基于棉田原位高光谱数据的土壤pH值反演与制图研究
2021-10-11蔡海辉柳维扬罗德芳王玉珍白建铎白子金
蔡海辉, 彭 杰, 柳维扬, 罗德芳, 王玉珍, 白建铎, 白子金
(塔里木大学 植物科学学院, 新疆 阿拉尔 843300)
由于受农业灌溉、蒸降比、地下水矿化度等因素影响[1],新疆土壤碱化状况不容乐观。2015年中国地质调查局资料表明,近40 a来,中国有近2.67×107hm2耕地土壤碱化状况加剧,约占耕地面积的23%,土壤pH值上升了0.6左右。pH值是土壤酸碱化的重要评价指标,土壤碱性越强所对应的pH值越大,土壤越容易表现出板结、透气性差等现象,从而降低植物根系对养分的吸收效率[2-4],影响植物的生长发育。为更好防治农田土壤碱化,提高农田作物产量、提升作物品质,需要对农田中土壤pH值的分布状况进行持续监测。但传统野外采样并进行室内化学分析的方法不能实时、快速获取土壤pH值在农田中的分布信息,随着高光谱技术的不断发展,可通过建立土壤pH值与土壤反射率反演模型实现土壤pH值信息的快速准确获取[5],为农田土壤改良、精准农业发展提供技术支撑[6]。
目前国内外学者在使用高光谱数据预测土壤属性方面有大量研究成果,如李诗朦等[7]使用室内光谱数据预测呼伦贝尔草原的电导率和pH值,使用支持向量机回归建模R2大于0.90,RPD大于3.00,具有较好的预测能力;徐驰等[8]研究发现使用室内高光谱数据反演内蒙古河套灌区的地表土(0—5 cm)的pH值与含盐量是可行的,模型预测效果良好,R2在0.95以上;Miles等[9]通过使用室内光谱数据反演土壤中的速效磷与pH值后,认为未来光谱分析可能会取代传统化学分析对土壤属性信息进行获取。虽然室内光谱可以减少土壤水分、土壤质地和一些环境因素对光谱测量与土壤属性预测精度的影响[7],但由于其对野外采集的土壤样品进行预处理后才能测定土壤光谱反射率,需要耗费一定时间因而不能对土壤属性进行快速实时监测,因此一些学者对使用野外实测光谱数据预测土壤属性也表现出了浓厚的兴趣,如翟茂彤[10]、乔娟峰等[11]利用野外光谱数据成功反演了鄱阳湖和阜康地区的有机质含量;贾科利等[12]使用偏最小二乘回归建立土壤pH值预测模型的拟合度R2达0.93,王凯龙等[13]建立的土壤pH值预测模型R2为0.90,RPD为2.65,他们使用野外实测光谱数据都较好预测了当地土壤的pH值。这些研究都证实了采用野外实测光谱预测土壤属性是可行的。
数字土壤图通常利用栅格的方式来详尽表达土壤属性的空间变化,是一种新兴的、有效的表达土壤属性空间信息的方法[14-15],如廖琪等[16]、Brian等等[17]使用克里格插值方法分别获取了其研究区的土壤有机质、pH值空间分布图,但利用田间原位高光谱数据反演土壤pH值并制图的研究还较为少见。基于以上分析,本文以南疆阿拉尔市十二团棉田土壤为研究目标,通过野外原位间隔采集光谱数据、土壤样品与室内化学分析,结合偏最小二乘回归、支持向量机回归、随机森林3种建模方法,筛选最优模型反演研究区土壤pH值并使用普通克里格插值制作土壤pH值分布图,为南疆土壤碱化研究与治理提供理论依据。
1 材料与方法
1.1 研究区概况
研究区位于新疆阿拉尔市十二团,其中心地理坐标为东经81°19′05″,北纬40°29′20″,地处南疆中部,紧邻塔克拉玛干沙漠边缘,位于塔里木河上游。年均降水量约为47 mm,年均蒸发量约为1 988 mm,年平均气温为10.8 ℃,年均日照时长约为2 700 h,属典型的大陆性干旱气候。研究区内土壤以砂土和砂壤土为主,依靠膜下滴灌提供作物生育期内所需水分,每年冬春季节都要进行大水漫灌。研究区地势西高东低,灌溉入水口在地势较高处。在阿拉尔市十二团选取能代表当地管理水平且具有一定程度碱化的棉田作为研究区。
1.2 土壤样品采集与测定
土壤样品采集于2018年11月3—4日,采样点远离路边、地边,采用网格布点法均匀分布于研究区内,样点间隔为20 m,去除表面覆盖的植物残留物、石块等影响光谱反射率的杂物后,采集较为平整、没有明显水分聚集的土壤表面光谱反射率信息。每行采集21个样点原位高光谱数据并间隔采集0—20 cm深度的棉田土壤,在8 hm2面积内采集11行共计231个样点原位高光谱数据及其经纬度信息,并同步采集其中116个样点的土壤样品,建立原位高光谱数据和土壤pH值的反演模型,并利用最优反演模型预测未采集土壤样品的115个样点的pH值,结合实际测定的土壤pH值进行插值制作研究区土壤pH值分布图。将采集所得土样带回实验室风干研磨后过2 mm筛,使用土水比为1∶2.5土壤浸提液测定土壤pH值[18]。
1.3 原位光谱数据采集与预处理
使用美国SR-3500型地物光谱仪采集光谱数据,其波长范围为350~2 500 nm,在波长区间分别为350~1 000 nm,1 000~1 900 nm和1 900~2 500 nm时,光谱分辨率分别为3.5,10和7 nm,数据重采样间隔为1 nm。使用具有内置光源的光纤手柄采集土壤原位光谱数据,将土壤表面的植物残体、残膜、石块等杂物清除干净后,仪器探头紧贴地面测量,每个样点重复测量10次,取其算术平均值作为该样点原位光谱数据。每个样点在测量前都要清理手柄的镜面,每10个样点进行1次白板校准。为了便于描述,将此方法采集的光谱数据简称为“原位数据”。根据国内学者的研究成果去除噪声较大的350~399 nm,2 401~2 500 nm波段[19-20],采用Savitzyk-Golay平滑滤波去除光谱噪声后[21],使用Excel和The Unscrambler X 10.5.1软件对原始反射率(R)进行倒数(1/R)、对数(lgR)、倒数对数lg(1/R)、面积归一化(AN, area normalization)、峰值归一化(MAN, maximum normalization)、多元散射校正(MSC, multiplicative scatter correction)、一阶微分(FDR, first derivative)、二阶微分(SDR, second derivative)等9种数据预处理。
1.4 建模方法及评价指标
将土壤pH值进行升序排列,取每3个相邻样本的中间样本的集合为验证集,其余三分之二为建模集,即78个样本用于建模,38个样本用于验证。建模方法为偏最小二乘回归(PLSR,partial least squares regression)、支持向量机回归(SVMR, support vector regression)、随机森林(RF, random forest)3种,其中PLSR与SVMR建模在The Unscrambler X 10.5.1软件中实现,RF建模在Rstudio中实现。
PLSR集中了主成分分析、典型相关分析、线性回归分析的优点,解决了数据间多重共线性、样本数少于变量数的问题,因而成为了普遍使用的一种线性模型[22]。
SVMR方法是一种通过一个非线性映射,把样本空间映射到一个高维的特征空间中,使得在样本空间中的非线性可分问题转化为在特征空间中的线性可分问题的机器学习算法[22]。SVMR方法的关键在于核函数,结合相关文献[23-24],本研究选取RBF函数为其核函数,根据模型交叉验证最优效果及模型稳定性确定惩罚系数C和Gamma的值。
RF是使用随机方式建立一个具有许多且没有关联的决策树的森林,从N个样本中随机选取n个样本用于构建回归树,当有样本输入时都要经过每棵分类决策树决策分类,投票最多的一类作为最终分类结果,在进行回归预测时,预测值为所有回归树输出结果的平均值。根据模型稳定性及较高预测效果,并经多次建模验证,确定决策树个数及其余参数设置。
模型稳定性及精度评价指标为决定系数(R2)、均方根误差(RMSE)、相对分析误差(RPD)。针对RPD而言,当RPD<1.5时模型无法对样品进行预测,当1.5≤RPD<2.0时表明模型只能粗略估测样品中高含量和低含量部分,当2.0≤RPD<2.5时表明模型具有较好的预测能力,当2.5≤RPD时模型具有很好的预测能力[21]。选择R2和RPD大、RMSE小的模型作为最优模型,进行进一步研究。
2 结果与分析
2.1 土壤pH值描述性统计
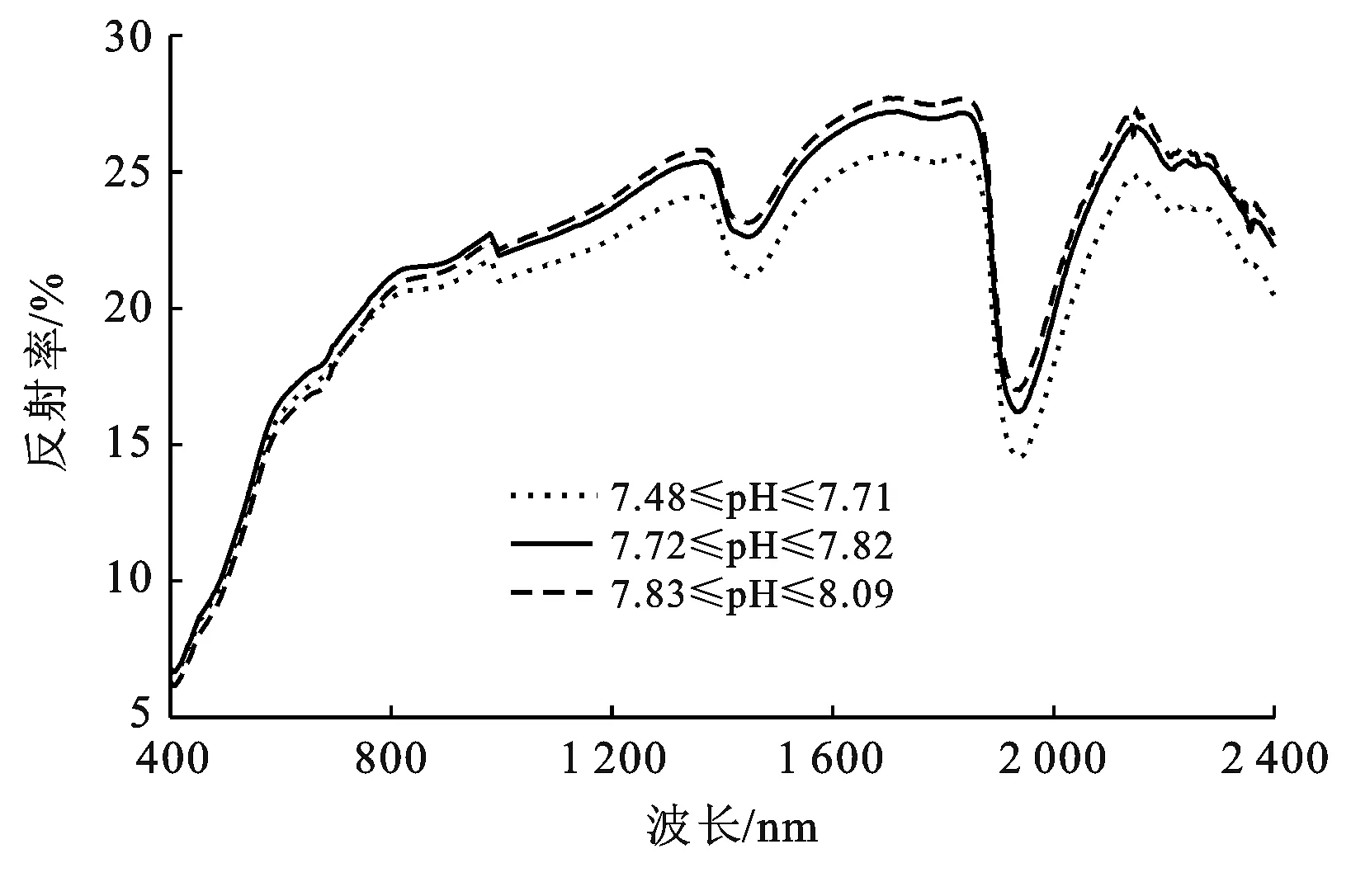
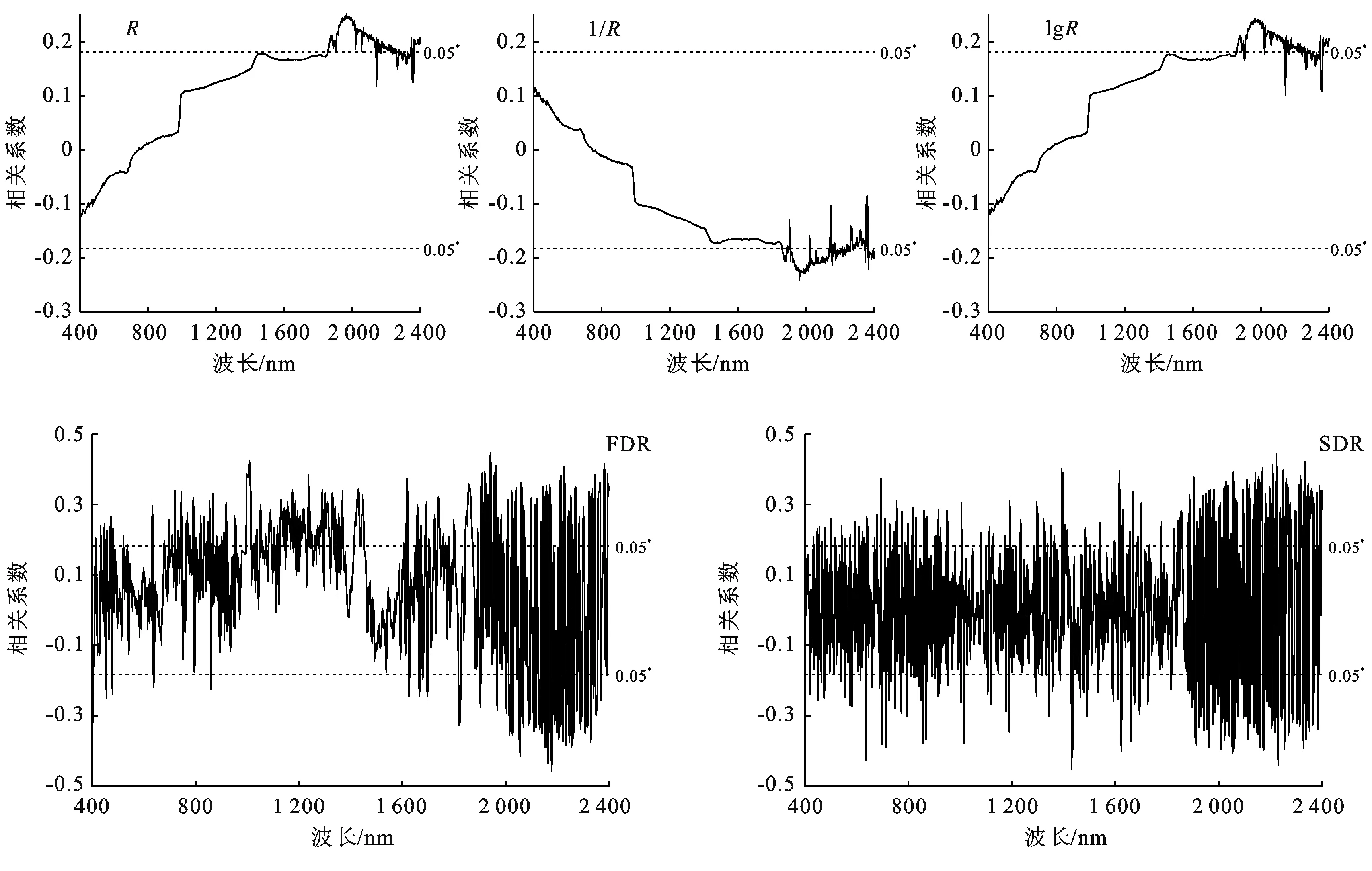
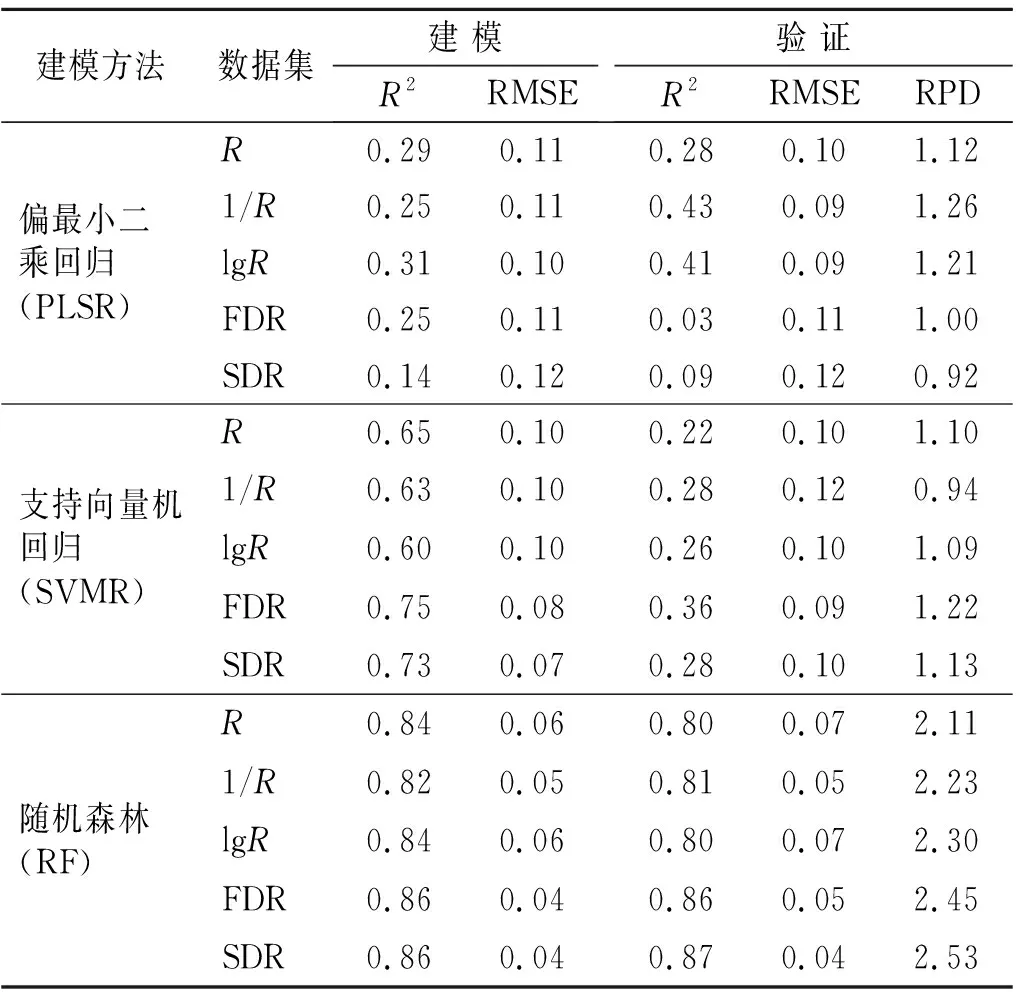
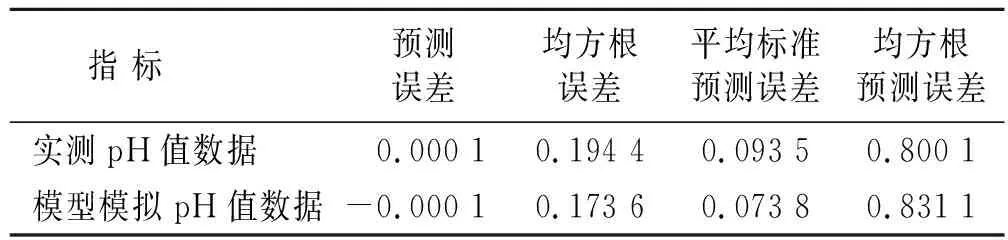
表1为建模集与验证集土壤pH值数据统计特征,由表1可知,116个供试样本pH值的最大值为8.09,最小值为7.48,平均值为7.77,标准差0.12,变异系数为1.54%,根据新疆土壤分析[25]中pH值分级标准,6.50≤pH<7.50为中性;7.50≤pH<8.50为碱性;pH值≥8.50为强碱性,变异系数是衡量数据间变异程度的统计量,其可以用于表示样品的离散程度,当Cv<10%时为弱变异性;当10%≤Cv≤100%时为中等变异性;当100% 表1 建模集与验证集土壤pH值数据统计 图1为将116个土壤样品的pH值升序排列均分为3类后(分别为7.48≤pH≤7.71,7.72≤pH≤7.82,7.83≤pH≤8.09)计算各类野外原位高光谱反射率数据平均值,所得到的土壤样品反射率曲线。从图1可以看出在400~988 nm波段内不同pH值的土样光谱反射率曲线差异较小;在989~2 400 nm波段范围内,相同波长条件下土壤pH值越大所对应的光谱反射率也越大,说明在pH值为7.48~8.09范围内土壤的光谱反射率与土壤pH值呈正相关,即在一定pH值范围内,在同一波长下随着土壤pH值的增大,反射率也随之增大;在1 450,1 940,2 200 nm附近存在3个明显的特征吸收谷,参照相关学者研究结果,1 450和 940 nm是水分吸收谷[27-28],2 200 nm附近是用于判断黏土矿物存在的特征谷[29],在这些吸收谷附近的土壤反射率明显降低,研究区土壤反射率最大值为27.70%。土壤质地、土壤含水量、环境杂散光是导致土壤光谱反射率数据降低的主要影响因素[27],这些因素也将影响光谱数据的建模和验证精度。 图1 不同pH值范围土样反射率均值曲线 经建模结果验证,选择建模及验证效果较好的R,lgR,1/R,FDR,SDR 5种数据形式进行后续分析。图2为在波长400~2 400 nm间,将土壤pH值与原位高光谱数据及其4种数据变换形式进行相关分析所得的相关系数曲线。由图2可知土壤pH值与R,lgR在400~745 nm呈负相关关系,与1/R成正相关关系,而在746~2 400 nm波段则相反,R,lgR与土壤pH值的相关性系数曲线几乎一致。R,lgR,1/R的最大相关系数均位于1 965 nm处,分别为0.25,0.24与-0.23,FDR,SDR的最大相关系数分别位于1 942 nm,636 nm处,分别为0.45,-0.43。土壤pH值与R,1/R,lgR,FDR,SDR的相关系数达显著性的波段总数分别为421,395,420,819,670个, FDR,SDR变换可以大幅度提高土壤pH值与光谱数据相关性,但由于其与土壤pH值的相关性缺乏规律,需要对光谱进行较为详细的分类,充分挖掘光谱信息才能取得好的建模及预测效果。原位高光谱数据经倒数、对数转换后对于改善光谱与土壤pH值相关性作用不大,对反射率进行一阶微分、二阶微分转换可以明显提高光谱与土壤pH值的相关性和相关系数达显著性的波段总数,其相关系数最大值为0.45比原始反射率提高了0.20左右,但相对于一阶微分变换,二阶微分的相关系数分布更为均匀,使用二阶微分建模可能会取得更好的建模效果。 图2 土壤pH值和光谱反射率不同转换形式的相关系数 以土壤pH值为因变量,所对应原位高光谱反射率数据为自变量,采用3种建模方法结合5种数据形式建立反演模型。建模集与验证集pH值数据详见表1。表2为建立的3种模型的精度对比统计。由表2可知,微分数据在支持向量机回归建模,随机森林建模中均取得了不错的效果,但在偏最小二乘回归建模时的建模和预测效果较差。相较于微分数据,3种建模方法在使用反射率倒数、对数建模时的建模与验证效果都不太理想。偏最小二乘回归建模中反射率倒数的建模效果最好,建模集的R2为0.25,RMSE为0.11,验证集R2为0.43,RMSE为0.09,RPD为1.26,支持向量机回归建模中一阶微分的建模效果最好,建模集R2为0.75,RMSE为0.08,验证集R2为0.36,RMSE为0.09,RPD为1.22,但这两者验证集的R2和RPD值较小、RPD均小于1.4,无法对样本进行预测。随机森林中最优反演模型的建模集R2为0.86,RMSE为0.04,验证集R2为0.87,RMSE为0.04,RPD为2.53 (2.5≤RPD<3.0)模型具有极好的预测能力。相较于PLSR模型、SVMR模型,RF模型的精度,预测能力均最好,因此选择RF模型为最优模型,对未采样的样点进行反演与制图研究。 表2 不同土壤pH值模型精度对比 基于对前文的分析,选取随机森林模型作为反演模型,对只采集原位光谱信息而未采集土壤样品的115个样点进行反演并制作研究区土壤pH值分布图。为进一步验证田间原位光谱的建模精度,将未采集土壤样品样点的原位高光谱数据进行Savitzyk-Golay平滑和SDR数据处理后使用随机森林模型进行反演土壤pH值。克里格插值是地统计学的主要内容之一,同时也是估计未采样位置属性值的最优无偏估计方法,是土壤属性制图中广泛使用的一种插值方法。图3为使用随机森林模型模拟的土壤pH值数据和实测土壤pH值数据分别进行普通克里格插值得到的研究区土壤pH值插值图。 图3 研究区土壤pH值模型模拟插值与实测数据对比 由图3可知,模型模拟的土壤pH值数据插值图与实测土壤pH值数据插值图中土壤pH值的分布特征高度吻合,都表现为土壤pH值在东西方向上总体呈现逐步减小趋势,南北方向上呈现逐步增加趋势。研究区内土壤pH值分布状态为高值部分呈片状集中在研究区东部,低值部分成片集中在研究区的中西部,低值地带和高值地带间有较为明显的缓冲带,出现这种规律可能是因为研究区地势西高东低,在进行冬灌、春灌洗去土壤盐分时,使得土壤中交换性Na+随水流原因被土壤胶体吸附导致东北区域土壤碱性增强,而表现出土壤pH值增加所造成的。研究区选取的是最接近当地生产管理水平的田块,属于轻微碱化,说明该地区土壤可能存在不同程度的碱化现象,因此研究该地区的土壤pH值的空间分布信息,对于精准改良当地的土壤酸碱度,提升作物产量有重要意义。对使用实测pH值与模型模拟pH值得到的插值图进行预测误差分析,结果见表3。预测误差、均方根误差、平均标准预测误差越小说明预测效果越好,均方根预测误差越接近于1越好[28]。由表3可知,实测pH值预测误差与模拟pH值预测误差相近,都达到了较好的插值效果,说明使用野外原位光谱预测土壤pH值是可行的。 表3 普通克里格插值预测土壤pH值误差分析 土壤pH值是衡量土壤酸碱化程度最重要的指标之一,使用田间原位高光谱数据对土壤pH值进行反演并制作土壤pH值分布图,可为土壤养分利用、实现精准农业的实时快速检测提供一定的科技支撑[15,30]。文中对不同数据转换形式的光谱数据与土壤pH值的相关系数进行比较,结果表明反射率数据经微分变换后与土壤pH值的相关性明显提高,能为建立预测模型提供更多信息,这也与李阳等[19]、李诗朦等[7]、魏雨露等[31]研究结果一致。微分数据在SVMR,RF建模中都取得了不错的结果也验证了这一点,但微分数据会放大噪声的干扰,同时也易引进无关因素进而影响建模精度[32],如张芳等[5]、彭杰等[33]使用微分数据建模的效果不如实测光谱。本文使用RF模型预测土壤pH值取得了较好的效果,同郭鹏等[34]、张振华等[35]研究结果一致。不少研究证实RF在噪声较大、数据量少时仍能建立准确且可靠的模型,其具有处理定量和定性数据的能力,在数字土壤制图中能够发挥出巨大的潜力[36-37]。正是由于随机森林具有较强的抗拟合能力及其对高维数据极强的处理能力[38],本文在使用其与原位高光谱数据的微分建立的反演模型时取得了不错的结果。PLSR在处理线性回归时有着独特的优势同时还能解决数据间的多重共线性问题,但对于非线性数据的拟合能力较低,SVMR适用于小样本的非线性数据建模,但当数据集的噪声过大甚至是成为支持向量时使用SVMR预测可能会取得较差的结果[39],因原位高光谱数据量大且含有土壤水分信息与其他干扰因素,所以本文使用PLSR,SVMR建模效果不如RF模型。与室内光谱反演土壤属性数据相比,田间原位光谱可以节省室内测定时间,得到更接近实际的土壤属性数据,实现土壤属性的快速、实时检测。原位光谱数据易受环境因素、土壤类型等因素影响,且土壤pH值在近红外波段属于间接预测,本文建立的预测模型精度不如李诗朦等[7]、魏雨露等[31]的高。建立的模型受地域、土壤类型等影响较大,在不同的地区应用需建立相应的原位光谱库,进而为精准农田的实现提供一定的技术支持。 本文采用随机森林算法建立新疆阿拉尔市十二团研究区土壤pH值的原位高光谱反演模型并利用普通克里格插值方法制作研究区土壤pH值插值图,着重讨论了4不同数据预处理方式结合3种建模方法对于提高建模及验证精度的帮助,确定了使用二阶微分数据预处理后的随机森林反演模型为最优模型。 (1) 原位高光谱反射率数据与土壤pH值在746~2 400 nm波段呈正相关关系、400~745 nm波段呈负相关关系,在1 856~2 400 nm相关关系达显著性水平,相关系数在1 965 nm处达最大值为0.25。 (2) 相较于偏最小二乘(PLSR)、支持向量机(SVMR)建模,使用5种数据形式进行随机森林建模都能取得好的建模及验证效果(RPD均大于2.00)。对于不同数据变换来说反射率数据经一阶、二阶微分变换后使用支持向量机回归(SVMR)、随机森林(RF)建模都可以取得较好的建模效果,但支持向量机的模型验证效果较差(R2为0.36,RPD为1.22,RPD小于1.40无法预测土壤pH值),随机森林模型验证效果较好R2达0.87,RPD达2.53,能极好的反演未采样点的土壤pH值。 (3) 分别利用模型模拟数据和实测数据进行普通克里格插值制作研究区土壤pH值插值图,模型模拟数据插值图与实测数据插值图中土壤pH值的分布特征相一致,说明田间原位高光谱测量手段可以实现土壤pH值空间分布信息的实时快速获取,同时也能为农田碱化防治提供一定依据。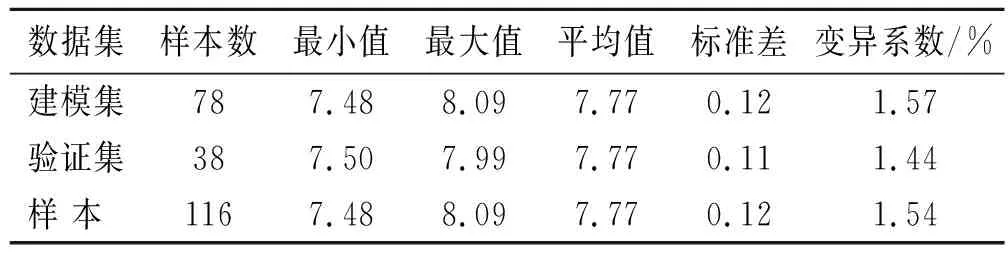
2.2 不同pH值的土壤光谱特征分析
2.3 土壤pH与土壤光谱数据相关分析
2.4 土壤pH值反演模型的建立与验证
2.5 土壤pH值空间分布数字制图

3 讨 论
4 结 论
