基于模式匹配的交通微博文本位置信息提取模型
2021-10-18谭永滨,侯梦飞,张志军,李小龙,程朋根*,章泽之
谭 永 滨,侯 梦 飞,张 志 军,李 小 龙,程 朋 根*,章 泽 之
(1.东华理工大学测绘工程学院,江西 南昌330013;2.天津市测绘地理信息研究中心,天津 300381)
0 引言
及时获取有效的路况信息是实现智能交通服务的重要前提,其中道路的拥堵情况是路线智能规划的重要影响因素。目前道路拥堵信息的采集方式有基于路口传感器的实时监测、结合手机地图软件的浮动车采集等,上述方式虽能较准确分析拥堵信息,但受限于传感器铺设位置、拥堵情况语义不明等原因,无法及时获取道路突发拥堵信息。作为当前主流的互联网信息分享方式,微博已成为交通信息及时发布的重要渠道,从中提取路况信息可作为目前采集方式的重要补充[1,2]。位置是道路拥堵信息的重要组成,如何准确有效地从微博文本中提取位置信息是实现路线智能规划的基础之一。
线性参照方法(Linear Reference Methods,LRM)利用与已知点的距离或方向,确定线性要素任意未知点位置[3],是交通事件文本中常用的位置表达方法。LRM包括参照地理实体与空间关系两个基本元素,元素间的关联状态常用具有指示作用的空间关系词描述[4,5],表达模式的定义则隐含于位置文本的句法结构中[6]。其中,地理实体识别及提取方法有利用已有地名库或词典的地理命名实体提取方法[7,8]、基于机器学习或规则库的参照地名提取方法[9-11]、通过提取隐含的方位关系[12]或距离关系[13]进一步提高定位准确性的方法等[14,15]。针对空间关系的提取方法主要包括基于模式匹配及机器学习两类算法。前者利用匹配算法识别与待抽取文本相同或相近的位置表达模式,进而抽取文本中蕴含的位置信息[16,17],对于中文文本的空间关系主要采用受限句法模式识别抽取空间关系角色[18],在语料标注的基础上实现空间关系的形式化表达及抽取[19,20],其对模式变化较小文本的信息提取效率较高,但需提前建立模式库;后者则利用与空间关系描述相关的词语或语法[21],结合条件随机场、支持向量机、隐马尔可夫模型等算法构建分类器,识别不同的空间关系角色[22],进而提取文本中的空间关系[23,24],该类方法能有效避开模式匹配算法中位置表达模式缺失的问题,适用于模式多样的信息提取,但依赖大量已标注的语料库。
虽然交通微博文本中位置的描述形式多样,但权威用户发布的交通微博文本主要基于线性参照方法描述位置信息,该描述模式较规律,如“八一大桥东向西上桥处发生两车剐蹭”“目前皇岗路梅陇人行天桥路段南往北方向出现拥堵的情况”等。因此,针对交通信息及时性的实际需求,可采用模式匹配法快速有效地提取微博文本中的位置信息。空间特征词的角色(定位起点、终止方向等)是文本位置表达模式的重要组成部分,主要指空间特征词在位置表达模式中的作用。基于上述角色属性,可将文本位置表达模式的匹配表达为空间特征词在不同角色间的跳转,而有限状态机(Finite State Machine,FSM)是解决状态(或对象)跳转问题的模型。因此,本文面向交通领域,基于线性参照方法的特点构建文本位置表达模式,并将特征词角色映射为有限状态机中的状态,利用状态转移规则实现微博文本中位置表达模式快速匹配,据此提出基于有限状态机的位置信息提取模型,以期实现交通微博文本中位置信息结构化。
1 交通微博文本位置信息提取模型
本文构建的交通微博文本位置信息提取模型实现流程(图1)为:1)基于线性参照方法(LRM)的位置表达模式库构建。基于LRM表达的位置信息是微博文本描述交通信息的重要部分。首先分析交通微博文本中位置表达的句法特征,进而基于空间特征词及其在句法中的角色构建位置表达模式,并基于Trie搜索树结构实现模式的统一形式化表达。2)基于有限状态机(FSM)的交通微博文本位置信息提取。将交通微博文本位置转换为空间特征词及其词性的文本词对象集合,同时结合位置表达模式库建立与FSM元素的映射,依据FSM状态转移函数匹配出微博文本中合适的位置表达模式,实现位置信息的快速准确提取。

图1 交通微博文本中位置信息提取模型流程Fig.1 Flowchart for the model of location information extraction from traffic microblog text
1.1 基于LRM的位置表达模式库构建
(1)LRM位置基本表达形式分析。交通事件中的位置表达通常以交通路网为基础,先以桥梁、道路、路口、POI等点状与(或)线状地理实体为参照物实现初步定位,再结合方位关系与(或)距离关系定位至参照物附近的具体点位或路段。本文分析交通微博文本中位置表达的句法特征,基于LRM构建微博文本位置信息的基本表达形式(表1)。其中,定位线指各道路或桥梁等线状地理实体,常作为主参照对象;定位点通常指两条道路交叉口、某路段起始路口等点状地理实体,常作为辅助参照对象。
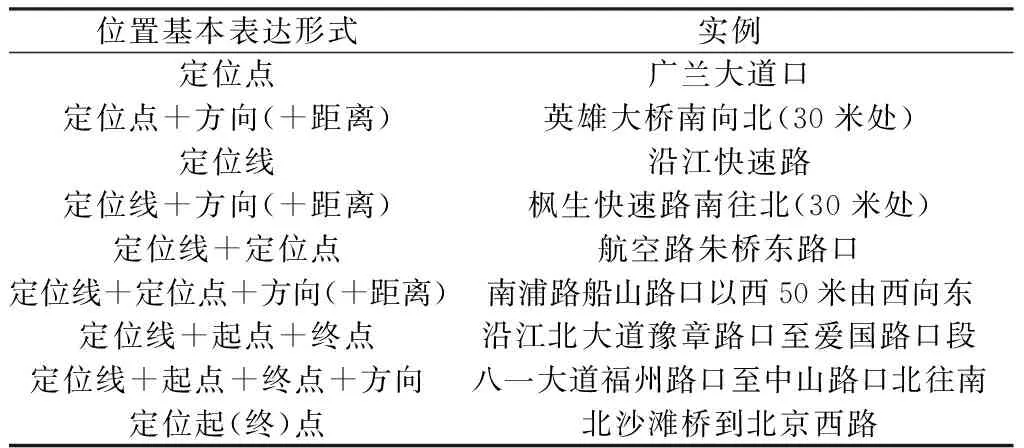
表1 交通微博文本位置信息的基本表达形式Table 1 Basic expression patterns of location information in traffic microblog texts
(2)文本位置表达模式定义。位置表达模式是文本位置信息识别和提取的基础,描述了空间特征词的词性及其在位置表达模式中的角色。本文将表达模式定义为由多个空间特征词对象(e= {pos/role},pos、role分别为空间特征词的词性和角色属性)组成的序列,即LocPattern= {e1,e2,…,en}。除采用语料库已人工标注的词性代码外,本文针对交通微博文本的特征,进一步扩充词性库(表2),用于标注路桥名称词、附属定位词、POI名称、特殊限定词等特征词,并定义文本位置表达中常见的空间特征词角色属性(表3),描述不同特征词在位置表达模式中的作用。

表2 交通文本空间特征词词性及代码Table 2 Part-of-speech and code of spatial words in traffic texts

表3 空间特征词角色属性Table 3 Role attributes of spatial words
本文以交通微博文本位置的基本表达形式(表1)为基础,结合空间特征词之间由介词等指示词连接成的实体关系,建立12种核心位置表达模式(表4)。为避免因表达模式库不完整导致特征词提取失败等问题,本文在各核心模式的空间特征词对象前后,增加附属定位词或特殊限定词,以扩展位置表达模式库。例如,在模式“{nsr/rm,f/fs,nsr/rs}”中增加附属定位词(ndrs),扩展为“{nsr/rm,ndrs/null,f/fs,nsr/rs,ndrs/null}”,可提取“龙观快速辅道北行白石山隧道出口”中的“辅道”信息。最终,本文共采用30种位置表达模式提取位置信息。

表4 核心位置表达模式及示例Table 4 Core location expression patterns and examples
(3)基于Trie搜索树的位置表达模式库构建。通过分析位置表达模式的特征发现,各模式序列的起始部分均存在一定长度的相同序列项。Trie搜索树是一种用于快速检索的多叉树结构,其特点是利用树结构中的公共祖先节点降低查询时间开销,提高效率[25]。本文采用Trie搜索树结构化位置表达模式,利用各位置表达模式的相同序列项减少查询时间,提高位置表达模式的匹配效率。针对Trie搜索树结构的存储特点,对基于Trie搜索树的位置表达模式库构建如下约束:1)位置表达模式中的空间特征词对象表达为Trie搜索树中的节点,每个节点包含特征词词性pos和角色属性role;2)位置表达模式库结构仅有一个不包含任何值的根节点(root);3)各位置表达模式的相同特征词只存储一次;4)位置表达模式对应自root节点向下跳转的路径,即ei+1为ei的子节点,模式末位特征词的节点标记为终止节点。图2为基于Trie搜索树结构的核心位置表达模式库,其中每个深色节点均代表一个位置表达模式的终止节点,其可能是其他模式的中间节点;root节点与每个终止节点间的路径均对应一个位置表达模式。如模式{nsr/rm,nsr/rs,f/fs,p/null,f/fe}可表示为图中粗箭头形成的路径,其中节点{nsr/rs}既是该模式的中间节点,又是模式{nsr/rm,nsr/rs}的终止节点。

图2 基于Trie搜索树表达的核心位置表达模式库Fig.2 Trie tree structure of core location expression patterns
1.2 基于FSM的交通微博文本位置信息提取
(1)位置表达模式库与FSM元素映射。FSM是用于描述有限个状态及各状态之间转移和动作等行为的数学模型[26],其五元组结构表达为M={V,S,s0,σ,F}。将位置表达模式库的Trie搜索树结构表达为FSM模型,二者的映射关系如表5所示。其中空间特征词对象的角色属性映射为FSM中的状态,词性作为触发状态转移的关键词;依据各树节点的先后顺序,将Trie搜索树结构表达为空间特征词转移规则表,即状态转移规则表(部分示例见表6),表中每行的规则表示当前状态(角色)在遇到不同词性的特征词对象时,可能发生的几种状态转移(角色关联)情况,包括下一状态、不可跳转等;状态转移函数sj=T(si,pos)是利用状态转移规则实现状态间的跳转,即假定当前状态为si,若遇到词性为pos的文本词对象,则会触发从当前状态si跳转到sj。

表5 FSM五元组元素与位置表达模式库的映射关系Table 5 Mapping between elements of FSM and location expression patterns
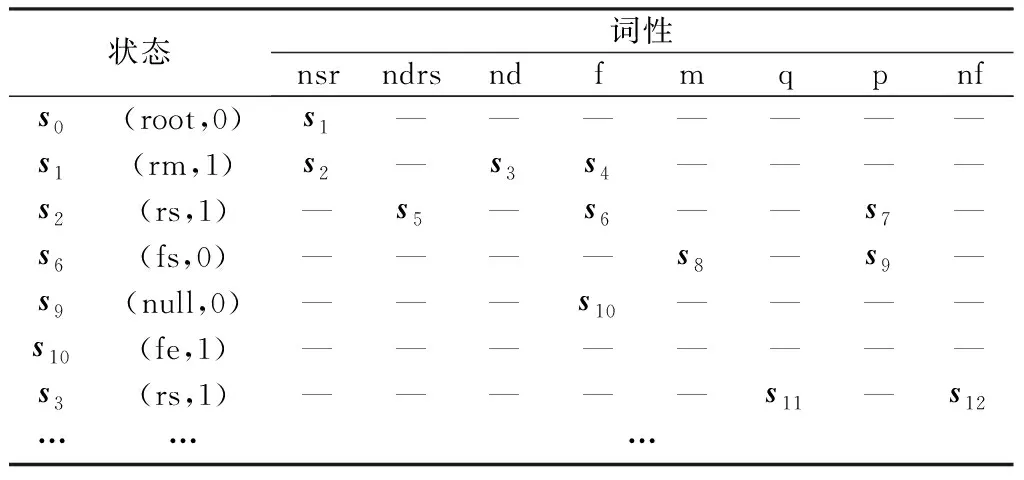
表6 空间特征词转移规则示例Table 6 Some examples of transfer rules among spatial words
(2)微博文本中位置信息提取。经过预处理后,先将微博文本转换为包含词语及其词性的文本词对象序列V。位置表达模型的匹配算法是实现位置信息提取的核心部分,该匹配算法(图3)基于文本词对象的词性,利用状态转移函数提取状态转移路径,匹配出与微博文本合适的位置表达模式,并建立与文本词对象序列对应的角色属性序列,最终实现微博文本位置信息提取。基本步骤包括:1)建立状态堆栈SA及状态—词关系映射S-V。根据状态转移函数,判断在当前状态sc下,文本词对象vi的词性posi是否能触发状态的跳转,如果可跳转,则将sc跳转到下一状态snext,同时记录snext至状态堆栈SA以及vi与状态snext的映射关系表S-V中,若记录的是第一个状态则定义为ss,接着重复步骤1),处理下一个文本词对象vi+1;若不可跳转,则执行步骤2)。2)构建候选位置模式集合PA。判断已记录的状态堆栈SA中是否存在终止状态,若存在则将该终止状态定义为se,并建立ss与se间的“状态转移路径”,作为候选位置模式存储在PA中;否则重置当前状态sc为初始状态s0,处理下一个文本词对象vi+1。3)结构化位置信息提取。当所有文本词对象遍历完成后,选择PA中序列最长的候选位置模式,并基于状态—词关系映射S-V提取该序列中每个状态对应的词语,完成微博文本的位置信息提取。
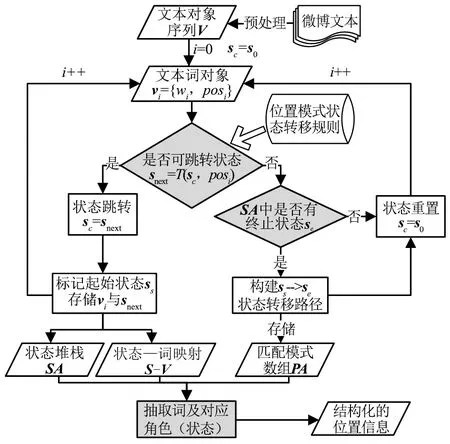
图3 基于FSM的位置信息提取算法流程Fig.3 Flowchart of location information extraction based on FSM
2 模型评价与分析
2.1 实验数据及预处理
本文利用Python自动爬取新浪微博文本,构建实验数据集,利用Java设计工具提取微博文本位置信息,位置表达模式存储于MySql数据库中;实验硬件环境为Windows 10操作系统,处理器为双核Intel(R) Core(TM) i5-4210M CPU @ 2.60 Hz,内存为8 G。
实验爬取了“南昌路况信息”“广州实时路况”“深圳路况播报”为主题的共10 162条微博文本,利用正则表达式清理表达情感的表情符号(如“[怒]、[开心]”等);去除夹杂英文字母表示的词语简写、微博账户名、过短微博等;结合分隔符号(句号或分号)将同时描述多个交通事件的微博文本拆分为多个单一事件的短文本;基于城市POI数据扩展地名词典,以提高交通位置信息中空间特征词的分词及词性标注的准确度,最终共提取有效微博文本9 799条。最后,利用自然语言处理工具HanLP(https://github.com/hankcs/HanLP/tree/1.x)对微博文本进行分词及词性标注,并人工标注出微博文本中包含的位置信息,作为实验结果的验证数据。
2.2 位置信息提取实例
以微博文本“在北环大道龙珠立交西往东方向发生拥堵”的位置信息提取为例,阐述其位置模式匹配及角色提取的全过程(图4)。1)首先对微博文本进行预处理,获得文本对象序列V={“在”“北环大道”“龙珠立交”“西”“往”“东”“方向”“发生”“拥堵”};2)遍历所有文本对象,以表6中的状态转移规则为基础,实现文本对象驱动的状态(角色)跳转,在每次跳转后记录状态(SA)及其与词语间关联(S-V),并基于SA构建候选匹配模式集合(PA);3)遍历结束后,结合PA与S-V得到各文本对象的角色属性;4)从微博文本“在北环大道龙珠立交西往东方向发生拥堵”中提取出北环大道(所在道路)、龙珠立交(定位起点)、西(起始方向)、东(终止方向)等位置信息。

图4 文本实例中位置信息提取过程Fig.4 Example of location information extraction from traffic microblog text
2.3 模型精度评价
(1)位置提取精度评价。本文从9 799条微博文本中提取出16 966个位置。通过比对人工标注检查结果,发现正确识别位置15 177个,错误识别位置1 789个,未能识别位置2 294个,处理时长约7.53 s。部分微博文本及提取的位置信息如表7所示,可以看出,提取结果较准确地描述了交通事件的发生位置,包括参照物、起点、终点、起始方向、终止方向与距离等信息,而且总体提取耗时较短,效率较高。通过分析提取结果发现,大部分错误及未能识别位置的微博文本主要采用单一的“所在道路”或“POI”位置表达模式,此类模式可利用信息较少,极易因未登录地名、道路名或POI名简(缩)写等而产生错误提取或无法识别,如微博文本“南海大道深大门口路段北往南方向”中“深大门口”的缩写地名无法被正确提取而产生识别错误。此外,少部分微博文本由于参照物或附属定位词切分或识别失败,造成这些道路或POI无法被准确识别,进而导致其位置表达模式无法与模式库中的相匹配,致使信息提取失败或提取不完整等。例如“公常路圳美江吓路段往东莞方向”中的“圳美江吓路段”,因语句错误切分而导致识别错误。

表7 交通微博示例数据及位置信息提取结果Table 7 Examples of traffic microblog text and its location information extraction results
本文利用准确率、召回率与F1值对模型的提取精度进行定量评价(图5),可以看出,南昌与广州的路况微博文本中位置提取效果较好,准确率均在90%左右,深圳的提取效果略差(约为83%),总体结果准确率和召回率都达85%以上。通过对比发现,南昌与广州的微博文本中位置表达相对直接,描述交通事件的干扰信息较少,因此位置信息提取效果较好;而深圳路况微博文本中存在简写地名或地名库中不存在的小地名等情况,导致部分地名匹配失败,影响模式匹配结果,提取效果较差。

图5 位置元素提取结果评价Fig.5 Evaluation of location element extraction results
(2)位置表达模式统计分析。为分析交通事件文本位置表达模式的分布情况,本文统计所有正确提取位置信息的表达模式,累计数量排名前10的位置表达模式如表8所示。1)按表达模式统计发现,交通事件的文本位置表达多采用“参照位置(道路或POI)+空间关系”的模式(占比约50%),包括只有起始方向、起始与终止方向等情况,此类模式能更准确地描述位置;其次结合POI的位置表达模式约占38%,包括POI、POI+方向组合等,此类模式利用人们对POI位置的初步印象可实现快速的粗略定位。2)按不同城市统计发现,由于各城市发布的微博数量、重点交通事件类型等方面的差异较大,各城市主要采用的位置表达模式也有较大不同。南昌发布的交通微博多采用“所在道路”模式(约占54%),广州多采用“所在道路+POI+方向”模式(约占54%),深圳则多采用“所在道路+路段+方向”模式(约占41%)。

表8 累计数量排名前10位的位置表达模式Table 8 Location expression patterns of top 10 in cumulative quantity
3 结语
快速提取有效的位置信息是实现文本位置空间化的基础。本文以交通微博文本为对象,提出一种基于有限状态机的位置信息识别与提取模型。该模型基于线性参照方法构建位置表达模式库,并将模式库表达为Trie搜索树,利用有限状态机匹配微博文本中位置表达模式,识别并提取微博文本中的位置信息,最后以南昌、广州与深圳的微博文本为实验数据进行模型验证。结果表明,该模型能有效识别并提取微博文本中的位置信息,综合准确率达89.46%,召回率达86.87%;通过分析错误提取结果,发现未登录地名与模式不确定性是造成识别错误的主要原因。未来将主动吸收和识别外部开放地名词典或句法知识等,尝试结合语义分析方法,加强对位置表达中各要素及其空间关系等语义的理解,提高分词和词性标注的效果,进而提高位置信息提取的准确性。
