基于集成学习的改进深度嵌入聚类算法
2021-10-12黄宇翔王昌栋赖剑煌
黄宇翔,黄 栋+,王昌栋,赖剑煌
1.华南农业大学 数学与信息学院,广州 510642
2.广州市智慧农业重点实验室,广州 510642
3.中山大学 计算机学院,广州 510006
数据聚类是无监督学习的一个重要问题,其目标在于将一组数据样本划分为若干个簇,以使得同簇样本尽可能相似,异簇样本尽可能不同[1]。传统聚类算法往往以给定的数据特征作为输入,再采用不同模型对其进行划分,但在一些复杂高维数据(例如图像数据、文本数据等)情况下,则可能因缺乏在高维空间对样本相似性的有效度量而难以发现其内在聚类结构,即面临所谓的“维数灾难”(curse of dimensionality)。对于高维数据聚类,常规应对方法包括子空间聚类(subspace clustering)[2]、特征降维(dimension reduction)[3]、特征抽取(feature selection)[4-5]等;近年来,深度学习因其在特征表示上的独特优势,也为高维、复杂数据聚类带来了一个新的解决思路,并已涌现出许多行之有效的深度聚类算法[6-11]。
在初期的深度聚类研究中,Tian 等[6]对自编码器(autoencoder)与谱聚类(spectral clustering)之间的关联进行了分析,提出利用一种稀疏自编码器,以数据样本的相似性矩阵作为训练集,通过深度神经网络(deep neural network,DNN)学习得到低维数据特征,进而使用K均值(K-means)聚类构建聚类结果。Chen[8]利用一个深度置信网络(deep belief network,DBN)进行特征学习,进而使用非参最大间隔聚类(nonparametric maximum margin clustering,NMMC)得到最终聚类。Peng 等[9]结合输入空间的稀疏重构关系,训练一个兼顾数据局部与全局信息的深度神经网络,以学习得到低维数据表示并进行数据聚类。这些方法[6,8-9]将深度聚类过程划分为两个阶段:一是特征表示学习阶段,即以一定的深度神经网络结构来学习得到数据的低维特征表示;二是聚类阶段,即采用传统聚类算法在学习得到的低维特征空间上对数据样本进行划分以得最终聚类。
相比于将表示学习与聚类过程划分为两个不同阶段的做法[6,8-9],Xie 等[12]通过定义一个基于KL 散度(Kullback-Leibler divergence)的聚类损失函数,对深度神经网络的参数和聚类分配进行同时优化,提出了深度嵌入聚类(deep embedding clustering,DEC)算法。DEC 算法为聚类研究提供了一个有力的工具,但是该算法的一个局限性在于超参数λ的调节与优化问题。在DEC算法中,用于控制退火速度(annealing speed)的超参数λ对聚类效果有着较为敏感的影响,其设置往往依赖人工调节;但是,在缺乏先验知识或人工监督的情况下,如何在不同数据集下为其选取合适的超参数值仍是一个有待解决的问题。
针对DEC 算法的超参数敏感问题,本文基于集成聚类(ensemble clustering)的思想对其进行解决。集成聚类是一类重要的无监督集成学习技术,其目标在于融合多个具有多样性的基聚类(base clusterings)以得到一个更优、更鲁棒聚类[13-24]。常规DEC 算法对超参数λ的敏感性,正好可以为集成聚类过程提供其所需的基聚类“多样性”因素。具体地,本文提出一种基于集成学习的改进深度嵌入聚类(improved deep embedding clustering method with ensemble learning,IDECEL)算法;区别于为每一个数据集人工调得一个合适超参数的做法,IDECEL 不寻求超参数的单一最优取值,而是令超参数λ在较大范围内波动以构建一组具有多样性的基聚类集合。进一步,结合熵理论对各个基聚类的簇不确定性进行评估与加权,进而构建基于局部加权的二部图模型并将其高效分割,以进行基聚类融合,并得到最终集成聚类结果(其算法流程如图1 所示)。本文在多个数据集上的实验结果表明,所提出的IDECEL 算法一方面可以有效应对常规DEC 算法的超参数敏感问题,另一方面,即使与DEC 算法在最优超参数下的性能进行对比,仍可表现出更为鲁棒的聚类效果。在后续章节中,将对IDECEL 算法进行具体介绍。
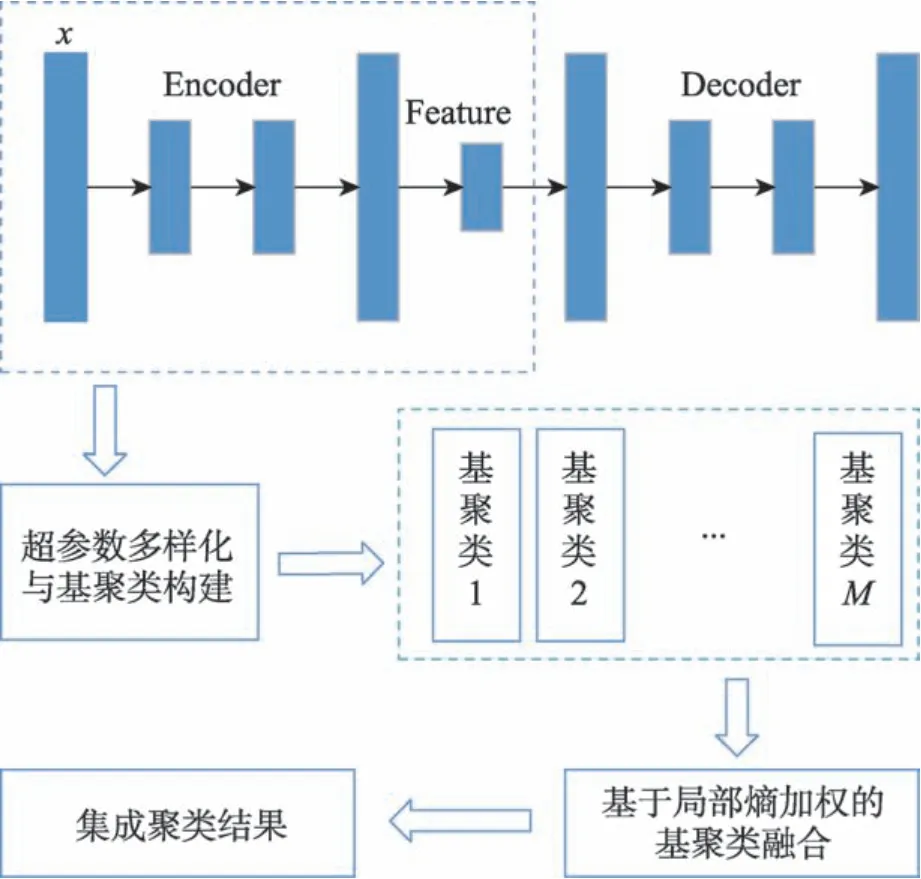
Fig.1 Flowchart of IDECEL图1 IDECEL 算法流程图
1 基于集成学习的改进深度嵌入聚类
1.1 由深度嵌入聚类到多样化基聚类
深度嵌入聚类(DEC)[12]是一个重要的深度聚类算法,该算法主要包括两部分:一是对自动编码器进行参数初始化;二是用KL 散度迭代优化聚类。DEC使用堆叠自编码器(stacked autoencoder,SAE),逐层初始化SAE 网络,每一层都是经过降噪处理的自编码器[25]。自编码器训练好之后,舍弃解码器部分,在编码器后添加聚类模块。为了初始化簇心,DEC 将数据输入到编码器中,输出为嵌入点,然后对这些嵌入点进行标准K均值聚类处理,将聚类结果作为后续聚类用的初始簇心。
对于嵌入点zi=fθ(xi)∈Z和初始簇心,DEC在两个步骤间迭代优化聚类:一是计算嵌入点和簇心之间的软分配;二是更新嵌入点,通过最小化软标签分布和辅助目标分布之间的KL 散度来优化簇心。基于t-SNE 的思想[26],DEC 使用t 分布来估计嵌入点和簇心之间的相似度,也就是软分配,如下:

其中,α是t分布的自由度,在DEC 中,该自由度设置为1。此处qij也可以解释为样本i属于聚类j的可能性。然后,DEC 提出了一个辅助目标分布来衡量样本属于某个聚类的分布:

有了原始分布和辅助分布之后,DEC 通过KL 散度拉近两个分布的距离,其损失函数如下:
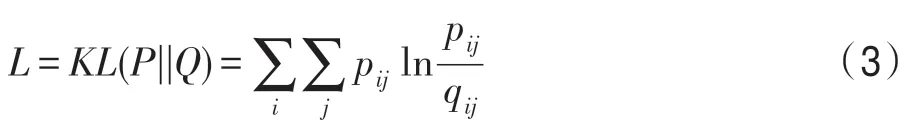
每次迭代需要更新的参数的梯度为:
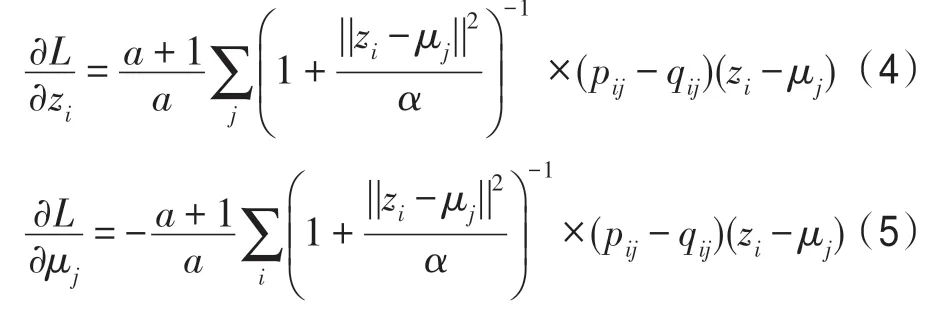
此处,式(4)用于优化编码器的网络参数,式(5)用于优化簇心。在此框架下,DEC 可同时优化网络参数与聚类。
为构建所需的基聚类集合,本文沿用DEC 的网络结构,在优化部分对聚类的簇心和深度网络的参数用梯度下降法进行联合优化。在优化过程中,都在计算辅助目标分布和最小化KL 散度之间迭代;每隔λ次,对软分布和辅助目标分布进行更新。其中,超参数λ对聚类性能有较大影响,但又难以进行估计。对此,本文基于集成聚类的策略,不寻求单一λ值,而是令其在较大范围内活动以构建多样化基聚类。具体地,令λ=2i×10,i=0,1,…,9 以获取10 个不同λ值,在每个λ值下运行M′次以得M′个基聚类结果(需要注意的是,在相同λ值下运行多次的聚类结果也往往不同),从而可得总共M=10M′个差异化的基聚类,表示为:

其中,πm=表示第i个基聚类,表示基聚类πm中的第i个簇,nm表示该基聚类πm中的簇数量。在基聚类集合中,每一个基聚类包含若干个簇,不妨把各个基聚类中所有簇的集合表示为:

其中,Ci表示基聚类集合中的第i个簇,nc表示其全体簇数量。接下来,在此多样化基聚类集合的基础上,下一节将介绍其集成过程。
1.2 局部加权与基聚类集成
对于所构建的基聚类集合,不同基聚类的可靠度可能各不相同;即使同一基聚类内不同簇的可靠度也不一样。为得到更优集成聚类结果,本文采用局部熵加权策略[19]对基聚类集合中的各个簇进行可靠度评估与加权。具体地,借助于熵(entropy)的概念,来对簇的不确定(uncertainty)作度量。给定一个簇Ci,其相对于该基聚类πm的不确定性计算如下[19]:
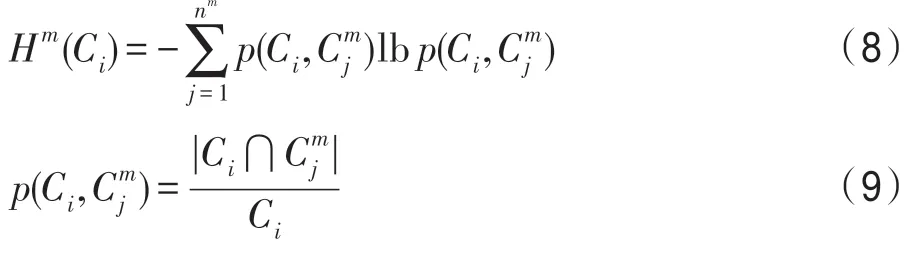
其中,⋂表示两个簇的交集,|Ci|表示簇Ci中样本数量。基于基聚类集合Π中M个基聚类具有相互独立性的假设,簇Ci相对于整个基聚类集合Π的熵(即不确定性)可计算为:

各个簇的不确定性(或不稳定性),可视作与其可靠度呈负相关。在其基础上,计算一个集成驱动的簇指标(ensemble-driven cluster index,ECI)来作为簇可靠性度量,如下:

进一步,以样本集合X与簇集合C的并集作为节点集,以ECI 作为边的权值,构建一个加权二部图(bipartite graph),表示如下:

其中,V=X⋃C表示节点的集合,L表示边的集合。对于节点vi和vj之间的边,其权值定义如下:
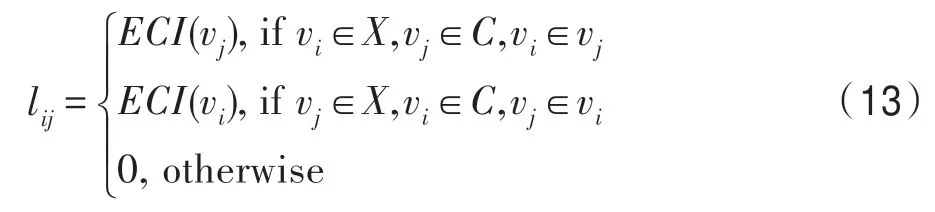
在此二部图中,当且仅当一个节点为数据样本节点,另一个节点为簇节点,且该样本“属于”这个簇时,这两个节点之间存在连接边,且其边的权值取决于这个簇的可靠度,即由其ECI值决定。对此二部图结构,进一步可以通过Tcut算法[27]将其划分为若干个节点子集,并将划为同一子集的样本节点归为同一个簇,从而得到最终的集成聚类结果。
2 实验结果与分析
在本章中,将在5 个数据集上进行实验,并对IDECEL 算法与其他多个深度聚类及集成聚类算法进行对比与分析。
2.1 实验设置
在本文实验中,深度神经网络[12]由完全连接层组成,大小设置为d-500-500-2 000-10,其中d是输入数据的维度。初始化网络权重为零均值高斯分布(标准差为0.01)的随机数;各层的激活函数均为ReLU;minibatch size为256。在最小化KL散度阶段,本文使用SGD 优化器进行优化,其学习率λ=0.01,β=0.9。判断收敛的阈值为tol=0.1% 。对于超参数λ,令λ=2i×10,i=0,1,…,9,获取10 个不同λ值,在每个λ值下生成M'个基聚类,以构建总共M=10M'个差异化的基聚类。在实验中,本文默认使用集成规模M=50(即对应于M'=5)。在第2.5 节中,本文将进一步进行实验,测试所提出算法在不同集成规模下的性能。
2.2 数据集与评价指标
本文实验将在5 个数据集上进行,分别是:MNIST[12]、FMNIST[28]、Reuters10K[12]、Gisette[29]以 及Cifar10[30]。在这些数据集中,Reuters10K 为文本数据集,其余4 个则为图像数据集。各个数据集的具体情况如表1 所示。
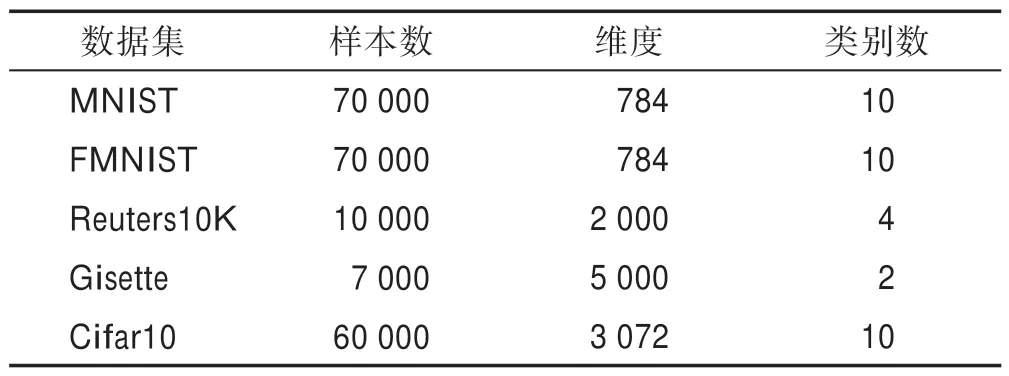
Table 1 Dataset of experiment表1 实验数据集
为对比不同聚类算法的性能,本文采用了三种常用的聚类评价指标,分别是NMI(normalized mutual information)[13]、ARI(adjusted Rand index)[9]以及ACC(accuracy)[9]。在实验对比中,每个聚类算法将分别运行20次,然后取其平均NMI/ARI/ACC得分进行比较。
2.3 与常规DEC 算法在不同超参数下的对比
针对常规DEC 算法[12]的敏感超参数问题,本文提出了IDECEL 算法,以集成学习的策略对其解决。本节实验将对所提出的IDECEL 算法与DEC 算法在不同超参数λ下的性能进行对比(如图2、图3 和图4所示)。需要注意的是,IDECEL 使用多样化超参数以构建一组基聚类集合,并不需要选取单一的超参数值。由图2、图3 与图4 可以看出,本文提出的IDECEL 算法不仅比DEC 算法在不同超参数下的平均NMI、ARI、ACC 得分有显著提升,即使与DEC 在最佳超参数下的性能进行对比,也可以得到更优聚类效果,这也验证了IDECEL 算法在应对敏感超参数、得到更鲁棒聚类方面的有效性。
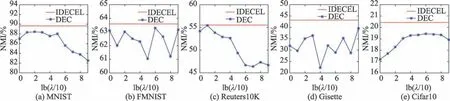
Fig.2 Comparison of NMI scores at different hyperparameters λ图2 在不同超参数λ下的NMI得分对比

Fig.3 Comparison of ARI scores at different hyperparameters λ图3 在不同超参数λ下的ARI得分对比
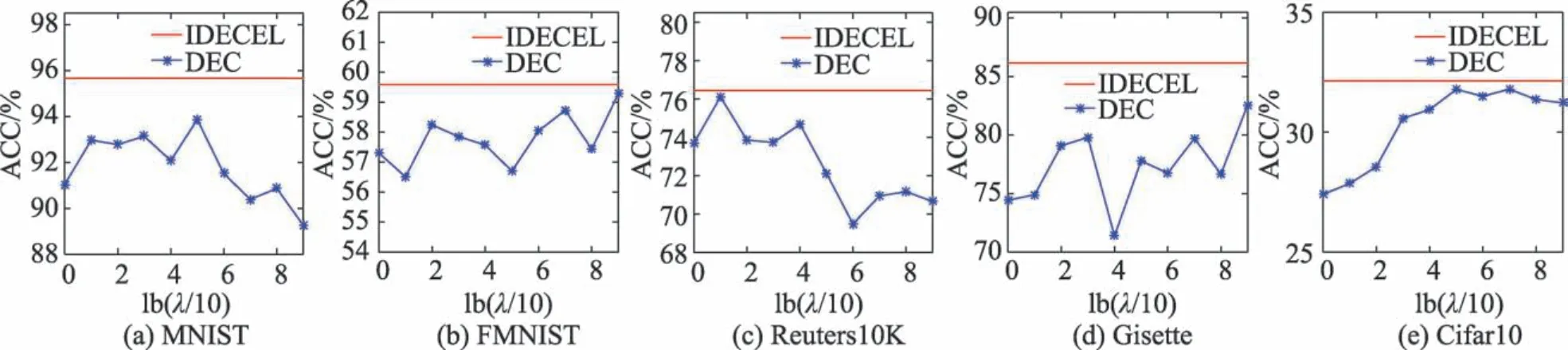
Fig.4 Comparison of ACC scores at different hyperparameters λ图4 在不同超参数λ下的ACC 得分对比
2.4 与其他深度聚类及集成聚类算法的对比
本节实验将所提出的IDECEL 算法与6 个其他聚类算法进行性能对比。这些算法分别是:Kmeans、KCC(K-means-based consensus clustering)[31]、SEC(spectral ensemble clustering)[32]、LWGP(locally weighted graph partitioning)[19]、DEC(deep embedded clustering)[12]以及IDEC(improved deep embedded clustering with local structure preservation)[33]。在这些对比算法中,KCC、SEC 以 及LWGP 是集成聚类算法,DEC 与IDEC 是深度聚类算法。
如表2 所示,本文提出的IDECEL 算法在5 个数据集中均取得了最高的NMI 得分。值得一提的是,在本文实验中,对每一个数据集,DEC 算法的超参数λ均由人工调至最优,而IDECEL 算法则无需针对数据集进行调参(dataset-specific tuning);即便如此,IDECEL 算法也仍能够在这些数据集上取得与DEC(在最优超参数下)相当或更高的NMI 得分。与此同时,表3 及表4 的ARI 及ACC 得分对比也同样显示出本文IDECEL 算法在各个数据集上的显著优势(表2~表4 中最高分以粗体表示)。

Table 2 NMI scores of different clustering algorithms表2 不同聚类算法的NMI得分对比
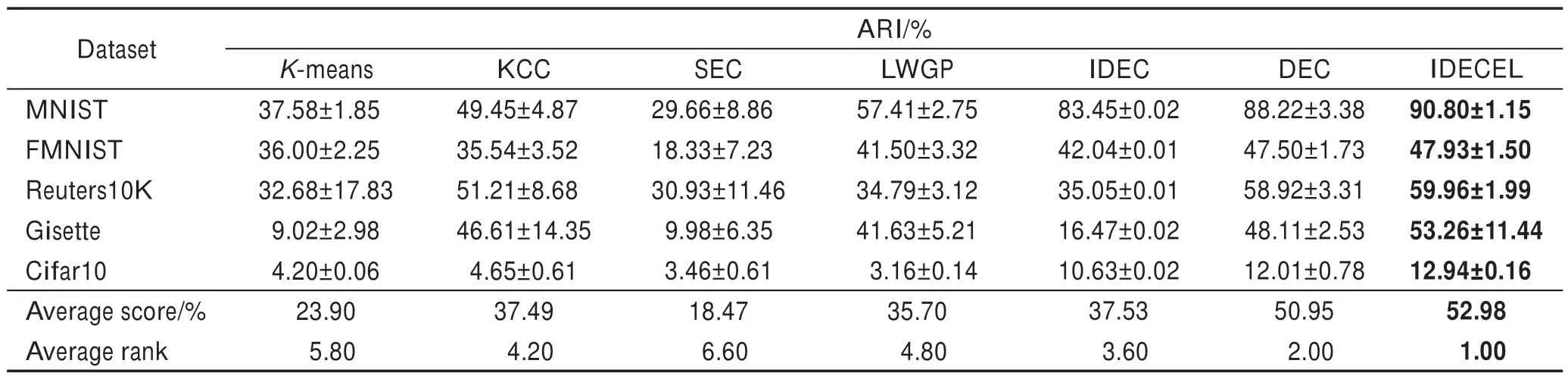
Table 3 ARI scores of different clustering algorithms表3 不同聚类算法的ARI得分对比

Table 4 ACC scores of different clustering algorithms表4 不同聚类算法的ACC 得分对比
进一步,本文在表2~表4 的末两行给出了各个算法的平均得分(average score)和平均排名(average rank)信息。平均得分表示每个算法在5 个数据集上的平均NMI/ARI/ACC 得分;平均排名则表示在一个表格的得分结果之中,每个算法在多个数据集中排名的平均情况。如表2 所示,所提出的IDECEL 算法在5 个数据集中均取得最高NMI 得分,平均排名为1;在5 个数据集中的平均NMI 得分为54.49,高于DEC(在最优超参数下)的平均得分,也高于其他5个聚类算法的平均得分。在表3 及表4 的ARI 及ACC 得分中,IDECEL 算法也表现出其在平均得分与平均排名上的优势。
2.5 集成规模对性能的影响
在本节实验中,将测试本文算法以及3 个其他集成聚类算法在不同集成规模下的性能对比。
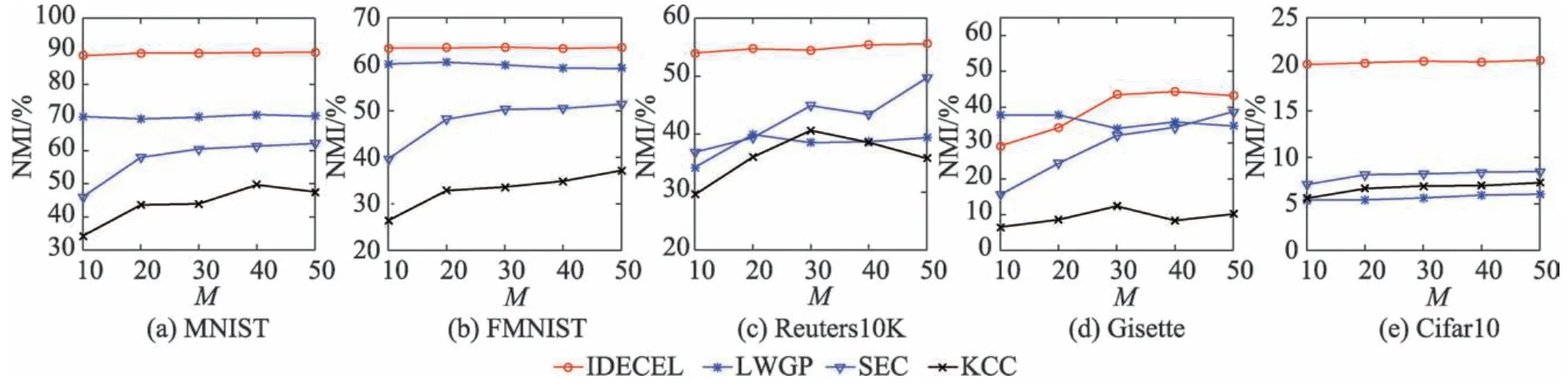
Fig.5 Performance of different ensemble clustering algorithms at varying ensemble sizes(NMI)图5 各集成聚类算法在不同集成规模下的性能表现(NMI)
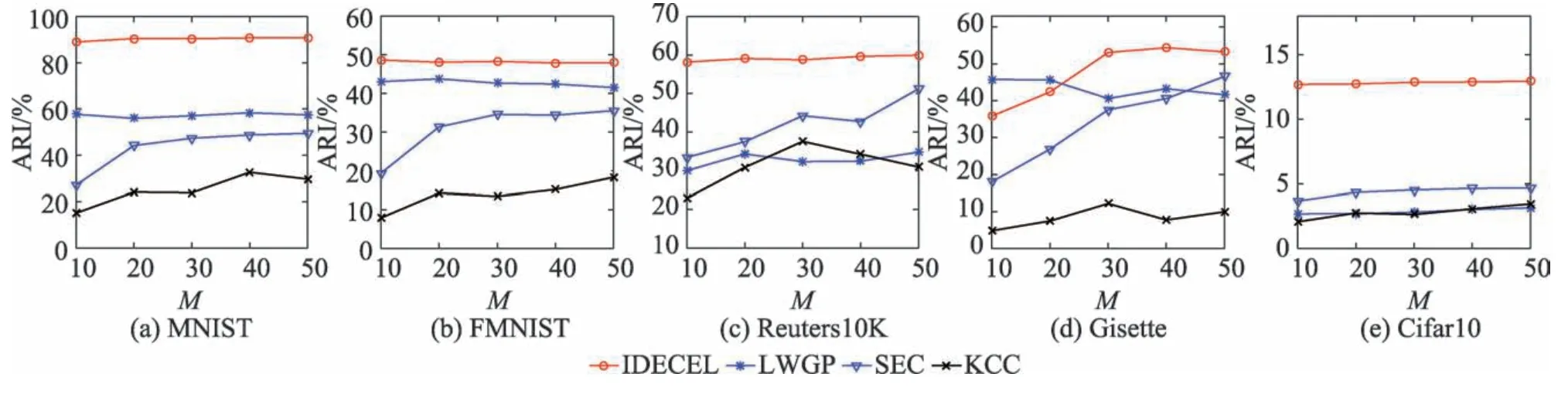
Fig.6 Performance of different ensemble clustering algorithms at varying ensemble sizes(ARI)图6 各集成聚类算法在不同集成规模下的性能表现(ARI)

Fig.7 Performance of different ensemble clustering algorithms at varying ensemble sizes(ACC)图7 各集成聚类算法在不同集成规模下的性能表现(ACC)
在集成聚类中,集成规模M表示基聚类集合中的成员个数。图5~图7 分别给出了各个集成聚类算法在不同集成规模下的NMI、ARI 和ACC 得分。如图所示,当集成规模增加时,各个集成聚类算法的性能往往随之提升;而本文所提出的IDECEL 算法在不同集成规模下表现出相当稳定的聚类效果。在Gisette 数据集中,虽然LWGP 算法在集成规模较小时得分高于IDECEL,但是在集成规模增长到大于20之后,IDECEL 性能则持续优于LWGP。除Gisette 数据集之外,IDECEL 算法在其他4 个数据集上的性能得分均始终优于其他对比算法,其中IDECEL 算法在MNIST 和Cifar10 数据集上的优势尤为明显(如图5~图7 所示)。
3 结束语
本文针对常规DEC算法的敏感超参数问题,提出一种基于集成学习的改进深度嵌入聚类(IDECEL)算法。相比于人工调参以寻求单个最优超参数λ的常规做法,本文利用多样化超参数λ以构建一组具有差异性的基聚类,进而基于熵理论对基聚类的局部不确定性进行度量,然后结合二部图构建与分割策略将多个基聚类融合为一个更优聚类结果。本文在5 个数据集上进行了实验,实验结果验证了本文算法相比于其他深度聚类和集成聚类算法的性能优势。本文的集成策略不仅可用于改进DEC 算法,未来也可推广至其他包含敏感超参数的深度或非深度聚类算法,以超参数多样化再聚类融合的方式缓解其敏感超参数问题,由此提升相关算法的聚类鲁棒性。
