基于神经网络的多光谱信息融合的树种识别算法研究
2021-10-10高振宇吴增明李俊鹏
高振宇,吴增明,李俊鹏
(1.云南电网有限责任公司,云南昆明 650000;2.云南电网有限责任公司 带电作业分公司,云南昆明 650011)
为了保持生态平衡,维护人们赖以生存的地球,国家大力提倡植树造林工程建设,种类丰富的树木被广泛种植。植树造林可以抑制水土流失、抵御风沙,改善生态环境[1]。随着被种植的经济林陆续进入成熟期,需对树木种类识别,以保证树木的高效利用[2]。不同树木种类的利用价值各有不同,如何正确识别树种是一项非常重要的工作,传统的识别方法通过木材的风格特征进行识别,利用木材的宏观特征、微观特征对不同树种进行测算,识别不同风格特征的树种种类,充分发挥木材的经济价值[3]。
绿色森林不仅可以绿化家园,还可有效维持生态平衡,促进森林资源的可持续发展,对社会经济的发展具有重要意义[4]。随着树木种植面积的不断增加,为了更好地保护森林资源,应加强树种识别工作的效率。传统树种识别方法主要依靠人工实地调查,根据木材的风格特征进行判断,在人对木材风格特征的主观判断的基础上,实现对树种的识别[5]。这种定性识别木材的方式不仅浪费大量人力物力,而且识别耗费时间较长,无法满足高效率识别要求,还存在一定的误差。随着种植树种的种类快速增加,现阶段无法实现木材树种的自动识别。因此,文中提出基于神经网络的多光谱信息融合的树种识别算法,对树种进行识别。
1 基于神经网络的多光谱信息融合识别原理
神经网络是一种多层神经网络,其结构如图1所示。

图1 神经网络结构图
神经网络算法是运用导师学习算法,在学习过程中通过正向传播和反向传播实现。正向传播负责网络计算,根据输入参数求出结果;反向传播负责逐层传递误差,修改网络权重,用于网络的正确识别,训练完成后识别则只需正向传播[6-9]。多光谱信息融合识别模型如图2 所示。

图2 多光谱信息融合识别模型
神经网络各并行子网输出,通过与训练输出的差值进行误差识别,对训练输出识别误差值进行比较,计算后得出识别概率。运用神经网络子网的识别结果,作为D-S 理论后级推理的证据源,从而对同一目标进行多周期证据融合[10-12]。设识别框架为:
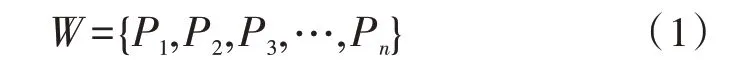
神经网络子网能够实现对树种的识别,并行子网数量为S,训练输出组合成的向量为:
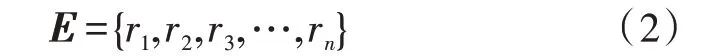
目标特征向量序列为{t1,t2,t3,…,tn},神经网络子网识别输出组合的S维向量为:

设其中一个中间变量为X,可表示为:

神经网络子网i对树种识别概率为:

将数据变换后的输出记作:
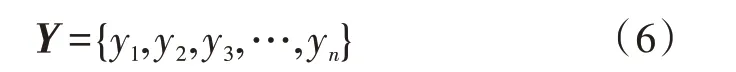
该变换公式为:

式中,向量y表示待识别树种对整个识别过程的归一化隶属度,其值能够满足赋值基本要求。将该向量时间序列作为证据递归到组合之中,形成多光谱信息融合推理,并输出全部融合结果[13]。
2 树种识别算法实现
2.1 关键点提取
1)枝下高提取
树木分为主干和树枝,测量时以枝下高位置作为树木主干与树冠的分割点,对枝下高进行测量。枝下高即为树木的主干高度,正常树木的枝干一般高度大约在1.3 m以上分叉,因此枝下高应大于1.3 m。测量时要对每棵树不同高度处树干的干径和重心位置进行测量,以每棵树的点云中取出该树从1.3 m 至最高处的点云[14-15]。在以1.3 m 处开始对点云数据进行水平分层,单层厚度为10 cm,采用Hough 变换和圆拟合的方法,求出这层树干的圆心和半径。以获取的圆心进行半径的提取,在2r范围内将点云数据体元化,以体元尺寸5 cm×5 cm× 10 cm 为标准,如果体元内回波点个数n>2,则表示该体元被覆盖。如此循环遍历所有层,从而得到各层的覆盖体元个数,作为树干处垂直剖面[16]。由于树干处点云分布比较集中,而且各层的覆盖度变化不大,直到枝下高处覆盖度才会明显变大,因此,根据树木枝干的分布特点,可以得到枝下高的准确位置。
2)冠高提取
树冠高的提取较为简单,在提取冠高时以树冠顶端到树冠最低端间的竖直距离作为树冠高。由于传统测量方法中对冠高的测量,很难分辨树冠最低端的位置,尤其在冠层底层树枝分布杂乱的情况下,不仅浪费大量的时间,还会出现测量误差。因此,利用地面激光雷达对树木的点云进行三维检视,这种检视方法既可以解决枝叶间互相遮挡的问题,又能实现快速寻找树冠最低端,准确地提取冠层部分点云,节约了人力物力,提高了树冠提取的精准性。
3)树高提取
在完整树种识别数据中,树木顶部是坐标系中的最大值,数据底部是坐标系中的最小值,两者之间的差值是树高。枝下高、冠高、树高的关系如图3所示。
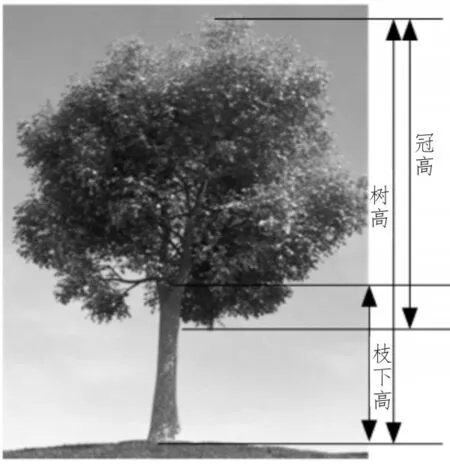
图3 枝下高、冠高、树高的关系
2.2 树种识别算法流程设计
根据上述提取的关键点,设计树种识别算法流程,如图4 所示。
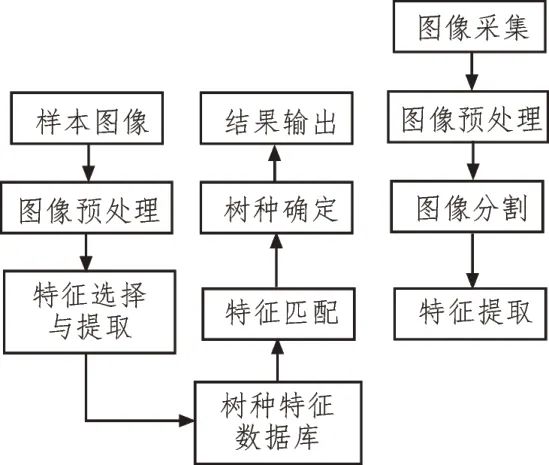
图4 树种识别算法流程
由图4 可知,对于树种识别,需先采用雷达设备以圆形为基础扫描该区域全部树木,获取相关图像。然后对图像预处理和分割,从中提取相关树种特征,实现特征匹配。通过提取相关样本图像,并进行一系列处理,从中提取样本特征,并存储到树种特征数据库中,再次进行特征匹配。通过匹配结果可确定树种,由此输出树种识别及结果。
3 实验分析
为了验证基于神经网络的多光谱信息融合的树种识别算法研究的合理性,进行实验验证分析。
3.1 实验环境
在Win7 操作系统下进行实验分析,系统开发使用工具是Eclipse,系统数据库为手机自带的SQLite数据库。
3.2 实验数据获取与处理
在云南地区选取树木,利用FARO photon 型号的地面激光雷达对该区域进行扫描,如图5 所示。

图5 FARO photon型号的地面激光雷达
对该区域树木进行多次扫描,在立体视图中删除多余噪点。该雷达相关参数设置如表1 所示。

表1 雷达相关参数设置
3.3 树木数据提取
在树干高处朝南或朝北方向贴标识,并在样本树木周期均匀防止参考求,以此作为基站,可对树木进行全面扫描。选取扫描区域为一个圆形,每隔10 min 扫描一次,具体扫描结果如图6 所示。

图6 扫描结果
在3D 模式下,选取单木数据,剔除多余数据。依据该扫描结果可看出3 种树木的特征,如表2 所示。

表2 树木特征
3.4 实验结果分析
基于上述内容,分别采用传统算法与神经网络的多光谱信息融合识别算法对3 种树木进行识别,识别结果如图7 所示。

图7 不同算法识别精准度对比
由图7 可知,采用传统算法对桉树识别时,识别精准度最高为60%,对橡胶树识别时,识别精准度最低为9%;采用所研究算法对橡胶树识别时,识别精准度最高为98%,对竹子识别时,识别精准度最低为82%。由此可知,基于神经网络的多光谱信息融合的树种识别算法识别精准度较高。
4 结束语
随着森林资源的不断扩大,开展树种识别可以有效地促进树木的生存发展,利用神经网络的多光谱信息融合识别算法进行树种识别,改善了传统识别方法存在的时间长、效率低的缺点,实现了快速准确地识别树木种类,避免浪费大量的人力物力,有效节约经济成本,促进森林资源可持续发展。
