基于随机森林的海河流域地表温度降尺度
2021-10-12李建明马燕飞李仁杰商国营李明明
李建明,马燕飞,李仁杰,2,4,商国营,李明明
(1.河北师范大学 资源与环境科学学院,石家庄 050024;2.河北省环境变化遥感识别技术创新中心,石家庄 050024;3.邯郸学院 地理系,河北 邯郸 056005;4.河北省环境演变与生态建设实验室,石家庄 050024)
0 引言
陆地表面温度(land surface temperature,LST)是陆地表面水热平衡的重要分量,直接驱动地表与大气之间能量交换。观测与反演LST,对全球气候变化评估、生态问题控制、水热循环的进一步研究具有重要意义。同时,对农业指导、旱情监测、提高农田水资源利用率做出了重要贡献[1]。目前,LST已经广泛应用到多种领域,如城市热岛[2]、土壤水估算[3]、蒸散发(evapotranspiration,ET)估计[4]等。但现有的地表温度产品多为大网格尺度,难以满足田块尺度的地表热通量研究[5]。MODIS热红外遥感地表温度产品可以大面积获取地表热通量数据,但是空间分辨率较低,在中纬度地区受云雨天气影响,热红外地表温度空间上不连续、缺失大量像元,实际应用价值低[6-7]。近年来,星载热红外传感器空间分辨率与时间分辨率不能共存的缺陷日趋明显。在地表温度反演领域引入LST降尺度方法,使获取不同时空分辨率的地表温度产品成为可能[8],因此,降尺度技术就成为连接大尺度LST与区域小尺度地表热通量的纽带。
地表温度空间降尺度是在低空间分辨率像元值的基础上,融合高空间分辨率的解释向量,获取更多的空间细节信息。降尺度根据算法原理的不同可以分为两类。一类是基于物理机制的图像融合降尺度方法,包括空间滤波分析法[9]、相关系数法(相关统计分析)[10]、主成分分析法等[11]。二类是基于尺度因子统计关系的降尺度方法[12]。Kustas等[13]建立陆地表面温度与植被指数的统计回归关系,融合高分辨率的航空数据(24 m)进行地球同步运行环境卫星数据降尺度,得到田块尺度的空间细节信息,并提出使用热红外遥感与NDVI进行TsHARP算法融合,对地表温度反演;Ma等[14]使用NDVI在Kustas的TsHARP算法基础上进行改进,对地表温度进行降尺度。但是,传统算法难以表征地表温度与地表参数之间复杂统计关系。机器学习在地表温度数据降尺度的探索、分析、预测和模型的建立与评估方面优势明显,可以在众多解释向量中提取需要的信息,获取高分辨率地表温度影像,并重建热红外地表温度的缺失像元。孟杨繁宇[15]使用机器学习的方法对黑河流域的蒸散发进行回归、预测。受到启发,毛克彪等[16]尝试将机器学习引入LST降尺度研究,使用神经网络算法对地表温度进行反演,引入AMSR-E被动微波温度数据,并重建热红外数据在云雨天气的数据缺失。Hutengs等[17]使用随机森林算法对1 000 m分辨率的地表温度进行降尺度,利用红光、近红外波段的地表反射率和数字高程模型DEM构建最优解释向量集,建立简单随机森林降尺度模型(basic-RF),得到250 m分辨率的地表温度。
本文以海河流域为研究区,MODIS地表温度产品为数据源,通过随机森林算法对地表温度进行降尺度,建立地表温度与解释变量(植被指数、空气温度、下行短波辐射)的降尺度模型。建立了精细图像与粗图像之间的非线性映射关系,选取植物生长月份进行地表温度的回归预测。探讨随机森林降尺度算法在不同下垫面的表现,刻画田块尺度的地表温度在海河流域的时空分布格局,为海河流域地表水热循环研究提供数据参考。
1 研究区概况与数据预处理
1.1 研究区概况
海河流域位于112°E~120°E、35°N~43°N之间。东临渤海湾,西倚太行山,南临黄河,北接蒙古高原[18]。行政区划包括京津冀大部、山西省东部、河南省北部及山东省东北部地区。流域总面积32.06×104km2,占全国总面积的3.3%。海河流域包括五大支流(潮白河、永定河、大清河、子牙河、南运河)和一个小支流(北运河)。海河流域地势西高东低,以高原、山地以及平原等三种地貌为主。海河流域地处温带半湿润半干旱大陆性季风气候区,流域年平均气温在1.5~14.0 ℃,年平均相对湿度在50%~70%之间,年平均降水量约为535 mm,年平均陆面蒸发量约为470 mm,水面蒸发量约为1 100 mm。近年来,海河流域气温呈明显上升趋势,水资源呈减少趋势[19]。
1.2 数据来源与处理
本文主要使用MODIS产品中2~3级的V005版标准数据产品,包括地表温度产品、植被指数NDVI产品,具体信息见表1。其中,地表温度产品MOD11A1数据集的DN值(有效数据)范围为7 500~65 535,地表真实温度值由DN值转换得到,转换如式(1)所示。
Ts=(DN)*(scale factor)+offset(K)
(1)
式中:scale factor为比例系数,取值为0.02;offset为偏移量,取值为0。
植被指数产品存储信息与地表温度产品类似。MODIS数据产品是以HDF-EOS格式存储,正弦格式(sinusoidal)方法进行投影的。如图1所示,本文所需完整海河流域的MODIS数据是由四幅影像镶嵌得到,需利用MODIS数据预处理工具MRT(MODIS reprojection tool)对这些产品进行重采样和镶嵌。首先,考虑到海河流域的地理区位与空间形状特征,将影像均采用Albers等面积投影;然后,使用最邻近法将影像均重采样为250 m×250 m、500 m×500 m、1 000 m×1 000 m三种栅格大小;最后,使用海河流域矢量边界将重采样后的栅格数据裁剪到研究区范围大小。
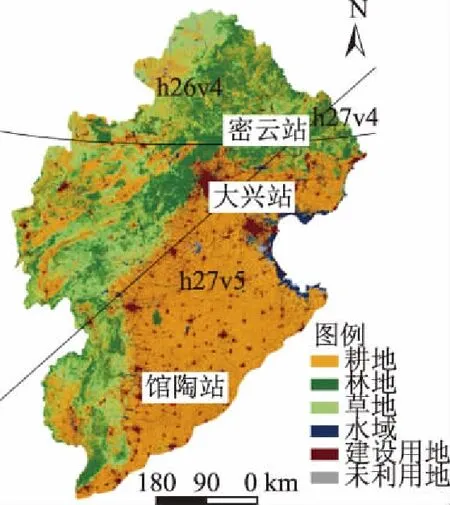
图1 研究区概况图、MODIS数据分幅及周边气象台站

表1 MODIS数据产品
1.3 地面站点数据
“海河流域多尺度地表通量与气象要素观测数据集”[20]是国家青藏高原科学数据中心(https://data.tpdc.ac.cn/zh-hans/)发布的2008—2010年自动气象站观测数据。用户可通过“寒区旱区科学数据中心”申请并下载该数据集。该数据集不仅可以定量揭示海河流域主要下垫面地表水热通量交换特征,同时也为遥感估算地表蒸散量的验证提供地面“相对真值”。如表2与图2所示,数据来源主要包括三个自动气象站点:海河流域密云站(山区林地)、馆陶站(南部农田)和大兴站(中部城郊)。密云站下垫面是果园(李子树和苹果树),馆陶站下垫面是耕地(玉米、小麦、棉花),大兴站下垫面是耕地(玉米、小麦),气象站点下垫面性质较为均一。自动气象站的采集频率为10 s,且10 min输出一次。
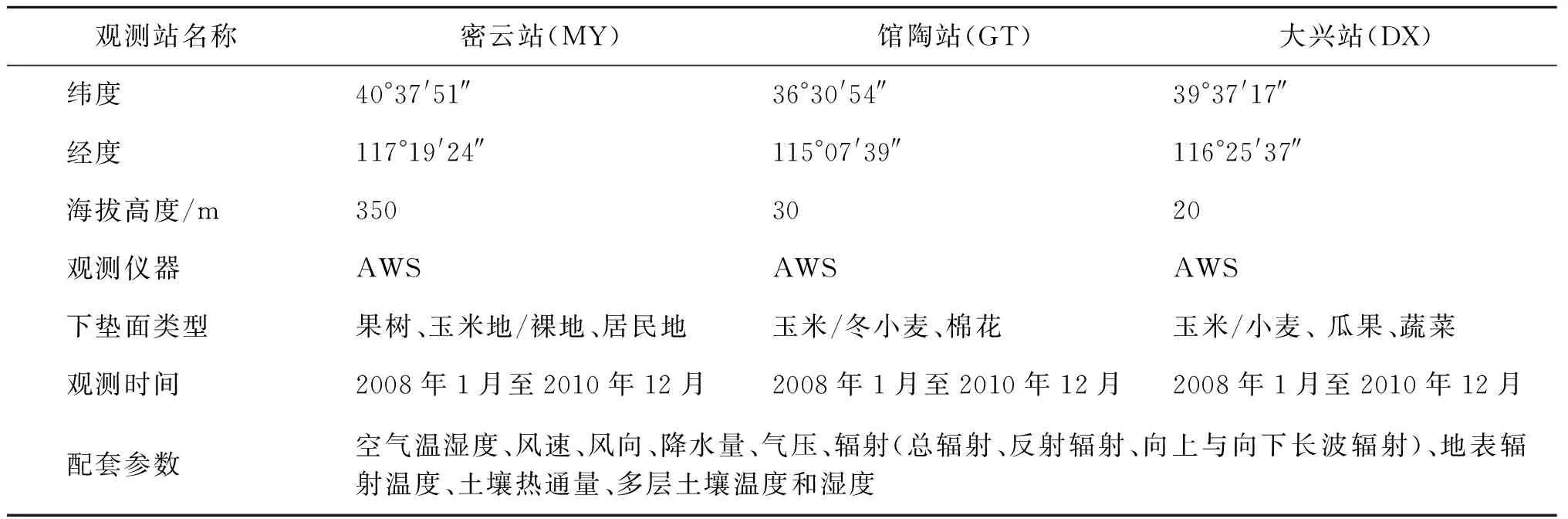
表2 观测点数据

图2 气象站点
1.4 其他数据
本文还收集了用于地表温度降尺度的海河流域部分地区的空气温度、下行短波辐射数据。用到的相关专题图有:海河流域边界矢量图、海河流域土地利用(GlobeLand30 http://www.globallandcover.com)等。在具体应用过程中还对这些专题图件做了进一步的裁剪、重采样及范围匹配等处理。
2 研究方法
2.1 随机森林原理
随机森林是用途广泛的一种机器学习算法,随机森林模型的本质是对决策树算法的改进。随机森林模型是一个树型分类器,输入一个二维的矩阵,构建没有剪枝的回归决策树,每个叶子节点代表一个回归结果,决定了单棵树的生长过程,随机森林的回归模型采用单棵树输出结果的简单平均得到。在估算数据的过程中,解释变量的构建对于目标数据相当重要。随机森林是一个决策树的集合,它的功能更多依赖于决策树的功能[21],是在其基础上的扩展,从训练库中提取实例进行判断,根据属性最终决定拿出哪个样本来预测最优结果。因此可以说,随机森林是一个元估计器,适用于大量子样本基础上的决策树分析,主要使用平均值来提高预测精度和控制过度拟合[22],最终的预测结果不会摆脱训练样本的范围。本文构建的模型本质上属于回归问题,对于回归问题随机森林模型给出所有决策树预测结果的平均。在地表温度降尺度过程中,地表温度与各地表参数(解释向量)间呈非线性关系,而随机森林降尺度模型对多元共线性不敏感。
本研究采用R语言中random forest数据包构建随机森林降尺度模型,训练样本为低空间分辨率(500 m、1 000 m)的遥感影像,地表温度作为因变量,植被指数、空气温度、下行短波辐射作为解释变量,以获取更高空间分辨率的地表温度。
如图3所示,解释变量集与地表温度训练出的某种映射关系构成了随机森林地表温度降尺度模型,即在低空间分辨率影像(1 000 m)上建立地表温度与地表参数(解释变量)的统计关系,并假设这种统计关系不随尺度的大小而变化。计算如式(2)所示。
LSTpre(EVI)=H(EVI)
(2)
式中:LSTpre表示地表温度预测值;EV表示多个地表参数组成的最优解释变量集;I表示高空间分辨率影像(250 m);H表示地表温度与最优解释变量集的回归模型。

图3 降尺度示意图
2.2 降尺度模型构建
随机森林地表温度降尺度由数据模型驱动,其本质是以大量解释向量样本为基础,通过随机森林模型方法训练样本,进而挖掘遥感图像更加精细的空间细节。因此,解释向量集的选择十分重要。经过实验,本文将表3中的归一化植被指数、空气温度与下行短波辐射构成解释向量集。本文地表温度降尺度的核心是:随机森林降尺度模型的建立与解释变量集的选择。降尺度模型构建的具体步骤为:①MODIS LST数据与解释变量数据的镶嵌、重投影等预处理,并重分类为高分辨率(250 m)和低空间分辨率(500 m、1 000 m)的数据集;②将不同分辨率的解释向量数据集、地表温度数据集转换成随机森林算法可以识别的CSV文件;③将MODIS LST、解释向量集作为降尺度模型的训练数据进行训练;④把高分辨率(250 m)的解释向量数据输入到训练好的降尺度模型,获取高分辨率(250 m)的地表温度预测结果;⑤将降尺度模型预测结果CSV文件转换回遥感图像。技术线路如图4所示。

表3 解释变量集类型与名称
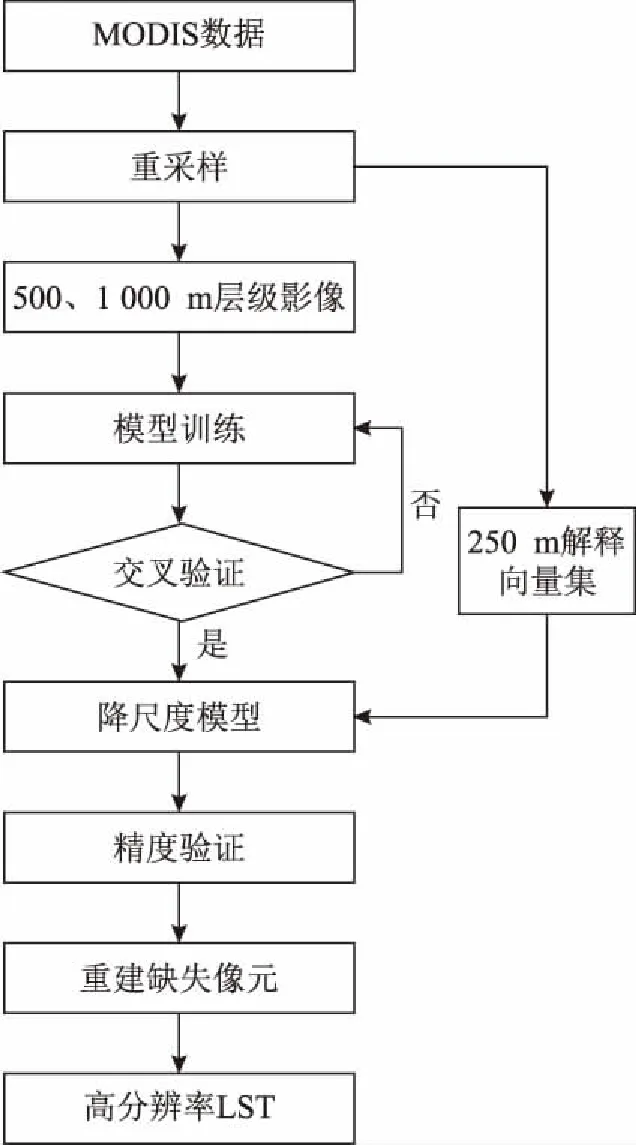
图4 技术流程图
3 降尺度结果
3.1 降尺度模型筛选
对随机森林降尺度模型输入参数进行调整,构建500 m、1 000 m两个不同分辨率层级的训练样本,使用均方根误差(RMSE)、决定系数(R2)、偏差(bias)、相对精度(RA)对模型进行筛选,确定最优模型算法。分别在500 m、1 000 m分辨率层级上使用随机森林模型进行训练。500 m与1 000 m分辨率层级模型的验证结果如表4所示。在不同分辨率层级,相同的解释向量组合的训练集下,随机森林降尺度模型的性能表现优秀,可以使用更少的数据来描述解释向量集与陆表温度之间的非线性关系。在500 m和1 000 m随机森林训练模型中,随机森林算法在1 000 m分辨率层级下表现出的空间异质性更小,训练模型表现更优,下一步采用1 000 m分辨率的训练模型进行陆表温度反演。
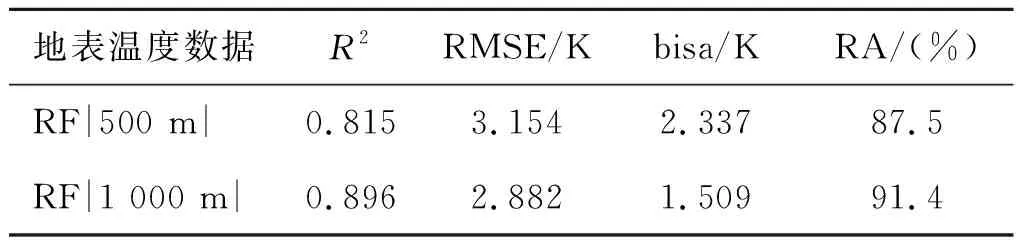
表4 随机森林在500 m、1 000 m层级下模型反演LST的评分
3.2 降尺度模型RF的站点直接验证
地面观测实验的目的是为了获取地面真实值,以便对遥感估算结果进行验证,但是由于仪器观测的不确定性和误差的客观存在,所以必须对观测数据进行处理与质量控制[23]。基于MODIS MOD11A1遥感数据来获取地表温度,降尺度后空间分辨率为250 m,这与自动气象仪的观测尺度是不匹配的。本文地表温度观测数据采用四分量辐射仪计算得到的结果。四分量辐射有效探测范围分别是:馆陶站15.6 m、大兴站28 m、密云站30.76 m。一定程度上克服了站点尺度监测范围小的缺陷,计算如式(3)所示。
(3)
式中:σ为斯蒂芬-玻尔兹曼常数(5.67×10-8W/m2K4);ε为地表比辐射率;Rlu为大气上行长波辐射;Rld为大气下行长波辐射。
大兴站、密云站、馆陶站的降尺度LST与辐射四分量对比,平均误差分别为3.86 K、2.37 K、1.96 K。地面气象数据为点尺度的数据,对卫星数据进行验证时理想的下垫面为匀质下垫面。其中,大兴站为非匀质下垫面(旱地与果园),因此在尺度匹配时出现系统误差,导致降尺度地表温度与地面气象数据误差较大;密云站、馆陶站为匀质下垫面(旱地),降尺度地表温度与地面气象数据误差较小。

图5 RF 模型的反演的LST与地面站点 LST散点图
3.3 RF降尺度模型在不同下垫面的表现
为了定量描述随机森林降尺度模型在不同下垫面的降尺度效果,如图6(a)所示,本文在海河流域选取了五个不同下垫面性质的子研究区。其中,子研究区A下垫面性质为草地;子研究区B下垫面性质为林地;子研究区C下垫面性质为旱地;子研究区D下垫面性质为旱地与建设用地;子研究区E下垫面性质为林草交错地。将五个子研究区降尺度结果升尺度至1 000 m,分别与MODIS原始地表温度影像对比在不同下垫面性质区域的降尺度效果并分析其空间分布特征。通过表5与图6(c)可以看出,RF随机森林方法在海河流域地表温度降尺度上总体表现优秀,这是由于RF随机森林主要使用平均值来提高预测精度和控制过度拟合,可以更好地捕捉解释向量与LST之间的函数关系,从而获得高精度的降尺度结果。在植被覆盖度高的草地、林地、林草交错地带降尺度效果R2、RMSE、bias优于植被覆盖度低的建设用地、旱地,降尺度的相对精度也更高,草地、林地、林草交错地与原始温度反演结果一致性更高。与植被覆盖度高的子研究区相比旱地、建设用地RF随机森林降尺度优势并不明显。从影像的RMSE来看,建设用地达到3.894 K,说明解释变量集(NDVI、空气温度、下行短波辐射)与LST的关系可能呈现出不稳定的非线性关系。
从图6(b)可以看出,在五个子研究区内,降尺度影像与MODIS原始影像的地表温度在空间分布上一致,但总体来说降尺度影像的地表温度要略低于MODIS原始影像。在降尺度地表温度产品空间分布格局上,能够合理地反映下垫面温度变化,对地表温度的空间分析具有重要意义。

注:A、B、C、D、E代表五个子研究区;下标1表示降尺度地表温度;下标2表示MODIS原始地表温度。图6 RF降尺度模型效果

表5 RF模型反演LST的评分
3.4 重建地表温度缺失像元
如图7所示,通过RF|1 000 m|模型的降尺度的地表温度数据,融合250 m分辨率的无缺失像元解释向量集得到的250 m海河流域地表温度数据,填补了MODIS MOD11A1地表温度产品由云导致的地表温度缺失像元。获取海河流域地表温度更精细的空间信息,得到精度更高的地表温度产品,满足海河流域地表温度时空格局的研究。
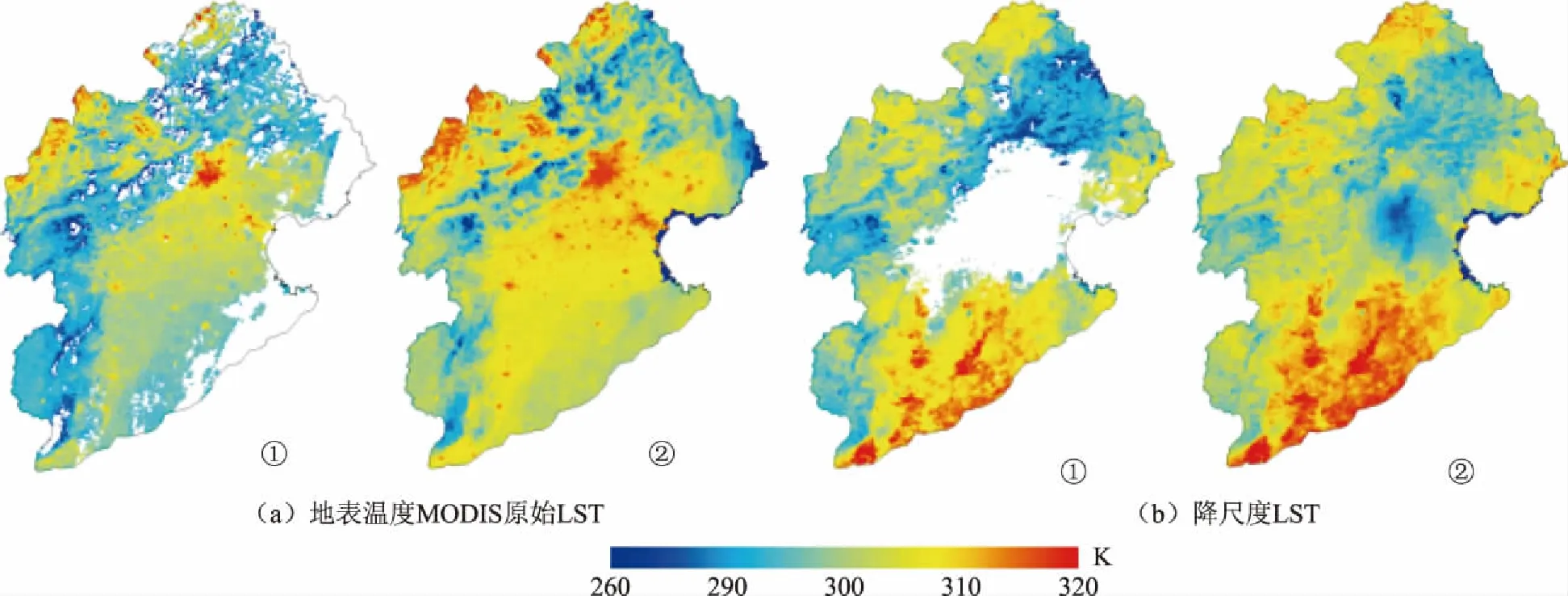
注:①代表2008年第241天;②代表2010年第240天。图7 海河流域降尺度结果
4 结束语
本文以海河流域为研究区,探索了利用植被指数、空气温度、下行短波辐射等解释向量对地表温度空间降尺度的方法。通过对随机森林算法在两个空间尺度(500 m、1 000 m)下的训练模型进行分析,随机森林1 000 m算法表现优于随机森林500 m。将MODIS MOD11A1地表温度产品与随机森林模型降尺度的地表温度在五个子研究区进行验证分析,结果表明降尺度地表温度的结果空间分布较为合理。将降尺度地表温度与地面气象站点的辐射四分量温度进行直接验证,在大兴站、密云站、馆陶站的平均误差分别为:3.86 K、2.37 K、1.96 K。最终,构建了随机森林算法地表温度降尺度模型。将MODIS MOD11A1地表温度降尺度到250 m分辨率,并利用降尺度地表温度填补MODIS地表温度的缺失像元,避免了MODIS MOD11A1地表温度产品空间分辨率较低、易受天气影响、有效像元信息缺失严重、实际应用价值低等问题。海河流域的降尺度地表温度数据为数据稀疏区域的数据获取提供科学参考。
本文总体上亮点有三点。一是将植被指数、空气温度、下行短波辐射组成的最优解释向量集引入到MODIS地表温度降尺度,将地表温度的空间分辨率由1 000 m降尺度到250 m,获取到更加精细的地表温度空间细节。二是在海河流域选出五个子研究区,分析了在不同下垫面性质下,随机森林降尺度模型的效果。三是采用辐射四分量温度对地表温度降尺度结果进行直接验证,一定程度上改善了验证数据与降尺度地表温度像元尺度不匹配的问题。
但文中仍存在一些不足需进一步研究,如通过遥感反演得到的地表温度具有一定的方向(观测角度)性,模型没有考虑卫星传感器倾斜观测角度造成的地表温度差异。如何将倾斜观测的地表温度归一到垂向观测值,是未来研究需进一步考虑的内容。
