基于改进遗传算法的光伏板清洁分级任务规划
2021-10-12李翠明
李翠明,王 宁,张 晨
(兰州理工大学 机电工程学院,兰州 730050)
近年来太阳能作为一种可再生的绿色清洁能源,受到了广泛的关注,光伏产业在我国得到了大力发展.太阳能光伏系统的核心部件是太阳能光伏板,其发电效率与接收到的太阳辐射强度、时长密切相关.我国西部地区有极丰富的太阳能资源,很多大型并网光伏电站都建设于此,但因空气中沙尘较多,沙尘极易附着在光伏组件上[1],光伏组件覆灰在极大程度上提高了光伏组件的衰减速率,严重影响太阳电池板的使用寿命[2].因此,及时对太阳能板表面进行清洁至关重要.对太阳能板表面覆灰典型的清洁方式有传统人工高压水枪清洗、爬壁式智能清洁设备清洁、太阳能板自洁技术、车载移动式清洗机清洁等[3].考虑到我国西部地区的特殊环境条件,车载移动式的清洗设备比较适应这种恶劣的自然环境.目前,对于用移动清洁机器人对光伏电站进行清洁问题的研究相对较少.文献[4]采用低成本的Kinect2深度传感器对半结构化环境进行实时三维环境重建,在重建得到的三维环境地图中用D*算法和弹性带算法实时规划出了清洗机器人的运动路径.文献[5]将机器人工作的空间分解成一系列具有二值信息的栅格网络,采用优先级启发式算法规划出了清洁机器人的运行路线.文献[6]利用Unity3D软件对西部某光伏产业园的真实地形进行仿真,运用融合了跳点搜索策略的改进A*算法在仿真地图上进行清洁机器人的路径规划.
上述研究只考虑了如何让清洁机器人快速、无碰撞地到达指定的清洁位置,并未考虑由于环境影响,不同区域的光伏板发电量不同,清扫顺序会对整体发电效率产生影响.本文根据西部地区特殊的环境特点,研究了清洁机器人对大面积光伏电站光伏板清洁作业时的任务规划问题.按照光伏板是否处在风口位置、光照时长等环境因素,对光伏电站进行分区,并确定各分区的清扫优先等级,利用Hamilton图将太阳能光伏板清洁问题转化为巡回旅行商问题(TSP).TSP问题是典型的NP-hard问题,目前解决TSP问题的方法大致可以分为两个方向[7],一种是能够找到问题最优解的精确算法;另一种是一般能够较为高效地求得可接受的问题解的近似算法,如:遗传算法[8]、蚁群算法[9]、布谷鸟搜索算法[10]等.这些近似算法大大缩小了解空间并增加了在有限时间内找到问题最优解的概率[11].在这些近似算法中,遗传算法在解决离散组合优化问题上的有效性引起了更多学者的关注.因此,本文在遗传算法的基础上,提出一种改进遗传算法(IGA)求解此TSP问题,运用将锦标赛选择法与轮盘赌选择法相结合的混合选择算子,提高算法的收敛速度;采用基于分段规则的交叉算子,使算法更容易跳出局部最优,并且增强算法的稳定性;最后,运用IGA对清洁机器人的分级任务规划进行求解,并与自适应遗传算法(AGA)对比仿真,验证了IGA的优越性.本文对光伏电站光伏板清洁问题的研究可为大面积光伏电站提高整体的发电效率提供一种新的研究思路.
1 光伏电站分区问题的描述
对我国西部地区大面积光伏电站提出分区规划策略,对放置在风口位置极易积灰、严重影响发电效果和光照充足、发电效率高的区域分配较高的优先级,其余区域给予相同的优先级,则可将西部某地区的光伏电站划分为若干区域,如图1所示.划分区域后的光伏电站如图2所示.其中:x为各区域围成的多边形几何中心的横坐标;y为各区域围成的多边形几何中心的纵坐标.每个点表示一片区域,并用数字对其进行编号.各区域的优先级如表1所示.优先级分为6级,数字越大表明优先级越高.
划分区域之后的光伏电站清洁问题本质上就是TSP问题,即已知各个区域的坐标,清洁机器人从起点出发,遍历每个区域且每个区域只经过一次,最后回到起点.TSP问题是图论中最著名的问题之一,TSP问题可以通过构造Hamilton图求解.可将每一片区域看成顶点,区域间的距离看成边,构造Hamilton图G=(V,E),如图3所示.其中:V={1, 2, …,n}为顶点集;E={1, 2, …,m}为边集.任意两顶点的连线表示边集,考虑到实际情况,两片区域之间基本不可能直接到达.因此,本文取顶点间的Manhattan距离构成边集.光伏电站清洁任务的分级规划问题,就是在图3中寻找一条最短的Hamilton回路.
2 基于IGA的机器人清洁任务规划
由于对各个区域指定了优先级,首先对各区域按优先级排序,先清洁优先级高的区域;优先级相同时,采用IGA进行清洁任务规划的求解.为了更接近实际问题,染色体采用实数编码方式,如图4所示.遗传算法存在比其他传统优化算法效率低、容易过早收敛等问题,针对遗传算法的这些不足,本文对遗传算法的选择、交叉操作进行了改进.
2.1 适应度函数的动态线性标定
适应度函数是对染色体的优劣进行评价的标准,适应度函数设计不当,将难以体现个体的差异,选择操作的作用就难以体现出来,从而造成早熟收敛等特点[12],因此,合理选择适应度函数在算法执行过程中至关重要.所求问题的目标函数为各区域的距离之和,距离越小越优,而适应度函数则越大越好,因此需要对其进行变换.如果直接取倒数,会导致适应度函数之间的相对差别很小,从而导致各个体被选择的概率差别很小,这将会弱化遗传算法的选择功能,本文对目标函数采用动态线性标定[13]的方法将其转化为适应度函数.变换公式为
(1)
(2)
式中:M、c为常数,c∈[0.9, 0.99].参数M是为了增大个体之间被选择概率的差别而设置的,根据所研究的问题,经过多次实验验证,M取为600,c取为0.99.
2.2 混合选择算子
将锦标赛选择法[14]和轮盘赌选择法[15]相结合作为选择算子.锦标赛选择法是随机从父代中选择一定数目(即竞赛规模N)的个体,将其中适应度高的个体保留到子代.反复执行本过程,直到子代的个数达到预先设定的终止条件.若种群大小用S表示,每个竞赛规模中选取适应度最高的个体,则共有S/N(取整数位)个个体保留到子代.本文选择的竞赛规模为10.
轮盘赌选择法用于在每个锦标赛选择法选出的竞赛规模中选取进行下一步交叉操作的一个父代,另一个父代在竞赛规模中随机选取.通过两种方法的结合,既确保了优秀个体遗传到下一代,又保证了参加交叉操作的父代质量.
2.3 基于分段规则的交叉算子
顺序交叉(OX)算子是一种常用的交叉算子,OX 算子可将父代染色体中指定的基因片段遗传给子代.但这种操作不考虑边之间的关系,不会加快遗传算法的收敛速度[16],且计算结果不稳定.针对OX算子的这种特点,提出一种基于分段规则的交叉算子,此算子采用OX和自身交叉两种算子,当所求路径长度大于所设阈值Q时,交叉操作采用顺序交叉;当所求路径长度小于Q时,采用自身交叉.阈值Q是通过分析改进之前的算法结果所确定的.经过多次实验,未改进之前的算法多次陷入局部最优,其局部最优值在 800~1 000 之间.针对这种情况引入自身交叉算子,并通过实验确定阈值Q.通过本次改进,增加了交叉操作产生最优个体的概率,提高了算法的收敛速度,增强了算法稳定性,本文中阈值Q选为900.
顺序交叉首先在两个父代上选择相同的区域:
然后,将两个父代交叉点之间的部分提取出来,得到:
记录父代1和父代2从第2个交叉点开始的数字排列顺序,当到达末尾时,继续从初始位置记录,直到回到第2个交叉点为止,由此便得到了父代1和父代2从第2个交叉点开始的数字排列顺序,分别为7→8→9→1→2→3→4→5→6和5→3→7→4→6→1→8→2→9.子代1已有从父代1继承的3、4、5、6,将其从父代2的数字排列顺序中去除,得到7→1→8→2→9,然后将此序列从第2个交叉点开始填入到子代1中,获得新个体子代1′.同理可得,新个体子代2′:
自身交叉首先在父代上随机选取两个位置,两个位置中间构成一块区域:
然后,将区域内的数字左右对调一下,形成新的个体:
2.4 启发式变异算子
目前,变异算子有很多种,如倒位变异算子、2-opt变异算子、启发式变异算子等,其中效果较好的是启发式变异算子[17].选用启发式变异算子,其操作步骤如下.
步骤1假设A=1 2 3 4 5 6 7 8.
步骤2随机选择3个点,如:1、2、6,任意交换其位置可得5个不同个体为
A1=2 1 3 4 5 6 7 8
A2=6 2 3 4 5 1 7 8
A3=1 6 3 4 5 2 7 8
A4=2 6 3 4 5 1 7 8
A5=6 1 3 4 5 2 7 8
步骤3从其中选择适应度最高的个体作为新个体.
2.5 算法流程
IGA流程图如图5所示,基本流程如下.
步骤1输入各区域坐标,并将各区域按优先级排序,先确定优先级高的区域清洁顺序,再确定参与IGA的区域个数.
步骤2生成初始种群,设定相关参数,包括适应度函数中的M和c,锦标赛选择法中的竞赛规模N,交叉操作中的阈值Q,交叉概率Pc,启发式变异概率Pm,最大迭代次数Tmax,种群数目S.
步骤3对各区域间的距离进行动态线性标定,转化为求最大值的适应度函数.
步骤4用锦标赛选择法筛选出直接进入下一代的个体;用轮盘赌法选取参与交叉的父代.
步骤5对父代进行交叉操作,当本次迭代最优路径大于阈值Q时,执行顺序交叉;否则,执行自身交叉.
步骤6对生成的子代进行启发式变异操作.
步骤7判断是否满足终止条件.若达到,则输出最优解;若未达到,则返回步骤3.
3 仿真结果及分析
根据上述算法步骤,利用MATLAB R2020a对算法进行设计实现,使用的CPU为AMD Ryzen 7 4800H,主频为2.90 GHz,内存为8.00 GB.其中,区域数为30,各区域的优先级见表1.种群数为100,交叉概率为0.8,变异概率为0.05,迭代次数为500次,仿真结果如图6所示,其中:L为路径总长度.由图6可知,IGA求解的机器人清洁各个区域的任务顺序为:30→29→28→27→6→24→···→7→20→4→22→30,路径总长度为760 km.IGA求解的最优路径随迭代次数变化情况如图7所示,其中:T为迭代次数;o为最优解.由图7可以看出,当算法迭代到181次时,能够求得此最优顺序.
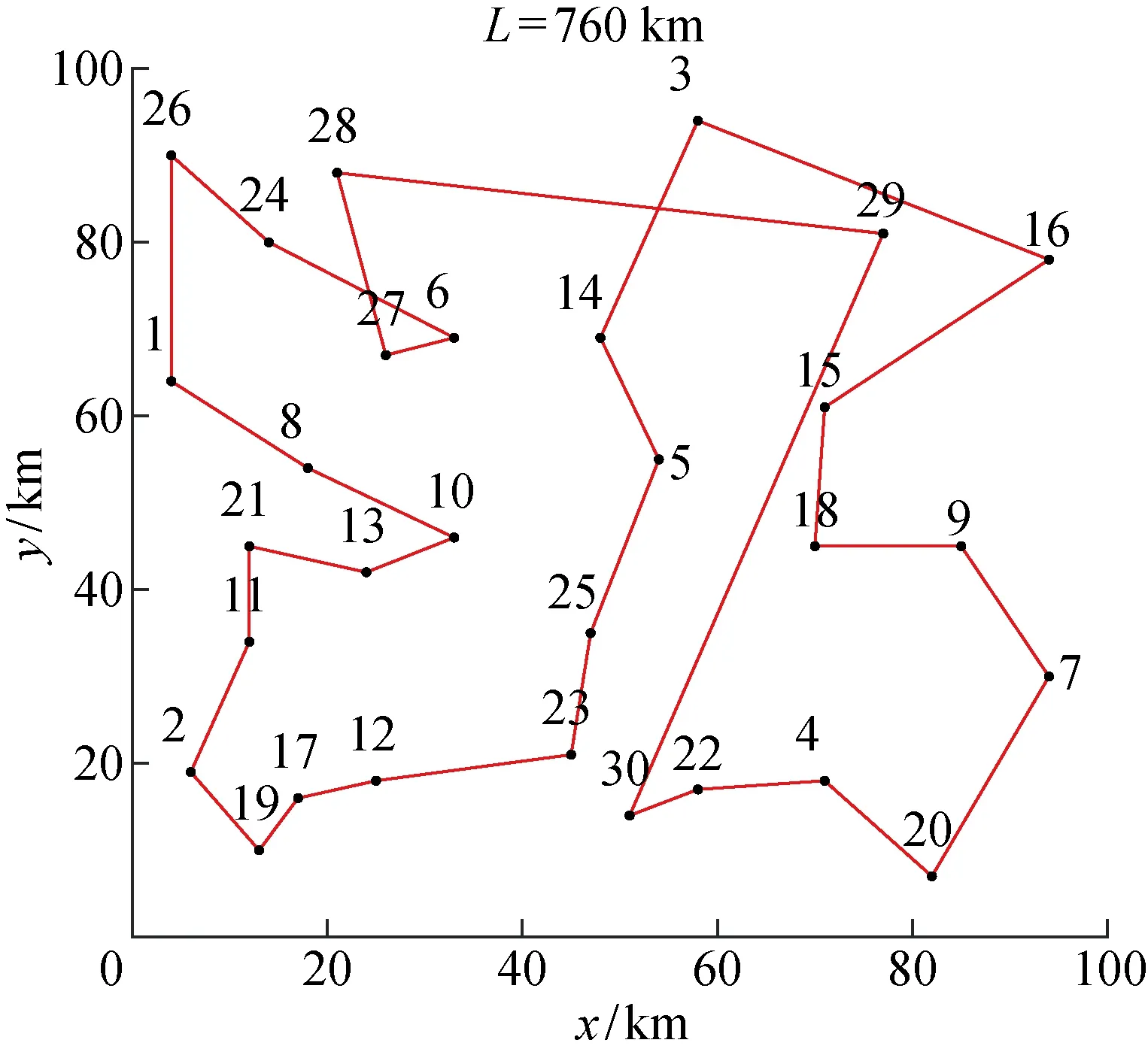
图6 改进遗传算法规划出的任务顺序
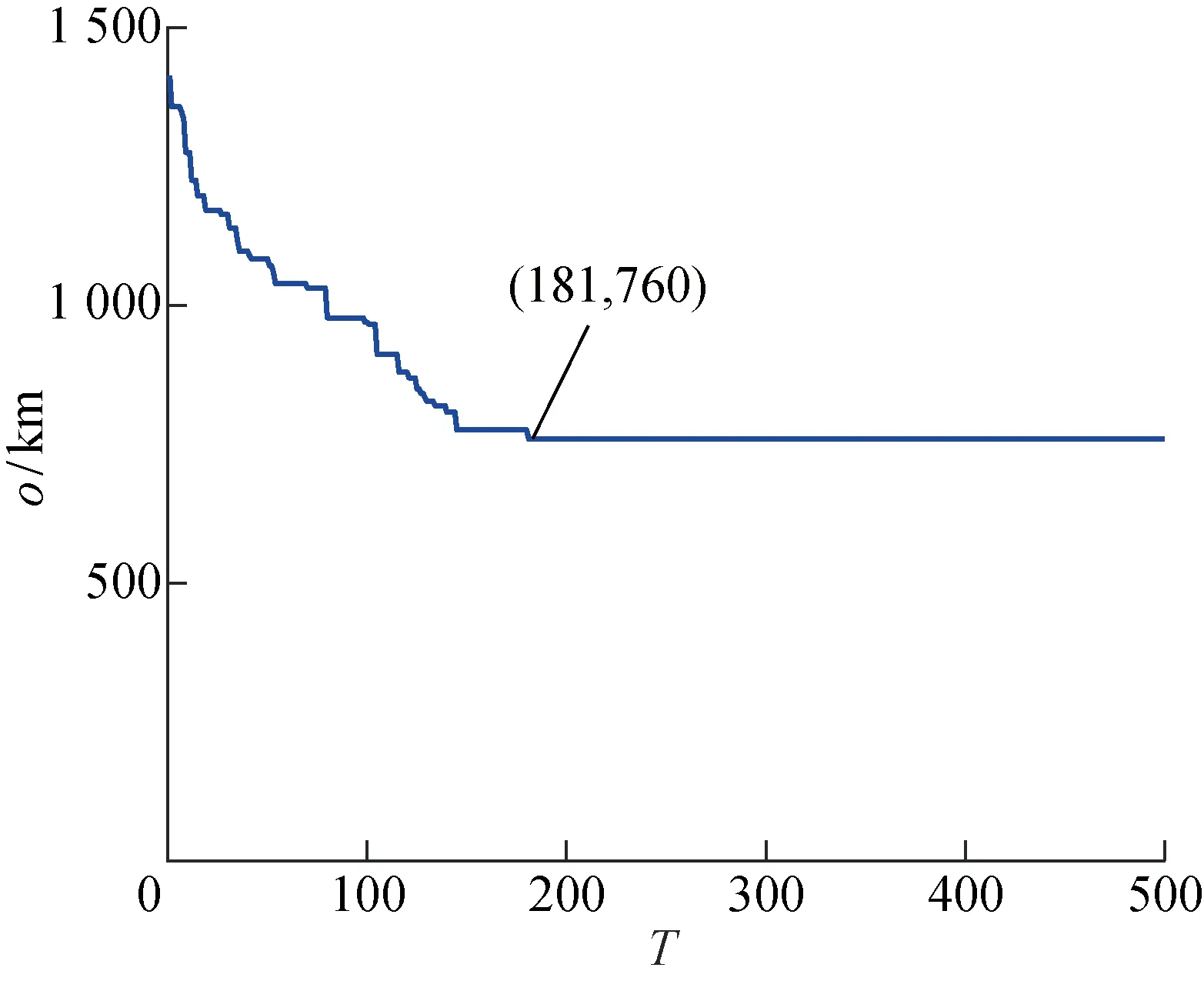
图7 改进遗传算法求解的o随T的变化
同时选取同样的参数,用自适应遗传算法对本文问题进行求解,其求解的最优路径随迭代次数变化情况如图8所示.由图8可以看出,AGA陷入了局部最优,在迭代到188次时,算法达到最优,最优路径长度为 1 454 km,明显大于用所提算法求解的最优路径长度.分别用两种算法对本问题求解10次,其对比结果如表2所示.由表2可知,IGA可以更高效、准确地求解出最优清洁任务顺序.
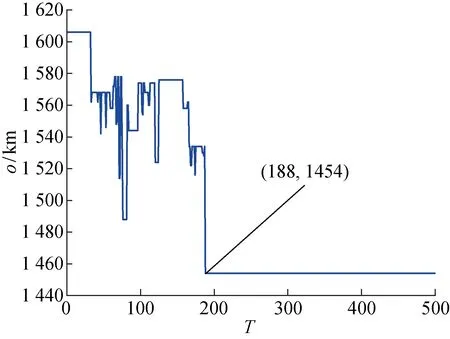
图8 自适应遗传算法求解的o随T的变化
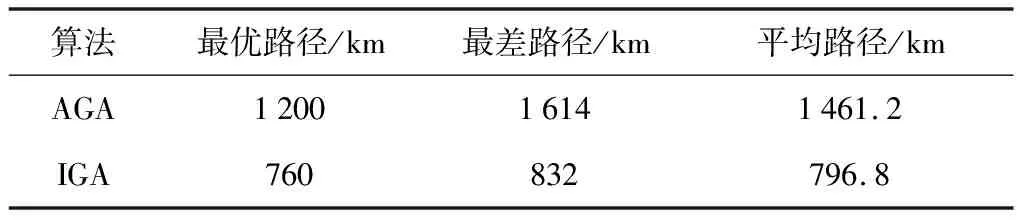
表2 两种算法求解本文问题时的性能比较
4 结语
本文通过对大面积光伏电站清洁任务规划问题的分析,将其转化为TSP问题,并提出IGA对单个清洁机器人的任务规划问题进行求解.通过对适应度函数的动态线性标定,保证了遗传算法的选择功能;采用混合选择算子和基于分段规则的交叉算子,增加了最优个体的产生概率,提高了算法的收敛速度,增强了算法稳定性.与AGA仿真结果的对比可以看出,IGA可以更为快速、准确地规划出机器人清洁光伏电站的任务顺序.分级任务规划为之后清洁机器人进行实际作业时的路径规划提供了理论依据.
