基于分布式管道模式的管道服务框架设计与实现
2021-10-16戴振邦江恩杰刘力嘉甘江伟戴振邦江恩杰刘力嘉甘江伟
戴振邦 江恩杰 刘力嘉 甘江伟 戴振邦 江恩杰 刘力嘉 甘江伟

摘要:集中化,合并任务的处理是分布式设计中的一个难点。由于不同任务中需要频繁的数据交换,且需对不同任务的结果进行合并,使其难以使用目前主流的分布式设计模型。分布式管道设计模式是一种高度解耦合的分布式设计模型,适合处理业务粒度较大,数据交换频发,IO瓶颈较高的任务。文章在分布式管道设计模式的基础上,参考服务发现机制实现了一个高性能的管道服务框架。
关键词:分布式;服务发现;动态负载均衡;管道任务;高解耦
中图分类号:TP311 文献标识码:A 文章编号:2096-4706(2021)07-0044-07
Design and Implementation of Pipeline Service Framework Based on
Distributed Pipeline Mode
DAI Zhenbang1,JIANG Enjie2,LIU Lijia2,GAN Jiangwei3
(1.School of Chemical Engineering,Northwest Minzu University,Lanzhou 730124,China;
2.Information Engineering Department,Chengyi University College,Jimei University,Xiamen 361021,China;
3.College of Physics and Electronic Information Engineering,Minjiang University,Fuzhou 350108,China)
Abstract:Centralization and combined task processing is a difficulty in distributed design. Due to there are frequent data exchanges in different tasks and the results of different tasks need to be merged,it is difficult to use the current mainstream distributed design model. Distributed pipeline design pattern is a high decoupling distributed design model,which is suitable for the tasks with large business granularity,frequent data exchange and high IO bottleneck. Based on the distributed pipeline design pattern,this paper implements a high performance pipeline service framework with the reference of service discovery mechanism.
Keywords:distributed;service discovery;dynamic load balancing;pipeline task;high decoupling
收稿日期:2021-03-09
基金項目:大学生创新创业训练计划项目 (省级)(202013471013)
0 引 言
目前比较流行的分布式解耦合的解决方案中,如微服务,这是一种将应用程序构造为一组松散耦合服务的软件开发技术,是面向服务的体系结构(Service-Oriented Architecture,SOA)架构样式的一种变体[1]。在微服务体系结构中,其服务是细粒度的,并且协议是轻量级的[2],是一种高度解耦合的分布式设计思想,但微服务更适合用在解决模块化可分离的任务中,可以在不同服务中通过相互调用的方式来完成不同服务中的协同。对于目前互联网大多数分层业务来说,微服务是一个很好的解决办法,但对于集中化的,需要合并处理任务来说,微服务无法有效地对任务进行分层。本文参考分布式管道设计模式的解决方案,设计一个用于分层合并任务的分布式解耦合任务处理框架。
本文设计了一个分布式解耦合任务处理框架(下文简称管道服务框架),主要解决分布式任务中的服务发现、动态负载均衡和管道粒度的拆分,最后通过实际业务中的应用效果验证了该框架的可行性和有效性。
1 分布式管道设计模式
分布式管道设计模式是一种去中心化的分布式设计模式,其特点是无须任务分配,每个独立的管道(总任务的子集)都可以主动或被动地推送或接收数据,并且按照一定的规则对数据进行处理,然后执行流出或者暂时储存的操作,管道还可以截留数据,在特定条件下对数据进行合并流出。在管道设计模式中,管道可以根据数据的标记,使用一种类似服务发现的方式主动地推送数据到处理管道中,即对于任何一个产生的数据,无须使用消息队列等工具对任务进行推送,只需要交付到任何一个管道的入口由管道进行推送即可。
分布式管道设计模式中道管道类型有进程管道、协程管道、线程管道,不同的管道维护不同的上下文,同时有不同的处理方案,相对来说,进程管道做到了并行处理,适用于计算密集型任务;协程管道适用于高IO任务,可以几乎不需要额外的消耗,进行操作系统回调。
2 管道服务框架架构
如图1所示,管道服务架构中,服务表示转流层负责记录每个处理管道的地址,以及管道数据交换以及日志的缓存。数据交换层主要负责相互隔离的2个管道的数据交换。管道工作层主要负责用户逻辑的处理部分,数据的合并处理,数据的流出处理。日志层主要用于管道崩溃后,根据日志进行数据的恢复,以及管道massage的记录。回调层,主要用于任务处理完毕或者管道合并后的结果输出。
2.1 服务表示转流层
服务表示转流层主要分为服务注册中心、管道全局中心。服务注册中心[3]在管道服务框架中使用,全局管道空间实现一个简单的Key-value数据库,当然可以使用ETCD[4]或者Redis[5]来作为服务注册中心的载体。
服务注册中心的作用主要是为了维护每个管道或者管道组的正常运行,维护每个管道或者管道组的信息,实际上在使用中会把多个管道合并为一个集合,包括管道集合所在的IP端口,以及它拥有的管道ID。并且每个管道集合必须定时的重新上报自己的情况,否则过期后,服务注册中心会删除这个管道集合的信息。
管道全局中心的主要作用是用于在不同分区中的管道交换数据时,会先在管道全局中心中缓存数据,发送管道先缓存数据,然后告知目标管道,目标管道激活后直接通过管道交换通道获取到对应的数据,流入管道。值得注意的是,为了保证在发生网络分区时,框架的数据恢复能力,管道对全局空间并不会直接操作,而是需要通过管道交换通道进行。
2.2 数据交换层
数据交换层主要由多个管道交换通道组成,一般来说管道交换通道的数目与管道集合的数目相等,即一个集合一个管道交换通道,管道交换通道主要用于解决数据一致性问题;数据通道解决事务一致性问题,保证管道推送的数据一定被日志记录以及被上传到管道全局中心中。然后去通知接收管道,同时管道交换通道还负责负载均衡的实现,如果管道在流出数据时没有指定目标管道的唯一标识ID,而是指定了管道服务ID,那么数据交换层会尽可能均衡的推送数据到管道集合中管道服务ID相同的分组。同时管道交换通道还支持动态均衡[4]策略,管道交换通道会跟踪每一个管道分配的拉取时间,对于分配拉取管道拉取时间慢的管道集合地址更新更小的权重,根据权重来进行负载均衡。
交换层代码为:
func (cr*ConsulResolver) resolveService(ctxcontext.Context) (string, connect.CertURI, error) {
health :=cr.Client.Health()
svcs, _, err :=health.Connect(cr.Name, "", true, cr.query Options(ctx))
iferr!=nil {
return"", nil, err
}
iflen(svcs) <1 {
return"", nil, fmt.Errorf("no healthy instances found")
}
// Services are not shuffled by HTTP API, pick one at (pseudo) random.
idx :=0
iflen(svcs) >1 {
idx=rand.Intn(len(svcs))
}
returncr.resolveServiceEntry(svcs[idx])
}
func (cr*ConsulResolver) resolveQuery(ctxcontext.Context) (string, connect.CertURI, error) {
resp, _, err :=cr.Client.PreparedQuery().Execute(cr.Name, cr.queryOptions(ctx))
iferr!=nil {
return"", nil, err
}
svcs :=resp.Nodes
iflen(svcs) <1 {
return"", nil, fmt.Errorf("no healthy instances found")
}
// Services are not shuffled by HTTP API, pick one at (pseudo) random.
idx :=0
iflen(svcs) >1 {
idx=rand.Intn(len(svcs))
}
returncr.resolveServiceEntry(&svcs[idx])
}
2.3 管道工作層
管道工作层作为管道服务框架中实际的工作角色,用户将给每个不同的管道定义不同的工作任务,同时定义管道的服务ID或者叫作任务ID,定义管道的流动条件,定义管道的推送条件,定义管道的合并条件。如在计算阶乘和的任务中,我们可以分解出计算阶乘和求和的子任务,这2个任务会被定义到2个不同的管道中并且有自己的任务ID,在这个任务中我们可以开启多个计算阶乘的管道,一个组合的管道,并且指示计算阶乘的管道的流出是组合管道,在组合管道中会对阶乘管道的求出结果做合并,最后输出到流出器中等待回调得到最终的结果。管道的基本工作流出如图2所示。
管道工作层代码为:
typePolicystruct {
ID string `hcl:"id"`
Revision uint64 `hcl:"revision"`
ACL string `hcl:"acl,expand"`
Agents []*AgentPolicy `hcl:"agent,expand"`
AgentPrefixes []*AgentPolicy `hcl:"agent_prefix,expand"`
Keys []*KeyPolicy `hcl:"key,expand"`
KeyPrefixes []*KeyPolicy `hcl:"key_prefix,expand"`
Nodes []*NodePolicy `hcl:"node,expand"`
NodePrefixes []*NodePolicy `hcl:"node_prefix,expand"`
Services []*ServicePolicy `hcl:"service,expand"`
ServicePrefixes []*ServicePolicy `hcl:"service_prefix,expand"`
Sessions []*SessionPolicy `hcl:"session,expand"`
SessionPrefixes []*SessionPolicy `hcl:"session_prefix,expand"`
Events []*EventPolicy `hcl:"event,expand"`
EventPrefixes []*EventPolicy `hcl:"event_prefix,expand"`
PreparedQueries []*PreparedQueryPolicy`hcl:"query,expand"`
PreparedQueryPrefixes[]*PreparedQueryPolicy`hcl:"query_prefix,expand"`
Keyring string `hcl:"keyring"`
Operator string `hcl:"operator"`
}
2.4 管道工作層调度模型
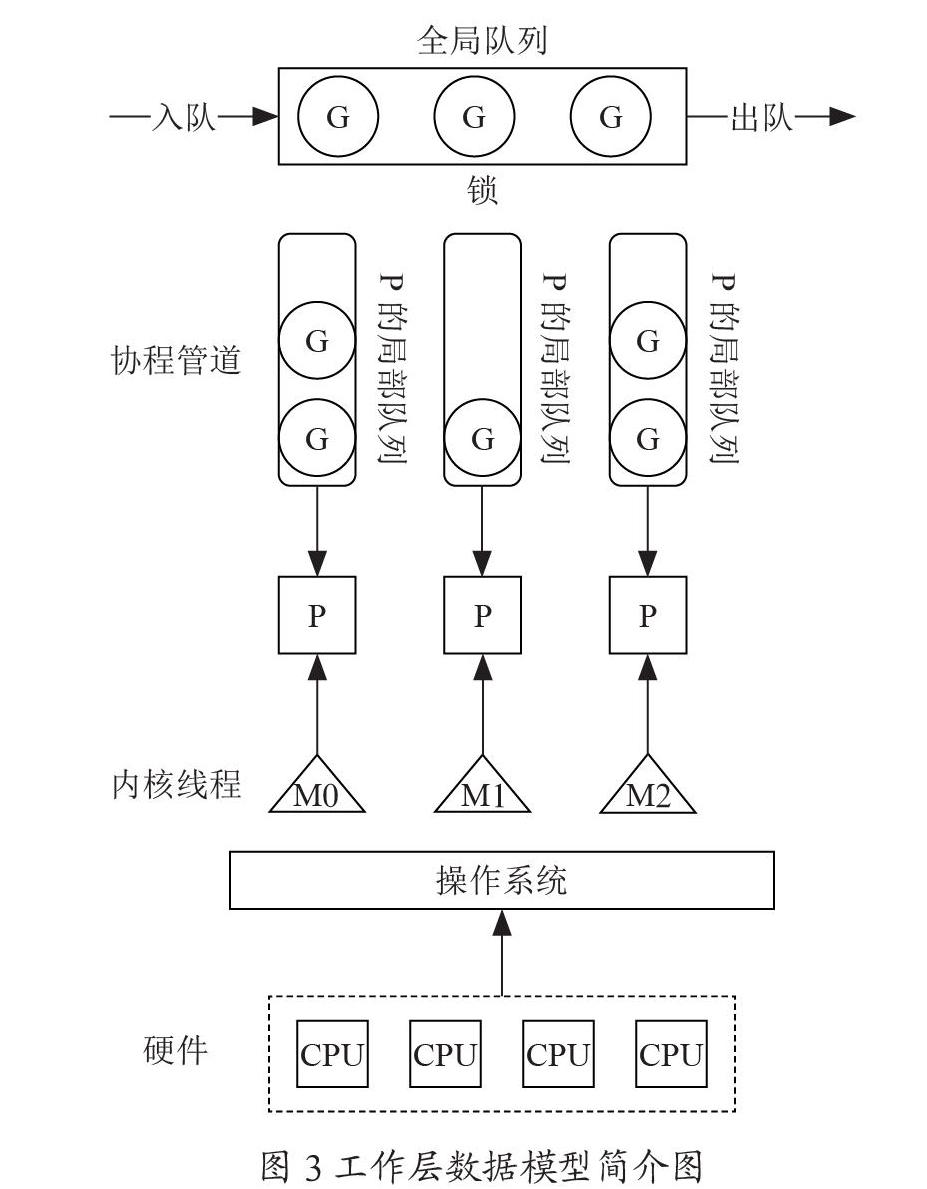
在管道服务框架的实现中,管道的工作使用GMP模型,模型分为M、P、G三个角色,分别代表POSIX Threads,Processor和Go Pipeline。P可以理解为执行上下文,也就是context,P负责完成对G和M的调度,我们可以把M理解为操作系统资源的抽象,是真正的执行体;把G理解为要执行任务的抽象,是执行代码和数据的集合。P用执行体M来执行G,并且维护了一个队列来存放可执行的G,当前G执行结束,M就空闲了下来,P就可以从队列的顶部取出下一个G在M上继续执行。
当M去执行该系统调用时线程会阻塞并被操作系统挂起,这个时候P会把当前的G留在原来的M中处理,然后从队列里取出下一个G并创建一个新的M对象来执行它。被的G-M对完成系统调用变成可执行状态时,又会在合适的时机被重新调度执行。如图3所示。
图中,长矩形为全局可用资源,包括全局队列、操作系统;圆角长矩形为局部可用资源,图中为局部队列;圆形为虚拟工作角色,即工作管道;正方形为具有调度功能的角色,图中为P(虚拟调度器)以及CPU(调度器);三角形为实际工作内核线程;虚线标记部分标识其为虚拟整体,图中相对于整个系统CPU为一个整体工作,实际上CPU独立互不干涉。
使用以上模型,可以使管道用更小的开销异步处理计算密集型以及IO密集型的任务,相对来说,更适合处理IO任务,并且解决了分布式管道设计模式中用户的管道选择问题,降低了管道设计模式的任务分层时的选择复杂度,使得用户只需要关注如何拆分任务。
2.5 回调层
回调层主要为结果的输出,用户最终使用回调层提供的接口,如图1中的流出器获取到管道处理完毕的数据。值得注意的是,为了解决管道资源的占用问题,管道使用回调层流出数据后会立刻释放当前的资源,认为该任务集合的本次任务已经完成。
2.6 日志层
日志层主要分为异常日志和恢复日志:
(1)异常日志。异常日志主要用于记录POSIX Threads这里可以理解为操作系统回调的错误日志,以及框架用户在GOPipeline中手动定义,并且被抛出触发的错误,异常任务可以对框架的执行情况进行简要的分析,使得框架具有更好的错误检测,中断分析能力[6]。
(2)恢复日志。在管道设计模式中全局管道空间储存每一次管道执行任务后得到的中间态数据,并且管道全局中心中的数据保存在内存中,一旦发生宕机或者进程意外终止等问题,管道全局中心中的数据会全部损失,对应的管道任务需要重新执行。为解决上述问题管道设计模式参考Redis的持久化策略[5]引入恢复日志来解决框架的容灾问题。恢复日志的工作主要分为以下3个过程。
1)管道全局中心会在计算压力较小的时候,对管道全局中心的数据进行磁盘持久化,被称为备份,并且在恢复日志中打下一个版本标记。
2)管道交换通道每产生一次中间态数据,优先记录操作到恢复日志中,保证管道全局中心以及恢复日志的原子性,一致性[7]。
3)一旦发生导致进程崩溃的问题,在管道服务框架重新启动时优先从最新的备份中恢复数据到管道全局中心中,根据备份的版本号,到恢复日志中逐步对该版本号以后的操作进行恢复。
以下为日志层代码:
funcSetup(config*Config, uicli.Ui) (*logutils.LevelFilter, *GatedWriter, *LogWriter, io.Writer, bool) {
// The gated writer buffers logs at startup and holds until it's flushed.
logGate :=&GatedWriter{
Writer: &cli.UiWriter{Ui: ui},
}
// Set up syslog if it's enabled.
varsyslogio.Writer
ifconfig.EnableSyslog {
retries :=12
delay :=5*time.Second
fori :=0; i<=retries; i++ {
...
// Create a log writer, and wrap a logOutput around it
logWriter :=NewLogWriter(512)
writers := []io.Writer{logFilter, logWriter}
varlogOutputio.Writer
ifsyslog!=nil {
writers=append(writers, syslog)
}
}
3 管道服務框架设计与验证
3.1 任务说明
我们对巨潮网上市公司2020年期间的报告数据进行爬取,同时使用朴素贝叶斯算法进行主题抽取,获取年报中财务分析部分的报表内容,并且对每个提取到数据进行储存分析。
3.2 任务瓶颈分析
通过对巨潮网爬虫的年报进行估计,全国上市公司共3 869家其中深圳股市有2 241家,上海股市有1 628家,平均每个年度的报告数据为900条目,平均年报大小为1 350 kB,粗略估计总IO任务读写大小为4.05 TB,可以确定该任务为高IO复杂度任务。在本次实验任务中,假设朴素贝叶斯模型的训练过程已经完成,来分析朴素贝叶斯模型的计算压力。利用式(1)对离散数据进行简单化计算:
P(X|Ci)=P(xk|Cj) (1)
式(1)中,P(X|Ci)为Ci文本属于X的概率,P(xk|Cj)为Cj中包含词条xk的概率。
朴素贝叶斯分类器[8],分类的设计复杂度大概为O(C× D),其中C为类别,D为特征数。在本次二分类问题中时间复杂度为O(2D)属于线性时间复杂度,由于在本次实验任务中,需要对每个上市公司的报告进行分段输入朴素贝叶斯分类器中进行分类,根据对巨潮网的财报分析平均需要对3 000 byte(每个段落的大小)进行分割计算,所以本次任务也属于高计算密集型任务。
综上所述,本次设计目标为高IO高计算密集型任务,任务主要瓶颈为IO瓶颈,其次为计算瓶颈,最后为任务调度开销。
3.3 任务分层情况与管道设计
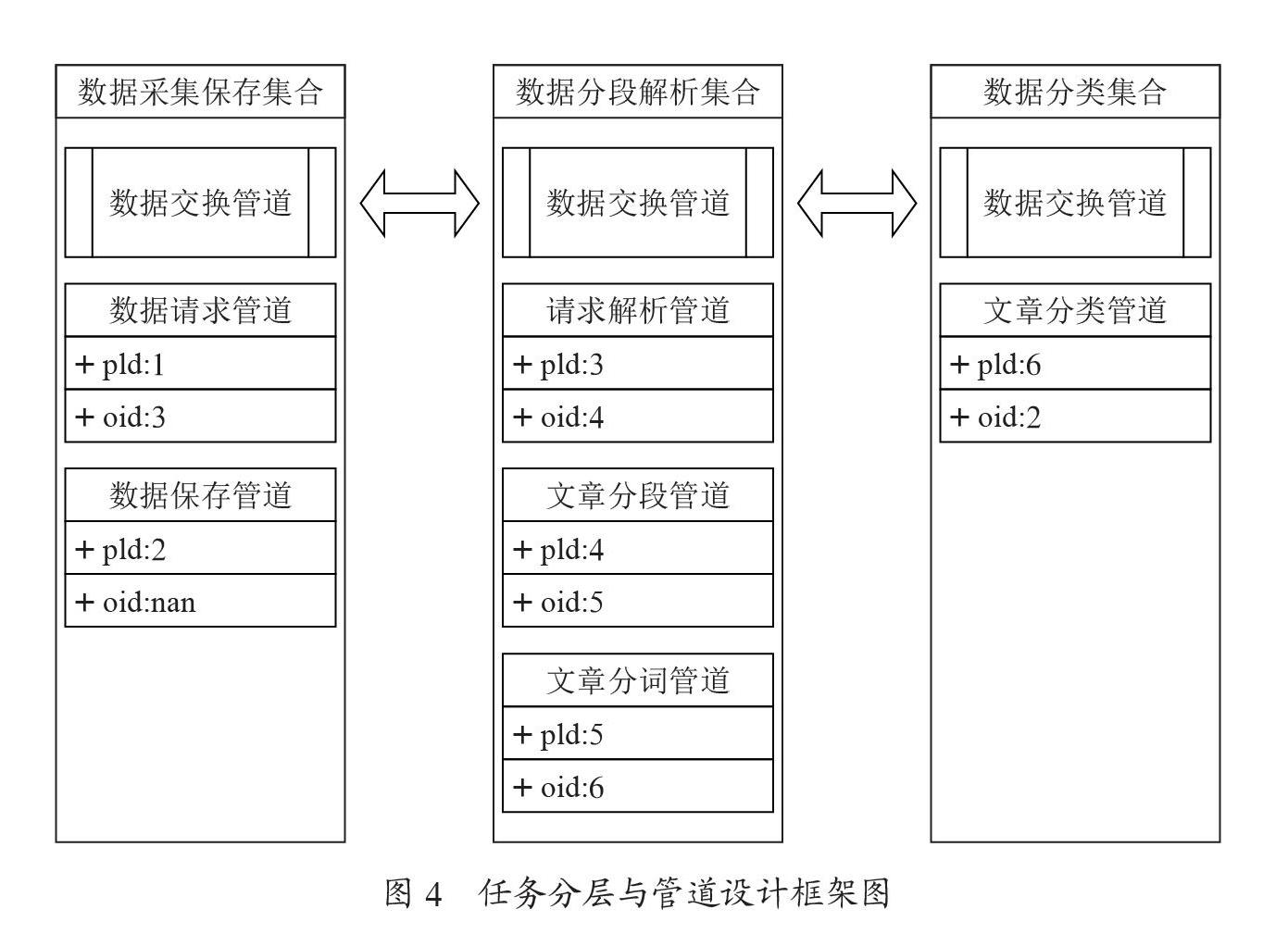
对于以上任务,在管道服务框架中,按照复杂度分离,可以概括为以下几个任务:数据请求返回、原始数据保存、数据分割、朴素贝叶斯分类、报表数据统计。其中IO任务主要集中在数据请求,保存部分即数据采集部分。计算密集型任务主要存在于数据分割、朴素贝叶斯分类部分。报表数据产生的IO相对于数据采集部分IO的开销极小,在本文中不做统计。经过以上分析可以建立以下管道任务模型,如图4所示。
在图4中,我们共定义了3个管道集合,管道集合的定义,可以把一类有较高瓶颈任务的组合在一起,如数据请求管道,数据采集保存集合代表了高IO任务,数据分段解析集合,数据分类集合都是一个高CPU密集型集合任务。在分布式管道设计模式理论中,将每个管道分离出来会有更好的处理能力,更小的粒度,但是在我们进行分机部署工作时,就需要指定大量的管道部署,这是一个非常复杂的过程,同时也会出现数据交换管道过多出现管道全局中心抢占问题。在本次设计的服务框架中,使用管道集合的方式集中的管理一些管道,这样的做法会导致管道的高解耦合性有一定影响,但是在一定程度上我们可以在用户对管道集合的设计部分分离出可能出现高耦合的任务。如图4中分离出了文章分类管道,使得数据的处理和我们的分类任务分离使用不同的数据交换管道,来获取更高的性能和错误恢复能力。
3.4 对比实验
本次实验只采用完整任务的1/1 000的工作量,并且使用上述的管道服务框架,以及GoCollaborate框架,一个提供分布式服务管理搭建的轻量级通用框架,可以轻松地用它进行编程,构建扩展,以及创建自己的高性能分布式服务。使用上述的2个框架同时实现对平安银行、东航物流、中科软3个企业在2020的年报分析,并且对2个不同框架做,丢包率、内存使用情况、CPU负载情况、单位请求QPS做了比较研究。
3.5 实验结果
在实验过程中使用pprof[9],一种Go自带的工具,可以做CPU和内存的profiling。对2个不同框架对任务实现的内存以及CPU负载情况进行查看,结果如图5所示。
图5中可以观察到管道服务框架的内存和CPU的占用率都要大于GoCollaborate框架,换言之,管道服务框架的开销较大,这很有可能是管道服务框架的管道全局中心中,产生大量的数据交换,以及恢复日志的处理导致的。同时在6、7、8时间点,管道服务框架的CPU占用明显下降经过分析,在6、7、8时间点,全局管道交换中出现高IO占用,管道服务框架,优先处理数据保存流出管道的拉取推送任务,而GoCollaborate框架是平衡的,在高IO任务到来时,它必须分配更多的CPU资源去管理IO任务。
在本次实验中,为检查每秒请求数(querypersecond,QPS)情况,使用自搭建Web服务器,只实现读取接口,并对在单位时间内,本次实验采用1分钟作为运行时间,使用Gin框架[10](一个go语言实现的高性能web框架)对日志分析获取单位时间内的QPS量。
QPS=req((请求数)/sec(秒)),在本次实验中单位时间一定,QPS=req/60。得到QPS数据如表1所示。
在单纯QPS的检测中,框架性能相差不大,对于单纯的高IO任务,管道服务框架和GoCollaborate框架在宏观上来看都是平衡的,那么QPS的瓶颈在gin服务器中。
在本次实验中丢包率以及总工作时间,使用系统运行日志进行分析,即在框架层面,每次发生数据传输丢失重新传输时,或者发生日志恢复时,认为发生丢包。在本次使用中的丢包率指的是在应用层发生重发的概率,忽略传输层的情况。使用W=重发数据包/发送数据包,来计算丢包率,结果如表2所示。
管道服务框架的丢包率要远大于GoCollaborate框架,经过分析,这是由于管道服务框架在交互数据需要经过,管道、管道交换通道、管道全局中心、管道交换通道、管道,5个过程,GoCollaborate框架只需要从一个服务到另外一个服务,2个过程,并且GoCollaborate框架保证数据安全在传输层中解决,管道服务框架的数据安全保障在应用层中处理。在表现上管道服务框架的数据传输安全性较差,但在应用层中进行安全保证,使得在发生灾祸时,管道服务框架有更好的容灾能力。
4 结 论
特定的计算环境产生的不同特征的问题,本文的实验过程在不同特点,不同计算性能要求情况下的处理能力往往不同。在真实应用环境下的性能可能达不到预期要求,随着更多实际计算任务场景的出现,分布式管道如何更高效地解决计算机资源的处理、调度仍需更深层次的研究。通过结合本文研究的不足之处,须在以下方面进行相应改进:
(1)在连续性任务中,若中间某一类数据管道全部断开连接,则数据将被迫留在管道全局中心中,可能导致全局管道空间数据溢出。对于此问题可以在全局管道空间中对每个集合管道的推送添加缓存最大值,同时在管道交换通道中添加缓存和通知机制,尝试重新唤醒断开连接的管道,最终解决管道全局中心数据溢出问题。
(2)在数据推送过程中,数据在原管道—原管道交换通道—全局管道空间—目标管道交换通道—目标管道转移。在此过程中,由于网络交换的次数较多数据更易丢失。对于此问题,可以在数据交换频繁,单次计算量较小的部分定义一个快速管道(实现管道于管道之间直接通信,牺牲容灾性),提高数据处理效率,降低框架丢包率。
(3)全局管道空间备份的时机。全局管道空间使用定时器对数据进行定期备份,且对数据加锁防止其在保存过程中被篡改。在系统在处理高负载任务时若全局管道空间进行备份加锁,使得管道交换通道无法进行数据傳输,则会影响其高计算密集任务的工作,导致任务长期阻塞等待。在此提出一种侦察机制,使得系统在执行高IO任务时,有更高的备份优先级,一定程度避免在进行高CPU任务时进行全局管道备份,将其和定时器相结合,有效提高系统计算能力。
参考文献:
[1] HU H R,FANG L L,YANG C H,et al. Research on Cloud Architecture of Enterprise Distributed Business Information System Based on SOA [J].Journal of Physics:Conference Series,2020,1684(1):1-8.
[2] 徐旻洋,高承勇,周向东,等.基于微服务架构的大型建筑设计企业生产业务平台构建 [J].土木建筑工程信息技术,2019,11(3):89-95.
[3] 袁晓晨,张卫山,高绍姝,等.基于微服务架构的众包图像数据集标注系统 [J].计算机系统应用,2021,30(5):83-91.
[4] 邓兆森.一种云平台服务状态显示方法及相关装置:CN1 12737882A [P].2021-04-30.
[5] DONG Y,ZHU P F,JIANG Z Y,et al. Real Time Data Distribution Technology of SCADA based on Redis [C]//Proceedings of 2016 International Conference on Computer,Mechatronics and Electronic Engineering (CMEE 2016).Beijing:DEStech Publications,2016:190-194.
[6] 贾统,李影,吴中海.基于日志数据的分布式软件系统故障诊断综述 [J].软件学报,2020,31(7):1997-2018.
[7] 孙志龙,沙行勉,诸葛晴凤,等.面向内存文件系统的数据一致性更新机制研究 [J].计算机科学,2017,44(2):222-227.
[8] 张晨跃,刘黎志,邓开巍,等.基于MapReduce的朴素贝叶斯算法文本分类方法 [J].武汉工程大学学报,2021,43(1):102-105.
[9] 向勇,汤卫东,杜香燕,等.基于内核跟踪的动态函数调用图生成方法 [J].计算机应用研究,2015,32(4):1095-1099.
[10] 张晶,黄小锋.一种基于微服务的应用框架 [J].计算机系统应用,2016,25(9):265-270.
作者简介:戴振邦(2000—),男,汉族,福建莆田人,本科在读,研究方向:分布式、数据挖掘、集群计算;江恩杰(2000—),男,汉族,福建漳州人,本科在读,研究方向:人工智能、模式识别、云服务;刘力嘉:(2000—),男,汉族,福建漳州人,本科在讀,研究方向:虚拟化;甘江伟(2000—),男,汉族,福建永安人,本科在读,研究方向:微电子。
