基于XGBOOST-DNN的中期电力负荷预测①
2021-10-11谷震浩
杨 洋,谷震浩
1(中国科学院大学,北京 100049)
2(中国科学院 沈阳计算技术研究所,沈阳 110168)
电力负荷预测在电力系统调度、维护和容量规划等方面起着至关重要的作用,对指导电网规划建设和改善电力系统资源的优化配置具有重要意义.实际的电力负荷预测分为短期、中期和长期预测.短期负荷预测(Short Term Load Forecasting,STLF) 与未来几小时到几天的负荷预测相关,中期负荷预测(Medium Term Load Forecasting,MTLF) 则处理以几周到几个月为目标的预测,长期负荷预测(Long Term Load Forecasting,LTLF) 则是处理一年到几年的负荷预测.LTLF可以协助规划新的电力系统;MTLF 有助于系统维护、购买能源和定价计划;而 STLF在配电和负荷调度中起着关键作用.MTLF是一项及具有挑战性的任务,因为它需要在较长的时间内完成及长期指导和预测的功能.
在前沿工作者的研究当中,短期电力负荷预测的算法种类较多,丰富多样.如Chen 等[1]在2018年提出了一种引入深度残差网络结构的短期电力负荷模型;孔祥玉等[2]在2019年提出了一种基于模态分解与特征相关分析的短期负荷预测方法;Del Carmen Ruiz-Abellón 等[3]在2018年验证了集成学习方法随机森林在短期电力负荷的有效性.肖勇等[4]在2020年提出了基于多尺度跳跃深度长短期记忆网络的短期负荷预测方法.在中长期的电力负荷预测的研究工作中,傅靖等[5]在2020年提出了基于基因表达式编程的中长期电力负荷预测算法,并通过仿真实验验证了其算法的精确性;王军[6]在2018年提出了基于深度神经网络的中期电力负荷预测,在中期的负荷数据分析处理和神经网络模块中给出了具体的处理方案;陈家慧[7]在2019年提出了灰色理论与深度神经网络在电力系统中长期负荷预测中的应用方案.
在本文中,我们提出了基于XGBoost和DNN 模型相结合的XGBoost-DNN 算法,最大程度地利用除负荷时序特征以外的特征信息,并引入短期电力负荷的预测形成的交叉特征到最终的中期电力负荷模型中.
1 电力负荷预测的影响因素
电力负荷预测的数据主要是以时序形式存储,其影响因素非常复杂,因此需要观察不同时间段的天气、温度、湿度、节假日、经济状况来对数据进行不同角度的分析.这里我们主要采用的数据源于全球能源大赛GEF-Com2017,其中的更多数据细节可以参考文献[8]进行查阅.该数据提供了横跨美国新英格兰的8 个区域的小时级电力负荷数据,还提供了包括干球温度和露点温度在内的每小时天气数据.当前数据的分析主要取2003年3月到2017年12月时期所有区域总和的负荷数据,温度是8 个地区气象站的加权值,根据文献[8]所解释,每个负荷区对应的气象站是根据其与负荷区地理位置的接近程度来表示的“最佳选择”,并不代表负荷区的“实际天气”,而仅代表所列气象站,其权重数据可具体参见GEF-Com2017 数据集.
受于数据所限,本文的负荷数据影响因素的分析将在干球温度和露点温度的数据上进行.如图1和图2所示,我们可以获取到从2003年到2017年在以小时为粒度,温度和真实需求负荷之间的散点图,我们从中进行了非线性函数的拟合,最终确定温度和负荷之间的非线性关系.
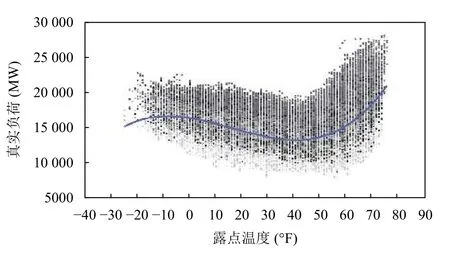
图1 露点温度与负荷数据的散点图
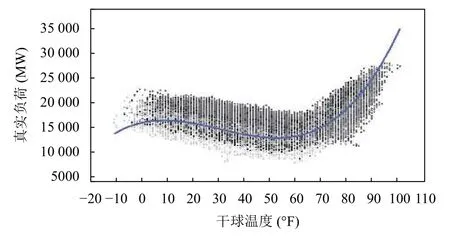
图2 干球温度与负荷数据的散点图
数据在数据分析过程中,我们不得不去验证数据温度的真实性,即其温度数据是否符合我们的基础认知(呈现线性关系).如图3所示,我们将所有的干球和露点数据进行了散点图的可视化,并进行了线性函数的拟合.可以发现,干球温度和露点温度小时粒度的区分度非常明显,并且线性拟合的函数满足于我们的基础认知的数据特性.
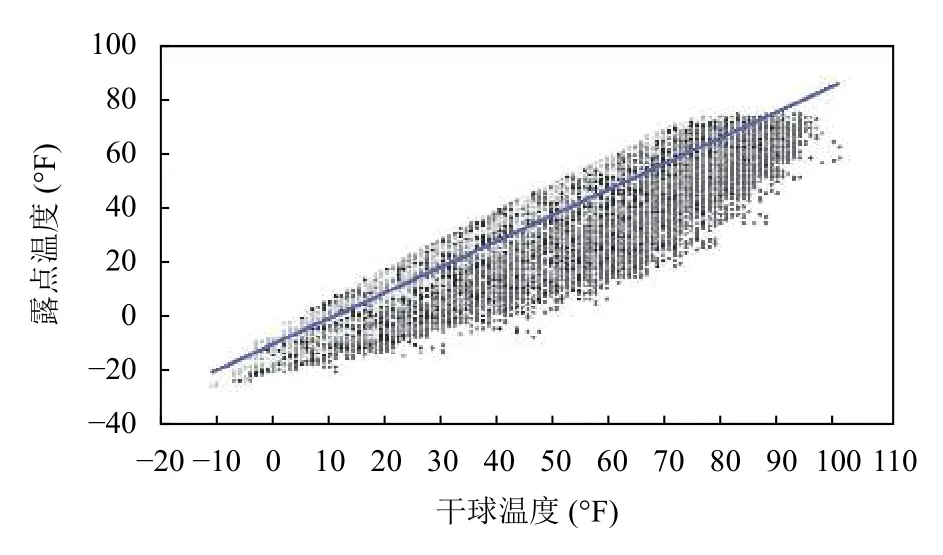
图3 露点温度与干球温度数据的散点图
除以上干球和露点温度的影响因素外,其负荷数据本身便存在一定的周期性变化,如图4所示,可以看出数据在2003年到2017年之间,每一年的负荷数据都呈现了3 个峰头和3 个峰谷的周期性变化.因此,与周期性变化具有强关联性的时间特征是需要重点挖掘的数据特征,比如季节、月份、上下旬、工作日、周末等.

图4 负荷数据的周期性变化图
2 XGBoost-DNN 模型算法
本文所提出的XGBoost-DNN 模型算法主要是由XGBoost和DNN 两个模块,前者作为特征处理器,利用短期负荷预测对原始数据进行用来学习特征到目标的映射关系,后者将学习的映射关系(叶子节点)作为特征接入到DNN 模型中去学习中期电力负荷的时序目标,由此完成中期电力负荷的预测任务.
2.1 XGBoost
树模型具备一般的if-then 结构,简单的决策树模型会将输入数据集的特征空间进行划分,每个数据样本最终会被分在特征空间的子空间中,也就是每个数据样本会落在决策树上的某一个叶子节点上,而该叶子节点得益于if-then 结构的原因就具备了一个天然的特征交叉效果,如图5所示,在Tree1 中,如果样本A落在第一个叶子节点上,那么可以获得<age<15 &gender=male>的二阶交叉特征.因此,通过树模型我们可以很自然地获取到高阶的交叉特征,基于这类特性,我们选择树模型可以将时序特征和类别特征加工成丰富的交叉特征.
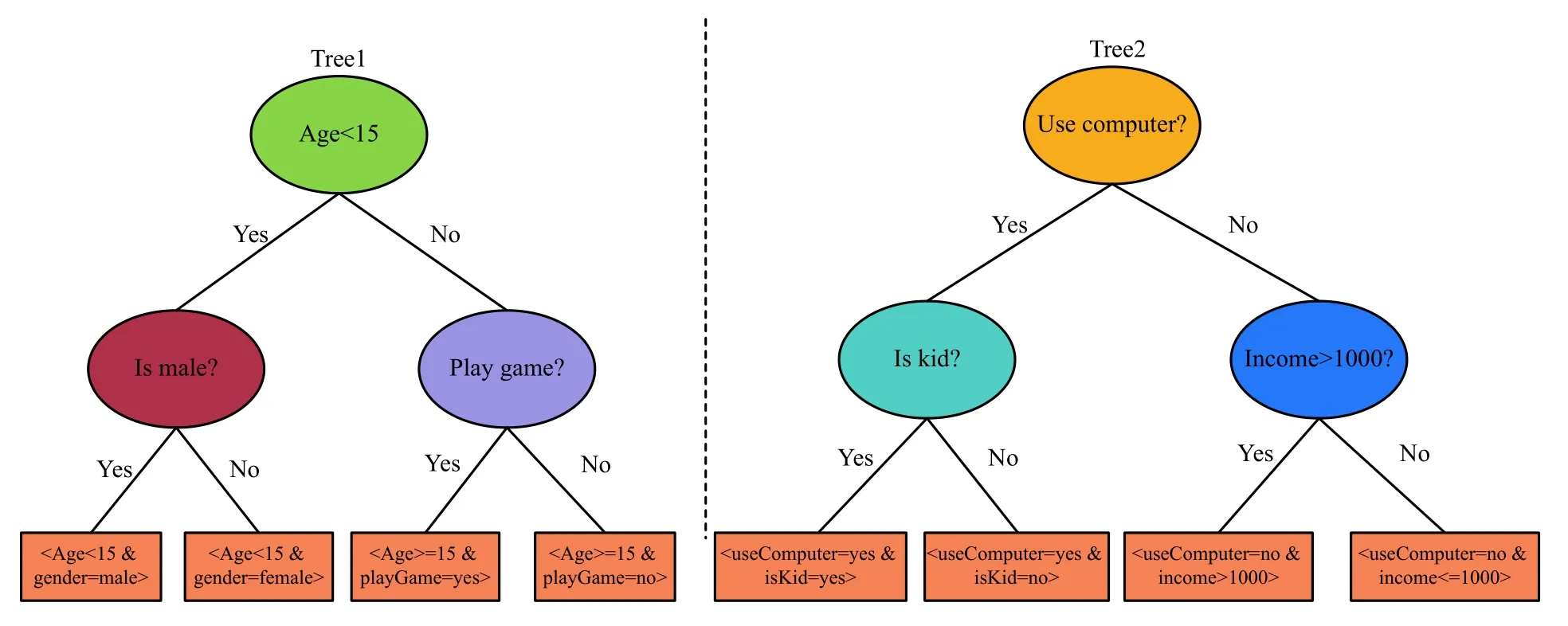
图5 树模型的特征交叉
在树模型的演化历史中,集成学习中的树模型又被分为了以随机森林(random forest) 模型为代表的bagging 思想和梯度提升树(Gradient Boosting Decision Tree,GBDT)为代表的Boosting 思想,两者都是使用弱学习器的集成学习方式对需求任务进行学习,其中主要的不同是,前者是分为多个子模型对放回抽样的数据进行多次决策,最终预测结果依赖于全部子模型的投票结果,后者是将多个子模型进行堆叠,后一个子模型在前一个子模型的基础上学习其剩余的残差,即一个样本不再只落在一棵树的叶子节点上.如图5所示,当一个样本A 通过Boosting的树模型,并且落在Tree1的第一个叶子结点和Tree2的第一个叶子节点,那么我们可以得到<Age<15 &gender=male>和<useComputer=yes &isKid=yes>作为样本A的高阶特征表达.
XGBoost (eXtreme Gradient Boosting)算法是由华盛顿大学陈天奇博士基于GBDT和随机森林提出的高效和广泛使用的集成学习方法,既可以应用于分类任务中,也可以应用在回归问题中.相比GBDT和随机森林,XGBoost不仅具备更加良好的精确性,还添加了正则化项增强了模型的泛化效果,同时支持并行化特征选择使其具备了更加高效的学习方式去提升模型的训练速度.损失函数的计算公式如下:
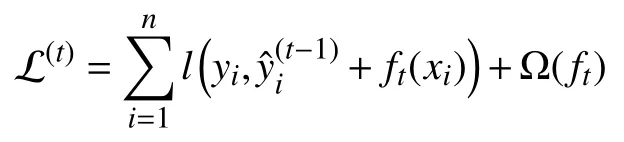
其中,是第t次迭代中第i个样本的预测结果,ft(xi)是第当前迭代中第i个样本的预测函数,Ω(ft)是正则项.
基于此,树模型本身的交叉特性和XGBoost的高精确性是我们选择它的主要因素.借助XGBoost 模型对中长期电力负荷预测任务进行预训练,将中长期电力负荷预测的特征数据接入到XGBoost 模型中,预测Label 由多目标转为单目标,即取最近的时序负荷作为目标Label,预测任务是短期负荷预测任务.该操作主要考虑到两个因素,其一是树模型本身不适用于做多目标回归任务;其二是XGBoost在XGBoost-DNN的模型结构里,承担的主要任务是提供高阶的交叉特征,而选择最近时序的负荷数据作为目标Label 有助于XGBoost 模型在学习过程中能更好地捕捉到以短期时序为目标的特征结构信息,让DNN 模型学习到更丰富的特征空间.
2.2 DNN
深度神经网络(Deep Neural Networks,DNN)是基于误差反向传播算法的前向神经网络,具有较强的非线性拟合和学习能力,一般包含3 层网络:输入层、隐含层和输出层.每一层都是由许多神经元组成,相同层的神经元之间没有任何连接,相邻层则是完全互相连接,其中隐含层大多情况下不止一层,而其中每个隐层的每个神经元都是非线性的激活函数,如ReLU、Sigmoid 等.一般,DNN在工业界中是由机器学习转到深度学习演进过程中必不可少的模型,其强大的非线性拟合和学习能力是得到业界共识的.在中期电力负荷的领域里,DNN在多目标的回归任务中是学习时序关系必不可少的重要模型.它可以很好地捕捉到负荷数据到目标的非线性映射关系,这是XGBoost 等树模型所不能替代的.
2.3 XGBoost-DNN 算法
XGBoost-DNN 模型是由XGBoost和DNN 所构成的组合模型,其模型结构如图6所示.在中期电力负荷预测的场景下一般是使用单个模块来去实现特征信息的提取,如我们常使用LSTM 提取时序特征信息,使用DNN用来学习特征到目标的非线性映射关系.目前在中长期电力负荷领域下,使用DNN的单模块模型在学习过程中更偏向于学习特征映射到多目标的时序关系,对特征本身的特征捕捉能力较少.这里XGBoost作为子模块之一,引入短期电力负荷的Label 作为单目标回归任务的学习,相对中期电力负荷预测的多目标回归任务,单目标模型因为精度和损失函数问题会更多关注数据特征的深度挖掘,不会因为多目标的Label之间存在时序关系从而导致模型更关注时序关系而忽略了特征本身.因此利用XGBoost 学习到的从数据到目标的交叉特征,就是一份经过深度挖掘后的丰富特征信息,利用这份预训练学习到的交叉特征结合原数据通过DNN的特性去学习中期电力负荷的时序关系,可在组合模型中降低DNN 单模型的学习阈值,并实现将中期电力负荷预测模型无法关注到的特征信息得以关注,以此来更适用于该场景下的预测任务.其算法流程如下详述:
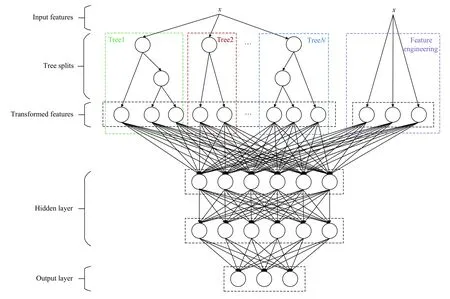
图6 XGBoost-DNN 模型结构
1)XGBoost 获取交叉特征:输入层会将数据分为5 折输入到XGBoost 模型中进行一次短期负荷预测,然后通过交叉预测的方式对每个样本进行预测,进而获取到每一个样本在XGBoost 中的所有叶子节点.例如,假设模型共3 棵子树,并且Tree1、Tree2、Tree3分别对应叶子节点数目为3,2,3,样本数据分别落在第2,1,3的叶子节点上,其样本数据获得的交叉特征当为[0,1,0,1,0,0,0,1]的特征向量.
2)特征工程:这里主要采用的是针对时间和负荷数据做了大量的特征处理,比如,在时间数据上,年、月、日,季度、工作日、节假日、小时、月份上下旬是我们所处理后的时间特征;在负荷数据上,我们生产了多阶差分数据(上一个时间点的负荷与当前时间点的负荷差值)作为偏移值,这里只做了过去72 小时的差分特征.同时,根据时间,为当前时间点产出过去30 天的小时级负荷数据,同时引入前一年同期的前后15 天小时级负荷数据.最后,将类别特征做独热编码的处理,并将全部产出特征和XGBoost所得到的交叉特征进行拼接,即可得到全部转换后的特征数据.
3)DNN 训练:DNN 模块这里主要采样了3 层的结构,激活函数采样ReLU,每层神经元数目根据塔式变化进行调整,并需保证最后一层输出层是720 个神经元,以此预测未来30 天时间里的负荷数据.
3 实验分析
如前面所说,实验所采用数据源自于全球能源大赛GEF-Com2017,主要是从2013年3月到2017年的12月的负荷和温度数据.
3.1 实验环境设置
本文中的实验环境是Docker 容器,镜像是Tensor-Flow-GPU-1.4.0 版本,对应Keras-2.25 版本,所用Python 版本是3.6.8.除此之外,其他配置为6 核CPU,24 GB 内存,一块Tesla P40 GPU,显存23 GB.
3.2 实验评估指标

为评估预测结果的性能,设置均方根误差(RMSE)和平均绝对百分比误差(MAPE)来去评估实验预测结果的性能.其中,n是样本数目,m是预测未来时间点的个数,xtrue(ij)是第i个样本在第j个时间点的真实负荷数据,xpred(ij)是第i个样本在第j个时间点的预测负荷数据.
3.3 实验结果分析
本次实验采用了Grid Search对XGBoost的参数进行了调试,并通过控制变量法逐步对DNN 模型的参数进行调优,在固定网络层数的情况下,测试不同的超参数对模型整体的影响.如图7所示,可以发现XGBoost-DNN的模型算法预测的某个样本未来30 天里的负荷曲线图,较之其他模型算法有较好的表现,更接近于真实的预测结果.

图7 各类算法在某一样本上对未来30 天的预测结果
各个算法的评测结果见表1.从表1中可知,XGBoost-DNN的算法在所有的实验算法中拥有较好的指标提升,可见这种架构模型的性能较好.

表1 各类算法实验结果
4 结论与展望
本文将XGBoost 引入到DNN 进行中长期电力负荷预测之中,并将短期电力负荷和长期电力负荷相结合.在实验过程中,采用了全球能源大赛GEF-Com2017的数据,分别对每一个时间点进行特征工程和模型训练的工作,并将XGBoost-DNN 算法和其他模型进行了对比,验证了该模型架构的准确性,也证实了多特征交叉的有效性.
