融合知识表示和深度强化学习的知识推理方法
2021-10-14宋浩楠王兴芬
宋浩楠,赵 刚,王兴芬
北京信息科技大学 信息管理学院,北京 100192
随着知识图谱相关技术的快速发展,各种大规模的知识图谱被构建出来并广泛服务于各个领域。例如Freebase[1]、DBpedia[2]、NELL[3]等知识图谱都为研究和应用提供了巨大数据支撑。但是,无论是自动化构建或人工构建的通用知识图谱,还是自动化构建或人工构建的领域知识图谱,绝大多数都存在一定程度的不完备问题[4],知识图谱中存在大量的实体和关系缺失。知识图谱补全技术便是为了应对实体和关系缺失而出现,该技术的最主要方法就是知识推理[5]。
近年来,基于知识表示学习推理和基于关系路径推理等研究方法,已成为知识推理研究的热点。知识表示学习方法(TransE[6]、TransH[7]等)因其具有较好的效率和性能,所以被广泛应用于知识推理相关任务中,该类模型将知识图谱中的实体和关系映射到低维向量空间,并在此空间中进行计算完成推理;关系路径推理方法作为一种适用于大规模知识图谱的推理方法引起关注和研究,其主要思想是:在知识图谱中充分挖掘和利用实体间多步关系,组成路径信息从而完成知识推理。而知识表示学习和关系路径相融合的方法因其同时具备以上两种优势,因此得到广泛的研究和利用。
尽管如此,现阶段知识图谱补全研究中仍存在可解释性差、大规模知识推理效率和准确率较低的问题,特别是推理的可解释性[8]逐渐受到领域研究者的关注。针对这类问题,本文提出了一种将知识表示和深度强化学习(Reinforcement Learning,RL)相结合的方法RLPTransE。将知识图谱中的所有的三元组信息通过知识表示方法映射成低维向量空间中的稠密向量,充分保留其语义信息,同时引入强化学习方法,将知识图谱中知识推理问题转化为马尔可夫序列决策问题,通过知识表示和强化学习相融合的方法充分挖掘知识图谱中的有效推理规则,并且对智能体选择的路径质量进行了控制,从而高效完成大规模知识图谱的补全任务,该融合方法也为知识推理的混合推理研究提供了新的思路。
与其他方法相比,本文方法在大规模数据集上的表现均优于知识表示学习推理和关系路径推理等方法。
本文的主要贡献:
(1)提出了一种融合知识表示和深度强化学习的知识推理方法RLPTransE,将知识推理问题转化为序列决策问题,增强了推理的可解释性。
(2)提出了一种单步择优策略网络和多步推理策略网络的双网络结构。其目的是准确并高效地挖掘高质量推理规则。
(3)该融合推理方法充分发挥了两者的优势,在公开标准数据集上的对比实验结果显示,本方法取得了较好的性能,为知识推理的混合推理研究提供了新的思路。
1 相关工作
知识图谱的中知识缺失问题普遍存在,而知识推理是解决知识图谱补全任务的重要方法。大规模知识图谱中知识推理方法大致分为三类:基于知识表示学习的方法、基于关系路径的方法和基于知识表示学习和关系路径融合的方法。本章将按照此类别对国内外知识推理方法研究进行介绍。
1.1 基于知识表示学习的推理方法
自词嵌入表示模型提出后,许多自然语言任务都证明了其重要作用。受此启发,对知识三元组的表示学习也取得了许多突破性成果。Border等人[6]提出了TransE,将知识库中实体之间的关系当作实体间的某种平移,实现了对多元关系数据高效建模的知识补全,但该模型在处理一对多等复杂关系表示问题存在不足。针对这个问题,后续研究提出了许多衍生版本。Wang等人[7]提出TransH,引入超平面法向量,实现了不同实体在不同关系下拥有不同的表示,但三元组知识仍处于相同的语义空间,限制了自身的表达能力;Lin等人[9]提出了TransR,为每一种关系定义单独的语义空间,并使用不相同的映射矩阵实现从实体空间到不同关系空间的映射;Ji 等人[10]提出TransD,不仅考虑关系的多样性,而且考虑实体的多样性,提出了不同实体具有不同的映射矩阵,减少模型参数的同时使模型更加灵活。Ebisu等人[11]提出TorusE,将TransE的思想应用在李群(Lie group)理论的环面空间中。Sun 等人[12]提出RotatE,实现知识表示学习从实数空间到复数空间的扩展。将关系看作是从头实体到尾实体的旋转。Zhang 等人[13]引入超复数的概念,提出了QuatE,与RotatE类似,该模型将关系看作超复数平面内头实体到尾实体的旋转。相比于其他先进方法,上述方法存在以下问题:(1)将知识推理转化为单一的向量计算,带来了可解释性差的问题;(2)未能充分利用关系路径等重要信息,推理能力受限,推理准确率尚有较大提升空间。
1.2 基于关系路径的推理方法
该类方法主要是基于知识库中图的结构特性进行研究推理[14]。Lao 等人[15]提出了路径排序算法(Path Ranking Algorithm,PRA),将知识库中连接实体的不同的关系路径作为特征,通过在知识库中统计路径来构建分类的特征向量,建立针对关系的分类器来预测两个实体之间的关系。Lao等人[16]基于PRA算法,通过调整和组合图中不同随机游走相关权重来学习推断关系,提升路径推理质量的同时使其更适用于大规模知识图谱推理。Gardner 等人[17]提出的子图特征提取模型,将图中的节点对生成特征矩阵,通过修改PRA 路径搜索的过程,提取路径之外更丰富的特征,提高推理的效率。Gardner 等人[18]通过结合文本内容对PRA 算法进行修改,引入了向量空间相似性,缓解了PRA中的特征稀疏性问题。Das等人[19]使用RNN模型,通过递归方式组合知识图谱中多跳路径的分布式语义从而构成关系路径,并且在推理过程中引入了注意力机制。Chen 等人[20]设计了概率图模型下的推理问题,在知识推理中引入变分推理框架,将路径搜索和路径推理紧密结合从而进行联合推理,大幅提升了推理效果。相比于其他先进方法,上述方法存在如下问题:(1)由于存在数据稀疏问题,知识图谱中的信息未被充分利用;(2)未考虑路径的可靠性[5]计算问题,难以适用于大规模知识图谱。
1.3 基于知识表示学习和路径融合方法
上面的两类模型仅考虑了图谱中实体间的直接关系或者只考虑了实体间简单的路径关系,但事实上,知识图谱中实体之间的关系路径隐含着丰富的语义信息,研究知识表示和关系路径的融合方法具有重要意义。Lin等人[21]设计了PTransE,使用语义连接算法表示路径关系,同时引入路径约束资源分配算法来衡量关系路径的可靠性,将实体和关系映射到低维空间中表示计算,从而显著提高推理能力。陈海旭等人[22]提出了PSTransE,该模型对PTransE进行了改进,用关系和路径的向量相似度来表示路径推理关系的概率,通过互补方法计算推理概率,在综合考虑相关路径信息的同时,更注重关键路径对推理所起的决定性作用。文献[23-24]都是在PTransE的基础上的改进模型,它们的基本结构一致,仅在知识的表示方式上存在不同。
近年来,机器学习的可解释性越来越得到大家的关注,强化学习在可解释性和性能等方面的优势,使得强化学习应用于知识推理领域成为研究热点。Xiong 等人[25]设计了DeepPath,将知识库中知识推理过程转化为马尔可夫序列决策过程(Marcov Decision Process,MDP),以实体集合为状态空间,关系集合为动作空间,智能体通过选择最优动作以拓展其路径来实现知识库中的推理。但由于DeepPath模型简单,并且需要提供大量已知路径进行预训练,训练过程复杂,因此其推理性能存在很大提升空间。Das等人[26]提出了MINERVA,将起始实体到目的实体之间的路径选择问题转化为序列决策问题,通过建模以查询问题为条件引导模型在知识库中找出预测路径,解决了在已知一个实体和关系情况下的问答问题。Lin等人[27]提出了Multi-Hop,针对路径择优和路径多样性探索的问题分别提出了软奖励机制和随机Action-Drop方法。Li等人[28]提出了DIVINE,一种基于生成式对抗模仿学习的框架,并通过模仿从知识库中自动采样来自适应地学习推理策略和奖励函数。Wang等人[29]提出了AttnPath,将LSTM和图注意力机制作为记忆组件,并提出一种新的避免智能体停滞不前的强化学习机制来提高推理成功率。相比于其他先进方法,上述方法侧重于提高推理准确率,但由于引入许多新技术,模型的复杂度更高,推理效率较低。
2 融合知识表示和深度强化学习的知识推理方法
上述推理方法,各有其优点和不足。因此本文考虑结合这两类方法的优势来提高模型推理的可解释性、准确性和推理效率,于是本文提出了一种融合知识表示和深度强化学习的推理方法RLPTransE。如图1 所示,使用知识表示学习方法,将知识图谱映射到含有三元组语义信息的向量空间中,然后在该空间中建立深度强化学习的环境。通过基于有监督的单步择优策略网络的训练,降低RL智能体单步错误动作的选择率,再通过基于奖励函数的多步推理策略网络的训练,提升RL 智能体搜索正确路径的成功率。最终,实现RL 智能体在与知识图谱环境交互过程中,成功挖掘推理规则进而完成推理任务。
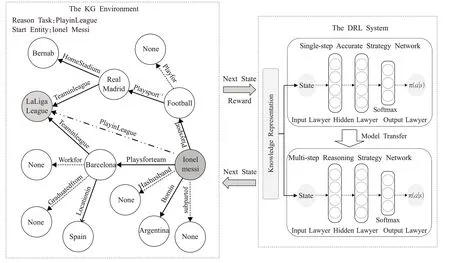
图1 融合知识表示和深度强化学习的知识推理模型框架图Fig.1 Overall framework of integrating knowledge representation and deep reinforcement learning model for knowledge reasoning
2.1 知识表示学习模块
为了解决大规模知识推理面临的复杂数据高效利用的问题,在词嵌入表示模型的启发下,研究人员基于分布式思想提出知识表示学习(Knowledge Representation Learning,KRL)的方法[6],将实体和关系的语义信息映射到低维向量空间,使得语义相近对象的向量表示距离也相近。
在TransE模型中,知识库中的关系当作实体间的某种平移。对于知识库中三元组,用lh、lr和lt依次表示头向量、关系向量和尾向量。该模型的核心思想如公式所示:

使用基于边界的方法,定义了如下优化目标函数:

其中,S是正样本三元组集合;S′是负样本三元组集合,该集合是通过随机替换正样本三元组的头实体或者尾实体得到;[x]+表示max(0,x);γ表示一个边界参数,是一个需要设置为大于零的超参。
当前知识表示学习模型多样。本文选用了TransE模型,因其参数数量较少,在大规模稀疏数据集上效果明显,在与深度强化学习融合过程中,解决了知识稀疏性问题,提高了模型整体效果,实验结果证明该模型对本文方法具有支撑作用。
2.2 深度强化学习模块
本文将知识图谱中推理问题转化为马尔可夫序列决策问题,RL 智能体的动作选择和状态转移都是在该框架中进行的,故本部分将介绍对知识图谱的强化学习建模过程。
该过程主要由
(1)状态空间S
本模型的状态空间S是由知识图谱中的有效实体集合E组成的。针对本文的双策略网络结构,设计了两种状态。在单步择优策略网络中,将每个实体作为RL智能体的具体状态s;在多步推理策略网络中,将当前实体和目标实体作为RL 智能体的具体状态s,其中状态s∈S。状态的两种表示如下:

其中,ec表示知识图谱中的当前实体,et表示知识图谱中的目的实体,s1t、s2t是当前实体在状态空间中的向量化表示。为了规范化表达,如无特殊说明,本文状态均用s表示。
(2)动作空间A
RL智能体在当前状态下,经过动作选择后,基于环境的交互反馈实现状态转移。本模型的动作空间A是由智能体可能选择的动作集合As组成的,它是由状态s的当前位置实体在知识图谱G 中所有可能的输出边组成的,动作集合表示如下:

其中,ec、en分别表示当前位置实体和下一个可能的位置实体,a表示采取的动作,S表示状态空间,R表示关系集合,E表示实体集合。
特别地,关系集合R由知识图谱中已存在的关系r和新添加关系r-1两部分组成,r-1是关系r的逆关系。大量实验研究表明,将r-1关系添加到动作空间中,不仅可以使智能体自动撤销错误的决策,而且还可能发现一些隐含的推理信息。
(3)状态转移P
RL智能体通过选择当前状态下的最优动作实现状态转移,具体而言,智能体以知识图谱中的某个实体为当前位置,选择一个与当前实体相连的某个具体关系作为下一步执行的动作,然后执行该动作,实现智能体状态转移。状态转移P表示如下:

(4)奖励函数γ
RL 智能体完成一次完整的任务过程后,环境都会给予智能体一定的奖励,包括正向奖励和负向奖励,智能体根据这些反馈的奖励值来更新自己的策略,以实现最大化的奖励。本文采取了多样化的奖励方式,下面将对奖励函数进行详细介绍。
全局奖励在同环境交互过程中,智能体会有大量的可选动作,这就意味着智能体很有可能选择错误的动作,从而导致无法到达目标状态。为了解决该问题,强化学习方法添加了一个全局奖励函数。若智能体在与环境的交互过程中,从起始状态ecur成功达到目标状态etar,则给予智能体一个正向奖励,否则无奖励。其定义如下:

单步负向奖励 在同环境交互过程中,智能体可能选择大量错误动作,为了降低智能体的错误动作选择率,定义了单步负向奖励函数,当智能体选择的动作不能推理出目标实体时,给予负向奖励。

路径长度奖励对于知识图谱中的推理任务,大量的研究表明:短关系路径p比长关系路径p更能提供有价值的推理关系。为了限制推理路径的长度,提高推理效率。本文定义了如下的路径长度奖励函数:

路径多样性奖励为了使智能体推理出不同的关系路径,本文定义了如下的路径多样性奖励函数:
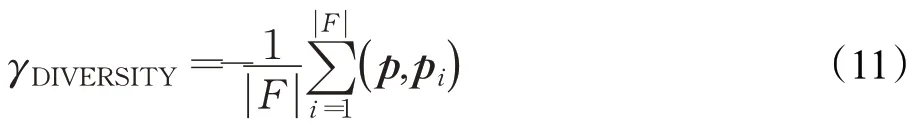
其中 |F|表示已发现的路径的数量,p和pi表示关系路径组成的表示向量。
单步择优策略网络仅使用全局奖励进行训练,多步推理策略网络则综合使用4种奖励函数进行训练,训练过程中保证正向奖励总和大于负向奖励总和。
(5)策略神经网络
由于大规模知识图谱的关系数量众多,建模出来的强化学习方法的动作空间规模庞大,因此本文直接选择基于策略梯度的深度强化学习来完成该任务。本文使用三层全连接神经网络设计策略函数,其中在每个隐藏层之后添加非线性层(ReLU),并使用softmax函数对输出层进行归一化处理。该策略网络实现了将状态向量s映射到所有选择动作的概率分布中,本方法采用REINFORCE[30]策略进行参数优化,如下面公式所示:

其中θ是策略网络的参数,π(a=rt|st;θ)是基于状态st时策略网络输出动作为rt的概率,γ是选择该动作获得的奖励值。
本文方法中单步择优策略网络和多步推理策略网络使用了相同的神经网络结构。
2.3 训练过程
训练过程由单步择优策略网络训练和多步推理策略网络训练两部分组成。如图1所示,首先使用有监督策略学习方法对单步择优策略网络进行训练,提高RL智能体在推理过程中单步择优能力。将训练后的参数作为多步推理策略网络的初始化参数,基于奖励函数对多步推理策略网络进行再训练,提高智能体在推理任务中的多步路径择优能力。
2.3.1 基于有监督的单步择优策略网络训练
本文首先对RL智能体进行有监督策略学习的单步择优策略网络训练任务,目的是让智能体尽可能地在第一步就选择正确动作。单步择优策略网络在知识图谱推理任务中只需训练一次,极大提高了推理效率。
(1)训练集
知识图谱中的三元组集合F={eh,r,et} 是RL 智能体知识推理的环境。首先,为三元组集合F中元素添加一个反向关系,生成一个新的三元组集合F′={(eh,r,et),(et,r′,eh)}。取出F′中三元组的前两部分并将相同部分合并组成二元组训练集合Dtrain={(eh,r),(et,r′)}。
(2)训练流程及算法
RL 智能体依次将训练集合Dtrain中的实体作为的起始状态ecur,并输入到深度强化学习的策略网络中,根据策略网络的输出结果,选择一个关系r作为下一步的执行动作,此时判断起始状态ecur和单步动作选择的关系r组成的新二元组是否属于Dtrain,若是,给予+1奖励并更新策略网络。预训练算法如算法1所示。
算法1单步择优策略网络训练算法
输入:Dtrain
输出:强化学习智能体的策略网络参数


2.3.2 基于奖励函数的多步推理策略网络训练
经过单步择优策略网络训练后,RL 智能体对单步动作选择具有很高的成功率,但它在知识图谱环境交互过程中多步动作选择的成功率却很低。而对于知识推理任务而言,实现多步推理才是任务目标。本部分的主要目的是通过基于奖励函数的再训练,提高智能体在推理任务中的多步路径选择能力。
(1)训练集
为了提高本模型的整体性能,对于知识图谱中的三元组集合F={eh,r,et},将r作为推理任务。针对特定的推理任务r′(r′∈r),将三元组集合F中含有关系r′的三元组分离出来,组成推理任务三元组集合T={eh,r′,et},按照比例7∶3分为训练集Trainset和测试集Testset。
(2)训练流程及算法
与单步择优策略网络训练任务不同,多步推理策略网络训练的目的是使RL智能体高效的完成多步关系路径推理任务。对于推理任务三元组集合T={eh,r′,et} 中的三元组(eh,r′,et),RL智能体从起始状态eh出发,通过与知识图谱环境不断地交互中发现有效路径,寻找除了关系r′外到达目的状态et的路径。在与知识图谱环境不断地交互过程中,使用多种奖励函数对深度强化学习进行多步推理策略网络训练。训练的算法2如下所示。
算法2多步推理策略网络训练算法
输入:训练集Trainset
输出:强化学习智能体的策略网络参数

3 实验与分析
通过公开数据验证方法有效性,并通过对比和消融实验来进一步分析说明。代码使用Python 编写,基于TensorFlow框架实现。运行环境为Ubuntu 18.04.5操作系统,Intel®Xeon Silver4210 2.20 GHz CPU和NVIDIA Tesla V100S GPU。
3.1 数据集及参数介绍
本文实验中,采用知识推理领域通用的两个基准数据集FB15K-237[31]和NELL-995[25]作为对比实验的实验数据集,两者都是较大数据集的子集,其中FB15K-237中的三元组是从FB15K中去除了冗余关系后得到的数据集。NELL-995 是基于NELL 系统的第995 次迭代产生的数据集整理后的数据集。数据的统计信息如表1所示。
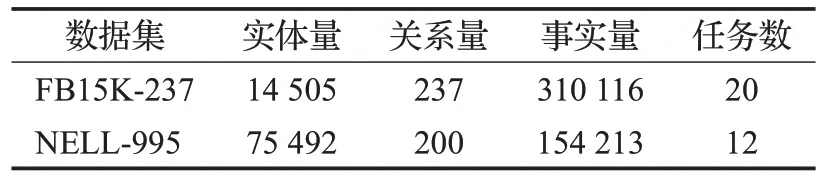
表1 数据集统计信息Table 1 Statistics of the datasets
本文方法知识表示模型TransE用Fast-TransX(https://github.com/thunlp/Fast-TransX)中的方法训练,嵌入维度设置为100维;策略网络的隐藏层是由两个全连接网络和ReLU激活函数构成,神经元分别设置为512和1 024,输出层节点数等于RL环境中所有关系数量:FB15K-237是474,NELL-995是400。单步择优策略网络训练任务上batchsize设置为1 000,训练1 000个epochs。
3.2 评价方式和评价指标
对于知识推理任务的评价方式,通常是链接预测(Link Precdiction,LP)和事实预测(Fact Precdiction,FP)。链接预测是预测三元组中缺失的部分。事实预测是在判断三元组的正确与否。数据集按7∶3的比例分为训练集和初始测试集,而测试集是由初始测试集和其生成的负样本组合而成,正负样本比例约为1∶10,其中负样本是由正样本被替换尾实体生成。此次实验使用平均精度均值(Mean Average Precision,MAP),定义如下:

3.3 实验结果及分析
为了验证RLPTransE 方法的有效性,将本文方法RLPTransE与基于知识表示学习算法(TransE[6]、TransH[7]、TransR[9]、TransD[10)]、基于关系路径算法(PRA[16]、DIVA[20)]和基于融合算法(DeepPath[25]、AttnPath[29]等)在两个公开数据集上进行对比实验,实验结果如表2和表3所示。

表2 链接预测结果Table 2 Link prediction results
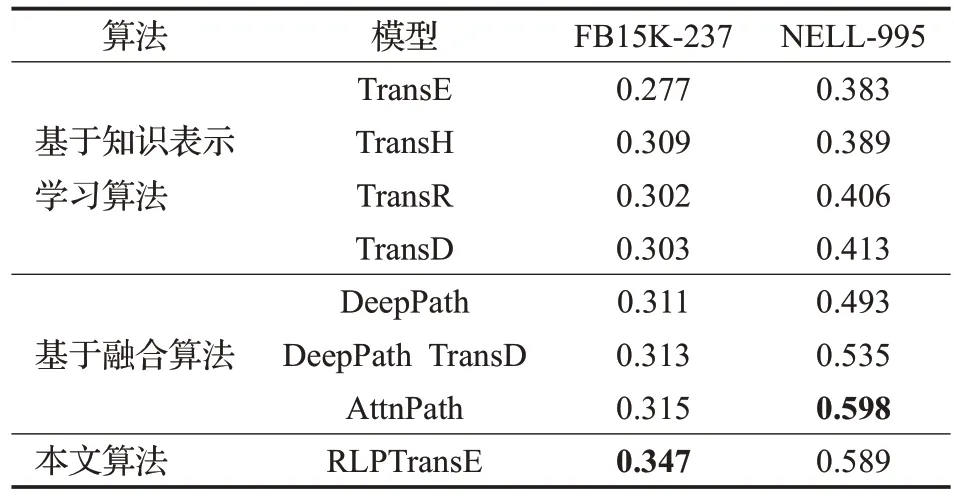
表3 事实预测结果Table 3 Fact prediction results
3.3.1 链接预测
链接预测是指三元组在给定头实体和关系二元组(eh,r)条件下预测三元组的尾实体et。本文采用DeepPath中测试方法,通过对候选尾实体打分来进行排名。实验结果由表2所示。
由表2所示的实验结果可知,本文方法在FB15K-237数据集上取得了最优的链接预测结果,性能比AttnPath高出0.031,而在NELL-995数据集上取得了优于知识表示学习方法、关系路径方法中PRA和融合方法中Deep-Path 的性能,但略逊色于MINERVA 等其他模型的性能。本文方法在规模较大的FB15K-237 数据集上性能提升更明显,主要原因是:相比于关系稀疏的NELL-995数据集,FB15K-237数据集中实体之间平均路径长度较长,动作选择的错误率更高,导致大量正确路径难以被挖掘,模型性能降低。而本文的优势在于降低错误动作的选择率,提高正确路径的挖掘成功率,因此在FB15K-237数据集上效果提升更明显。
3.3.2 事实预测
事实预测旨在判断未知事实是否为真,对于给定的三元组(eh,r,et),模型通过判断符合路径的个数作为分数,从而判断其正确与否。本文延用DeepPath中的评价方法,对测试集所有输出采取全排名方式计算结果,由于PRA 未提供所有三元组全排名结果,因此这里不考虑PRA作为基线。表3显示了所有方法的结果。
如表3所示,本文方法同样在FB15K-237数据集上的事实预测结果达到了最优性能,性能比AttnPath高出0.032,而在NELL-995 上取得优于其他模型,但略逊色于AttnPath的结果。对于FB15K-237数据集,本文方法比知识表示学习方法中性能最好的TransH 高出0.038。对于NELL-995 数据集,本文方法比知识表示学习方法中性能最好的TransD高出0.176。相比于融合模型中的DeepPath及其衍生模型,本文方法性能均有较大提升。
3.4 消融实验
为了进一步分析单步择优策略网络训练对本文模型推理效果的影响,本节对RLPTransE做了消融实验分析。将RL智能体直接从多步推理策略网络开始推理任务,即在原方法的基础上去掉单步择优策略网络训练任务,得到模型RLPTransE-part,使用和RLPTransE相同的训练集和测试集对该模型进行训练和测试。消融实验的结果如表4所示。两个模型的测试次数统一设为1。

表4 预训练消融实验结果Table 4 Pre-training ablation experimental results
如表4 所示,RLPTransE-part 模型在链接预测和事实预测的实验结果都不及RLPTransE模型,主要原因是缺乏单步择优策略网络训练的方法,单步选择有效路径能力不足,路径的搜索能力弱,直接影响多步推理效果。因此,实验结果表明,引入单步择优策略网络对推理任务的完成具有明显的提升效果。
为了进一步分析单步择优策略网络在本方法中的重要性。本文对该网络的单步择优能力作了对比实验,使用不同训练集对单步择优策略网络进行训练,然后对网络的单步选择成功率进行统计。定义如下三种模型:All-train,使用Dtrain的样本集合{(eh,r),(et,r′)} 训练;Postrain,使用Dtrain中正向样本集合{(eh,r)} 训练;No-train,不使用样本集合训练,即使用初始化参数。不同epoch次数下的实验结果如表5所示。
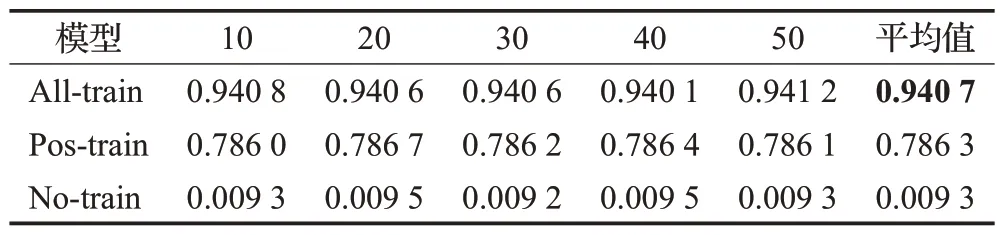
表5 对比实验结果Table 5 Comparative experimental results
如表5所示,使用Dtrain训练的All-train在单步选择成功率上的均值达到了94.07%,Pos-train 结果达到了78.65%,而No-train 的选择成功率几乎为0。该实验充分验证单步择优策略网络对本方法具有重要支撑作用。
3.5 推理规则的分析
为了分析本文方法对知识推理可解释性的增强作用,从RL 智能体在NELL-995 数据集上挖掘出的推理规则中选择部分任务结果,如表6所示。
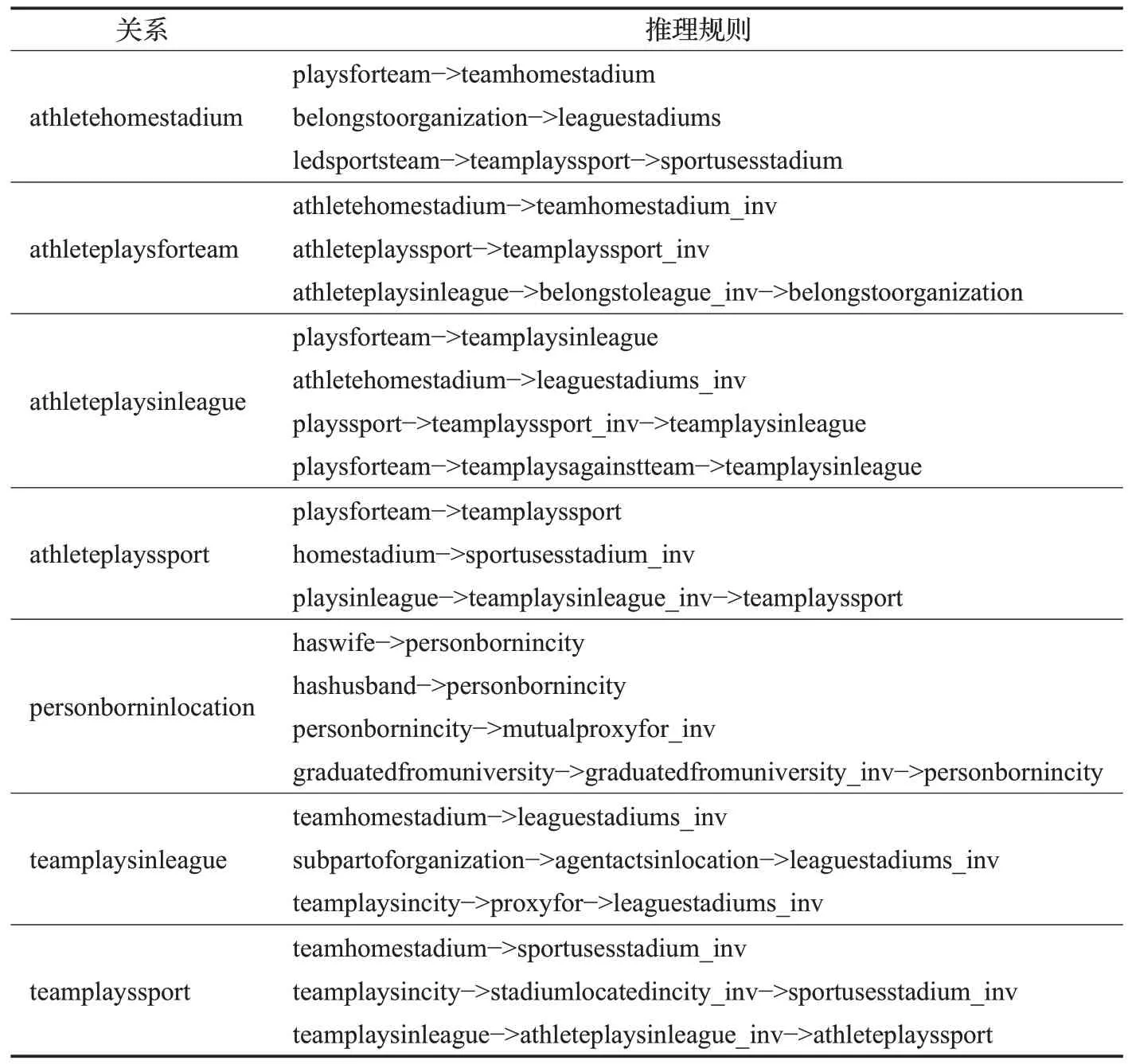
表6 RL智能体发现的推理规则Table 6 Inference formulas found by RL Agent
如表6 所示,对于任务关系“athleteplaysinleague”,对应的推理规则为“playsforteam->teamplaysinleague”和“athletehomestadium->leaguestadiums_inv”,即运动员效力的球队所属的联赛就是运动员效力的联赛和运动员主场所注册的联赛就是运动员效力的联赛。其他任务的说明类似,不再逐一展开分析。因此,分析结果表明,本文方法对于增强知识推理的可解释性具有重要支撑。
4 结束语
本文提出了一种融合知识表示和深度强化学习方法RLPTransE。该模型通过知识表示方法,将知识图谱映射到含有三元组语义信息的向量空间中,然后在该空间建立强化学习环境,将知识推理成功转化为马尔可夫序列决策过程。基于有监督的单步择优策略网络的训练和基于奖励函数的多步推理策略网络的训练,使得RL 智能体在推理过程中挖掘出高质量推理规则,从而完成大规模知识图谱推理任务。在公开数据集上的对比实验表明,本文方法提升了推理性能,特别是大规模知识图谱推理任务。本文还通过消融实验对单步择优策略网络对本文方法的影响做了进一步分析。通过对挖掘出来的推理规则分析,验证了本文方法对知识推理可解释性具有增强作用。
