关键节点选择的快速图聚类算法
2021-10-12尤坊州
尤坊州,白 亮
1.山西大学 计算机与信息技术学院,太原 030006
2.山西大学 计算机智能与中文信息处理教育部重点实验室,太原 030006
聚类[1-3]是依据特定标准将一个数据集分成不同的类或簇,使得类内相似性尽可能高,类间相似性尽可能低。聚类技术在各行各业中得到广泛应用,各种聚类方法也被不断提出和改进,不同的方法适合于不同类型的数据,例如基于连通性的聚类算法[4]、基于中心的聚类算法[5]、基于密度的聚类算法[6]等。其中,谱聚类作为一种极具竞争力的图聚类算法,由于其能够有效地识别数据的复杂类结构,已成功应用在不同的领域,如搜索引擎[7]、推荐系统[8]、图像分割[9]、语音识别[10]等。但是谱聚类的特征求解需要极高的时间复杂度,因而它并不适合应用于大规模数据集。近年来,随着信息化时代的发展,数据规模呈几何级数高速增长,如何将谱聚类方法应用于大规模数据集已成为了一个重要的研究内容。
为了提高谱聚类在大规模数据集上的聚类效果,许多加速方法被发展。它们主要从以下两方面加速聚类算法:(1)降低特征分解的时间复杂度。2001 年Dhillon[11]证明用奇异值分解(singular value decomposition,SVD)特定矩阵代替谱聚类最小化Ncut的目标函数的方法可行。2004 年Fowlkes 等人[12]提出Nyström 方法,该方法从给定的数据成对相似性矩阵中计算出一个样例成对矩阵的特征向量,并利用它估计原始矩阵特征向量的近似值,以提高求解特征值与特征向量的速度。2017 年Nie 等人[13]提出用于学习具有完全k(其中k为簇数)个连通分量的二部图的方法,在模型中学习的新二部图近似原始图,但保留了显式的簇结构,从中可以立即获得聚类结果,而无需进行后续处理。(2)选取关键节点实现数据压缩。2008 年Shinnou 和Sasaki[14]将K-means 聚类应用于大规模的数据集,删除那些靠近聚类中心(关键节点)的数据点(设置距离阈值),对剩余的数据点以及聚类中心(关键节点)进行谱聚类,那些被删除的数据点跟随自己相对应的聚类中心(关键节点)被分配到相应的集群中。2009 年Yan 等人[15]提出基于Kmeans 近似的谱聚类方法,首先对数据进行K-means聚类,再对得到的聚类中心(关键节点)进行谱聚类,其他数据点跟随自己相对应的聚类中心(关键节点)被分配到相应的集群中。2015 年Chen 和Cai[16]对随机选择的关键节点与原有数据进行重新编码,对编码之后的新数据进行奇异值分解(SVD)。2013 年Liu 等人[17]在Chen 和Cai[16]研究的基础上进一步提出一种重新编码的方法,使得提取出的关键节点更具有代表性。2020 年Huang 等人[18]提出用随机选择与K-means 选择相结合的方式选取关键节点。2019 年Lee 等人[19]提出为每一个点用图卷积定义自注意力分数,自注意力分数越高的节点越具有代表性。
虽然在大规模数据集上的谱聚类已经取得了一定的研究成果,但还是存在两个问题:(1)所选取的关键节点大多通过随机选择或K-means 聚类得到,无法保证被选出的关键节点可以很好地代表原有数据,从而影响之后的聚类结果;(2)在用不同方法进行特征分解的近似时,虽然降低了计算的时间复杂度,但受初始选点的影响,聚类结果稳定性差,算法鲁棒性不高。
基于此,本文对大规模数据集下的谱聚类算法进行改进,创新之处如下:
(1)从关键节点的局部代表性和关键节点之间的差异性两方面考虑,给出一种新的快速关键节点选择方法。
(2)通过对多次近似特征求解结果进行聚类集成,提高聚类结果的鲁棒性。
1 谱聚类算法的简介
2000 年,Shi 和Malik[9]首次提出基于Normalized cut 准则的谱聚类算法。与传统的聚类方法相比,谱聚类收敛于全局最优解且聚类效果好。本文用G=(V,E)表示图,其中V表示顶点集,E表示边集,给定包含n个节点的数据集,xi对应顶点集V中的每个数据点。谱聚类构造矩阵W={wi,j}i,j=1,2,…,n用于揭示数据点之间的相似性关系,对矩阵W求行和(或列和)得到度矩阵D∈Rn×n,由如下定义,得到Laplacian 矩阵:

其中,通过高斯核计算W:

其中,σ是核参数,一般情况下被设置为数据的方差。谱聚类的实质是将聚类问题转换为图分割问题,其目的为最小化如下目标函数:

其中,A1,A2,…,Ak为被分割的多个不相交子集。但是人们无法直接对上述目标函数求最优解,因此利用Laplacian 矩阵,将目标函数转换为:
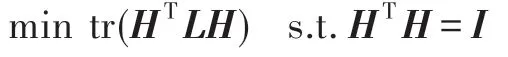
其中,H=[h1,h2,…,hk]为指示向量。谱聚类求解Laplacian 矩阵的前k个特征向量,最终通过K-means算法得到聚类结果。由于谱聚类中需要求解特征向量,其时间复杂度高达O(n3),并不适合应用在大规模数据集上做聚类运算。
2 大规模数据的快速图聚类算法
为解决大规模数据的聚类问题,本文提出基于关键节点选择的快速图聚类算法。算法的总框架包含以下三个主要步骤:(1)选择关键节点形成关键节点与原始数据之间的相似性矩阵W;(2)构建二分图,通过奇异值分解获得数据的近似特征向量;(3)对多次近似特征向量进行集成。接下来,本文将分别对它们进行详细介绍。
2.1 关键节点的选择
对于大规模数据,在进行谱聚类时由于其数据量大,导致在进行特征值与特征向量计算时时间复杂度较高。因此,本文提出一种关键节点的选择方法。通过此方法,本文对数据进行筛选,从中选出最具代表性的节点,构成新的邻接矩阵,再对其进行特征值与特征向量的计算,从而降低时间复杂度。接下来,首先给出关键节点的评价指标的相关定义。
定义1关键节点代表性的评价指标LD定义如下:
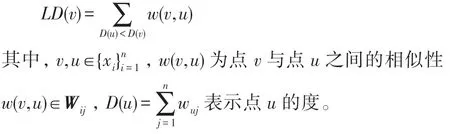
节点的LD代表了它在其所属类中与比自己度小的节点的相似性总和。某点的LD值越高,则表明以它为中心的局部密度越稠密,其所能够代表的节点越多。LD定义了关键节点的局部重要性,但若只考虑关键节点的局部重要性有可能导致被选出的节点均来自于同一类中。为了使得被选取出的节点可以代表不同的类,除了要考虑关键节点的局部重要性外,还应考虑关键节点之间的差异性。为解决差异性问题,本文首先将数据以K-means 聚类方法初始划分为d类,然后在每一类中通过比较LD的值选出一个关键节点,共计d个关键节点。为解释上述计算过程,本文以图1 为例进行阐述。如图1 所示,给定的数据关系图中包含19 个节点,通过K-means 聚类方法被划分为3 个集群。以第一个集群为例解释LD计算方法,集群1 包含6 个点(V1~V6)。如图2 所示,计算每个点的LD值,并从大到小进行排序。通过此方法,在其他集群中根据LD的值对节点进行排序,依次选出每一个集群中的关键节点、次关键节点等,如图3 所示。

Fig.1 Corresponding initial partition obtained by K-means clustering method图1 由K-means聚类方法得到相应初始划分
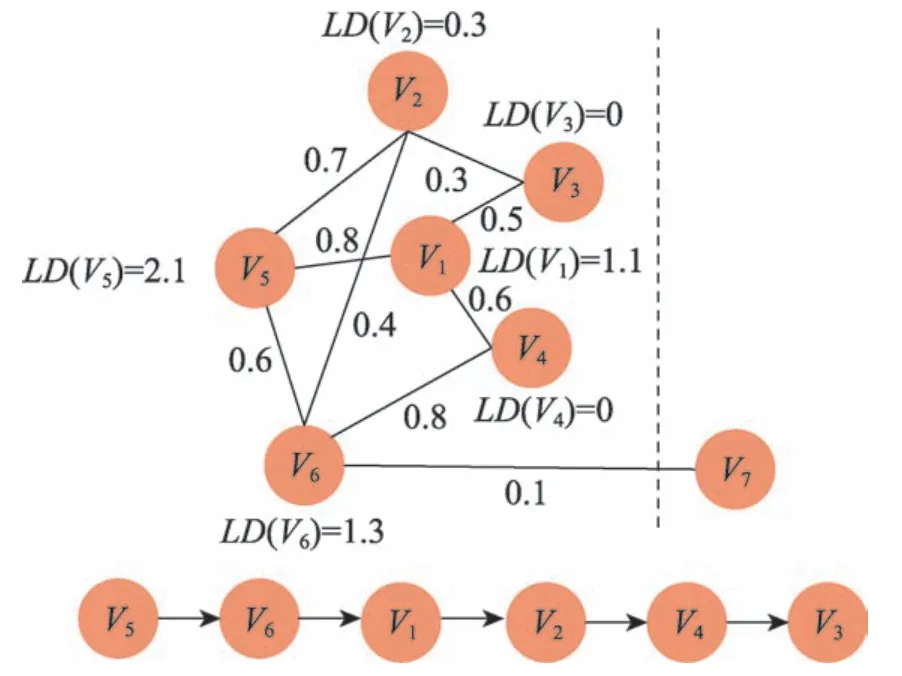
Fig.2 Sorting nodes in cluster 1 according to LD value图2 根据LD 值在集群1 中对节点进行排序
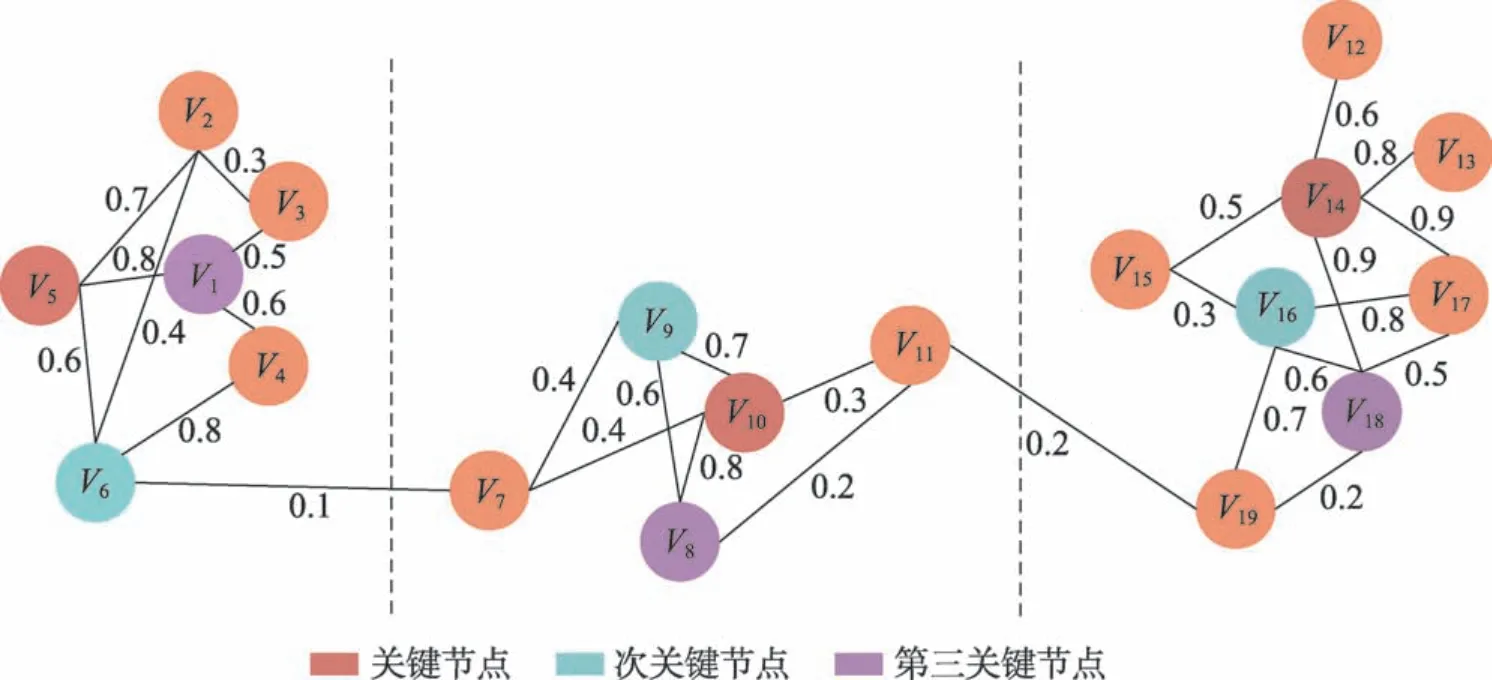
Fig.3 Key nodes selected in turn in each cluster图3 在每个集群中依次选出的关键节点
为增加聚类效果的稳定性以及算法的鲁棒性,需要对由奇异值分解而来的多个近似特征向量进行集成,因此在选择关键节点后,需要形成多个相似性矩阵。将从每一类中选出的LD值最高的关键节点形成相似性矩阵W1∈Rd×n(在本例中,选择V5、V10、V14构成相似性矩阵W1∈R3×19),再从每一类中选出LD值次高的关键节点,形成相似性矩阵W2∈Rd×n(在本例中,选择V6、V9、V16构成相似性矩阵W2∈R3×19)。以此类推。
2.2 二部图划分
由关键节点的选择,得到可以揭示d个关键节点与n个原数据之间关系的相似性矩阵Wi∈Rd×n。进而形成关键节点与原有数据的二部图[20]B=(X,Y,E),如图4 所示,其中X代表原始节点集,Y代表关键节点集,E为X与Y之间的边集。对于给定的二部图B,文献[17]中提出奇异值分解SVD 方法:根据谱图理论,对二部图归一化分割,可以同时划分原数据与关键节点。用奇异值分解代替特征分解以减小时间复杂度。为了划分二部图,可以将优化任务形式化为广义特征值问题。将记为
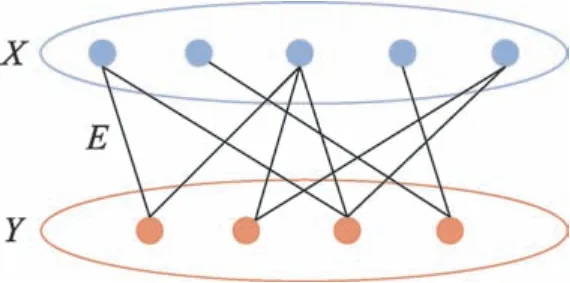
Fig.4 Illustration of bipartite graph图4 二部图示意

其中,Di1和Di2分别为Wi的列和与行和。由归一化矩阵的奇异值分解SVD 得到:
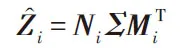
其中,Σ=Diag(σ1,σ2,…,σd),Ni∈Rd×d,Mi∈Rn×d分别为左右奇异值向量。易证得,Mi的列向量为的特征向量,Ni的列向量为的特征向量。得到如下:

由不同的矩阵Wi通过奇异值分解依次获得不同的矩阵Mi。
2.3 多近似特征矩阵集成
由于矩阵W的形成具有一定的不确定性,会受到初始K-means 聚类划分的影响,且形成的不同矩阵W之间具有差异性,满足聚类集成对于基聚类的要求。由矩阵W通过奇异值分解操作得到矩阵U,对矩阵U采用聚类集成操作以解决聚类结果不稳定的问题。
定义2对奇异值分解后的t个矩阵U1,U2,…,Ut进行融合,记作:
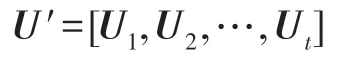
基于U′,本文将利用K-means 聚类算法完成集成任务,集成的优化目标如下:
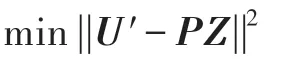
其中,P为最终的n×k划分矩阵,Z为K-means 的k×kt类中心矩阵。总的集成过程如图5 所示。
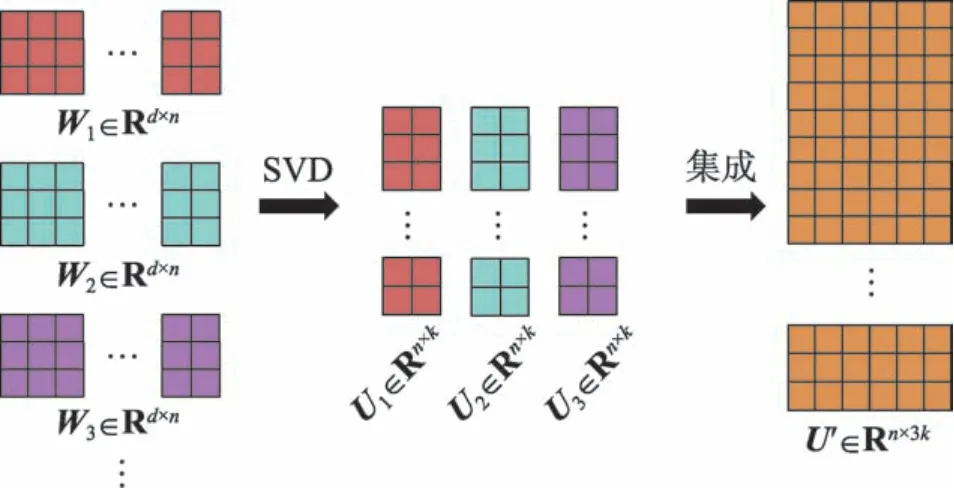
Fig.5 Example of ensemble process图5 集成流程示例
2.4 快速图聚类算法总流程
融合上述三个步骤,一个基于关键节点选择的快速图聚类算法(fast graph clustering algorithm based on key node selection)被提出,简称为KNS 算法,其总流程描述如下。
算法1KNS 算法描述
输入:n个数据点,首次聚类簇数d,最终聚类簇数k,集成组数t。
输出:k簇聚类结果。


在时间复杂度方面,由于数据集规模较大,近似K-means 算法时间复杂度为O(n),计算相似性矩阵与排序的时间复杂度为O(2n2),得到的时间复杂度为O(nd),得到的时间复杂度为O(d3),得到M1的时间复杂度为O(ndk)。由于n≫k且n≫d,执行t次后本文算法总时间复杂度近似为O(t(n+2n2))。
3 实验分析
3.1 实验数据
为验证本文算法的有效性,从https://cs.nyu.edu/~roweis/data.html 中选取了5 个Benchmark 数据集,数据集的简要描述如下:
(1)Digits:手写数字数据集,包含5 620 个数据点、64 个特征和10 类,每个数据是一个数字的8×8 图像的像素值。
(2)Pen:手写数字数据集,包含10 992 个数据点、16 个特征和10 类,分别来自44 个作者的250 个样本,使用每个数字的抽样协调信息。
(3)Statlog:地球资源卫星多光谱数据集,包含6 435 个数据点、36 个特征和6 类,其数据为3×3 的街区在卫星图像上的像素值。
(4)MNIST:包含10 000 个数据点、256 个特征和10 类,来自Yann LeCun 页面的手写数字,数字进行标准化并集中在固定大小的图像中,每个图像表示为一个784 维的向量。
(5)Letters:英文字母表中26 个大写字母的数据集,包含20 000 个数据点、16 个特征和26 类。
3.2 评价指标
本文使用标准互信息(normalized mutual information,NMI)[21]和调整兰德系数(adjusted Rand index,ARI)[22]来评价最终聚类质量,可以比较客观地评价出划分与标准划分之间相比的准确度,并比较不同算法完成聚类的用时。
3.3 实验结果分析
为了测试新算法的有效性,使用该算法与经典谱聚类算法SC(original spectral clustering)[9]和若干个改进谱聚类算法进行了比较分析。改进算法包括CSC 算法(construction of committee based spectral clustering)[14]、Nyström 算法(Nyström spectral clustering)[12]、LSC 算法(landmark based spectral clustering)[16]、SNC算法(scalable normalized cut)[23]、FastESC 算法(fast explicit spectral clustering)[24]、EulerSC 算法(Euler spectral clustering)[25]。在比较过程中,本文设置聚类簇数k为数据集真实的簇个数,选择高斯函数为核函数计算图的相似性矩阵,其核参数被设置为0.095,首次聚类簇数d为最终聚类簇数k+1。为了使得比较在同一环境上,在每一个算法中使用相同的核参数。对于KNS 算法,设置t的值为3。
同时为对KNS 算法中多近似特征矩阵集成的效果进行评价,设置对比实验,比较无集成操作的KNS算法(fast graph clustering algorithm based on key node selection without ensemble,NE-KNS,即在KNS 算法中设置t的值为1)与其他算法在5 个数据集下的聚类结果。
使用上述9 种算法得到聚类结果后,应用NMI和ARI 这两种评价指标对上述聚类结果进行评价,实验结果如表1、表2 所示,并比较各算法用时,实验结果如表3 所示。其中由于NE-KNS 算法为KNS 算法的一部分,用时均少于KNS 算法,但其聚类效果并不为最佳,故不具有比较意义,没有列出。
表1 和表2 展示了不同算法在5 个Benchmark 数据集上的聚类效果,结合表3 所展示的不同算法的聚类用时发现,在多数数据集上,比如Digits、Statlog、MNIST 数据集,本文算法聚类效果更好,更接近于真实划分。多近似特征矩阵集成的应用,使得聚类结果更加稳定,聚类效果更好。并且在全部数据集下,本文的聚类用时对比其他比较算法有大幅度的缩短,尤其是在Pen、Letters 数据集下,耗时仅为最长用时的1.35%,这就证明了本文算法在提高聚类效果的同时极大缩短了聚类用时,使得大规模数据集下的聚类更具有可行性。虽然在一部分情况下聚类精度并未达到最好,但也证明了新算法具有的优势。综上所述,本文提出的基于关键节点选择的快速图聚类算法较其他算法有更好的聚类结果,用时大幅度缩短,因此本文算法对于大规模数据集来说有更好的适用性。

Table 1 Comparison of NMI of different algorithms表1 不同算法的NMI值比较

Table 2 Comparison of ARI of different algorithms表2 不同算法的ARI值比较

Table 3 Comparison of clustering time of different algorithms表3 不同算法的聚类用时比较 s
4 结束语
本文针对谱聚类算法的高计算成本问题,提出一种新的快速图聚类算法。该算法通过选出具有代表性的关键节点代表原数据,获得数据的近似特征向量,并通过聚类集成实现多近似结果的融合,提高了图聚类的鲁棒性。在不同的数据集上的实验结果表明,该算法在NMI 和ARI 两个评价指标上的效果都有提高,且用时短,证实了该算法的有效性,提高了谱聚类算法在大数据集上的规模适应性。
虽然本文算法在降低谱聚类的时间复杂度和缩短聚类用时方面取得一定进步,但是在关键节点的选择方面仍存在部分所选关键节点代表性差的问题。在今后的工作中,会将工作重点放在如何更准确地选择出关键节点方面,希望结合神经网络等方法找出关键节点,将大规模数据集通过分步依次压缩为具有代表性的小数据集,进一步实现准确的数据压缩。
