒子群算法在搜寻迭代初期更需要全局搜索、搜索迭代后期更需要快速收敛的特征,在保证粒子群种群多样性和快速收敛性的情况下,采用动态调整加速因子,提出一种自适应加速因子的改进方法[22]:
(14)
其中:c1max、c1min、c2max、c2min分别为加速因子c1和c2的最大值、最小值;t表示当前迭代次数;Tmax代表最大迭代次数。对于加速因子最值,选取c1max=1.3、c1min=1.1、c2max=2.0、c2min=1.2。
3 自适应遗传粒子群算法的故障定位模型及算法流程
3.1 自适应遗传粒子群算法故障定位的原理
当配电网发生故障时,网络中的馈线终端设备可以检测到故障过流信息。首先,利用改进后的配电网整数规划模型将故障过电流信息转化为整数表达的故障向量,即当FTU检测到有正向的故障电流流过开关时,取向量值为1;若检测到反方向的故障电流,取向量值为-1;若未检测到故障电流,则取向量值为0。然后,利用重新构建的适用于有源配电网的开关函数,得到故障区段的等效故障向量,并以此为算法的输入,以配电网馈线区段总数为粒子群算法的种群维度和遗传算法的编码长度,以评价函数作为算法的目标函数,以算法的粒子群最优粒子的位置作为算法的输出,进行仿真测试,最终做出对故障区段的判断。
3.2 评价函数的构造
合理的评价函数能使优化算法实现更准确的故障区间定位。本文中的评价函数即为混合算法的适应度函数。传统的有源配电网的评价函数为:
(15)
但是,在实际计算过程中,由于过电流信息畸变或缺失等情况,导致评价函数不能取极小值,造成对故障区段的误判,因此对含DG的有源配电网进行改进,引入“最小集”的概念[23],如式(16)所示。
(16)
式中:M为馈线区段总数,一般而言,M=N;θ表示修正系数,取值范围为0~1,此处取值θ=0.5;SB(j)表示各个馈线区段的状态值。
3.3 算法流程
算法具体流程如图3所示。Pc、Pm分别表示遗传算法的交叉概率和变异概率。

图3 基于自适应遗传粒子群算法的有源配电网 故障定位流程框图
混合算法以粒子群算法为主体,通过引入自适应遗传算法的选择、交叉与变异操作,将交叉算子与变异算子嵌入到自适应粒子群算法中。为使良好个体尽可能多地遗传到下一代,确保算法的全局收敛,采用最优解保存策略实现优胜劣汰,降低交叉、变异操作带来的随机性影响[24]。
4 算例仿真
以图4所示的IEEE 33节点的有源配电网为例进行仿真。其中,G为系统电源,DG1、DG2、DG3为3个分布式电源,K1、K2、K3为分布式电源的接入开关,当分布式电源接入时,取值为“1”,否则取“0”;S1~S33表示开关节点,L1~L33表示馈线区段。
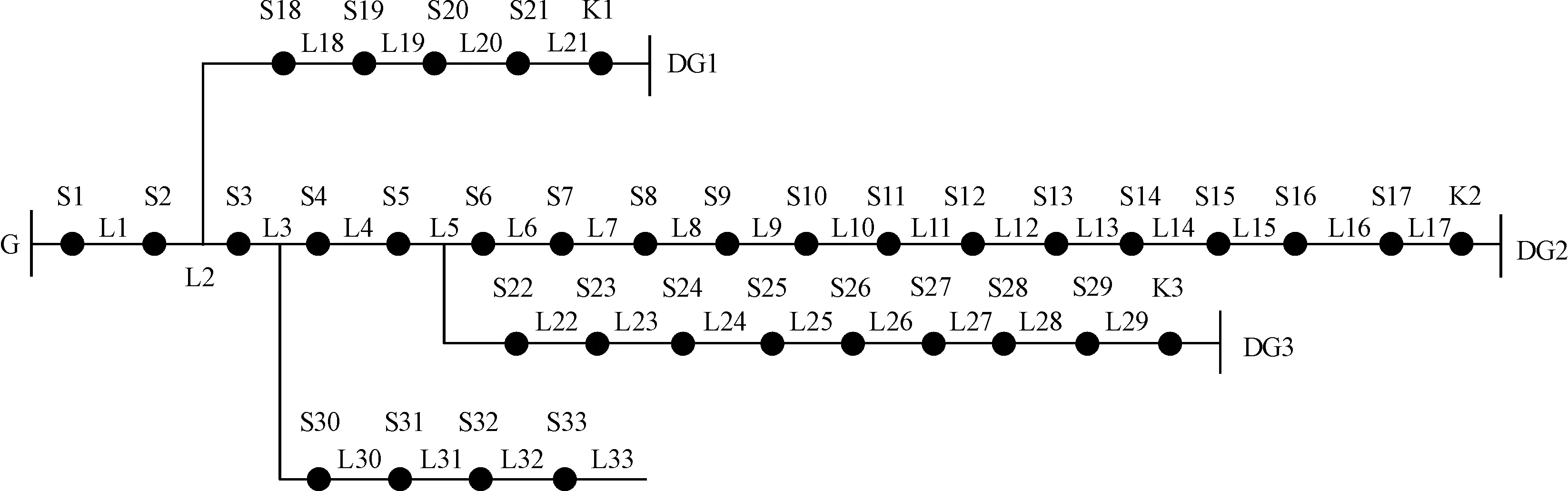
图4 33节点有源配电网示意图
4.1 算例仿真分析
实验所用的故障定位程序由Matlab2019a编制。本次仿真AGA-ABPSO的参数设置:种群数m=50,遗传算法最大迭代次数n1=50,粒子群最大迭代次数n2=50,遗传算法的二进制编码长度以及粒子群维数与配电网馈线区段总数相同,即粒子群种群维数D=33,编码长度L=33,惯性权重最大值wmax=0.9,惯性权重最小值wmin=0.4。
4.1.1DG未接入的情况
当配电网中未接入DG时,即开关状态[K1 K2 K3]=[0 0 0],为传统配电网的模型,开关只有“0”和“1”状态。仿真结果如表1所示。不难看出,当单一馈线区段和多个馈线区段发生故障时,均能准确定位故障区段。

表1 DG未接入时故障定位仿真结果
4.1.2DG接入并计及信息畸变
当DG接入配电网中,不同故障类型的定位结果如表2所示。

表2 DG接入时不同类型故障定位结果
由表2可知,在不同位置的DG接入后,算法均能准确判断故障区段。当单一馈线区段和多个馈线区段发生故障时,均能进行准确的故障区段定位。在部分FTU上传的故障过电流信息缺失和畸变的情况下,混合算法同样能够准确定位故障位置。由仿真结果可知,混合算法具有可行性,能动态适应DG的接入与否,同时对缺失和畸变的故障信息具有高容错性。
4.2 算法对比分析
为了突出混合算法在故障定位中的优势,将混合算法与标准粒子群算法(BPSO)以及带压缩因子和线性递减惯性权重的改进粒子群算法(IBPSO)进行不同故障类型的对比。
BPSO以及IBPSO参数设置:种群数m=50,最大迭代次数n=100,种群维数D=33,wmax=0.9,wmin=0.4,C1=C2=2.05。线性递减惯性权重和压缩因子如式(17)(18)所示。
(17)
(18)
式中:t为当前迭代次数;Tmax为最大迭代次数;φ为压缩因子,φ=C1+C2。
4.2.1容错性、快速性对比分析
针对不同的故障类型,即无故障信息畸变时单一区段发生故障、多个区段发生故障以及存在故障信息漏报和畸变的单一区段发生故障、多个区段发生故障,来进行算法准确性、快速性、容错性的对比分析。BPSO、IBPSO、AGA-ABPSO 3种算法的迭代曲线如图5所示。

图5 不同故障类型的BPSO、IBPSO、AGA-ABPSO算法迭代曲线
1) 预设DG1、DG2、DG3这3个分布式电源均接入电网,馈线区段L27发生故障,FTU上传的故障信息无畸变。通过图5(a)的结果对比可知,3种算法均能在最大迭代次数内取极小值,准确定位故障区段。AGA-ABPSO算法能最快取得全局最优值,IBPSO次之,BPSO最慢,平均迭代次数超过35次。
2) 预设DG1、DG2、DG3这3个分布式电源均接入电网,馈线区段L27发生故障,FTU上传的开关S7、S9、S12、S14故障信息发生畸变。由图5(b)对比分析可知,当故障信息发生畸变时,BPSO算法长时间陷入局部最优值中,即便最终取得了全局最优值,但迭代次数明显多于其余两种算法。对比之下,AGA-ABPSO算法对于存在畸变的故障信息仍能准确快速地确定故障位置。
3) 预设DG1、DG2、DG3这3个分布式电源均接入电网,馈线区段L9、L23发生故障,FTU上传的故障信息无畸变。根据图5(c)的结果可知,利用AGA-ABPSO算法时,平均迭代次数少,能够快速准确地对故障区段进行定位。IBPSO算法平均迭代次数较多,在前期过早收敛而陷入局部极值,但最终能够在50次左右取得全局最优值。BPSO算法在即将达到最大迭代次数前取得全局极值,但在寻优过程中多次陷入局部最优值,几乎不能准确地进行故障定位。
4) 预设DG1、DG2、DG3这3个分布式电源均接入电网,馈线区段L9、L23发生故障,FTU上传的开关S12、S14、S16、S20故障信息发生畸变。由图5(d)不难发现,AGA-ABPSO算法在故障信息畸变的影响下,虽然迭代次数有所增加,但仍然能够准确地确定故障区段。存在大量畸变信息的情况下,IBPSO算法不能在最大迭代次数内取得全局极值,且过早收敛陷入局部最优值。BPSO算法达到最大迭代次数时,仍未计算出全局最优值,早熟问题严重。
综上所述,BPSO算法容易过早收敛而陷入局部最优值,且迭代次数较多;IBPSO对于畸变故障信息容错性差,迭代次数较多,以上两种算法均不适用于存在畸变故障信息的有源配电网。本文中提出的AGA-ABPSO算法能在存在大量畸变信息的情况下快速取得全局极值,准确地定位故障区段,具有较好的稳定性,可快速收敛,容错能力强,适用于多支路的有源配电网。
4.2.2准确性对比分析
在3个分布式电源均接入的情况下,预设不同类型的故障,分别对3种算法进行30次仿真测试,并进一步进行准确性对比。3种算法准确率如表3所示。
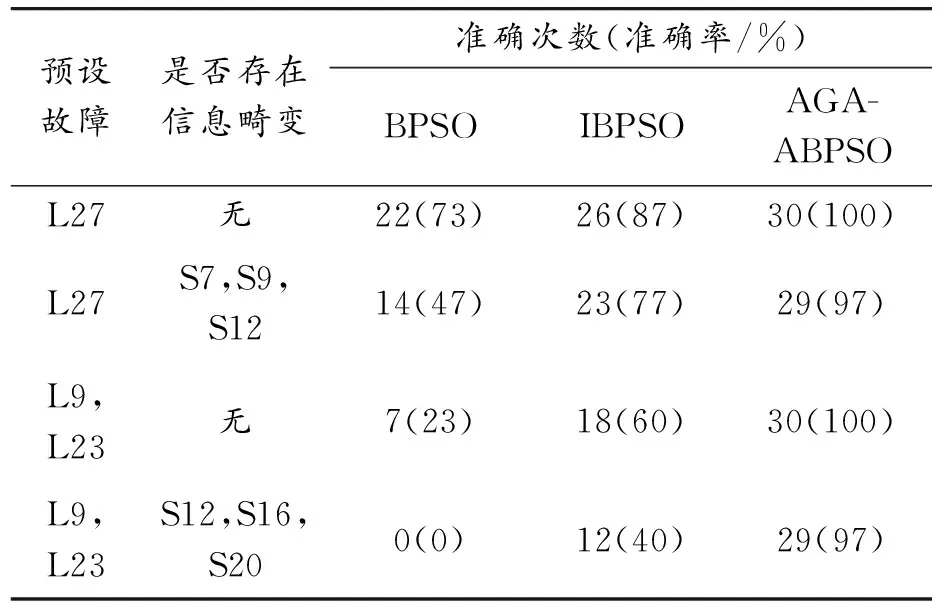
表3 3种算法准确率
通过表3的准确率对比可以看出,BPSO算法对于多个区段发生故障且存在大量故障畸变的情况,几乎不能进行故障诊断,对于单一区段发生的故障定位准确率也不高,应用于大型配电网的意义不大;IBPSO算法相对于BPSO算法准确率有所提高,但对畸变故障信息容错性较差;AGA-ABPSO算法在多个区段发生故障时,有较高的定位准确率,且对于畸变的故障信息具有较高的容错性。
5 结论
利用自适应遗传粒子群混合算法对有源配电网进行故障定位,验证了混合算法具有较高的准确性。通过混合算法与标准粒子群算法、改进粒子群算法的对比研究表明,混合算法应用于有源配电网时计算效率更高,同时对畸变的故障信息容错性更好,凸显了混合算法在故障定位中的优越性。
