城乡医保一体化制度政策效果的DID实证分析
2021-10-11曹翔宇王茵田
曹翔宇,王茵田
(1.清华大学 新雅书院,北京100084;2.清华大学 经济管理学院,北京100084)
改革开放以来,我国的社会医疗保险制度进行了多轮改革。国务院1998年制定出台了城镇职工基本医疗保险(以下简称“职工医保”)的政策,在2003年开展了新型农村合作医疗(以下简称“新农合”)试点,并在2007年完成了城镇居民基本医疗保险(以下简称“城居保”)的制度建设,基本达到了人员全覆盖。自此,我国进入了全民医保时代。但是,这三种基本医疗保险在参保、统筹、筹资和报销等机制上都有较大差距,在保障待遇上存在一定程度的不平等。为切实保障城乡居民公平利用医疗资源,国务院于2016年出台了《关于整合城乡居民基本医疗保险制度的意见》,从覆盖范围、筹资政策、保险待遇、医保目录、定点管理和基金管理六个层面,实现了居民医保制度统一。改革后,原“城居保”和“新农合”合并为“城乡居民基本医疗保险”,城乡居民在公共医疗保障上同等出资、同等报销。那么,一体化的城乡居民医保对全面脱贫、建成小康社会究竟有多大的意义?并轨后的医保政策是否能有效地减轻居民医疗负担,并进而避免因病致贫的情况发生?笔者试图从居民医疗负担、贫困脆弱性等角度切入,通过实证分析进一步探讨城乡医保并轨的影响,并为城乡居民医保制度的全面落地实施提供评估参考和改进建议。
一、政策概述
为了便于理解,我们对城镇居民医疗保险、新型农村合作医疗保险、城镇职工医疗保险和城乡居民医疗保险制度的异同之处作如下的比较分析。
(一)城镇居民医疗保险、新型农村合作医疗保险的比较
新农合门诊待遇水平高于城镇居民医保,主要让农民在乡镇卫生院报销更多,起付线低,在城里的医院报得相对少些;城镇居民医疗保险住院及门诊大病待遇要高于新农合,在大医院报销比例稍高一点,起付线比新农合稍高,保费也多一些。
(二)城镇职工医保、城乡居民医保的比较
职工医保通常由单位和个人按月缴纳、共同承担保费。缴费后,可在下一个月享受该医保待遇。灵活就业人员以个人身份参保。职工医保的保费的范围通常是上年度本市职工平均工资的60%~300%,一般是上千元。该医保会建立个人医保账户,每月可注入医保金,年龄不同,注入比例也不一样,可以去药房买药、门诊看病等。
城乡居民医保的所有保费均由个人承担,费用一年一缴。居民需要每年下半年到当地社区或村委会办理接下来的参保手续,即可在次年继续参保。保费通常是定额或者按当地人均可支配收入的一定比例收取,通常一两百元。城乡居民医保没有个人账户,社保卡也没有医保金的注入。
(三)关于异地结算、报销的政策
城镇居民医疗保险在异地可以报销,但是需要满足三个条件:在参保地按时参保并在待遇享受期内,在参保地领取社会保障卡并激活,在参保地进行异地就医备案。因此要求较为复杂严格。新型农村合作医疗保险需要经过参保地批准,携带相关证明,才能到指定报销医院的医保结算窗口进行报销。而城乡医保制度统一后,异地就医的住院费用直接结算,并且还实现持卡结算功能,还能参与跨省报销。
二、数据来源
本文数据来自中国健康与养老追踪调查(China Health and Retirement Longitudinal Survey,CHARLS),此项调查是由北大国家发展研究院主持、北大中国社会科学调查中心与北大校团委共同开展的大型调查项目。项目范围包括28个省(自治区、直辖市)的150个县、450个社区(村)。调查内容包括个人基本信息、家庭结构和经济支持,健康状况、体格测量,医疗服务利用和医疗保险,工作、退休和养老金,收入、消费与资产,以及社区基本情况等。
CHARLS收集了一套代表中国45岁及以上中老年人家庭和个人的高质量微观数据,给本研究提供了极大的便利。更重要的是,在CHARLS有关参合医保类型的调研问卷中,有专门针对“居民医保”(即新农合、城居保合并后的医疗保险)的问题,对于研究城乡医保一体化制度提供了直接、便利的数据支持。因此,本研究通过在CHARLS数据库中选取2015、2018年的相关数据开展。使用这两期数据的原因是,在2016年国务院印发《关于整合城乡居民基本医疗保险制度的意见》之前,一体化政策只是在一些地方进行试点,随后才开始推行全国范围内的改革。所以,选取该节点前后的数据便于进行对比分析。
三、城乡医保并轨对居民医疗负担的影响
(一)模型说明
在衡量居民的医疗负担时,我们选择了过去1年居民自付医疗费用比例、过去1年居民自付医疗费用对数值和预期的贫困脆弱性(VEP)作为衡量指标。前两个指标由CHARLS数据库直接计算得出,第三个指标即预期的贫困脆弱性(VEP)的模型构建如下。
贫困和脆弱性是一枚硬币的两面。贫困是对居民家庭福利状况的事后反映,表明了居民家庭缺乏必要生活资料的状态;脆弱性是对未来居民家庭福利状况的事前预测,估计了福利水平在未来经历损失的概率。对脆弱性的预测可以很好地衡量政策对社会福利水平的影响,从而引导政策调整以降低未来的贫困发生率。因此,将贫困和脆弱性两个高度相关又存在差别的概念结合在一起,得出了贫困脆弱性(Vulnerability to Poverty)的概念。
预期的贫困脆弱性(Vulnerability as Expected Poverty,VEP)是指个人或家庭在将来陷入贫困的可能性。Chaudhuri等给出的预期的贫困脆弱性的定义式为:
V
,=E
[p
,,+1(c
,+1)∣F
(c
,+1)](1)
其中V表示在t时期家庭h的贫困脆弱性,c表示家庭h在t+1时期的收入水平或者消费水平,在本文中我们将其看作收入水平,p(c)表示贫困指标,在本文中使用贫困评估中最常用的FGT(Foster-Greer-Thorbecke)贫困指数(Foster等,1984),F(·)表示累积分布函数。
FGT贫困指数构建如下:

(2)
其中,z是一条提前确定的贫困线,α取整数,当α=0时贫困指数表示贫困发生率,α=1时贫困指数表示贫困的深度,α=2时贫困指数表示贫困的强度,在本文中取α=0。
将式(2)代入式(1)中,得到本文贫困脆弱性的定义式:
V
,=E
[p
,,+1(c
,+1)|F
(c
,+1)]

(3)
确定收入水平的分布。Chaudhuri对印度尼西亚贫困脆弱性的研究,Christiaensen和Subbarao对肯尼亚农村家庭贫困脆弱性的研究,都对收入水平作了符合对数正态分布的假设。本文的研究对象主要是45岁及以上中老年人,样本平均年龄在55岁以上,属于中低收入水平人群。根据Singh和Maddala的研究,对低收入人群的收入分布,最适合的分布假设是对数正态分布。基于以上考虑,本文使用对数正态分布来拟合家庭未来收入。
用回归的方法估计家庭未来收入的均值和方差。在任何一个时期,一个家庭的收入(消费)水平受多种因素影响,因而很难找到一个可行的理想模型将所有可能的影响因素完全包含在内。参考Chaudhuri给出了的相对简化的模型,结合CHARLS数据库包含的变量数据,本文构建以下模型来预测未来收入:
lnC=Xβ+e
(4)
其中,C为预期收入,X表示影响家户收入的一系列控制变量,e为扰动项。由此也可以得出未来收入的预测均值为:

(5)

e
=X
θ
+ε
(6)
由此得出未来收入方差的预测值:

(7)
由于我们将未来收入水平作了符合对数正态分布的假设,因此将式(5)和式(7)所得均值和方差代入式(3)中,可以用正态分布累计密度函数得出样本的贫困脆弱性为:


(8)
其中,z表示为贫困标准线。本文采用世界银行提出的1.9美元/天作为贫困标准。以样本采集年份的平均美元汇率计算,2015年的贫困标准线为4 320元/年,2018年的贫困标准线为4 600元/年。
DID回归模型的构建如下:
Y
=β
+β
*Year
*Treat
+β
*Year
+β
*Treat
+θX
+η
(9)
其中,Y为因变量,即个人过去1年自付费用比例、过去1年自付医疗费用的对数值和贫困脆弱性,Year为时间虚拟变量(2015年取值为0,2018年取值为1),Treat为分组虚拟变量(实验组取值为1,对照组取值为0),X表示控制变量,η表示期望为零的随机扰动。根据DID模型,交互项的回归系数β是我们关注的核心结果,代表了医保并轨对居民就医负担的影响方式及效果。
(二)数据与变量
在衡量居民医疗负担时,个人支付的医疗费用和报销比例是重要指标,因此我们对CHARLS数据库进行处理,得到个人过去1年医疗总费用、过去1年自付医疗费用,并以此计算出过去1年自付费用比例和过去1年自付医疗费用的对数值,作为因变量。同时,在计算贫困脆弱性时,由CHARLS数据库得到个人过去1年总收入,并计算得出每个样本的贫困脆弱性预测值,作为因变量。在解释变量侧,除了DID模型本身的核心变量,我们还加入了年龄、性别、婚姻、教育、有无残疾、有无慢性病、过去一年有无重大事故、是否吸烟等个人特征的控制变量,和家中有无马桶、有无自来水、能否淋浴等家庭特征的控制变量。
在CHARLS数据库中,我们整合了2015和2018两期数据,并通过对解释或被解释变量缺失的样本数据的删除等手段,将数据从17 795个缩减至1 509个,其中对照组2015年样本量325,2018年样本量996;实验组2015年样本量18,2018年样本量170。具体变量的描述性分析如表1。
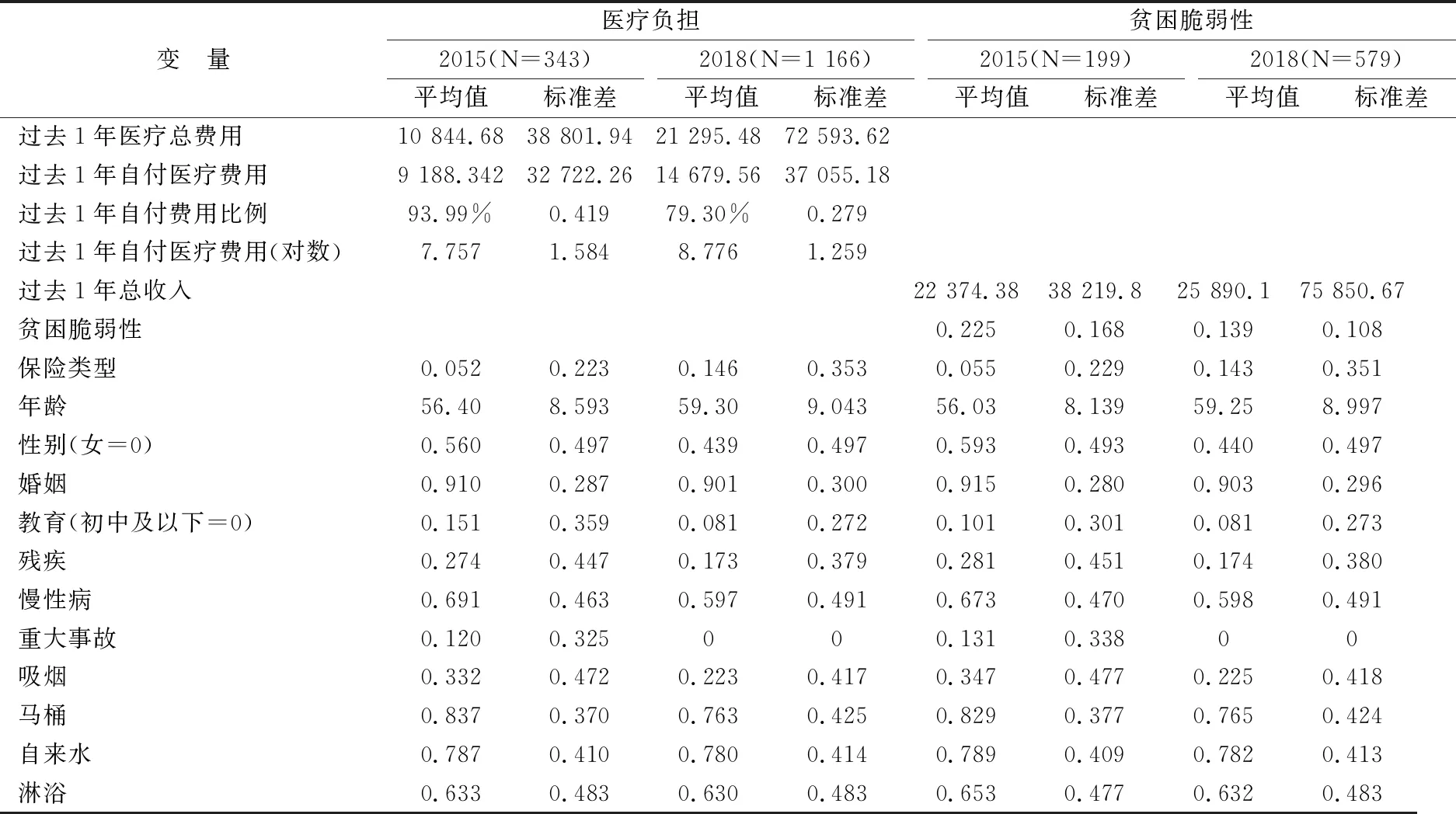
表1 医疗负担研究描述性分析
(三)均值双重差分
按照DID的基本定义,我们针对过去一年自付费用比例、过去一年自付医疗费用(对数)以及贫困脆弱性进行均值双重差分,得到结果如表2所示。

表2 医疗负担均值DID结果
从其结果来看,对于自付费用比例、自付医疗费用(对数)及贫困脆弱性,均值DID都表现出了一致的负向作用,因此,这样的表现较为符合我们的预期判断。但我们知道,均值双重差分方法仅提供定性的参考,其中并没有严格的统计学检验及其余因素等的控制。因此,为了更好地研究城乡医保并轨对居民医疗负担及减贫带来的影响,我们需要进一步操作DID回归。
(四)DID回归
应用DID回归模型对城乡医保并轨给居民医疗负担带来的影响进行辨别。我们在模型中加入实验虚拟(treated)变量,用以区分对照组和实验组;加入时间虚拟(post)变量,用以区分时间的不同,即政策前和政策后;并将二者相乘构建交互项,其系数是DID衡量的关注重点,表示该城乡医保一体化政策本身对指标的影响效果。
在基础模型之上,我们还加入了年龄、性别、婚姻、教育、有无残疾、有无慢性病、过去一年有无重大事故、是否吸烟等个人特征的控制变量,以及家中有无马桶、有无自来水、能否淋浴等家庭特征的控制变量。
DID回归的结果如表3所示,表格中第一个变量DID即代表所研究的政策效果。因此可知,城乡医保并轨政策对于过去一年自付费用比例、贫困脆弱性产生了显著影响,而对过去一年自付医疗费用(对数)没有显著影响。从具体数据来说,城乡医保并轨政策显著降低了过去一年自付费用比例,降低约0.235 1的比例;显著降低了贫困脆弱性,降低了约0.046 1。
总体来看,DID回归的结果和前面的均值双重差分的结果较为类似,过去一年自付费用比例、过去一年自付医疗费用(对数)和贫困脆弱性所对应的DID值均为负,在这之中,过去一年自付费用比例、贫困脆弱性这两个变量的DID值显著。故此,城乡医疗并轨政策对自付费用的比例和贫困脆弱性等两个方面的影响,对于居民来说降低了医疗负担、有显著的减贫良性作用。过去一年自付医疗费用(对数)变量对应的DID值也为负,同样是倾向于降低医疗负担的良性作用,但并不显著。

表3 医疗负担DID回归结果
(五)结果分析
回归结果显示,过去一年自付费用比例、贫困脆弱性两个变量都受到城乡医保并轨政策的显著影响而降低,而过去一年自付医疗费用(对数)虽然也有降低但影响并不显著。其可能的原因在于:
城乡医保改革前后,医疗保险的报销比例和范围产生了较大的变化。例如,新农合的报销力度总体来说是较低的,城乡医保一体化使得报销比例有较大提高;而且城乡医保并轨后,异地报销也变得非常便捷。因此,虽然就医行为的选择也会发生一些变化,但总体的结果仍会表现为自付费用比例显著降低。对于贫困脆弱性显著降低的分析,我们从自付医疗费用比例及自付医疗费用均降低两个方面可以得出其合理性,城乡医保并轨政策使得居民的医疗负担降低,减贫效果显著。
而自付医疗费用的降低效果并不显著,我们认为可能有以下原因。其一,在城乡医保并轨政策下,若不考虑报销则居民花费了更多的医疗费用,而实际由于报销比例的增大,居民自付的医疗费用会有所降低,但两者共同作用出现的结果是影响并不显著。其二,我们前期所进行的“城乡医保并轨对医疗行为的影响”的研究结果显示,门诊和住院的费用类变量均不显著,而次数类变量则受到显著影响,可能的原因是次数更能代表人们对医疗资源利用的真实态度和习惯,而费用类变量的影响因素过多,且波动性过大,会受到每一次具体病情严重程度、医生诊断、检查过程等复杂过程产生的噪声影响,而在我们的模型中这些噪声没有得到很好的消除,因此费用类变量不显著也在情理之中。整体的医疗费用水平如果有所上升,也可能出现这样自付费用降低并不显著的结果。同时个人自我治疗的费用虽然出现显著,但多是农村居民自己到药店、诊所等地方自行买药的情况,病情不是很严重,单次费用的额度范围整体不大,费用的波动也就会远小于门诊及住院的费用变化。因此总体而言,个人自付医疗费用的降低并不显著。
四、政策建议
通过上述实证研究,我们提出如下建议:首先,要提高医保费用报销比例,扩大报销范围,优化报销流程,提高整体的报销力度,以达到降低医疗负担的作用。其次,适当地控制整体医疗费用支出标准和水平,防止出现因报销力度加大或居民就医增多而造成的医疗费用水平大幅上涨情况。再次,可以引入更复杂的衡量模型,将那些低收入的居民在已有基础上再提高医保报销比例,以更好地发挥医保的减贫作用。
