基于流水模式的古籍文献汉字切分算法
2021-10-15倪劼
倪 劼
0 引言
在我国,古籍是指1912年之前书写或印刷的,具有中国古典装帧形式的书籍。以语言文字分类,汉文古籍占比最大。通过现存古籍数字化,尤其是汉文古籍全文数据库建设,不仅可以让更多读者挖掘其中蕴藏的财富,也可以最大程度保护中华文脉和传统文化。古籍文献汉字切分作为古籍文献全文数据库建设前期重要的基础性工作之一,主要是将图像化后的文献进行计算机处理,使其中的文字逐个呈现出来,切分的准确度将对后期的文字识别有直接影响。因此,加强这方面的技术研究可以提高切分的准确性与适用性,在促进古籍数字化工作方面具有重要的意义。
目前用于文字切分的算法有基于图论的切分算法[1]、基于神经网络的切分算法[2]、基于信息测度的切分算法[3]、基于偏微分方程的切分算法[4],大多数算法并未在古籍文献方面应用。古籍文献因其特殊性,受保存条件影响,页面内容会有缺失、模糊等情况,且刻本与抄本中往往内容非常“拥挤”,文字间常有交错与粘连现象,这些因素都成为文字切分的难点。在较早一段时期,基于投影法的切分方式使用较为普遍[5-6],通过对二值化后的图像进行逐行或逐列累加形成投影图,利用投影中的间隙找出相邻文字的分界点实现切分。但在具体应用中,对图像质量以及文字分布有着较为苛刻的要求。于是,基于连通域算法的方式在古籍文献切分中得到了较多的运用[7-10],连通域算法常用于图像目标的分割与提取,具有相同像素值的邻接点组成的区域为连通区域,对连通区域进行分析从而实现图像目标的分割提取。另外,基于滴水算法的切分方式也被常用于古籍文献中,其原理是水滴沿着图像字符轮廓下落或水平滚动,在轮廓凹陷处,它将穿透轮廓继续下落,最终水滴运动轨迹就形成了字符切分路径,该算法常被用于字符粘连部分的轮廓切分[11-13]。近年来,基于分层投影过滤的递归切分算法[14]、基于犹豫模糊集的切分方法[15],基于最小加权分割路径的切分方法[16],基于可变窗口的切分方法[17],基于分段投影方式的切分[18],以及基于改进后的SOM聚类算法[19]等等,这些方法在古籍文献切分中也有应用。在现有研究中,投影法、连通域算法、滴水算法的三种切分方式存在着一定的局限性,若图像噪声较大,文字间存在交错、粘连等情况时,采用投影法将无法准确进行文字切分。连通域算法在进行切分时,可以很好地解决文字交错的问题,但是面对文字粘连情况却无能为力。滴水算法则受到起始位置、水滴下落规则以及方向等因素制约,在不加限制的情况下容易出现切分错误,受制于古籍文献的复杂度,精确给定起始位置的难度较大。其他的研究成果中,大多是在传统算法基础上进行了改进,虽取得了一定效果,但从实验过程来看,选择样本种类较为单一,样本数量较少,且样本中并未有明显的文字交错与粘连,其算法的适用性未能有所体现。
面对上述问题,本文提出新的古籍文献汉字方式,能在多种类型的古籍文献中实现汉字切分,解决古籍文献切分算法中的局限和适用性不强的问题,具体流程见图1。首先,对古籍文献图像进行预处理,包括图像矫正、高斯滤波、二值化操作、形态处理等操作;其次,利用投影法与图像形态处理实现列切分;最后,结合古籍文献汉字特征,借鉴流水在下落时的状态,以呈现的运动轨迹作为切分依据,实现古籍文献汉字切分,并将这种新的切分方式命名为流水算法。

图1 古籍文献汉字切分流程
1 材料与方法
1.1 研究对象
本文选择不同时期、不同类型的古籍文献作为研究样本。以苏州图书馆藏宋刻本《容斋随笔》、南京图书馆藏清抄本《金陵防守利便》、清刻本《莲洋诗抄》、清抄本《钜鹿东观集》、明刻本《初唐诗》、明刻本《博异记》为例,样本数据见表1。样本各有特点,时间跨度较大,其中有刻本、抄本,内容有印章、批点、列分割线,文字有稀疏之异、版面有框格之分,且字与字之间有一定的交错与粘粘,确保样本选择有一定代表性,部分样本见图2。本文系统开发工具为Python3.7,图像处理使用OpenCV3.3。

图2 样本图示

表1 本文研究样本数据详细列表
1.2 图像预处理
切分前,对图像进行预处理。古籍图像的版面会有大量信息而产生复杂的噪声,如原图中的印章、批点、划线,以及笔画不均、字体断裂、版面污渍、图像倾斜等情况。图像预处理目的就是将图像中的不利信息进行最大程度消除,增强图像质量,改善文字清晰度,为后期的处理提供最佳环境。本文预处理包括图像矫正、高斯滤波、直方图处理、二值化操作、图像形态处理这几个步骤。图像矫正是通过计算机算法,去除原始图像中的倾斜角度,使得图像保持最佳角度,方便后期的切分。本文采用使用Hough变换算法,寻找最长间隔线计算矫正倾斜角,完成对原始图像的倾斜矫正。图像预处理见图3,采用高斯滤波方式去除原图中的噪声,以及灰度化、直方图、直方图均衡化、二值化处理,最终进行图像形态操作,预处理结果见图3(f)。

图3 图像预处理
1.3 列切分
古籍文献多以竖式排列,列与列之间具有一定间隔,且有些文献中存在分割线。列切分一般由投影法完成,因为列与列之间存在明显的间隔,这非常适用投影法来处理,列切分处理过程如图4所示。首先将图4(a)二值化图中每一列的白色像素值相加,形成图4(b)的投影图,通过投影图已经能够大致辨别出每一列所在的位置,但由于古籍图像的列与列之间会存在分割线以及边页等情况,这些内容也会被投影出来,将影响到列切分的准确性。本文采用对投影图像再一次进行形态运算,运用其中闭运算和开运算将投影图像进行处理,对二值化图像中的分割线、非正文内容进行消除,最终图4(c)呈现的就是正文列投影,以此为依据可以得到正文列位置。

图4 列切分处理过程
1.4 字切分
1.4.1 基本思路
古籍多为繁体字,结构丰富。古籍中的汉字也是书法表现形式,以楷书居多,笔画形式以“永字八法”为基础,具有点画齐备、结字方整、章法和谐的特征。这些特征使古籍文献汉字呈现出有利于切分的显性要素:一是古籍文献汉字呈现矩形形态,可以以此分析出文字的大致位置;二是书法的形式使得字体能够呈现更加完美的结构,利用其中的起笔、运笔、收笔时的变化,可对文字进行细切分。
流水在高处下落时,会受重力作用一直垂直向下运动。在这个过程中若遇到障碍物,流水会沿障碍物边缘继续向下,当进入一片洼地时,会逐步将洼地注满,再进一步沿障碍边缘行进,直至到达底部。在进行古籍文献汉字切分时,可以借鉴流水模式,将待切分图像中的文字,看做是流水行进中的障碍物,以流水在障碍中的运动轨迹作为最终切分的依据。根据古籍文献汉字呈现的矩形形态以及书法特征,通过投影法加上阈值的方式,可以大致确定出交错与粘连部分的具体区域,这个区域将作为流水的运动有效区域,使用算法计算得到最终切分位置。在待切分区域,将尝试各个位置点作为流水起点,选择将流水最终能够到达底部的轨迹进行比较,路径最短的那条轨迹将作为最终切分依据,实现交错文字的切分;如流水不能到达底部,则将图像上下翻转,再进行一次反方向尝试,若两次均不能到达时底部,则认为该区域文字存在粘连现象。这时,将根据古籍文献汉字中的书法特征,利用其起笔、运笔、收笔时的变化,以两次流水轨迹中最接近的位置作为切分依据,实现粘连文字的切分,本文将此切分方式命名为流水算法。通过流水算法,可以实现古籍文献汉字间隔、交错、粘连情况的切分,解决了传统算法中局限性的问题。
1.4.2 算法模型
采用逐字方式,在列切分的基础上实现字切分,字与字之间的状态可分为间隔、交错、粘连三种情况。间隔状态切分较为简单,可直接通过投影法实现切分。在遇到交错或粘连情况时,首先需要划出待切分区域,再通过算法模型对区域内的字进行切分。待切分区域由投影法结合阈值获得,结合古籍汉字中呈现的书法特征,本文选取黄金分割率0.618作为阈值参数,以平均字符高度的黄金分割点作为待切分区域的开始,在此基础上增加半个字符平均高度值作为待切分区域的结束,具体表达公式如下:

式(1)中H表示平均字符高度,λ表示阈值参数0.618,hstart、hend分别表示待切分区域的起始和结束位置。待切分区域处理过程见图5,图5(a)为原图中上下文字存在交错或粘连,首先将图5(a)进行二值化处理并向右旋转90度得到图5(b),方框部分表示由公式确定出的待切分区域,再将待切分区域单独取出,并以坐标轴的方式显示,结果如图5(c)所示。其中以X轴坐标每个像素点作为流水起始点,T记录流水运动路径,对该区域的流水路径进行比较分析,作为最终切分依据。

图5 待切分区域
在一个二值化图像中,一个像素点只有可能是黑色或白色,本文中前景色为白色,即二值化后的文字颜色,背景色为黑色。流水每一步行进路径选择均与周围像素值有关,若流水在坐标轴范围内顺利到达Y轴底部将被认为是有效路径选择,以此为依据进行交错文字切分;若当前坐标x、y值超出X轴极值,或y值为负值时,均会认为选择当前X轴像素点无法到达Y轴底部,则以此进行粘连部分切分。
在流水每次行进时都会首先查看当前点下面的三个像素,此时将有两种情况:一是三个像素点颜色不全为白色;二是三个像素点全为白色。三个像素点不全为白色时,运动轨迹选择如图6所示。其中T 表示当前点位置,*为无关像素点,w为白色像素点,b为黑色像素点。图中6(a)列出当前点下面三个像素位置以及命名,分别为p1、p2、p3。若p1、p2、p3不全为白色像素时,判断顺序如图6(a)-(g):第一步,只要p2为黑色,p1、p3不全为白色,下一步都将向p2位置移动,如图6(b)、(c)所示;第二步,若p1为黑色,p2、p3为白色,下一步移动至p1位置,如图6(d)所示;第三步,若p3为黑色,p1、p2为白色,下一步移动至p3位置,如图6(e)所示,可以看出流水始终沿着重力向下移动;第四步,若p1、p3为黑色,p2为白色,则认为该像素为噪点,将会被流水吞没,即p2像素值由白色转为黑色,并将下一步移动至p2位置,如图6(f)所示;第五步,若p2 为黑色,p1、p3为白色,则认为流水将流入洼地,此时需要将洼地用水注满,即p2像素值由黑色转为白色,并且移动位置保持不变,如图6(g)所示。

图6 流水运动轨迹选择(一)
为避免待切分图像中出现极细缝隙或极窄障碍条等极端情况,从而影响实际切分效果,本文在预处理过程使用多次滤波、以及调整卷积核大小方式对图像进行操作,最大程度消除待切分图像噪声点。以上流程中的第四、五两个步骤,也均是针对文字边缘噪点的进一步处理。如当前点下面三个像素点全为白色,运动轨迹则有另一种选择,如图7所示。图7中可以看出,p1、p2、p3同时为白色时,则需要获取当前点左右两侧像素值,分别为:若右下方黑色像素距离当前点更近,则下一步向右移动,如图7(a)所示。同理,若左下方黑色像素距离当前点更近,则下一步向左移动,如图7(b)所示。若当前像素两侧出现白色像素时,则认为当前这一行像素为洼地,此时需要将这一行洼地用水注满,即这一行像素值由黑色转为白色,并且移动位置退回至上一步,如图7(c)所示。
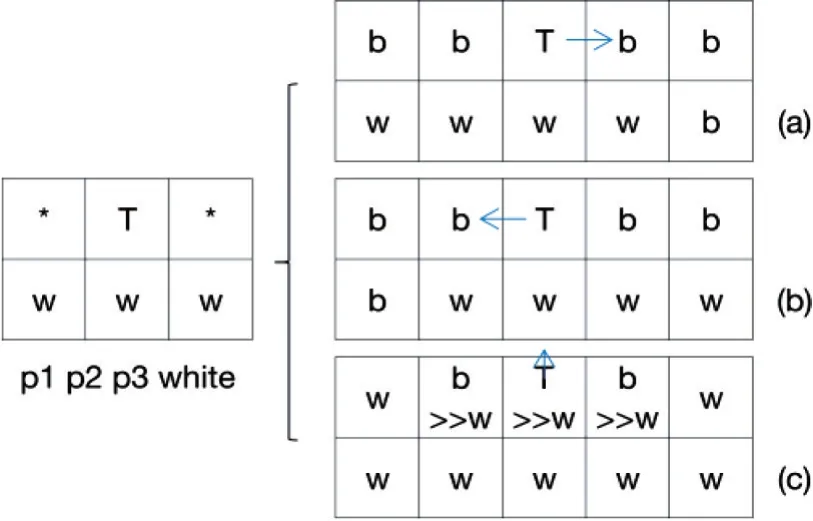
图7 流水运动轨迹选择(二)
所有位置都尝试完成后,进入切分计算。待切分区域有交错或粘连两种情况,待切分区域的处理方式也分为两种。
一是如果有流水轨迹能够顺利到达待切分区域底部,则认为该区域存在文字交错。具体公式如下:

式(2)中T表示流水运动轨迹(x,y)坐标集合,n表示有效运动轨迹T的总数量。将有效轨迹做比较,得到其中最短的轨迹作为结果Tmin;式(3)中将Tmin集合中所有X轴坐标求平均值,得到结果x为最终的交错部分切分的位置。
二是如果在所有位置进行尝试后,未能有流水轨迹到达待切分区域底部,首先会将待切分区域图像倒转,再从反方向进行尝试。若两次尝试都未有轨迹到达待切分区域底部,则认为该区域字符存在粘连。笔者认为,此时可根据书法的特征,古籍图像汉字粘连时,粘连部位存在笔锋最短路径,可利用此作为切分依据,如图8所示。

图8 粘连位置选择切分点
此时比较两侧轨迹,取两侧轨迹中最接近部分作为粘连字符切分点。公式如下:

式(4)中i、j分别表示以不同方式行进的轨迹坐标,对两侧所有轨迹的距离进行计算,得到距离的集合。

在式(5)中,对n个距离集合进行比较,取最短距离dmin作为最终的切分点。以上方式,通过借鉴流水模式,结合古籍文献汉字特征,实现了间隔、交错、粘连情况下的文字切分。
1.4.3 字切分演示
字切分演示如图9所示。图9(a)为待处理列文字,首先将二值化列文字图像进行投影,得到图9(b)。此时若想通过投影法切分文字将十分困难,除“容”与“斋”、“总”与“序”字之间可以通过投影法进行切分,其余切分点很难被找到。为更直观看出不同算法切分实际效果,使用三种算法对演示部分图像文字进行切分轨迹比较,三种算法分别是传统滴水算法、改进滴水算法以及本文的流水算法。图9(c)采用传统滴水算法,在待切分区域中通过Descending-left 方式,由待切分区域x轴的0点作为滴水起始位置进行切分,看到“随”与“笔”、“集”与“总”字大体上切分轨迹能沿着字体边缘行进。“五”与“集”字之间受到笔画因素影响,切分轨迹出现了一些小的偏离。而“笔”与“五”字之间由于起始位置不佳,最终将“五”字的一部分切分出去。在实际切分过程中,无法给出合适的起始点位置是传统滴水算法存在的最大问题。为此,本文通过选择待切分区域投影值最小的点作为起始位置尝试切分,对传统滴水算法进行改进,改进后的切分效果如图9(d)所示。从图中可以看出,调整起始位置后,交错部分的切分轨迹比传统滴水算法有了很大改善,但粘连部分的“笔”与“五”字之间切分轨迹仍没有能够达到理想位置。本文流水算法切分效果如图9(e)所示,为了便于观察,在原图上使用不同颜色进行切分展示,通过流水算法形成了间隔、交错、粘连三种不同情况时流水的轨迹,作为最终字切分依据。图9(e)中的细直线表示可以通过投影法直接切分;若上下文字存在交错,则通过流水轨迹中最短路径作为交错部分的切分位置;若存在文字粘连,则通过算法求出粘连部分最接近点坐标,以此位置作为粘连切分点。从图9(c)中可以看出,“容”与“斋”、“总”与“序”字之间通过投影法进行切分,“随”与“笔”、“五”与“集”、“集”与“总”字之间存在交错,通过穿越交错区域流水最短路径平均值作为切分依据;而“笔”与“五”字之间存在粘连现象,则是通过上下流水聚集区域最接近点作为切分依据。

图9 字切分处理演示
2 古籍文献汉字切分实践
2.1 列切分结果分析
列切分的准确率受页面分割线、图像倾斜角度等因素影响,列切分准确率公式为:

式(6)中Ln表示正确切分的列数,Lt表示列总数,Sl为列切分正确百分比。本文采用二值化投影后的形态处理,消除页面中的分割线、以及非正文内容残影。本文对三种古籍文献共计888列进行切分,总体准确率为98.65%,列切分结果如表2所示。列切分准确率受到文献保存完整性影响较大,在面对版面污渍较多、页面内容不完整情况时,会出现切分错误现象。

表2 样本列切分结果
2.2 字切分结果分析
样本切分效果如图10所示。为了更加清楚了解切分中的过程,图中分别用不同颜色的方框来表示切分时遇到的情况。红色方框,表示该字与下方文字存在一定间隔;绿色方框,表示该字与下方文字存在交错;蓝色方框,表示该字与下方文字存在粘连。从图中可以看出,运用本文中算法取得了较好的切分效果,能够较为准确地切分到每个汉字的主体结构,且从图10(c)可以看出,图像预处理对原图中的倾角进行了矫正。

图10 切分效果显示
流水算法实现古籍文献汉字切分时,虽然有的字一些边缘部分被切分了出去,但对字的整体识别没有影响,本文认为这种情况属于正确切分。本文将未能正确切分情况,分为过切与漏切两种,切分结果判定示例如图11所示。图11(a)中的“斋”与“随”字之间存在交错情况,通过流水算法能够很好地就交错位置进行切分。从图中可以看出,虽然“斋”有少量边缘部分被切除出去,但并不影响整体字的识别,此类情况将被判定为正确切分。图11(b)中“乘”与“木”之间存在明显的粘连,通过流水算法能够准确以粘连位置作为切分点。图11(c)“十”字由于字体所占像素较少,且有部分残缺,被误认为版面污渍,造成了漏切。图11(d)中,由于“一”与“爻”两字间的间隙较小,被误认为一个字,造成了漏切。图11(e)中,由于受到版面污渍影响,造成了过切。另外,切分结果受到版面图像中的批点、模糊等因素,以及页面残损、字体结构分离影响,这也是造成错误切分的原因。若版面由墨汁等因素造成的污渍较大,将会被误认为正文内容,造成过切。字体的结构也是造成错误切分的因素之一,若字体上下结构分离严重,或字与字间高度粘连,将也会出现过切或漏切现象。

图11 字切分判定
为验证流水算法效率,本文将采用分类任务评价方式,对流水算法在古籍文献汉字切分中的可行性进行评估。分类任务的常用评价指标有:精确率(Precision)、召回率(Recall)、F 值(F1 Score)等等。具体公式如下:

式(7)中的p为精准率,本文表示被流水算法实际切分的汉字当中,结果为正样本的比例,其中TP表示正确切分数,FP为过切数。

式(8)中的r为召回率,本文表示针对样本总汉字数量而言,通过流水算法实际切分为正样本所占比例,其中TP表示正确切分数,FN为漏切数。

式(9)中的f为精准率与召回率的综合评价值,本文表示流水算法在切分样本数据中的整体调和均值。
具体样本切分结果见表3,所有样本切分数量全部小于实际样本数量,且从FP与FN值比较可以看出,不论何种样本,漏切数均超过了过切数。导致这一结果的原因与本文算法中的流水区域阈值选择有关,为尽量避免由于字体结构分离使得的过切分概率增大,本文选择黄金分割0.618作为阈值参数,虽然有效避免了过切分现象发生,但是也使得实验过程中的漏切分数量增加。从表中也可以看到,《金陵防守利便》《钜鹿东观集》两种抄本的精准率虽然与其他刻本相差不多,但召回率分别为90.69%、95.05%。与其他刻本相比,受到字体、版面等因素影响,抄本中出现漏切现象较多。总体来看,文献的年代对结果影响不大,仅与文献的保存情况直接相关。最终实验结果,样本总体字切分精准率为99.00%,召回率为95.62%,F值为97.27%。

表3 样本数据切分结果
3 结论
古籍文献汉字呈现的复杂度较高,造成切分时难度远大于现代印刷品,除去文献的保存完整性因素,文字间的交错、粘连情况也是切分难点。本文利用古籍文献汉字特征,提出借鉴流水模式的思路实现古籍文献汉字切分,并选取6本文献中的87页内容、共计14,503字进行算法适用性验证。最终,列切分准确率达到98.65%,字切分精准率为99.00%,召回率为95.62%,F值为97.27%。受到样本复杂度影响,刻本切分效果整体好于抄本。结果表明,流水算法在面对古籍文献汉字存在交错、粘连等情况时,也能取得较好的切分效果。流水算法实现难度低、易用性强、实际效果好,适合在古籍收藏机构推广使用,配合当前国内大型互联网公司的文字云识别产品,使得很多中小图书馆自主推进古籍数字化工作成为可能。本文研究虽然取得一定的效果,但在面对古籍中版面存在破损、多粘连汉字、结构分离严重的汉字等情况时,仍会有切分不准确的情况存在,还需要后续开展更深入的研究。随着具体实践研究的增多,相信古籍数字化工作将会不断取得突破。
