基于城市计算的分布式异常数据分级过滤算法
2021-10-11王誓伟徐晓斌梁中军
王誓伟,徐晓斌,梁中军
(1.北京工业大学 未来网络科技创新中心,北京 100124;2.国家气象信息中心 北京 100081)
0 引言
城市计算是计算机科学中以城市为背景,与城市规划、交通、能源、环境、社会学和经济等学科融合的领域,通过不断获取、整合和分析城市中多种异构大数据来解决城市所面临的挑战[1]。文献[1-2]阐述了物联网在城市交通、环境监测等多个领域的广泛应用,同时也指出了在数据采集过程中,存在着设备类型繁多、设备所处物理环境恶劣、数据传输渠道复杂的问题。文献[3]讨论了传感器网络中广泛存在的安全问题,传感器网络一般不具备特殊的物理保护,使得大部分密钥管理方案或协议不能被嫁接到传感器网络中,开发新的安全解决方案需要时间,为攻击者向网络中注入虚假数据提供了可乘之机。另外,即使是在无人为破坏的情况下,物联网设备数据传输的过程中,也会面临数据异常的问题[4-5]。这些虚假或异常的数据一方面会严重影响采集数据的质量,导致数据分析系统分析不准确,进而导致决策失误。另一方面,它们会占用城市计算宝贵的网络和计算资源,严重影响城市计算系统的效率。因此城市数据安全已经成为了城市计算中的一个重要命题[6]。
城市计算的能力是宝贵有限的,因此对其进行合理的资源分配显得尤为重要,移动边缘计算将云计算中心的功能下沉到边缘云,使得云计算中心更靠近资源需求方,在面对数据吞吐量较大的场景,使用分布式的处理方法可以有效地降低网络整体的传输延迟,提高系统的处理效率[7-8]。
目前城市异常数据处理在城市计算的很多方面都有了广泛的应用:文献[9]对纽约市1.6亿条出租车出行记录进行异常数据分析;文献[10]对大规模交通数据进行异常数据检测;文献[11]在无线传感器网络中对异常数据进行监测,文献[9-10]探索了关于城市单一应用的异常数据处理问题;文献[11]探索了在局部传感器网络中异常数据处理问题。但是单一应用场景数据解决方案可能会依赖于应用数据的独特特性,导致方法不具有通用性。同时,局部网络中的异常数据解决方法也无法满足城市规模级的“多数据,多任务”的场景,因此本文提出一种面向城市级的异构数据分布式异常过滤算法。
本文面向应用层,设计了一种适用于异构数据的提取协议,在该协议中,每一个数据源设备都将所有数据同时发送到网络中,不同的应用根据实际需要,通过设定偏移字段的数值,得到所需类型数据,实现异构数据的快速获取;基于移动边缘计算架构,设计了一种分布式的异常数据分级过滤算法,使用模糊集合对每类数据进行表示,计算出异常数据的隶属函数;单个节点通过设定可疑数据与异常数据阈值,过滤掉异常数据,并标记可疑数据;应用收到多个节点的数据后,基于多个节点的数据对可疑数据进一步分析,过滤掉异常数据。
1 相关工作
异常过滤算法的重点是实现对异常点的识别。关于识别异常点,文献[12]建立了属性的特征空间,通过计算数据点的离群距离来判断数据点的异常程度。该方法具有良好的检测效果和广泛的适用性,但该算法时间复杂度过高,实时识别能力较弱,且不能满足实时分布式场景的需要。文献[13-14]提出一种在动态混合属性数据集中进行分布式离群值检测的可调算法。文献[15-16]通过密度聚类的方法对异常点进行捕获,但基于聚类的方法会局限于聚类簇的选择和个数,另外,聚类模型也只适用于特定的数据类型。文献[17]提出一种基于高斯统计的异常点识别算法,但是只基于统计的方法,过度依赖于先验知识,不能很好地处理未先验的情况。
为解决上述问题,并考虑到数据具有时空相关性,提出一种部署于感知节点之上,基于高斯隶属度的分布式异常过滤的算法。该算法通过对数据隶属度和数据差值变化隶属度进行分析,共同初步过滤异常无效的信息。同时,利用移动边缘计算,联合多节点对异常数据作进一步的过滤运算,从更高维的层面分析数据异常问题,进一步提高过滤水平。结合提出的过滤算法,设计了一种匹配的城市数据类型的数据提取协议。
2 面向城市计算的异构数据提取协议
在智慧城市中存在着各式各样的数据类型,由于不同的数据类型具有不同的数据结构,数据处理分析系统针对不同的数据结构进行数据提取的过程中,会严重降低系统的性能。因此,本文设计了一种通用的异构数据提取协议,并基于这种协议,定义了一种新的数据包数据结构,通过引入编解码器将数据中心数据预处理及数据提取的过程下放到边缘计算中,以降低云数据中心的数据处理负担,提高数据中心数据分析的性能和效率。
2.1 城市计算中的异构数据定义
在城市计算中,终端设备及其获取到的数据类型繁多,因此可以对传输报文进行统一制定,以减少系统处理识别的压力。
假设城市计算中可能包含的数据类型有n类,则每种设备可以获取其中的m(m≤n)类数据,因此,城市数据所具有的种类数量的信息熵即为所需要的数据类型编码的长度。
本文使用定长编码的方式对n种数据类型进行编码,根据定义1求得编码长度L。从二进制数字0开始以自增的形式与城市数据类型一一对应起来,对每一种数据类型形成独有ID编码。
定义1城市数据所具有的种类数量的信息熵:
L=log2n。
(1)
对于数据内容,由于城市数据内容长度不一,因此本文采用硬编码的方式,在感知节点对每类数据直接设定好数据长度。
2.2 数据包结构
数据包内容如表1所示,其中数据类型ID,数据内容是需要匹配加进数据包的。数据包生成后将以二进制流的方式上传。

表 1 数据包字段
2.3 数据提取方法
城市计算中可能有很多种应用,每类应用都需要若干种数据。每个应用需要记录数据源的设备ID,以及该设备ID下每一个数据类型内的数据内容。
数据提取过程如图1所示。编解码器(codecs)提供了对数据流的转换和分析能力,编解码器使用数据切片的方式对数据流进行分析,将异构数据流分解为多类数据片段,从而提取其中的城市数据信息。

3 异常数据过滤算法
在过滤大规模城市数据的过程中,需要每一个终端设备都具有初步独立过滤数据的能力。为解决终端设备独立过滤的问题,本文提出基于高斯隶属分析的数据过滤方案。本算法通过计算城市数据的高斯隶属度和数据差值变化高斯隶属度,联合考虑以求得数据的联合隶属度。数据高斯隶属度从数据分布的角度描述了数据对应于整体的隶属程度,数据差值变化高斯隶属度从数据差值变化分布的角度探讨了连续数据在数据变化时的可能性。数据的联合隶属度反映了其对于整体数据的可信关系、隶属关系。隶属度越高,则数据可信度越高。同时,本文又结合数据具有时空相关性提出了基于移动边缘云的异常数据过滤,进一步提高了数据挖掘分析的能力。
3.1 单节点异常数据隶属度分析
在实际应用中许多物理量的概率分布都可以使用高斯分布或近似高斯分布进行描述[17],城市物理数据也不例外。根据概率学原理,高斯分布的描述如定义2所示。
定义2如果随机变量X的概率密度函数为:
(2)
式中:u和σ为常数,σ>0,则X服从高斯分布,记X~N(u,σ2),称X为正态随机变量。
对于满足X~N(u,σ2)的城市数据,可以先对城市数据进行预处理,计算出其整体的数据分布概率密度函数P(x),并根据定义3求出其数据高斯隶属度Y(x)。
定义3该定义描述了从概率密度函数到数据高斯隶属度的映射关系:
(3)
式中:P(x)是城市数据所对应的高斯分布的概率密度函数,σ是其对应高斯分布的方差。在定义中,数据值如果偏离历史分布太远,就会导致其获得较小的数据高斯隶属度。
类似地,根据数据变化的差值,也可以建立起数据差值变化的高斯分布,从而得到数据差值高斯隶属度D(x)。
数据的联合隶属度为A(x),A(x)=Y(x)×D(x),A(x)∈[0,1]。对于数据的联合隶属度,可以通过定义异常隶属度门限Tat,可疑隶属度门限Tst,对数据进行进一步地区分、标记、过滤。对于A(x)∈[0,Tat)的数据将它标记为异常数据,实行过滤,对于A(x)∈[Tat,Tst)的数据将它标记为可疑数据;对于A(x)∈[Tst,1]的数据将它标记为合理数据。
数据过滤流程如图2所示,数据通过过滤器后,被区分为异常数据、可疑数据、合理数据。上传可疑数据和合理数据,在本地直接过滤掉异常数据。
3.2 基于移动边缘云的异常数据过滤
基于高斯隶属度的过滤算法,只能很好地解决在正常数据范围的数据过滤问题。但如果出现特殊情况,移动边缘计算可以帮助城市计算从更高维度的角度考虑数据异常的问题,应用场景如图2所示。
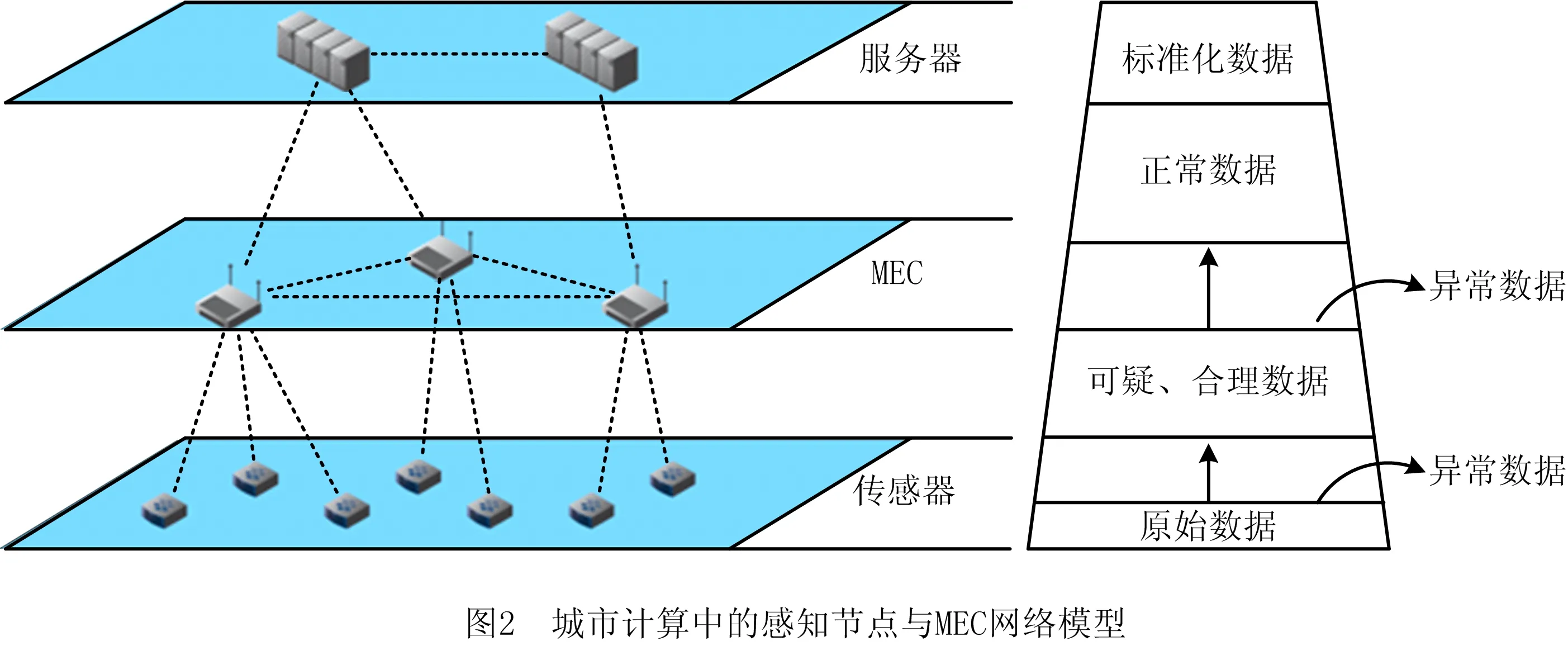
在移动边缘计算层,可以通过对多个节点的数据进行联合分析,进而挖掘数据异常的潜在可能。如果很多节点上传的数据都可疑,则可以认为是环境异常变化导致的。例如突然降温,所有节点采集到的温度数据都会骤降,那么这样的数据属于正常数据。通过设置可疑节点数量门限d,当汇报可疑变化的节点数量大于可疑数量门限,则认为数据的可疑变化属于正常变化;若小于这一门限,则认为数据的可疑变化属于异常变化,进行过滤。
4 仿真实验及分析
基于本文的算法设计,本章主要完成仿真实验并测试算法的性能。本文设计了两个实验,来评价本文提出的异常数据算法的性能,通过移动边缘云的分布式实时数据过滤算法对异常数据进行识别及过滤。仿真实验环境为:MATLAB R2017a开发,处理器Intel(R)Core(TM) i5-4690MQ,内存8 GB,操作系统为Windows 10。
4.1 实验数据
实验将在真实数据集上进行设计,实验的数据集是由伯克利英特尔实验室部署的54个传感器所生成的,原始的数据集中包括时间、温度、湿度、光照和传感器的电压等数据字段。本文将在此基础上构建边缘计算场景,每6个节点接入同一个边缘服务器,通过边缘服务器过滤异常并汇总给云服务器。在仿真实验中,为了提高数据的过滤效率,本文提取数据比较集中的温度数据作为仿真实验数据集,并对节点1~节点6这6个节点所属边缘服务器中的异常数据过滤结果进行验证。
4.2 实验分析
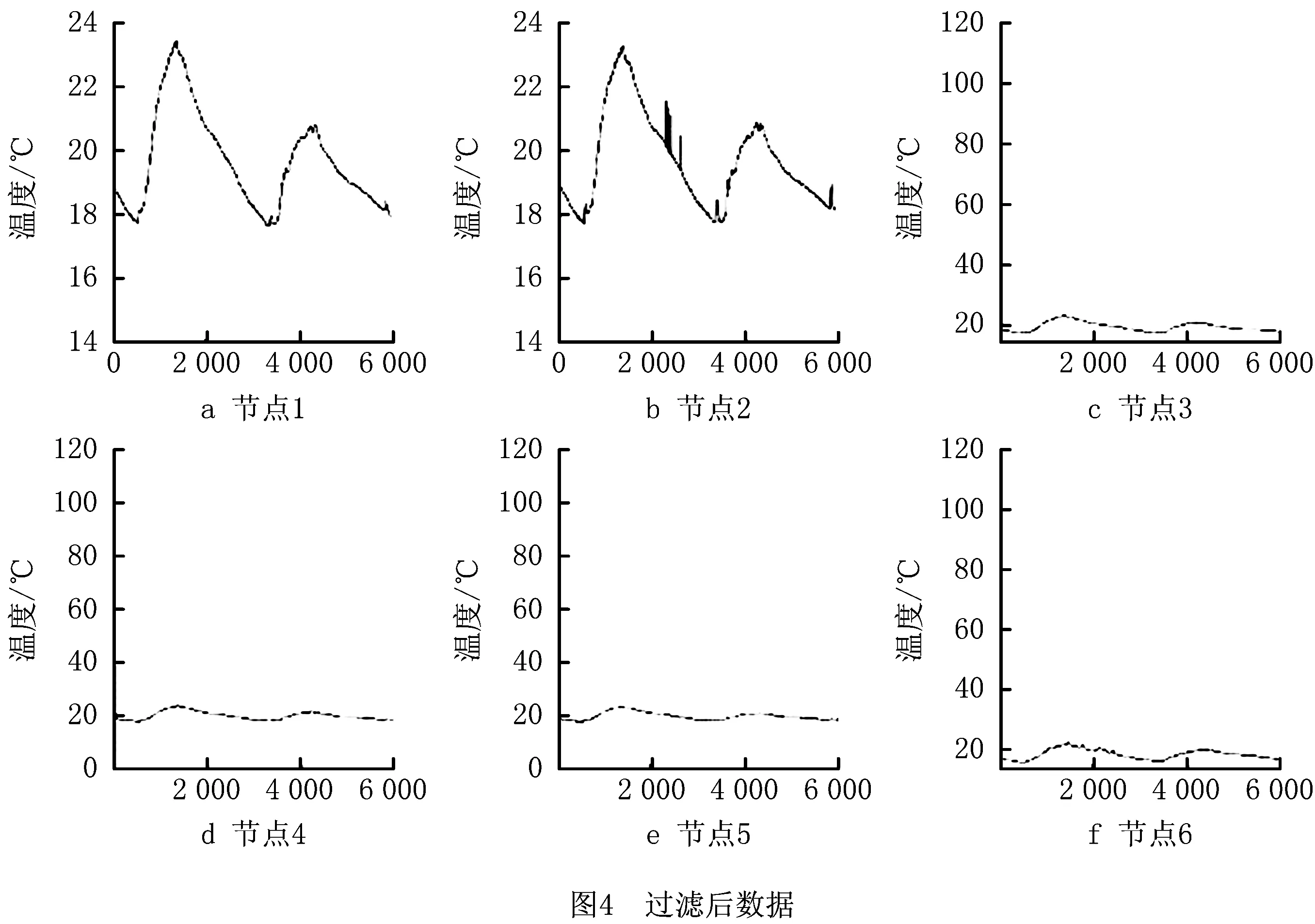
在本文提出算法的实验中,设置异常隶属度门限Tat=0.005,可疑隶属度门限Tst=0.01,并设置可疑节点数量门限d=2。如图3所示为原始数据分布情况,可以看到,某些节点的数据具有较大的波动,数据异常情况比较明显。其中,异常数据的分布比较集中,且变化范围也比较大。其中,图4所示为经过算法过滤后的数据。通过对比图3和图4发现,经过算法处理,数据具有较好的过滤效果。
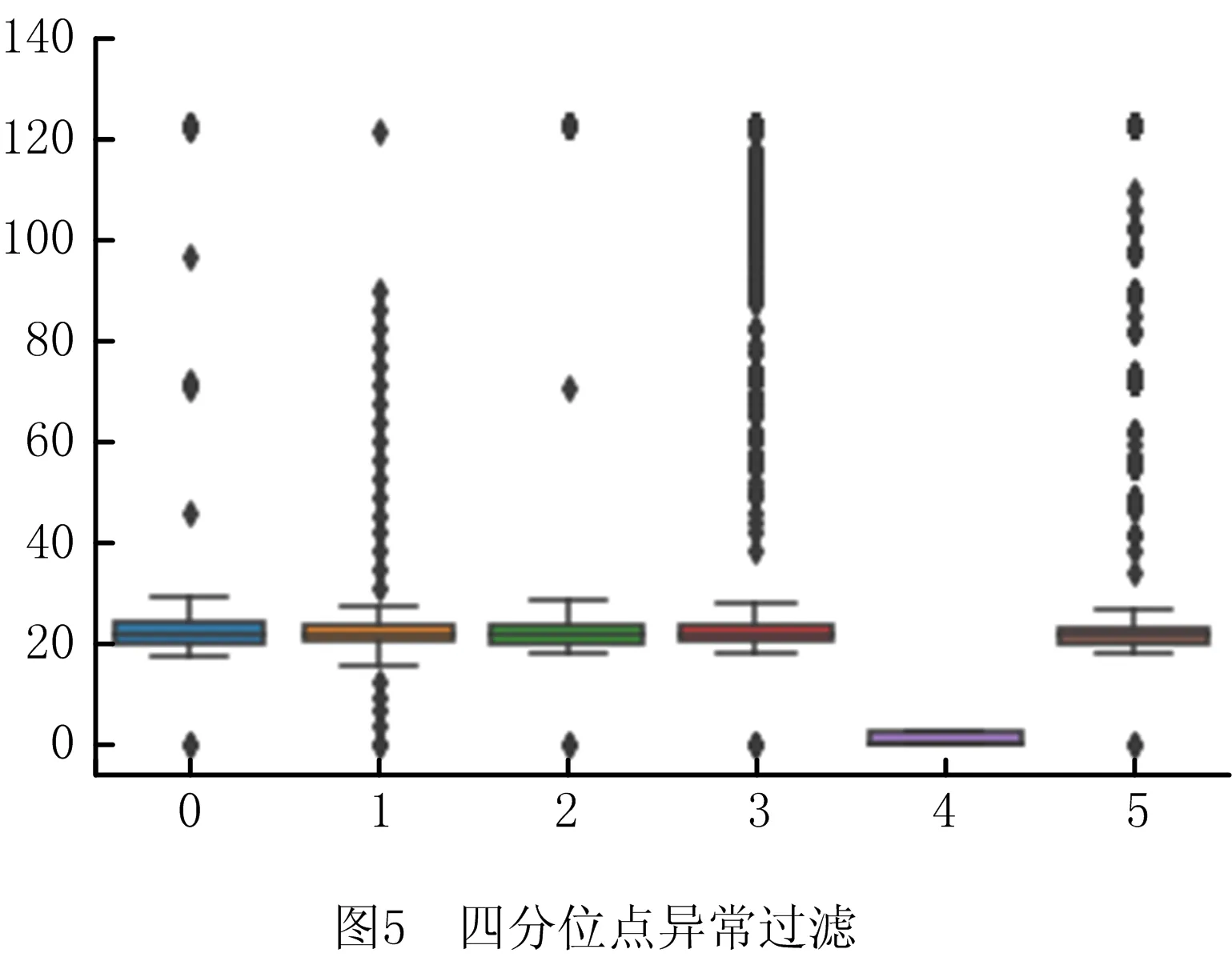
在四分位点异常过滤算法实验中,将异常数据定义为在四分位数范围之外的点,表示为:
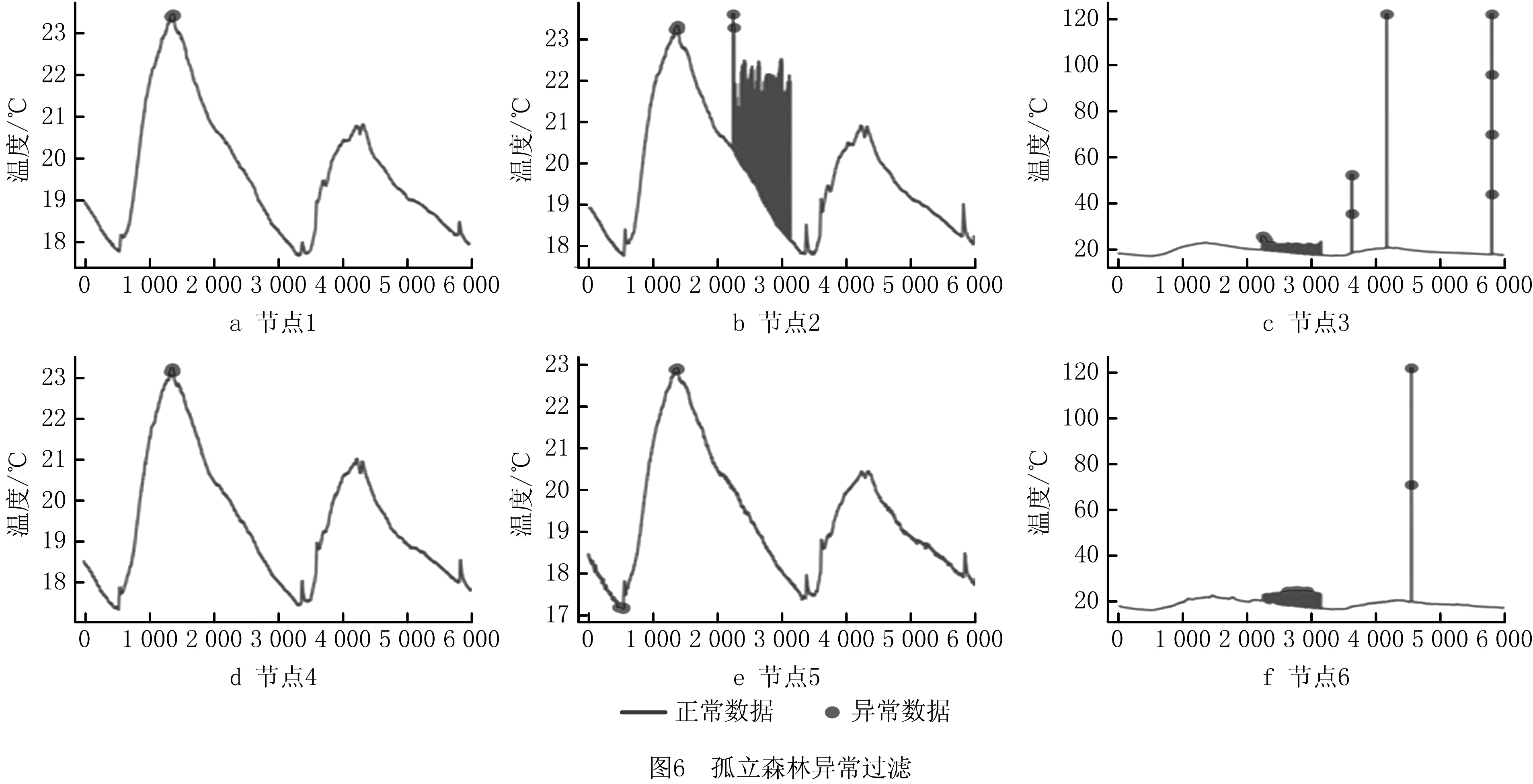
x>Q3+k(IQR)∪x (4) 其中:IQR=Q3-Q1,k=1.5,Q1,Q3分别为第一和第三四分位数。将满足条件的数据定义为异常数据点,但是,从实验结果来看,如图5所示,确定的异常值的比例虽然比较准确,但是,对于一些异常数据比较集中的节点来说,这种异常过滤的方法不能准确实现过滤。 此外,也利用孤立森林的方法来进行异常数据过滤。在孤立森林的算法中,将异常值的比例设置为0.005(在四分位异常过滤的算法中,实验结果较准确地确定了异常数据的比例,在本实验中,采用四分位算法中确定的异常数据的比例作为本算法的异常值数据的比例),实验结果如图6所示。可以发现,在节点1、节点4以及节点5中,孤立森林算法将一些认为是正常数据的点判定为了异常数据,而在节点6中,存在比较集中的异常数据,但是算法却没有将其判定为异常数据,这显然是不合理的。 通过异常检测实验结果可以得出,在真实物理环境数据中,针对不同节点的数据集,算法可以比较准确地过滤异常数据,并且更具健壮性。由图5可知,在节点1、节点3、节点6这3个节点中,异常数据的比例是很小的,甚至可以记为不存在异常数据,因此算法也没有对数据集进行过滤,但是从孤立森林的算法实验结果中可以看到,因为指定了异常数据的比例,算法一定会判定一些数据为异常数据,但是在实际应用中来看,这些数据是其实是正常数据。 在实验中,异常数据检测完成后,通过线性填充的方法对检测为异常值的数据进行填充,这种方法相对简单,而且能够平滑掉异常数据,往往能够替代像温度数据这样变化不明显,且变化连续的数据。 仿真实验验证了该算法具有较好的过滤异常数据的能力,且更具有健壮性。 本文提出基于联合高斯隶属分析的数据过滤方法。通过计算数据的联合高斯隶属度,对数据进行初步过滤。同时,本文基于移动边缘计算,提出了多节点联合过滤的方法,进一步提高了数据挖掘分析的准确性。通过仿真对比实验验证了该算法具有较好的过滤异常数据的能力,并且针对不同的真实物理数据集,算法更具健壮性。但算法也存在一些局限,如需要足够多的先验信息,算法的时间复杂度相对来说较高,另外需要人工指定隶属度门限以及可疑节点数量门限,可能针对不同的数据集,需要不断优化。因此,在未来的研究中,将进一步优化算法的复杂度,针对不同的数据集,设计算法可以自动确定隶属度门限以及可疑节点数量门限。
5 结束语
