基于YOLOV3优化模型的复杂场景下茶树嫩芽识别
2021-10-09张晴晴刘连忠宁井铭吴国栋江朝晖李孟杰李栋梁
张晴晴,刘连忠,*,宁井铭,吴国栋,江朝晖,李孟杰,李栋梁
(1.安徽农业大学 信息与计算机学院,安徽 合肥 230036; 2.安徽农业大学 茶与食品科技学院,安徽 合肥 230036; 3.茶树生物学与资源利用国家重点实验室,安徽 合肥 230036)
中国是茶叶的原产地,也是最早发现和利用茶叶的国家。茶叶中含有的微量元素和有机化合物不仅可以提神止渴,长期饮用对于软化血管、降低消化道疾病发病率也有帮助[1]。茶叶出口是我国对外贸易的重要组成部分,但茶叶的单位产值却与其他国家有一定差距[2]。目前,采茶的方式主要分为人工采茶和机械采茶[3-5]两种。人工采茶虽然能够准确地对茶叶嫩芽进行采摘,但是费时耗力,劳动成本高。机器采茶解决了人工采茶速度慢的问题,提高了采茶效率,但不能精确地识别嫩芽与老叶,所采茶叶的品质不高,迫切需要研究茶树嫩芽的智能识别技术[6]。
为了实现茶树嫩芽的智能化采摘,基于机器视觉的茶树嫩芽检测与识别成为当前的研究热点。唐仙等[7]研究了传统方法下的茶树嫩芽分割,利用数码相机采集茶叶图像,基于阈值分割法进行嫩芽分割,比较了多种阈值分割法的优劣。汪建[8]结合颜色距离和边缘距离对自然条件下茶树嫩芽的分割,实验能较好地保存嫩芽的轮廓信息。传统分割算法较低的泛化能力,对于光照、拍摄角度、背景的要求较高,复杂背景下茶树嫩叶的精确识别与定位效果并不理想。自2014年Girshick等[9]首先使用R-CNN网络进行目标识别,基于深度学习的目标检测算法迅速发展[10-11],相继出现了Fast R-CNN、Faster R-CNN等目标检测模型[12-15],以及YOLO(You Only Look Once)[16]、SSD(Single Shot MultiBox Detector)[17]等优化算法,并在农业领域得到应用[18-19]。在茶树嫩芽识别方面,Yan等[20]基于传统BP神经网络和支持向量机进行6个龙井茶叶品种的识别,改进后的BP神经网络达到较好的识别效果。吕军等[21]提出一种基于AlexNet卷积神经网络的茶树嫩芽识别方法,能够有效识别自然环境下茶树嫩芽的状态。孙肖肖等[22]通过超绿特征和OSTU算法对复杂背景下的茶树嫩芽图像进行分割,使得嫩芽区域更加明显,并采用YOLO算法进行嫩芽图像检测,达到较高的检测精度。以上研究,为复杂背景下茶树嫩芽智能采摘设备的研究提供了基础。
本文以YOLOV3模型[23]为基本框架展开茶树嫩芽的识别研究,并对该模型的网络结构进行优化,以实现复杂场景下茶树嫩芽的快速、准确识别。
1 材料与方法
1.1 实验材料
实验茶园位于安徽农业大学农业科技园,茶园长10 m、宽5 m,共种植四排茶树,故将茶园划分为4行、10列共40个监测区域,每个监测区域大小为1 m×1.25 m。实验使用的图像采集设备采用可变焦云台摄像机,由天津天地伟业公司生产,型号为TC-H556S,主码流分辨率为2 048 pixel×1 536 pixel,32倍光学变焦,水平0°~360°旋转,垂直-16°~90°转动,最大帧率60 frame·s-1。图像采集软件为自主研发[24],通过控制摄像机转动和变焦近距离抓拍茶树图像。实验于2019年3月中下旬至4月中旬进行,以生长良好的茶树为识别对象,每天5:00至18:00,间隔1 h采集一次茶树图像,其中包含天气、光照等自然条件下的复杂场景,以及拍摄角度、距离等位置变化。之后对图像数据集进行裁剪,并将图像尺寸统一缩放为416 pixel×416 pixel,选取包含嫩芽的图像区域,用标记工具进行标记,得到相应的XML文件。本实验利用Labelimg图像处理软件对嫩芽位置进行标记。裁剪得到的茶树图像数据集共1 020张,其中训练集900张,验证集100,测试集20张。如图1所示。
实验的硬件环境为Intel Core CPU i7-6700cpu@3.4GHZ,16 GB内存,Nvidia GeForce GTX 1080图形适配器,软件环境为Windows 10操作系统。开发环境为anaconda,开发语言为phython,深度学习框架为tensorflow,使用pycharm进行调试。
1.2 方法
实验的整体流程如图2所示。首先将采集的原始茶树图像裁剪为416 pixel×416 pixel的大小,对图像进行预处理操作消除干扰,并逐一标记图像中嫩芽的位置。然后以标记图像作为输入,对YOLOV3模型进行训练,得到茶树嫩芽识别模型。随后对YOLOV3模型进行改进,使用相同数据集进行训练,得到茶树嫩芽识别优化模型。最后对比分析两种模型的嫩芽识别结果,得出本实验的结论。

图2 实验整体流程图
1.2.1 图像预处理
自然环境下采集的茶树图像极易受天气和光照的影响,可能包括嫩芽本身的形态多样性,光照和天气等不确定因素,以及拍摄角度和距离等复杂场景。为克服光照对识别效果的影响,首先要对原始图像进行预处理,以提高图像的稳定性。
本实验采用中值滤波[25]进行降噪处理,并利用彩色直方图均衡[26]消除光照影响。中值滤波法是一种非线性平滑技术,实验中设置中值滤波的核数大小为5×5,使得降噪处理后引起的模糊效应较低。通过彩色直方图均衡处理增强图像对比度,具体做法是将R、G、B三通道图像生成对应的直方图,对每个通道进行直方图均衡处理,再将处理后的三通道合并为RGB彩色图像。采用彩色直方图均衡方法对图像进行调整,对于背景或者目标亮度过高的图像,调整后图像的颜色和亮度分布较为均匀,并可以有效增强局部对比度。另外,通过采集不同光照条件下的嫩芽图像对模型进行训练,可大大改善识别模型对光照的稳健性。图像预处理前后的对比效果如图3所示。经预处理后,图像更为平滑,图像中的嫩芽也更为突出。
除了图像预处理操作,还需采集上述复杂场景下的嫩芽数据集对模型进行训练,从而有效克服复杂场景的影响。
1.2.2 YOLOV3模型
YOLO模型是基于单个卷积神经网络的学习模型。卷积神经网络是能够进行深度学习的多层神经网络,由输入层、卷积层、池化层、全连接层和输出层组成。YOLOV3模型是YOLO算法经过YOLOV1、YOLOV2的改进模型,使用卷积和残差组合连接,通过调整卷积的步长实现降采样,并在主干网络之后添加不同尺度的检测输出,使得目标特征提取的准确性和模型的泛化能力得到很大提高。YOLOV3使用darknet-53前面的52层,它没有全连接层,而是增加不同尺度的融合输出,并使用数据集对网络进行预训练。YOLOV3使用3种特征图(13×13、26×26、52×52),3种感受野(大、中、小),9种先验框(116×90、156×198、373×326、30×61、62×45、59×119、10×13、16×30、33×23)进行多尺度检测,能够更好地适应检测对象大小的变化。
YOLOV3算法首先将一幅图像划分成S×S个网格,每个网格预测若干个预测框(bounding box),每个预测框均得到一个目标图像的预测信息(x,y,w,h,c),其中x、y为检测框中心点的像素坐标,w、h为检测框的宽度和高度,c为目标物体的置信度(confidence)。置信度的计算公式为
c=Pr(o)×IoU。
(1)
Pr(o)为目标落在网格中的概率,如果有目标落在其中划分的一个网格里,则值为 1,没有目标则为0。IoU(intersection over union)为交并比,即预测框和真实框的交集和并集的比值。如果待检测目标的中心落在某一个划分网格中,这个网格就对该目标进行预测。根据每个网格最终置信度的得分,使用极大值抑制算法NMS(non-maximum suppression)将低于设定阈值的检测框排除,从而得到最终的目标检测框。
1.2.3 YOLOV3优化模型
由于茶树嫩芽萌发的先后次序不同,相机距离目标的远近也不同,导致其图像中嫩芽的大小存在明显的差异。当待检测图像中检测目标的大小差异很大时,YOLO3模型的检测精度将明显降低。YOLOV3优化模型借鉴深度学习中的空间金字塔(spatial pyramid)[27]思想,考虑将待检测目标的局部特征与全局特征加以融合,以改善特征图对目标的表达能力,从而更准确地检测大小差异较大的目标,提升检测精度。
YOLOV3优化模型是以YOLOV3模型为基本结构,在YOLOV3网络结构的第一级检测之前增加一个SPP(spatial pyramid pooling)[28]模块,采用尺寸为 5×5、9×9、13×13的最大池化和一个连接组成,然后经过concat拼接输入下一层网络。利用SPP模块实现了局部特征和全局特征的融合,特征图经过局部特征与全局特征相融合后,丰富了特征图的表达能力,有利于识别待检测图像中目标特征差异较大的情况,提高了网络模型识别的泛化能力,并且对于较小物体的识别具有更高的检测精度,对不同尺寸的输入图像也可以应用到模型训练与识别检测。
YOLOV3优化模型的网络结构如图4。input为输入层,CONV为卷积层,conv+res模块是多层卷积组件和多个残差模块的组合,res为残差(Residual)模块,up Sam为上采样,concat为拼接操作。首先对输入图像进行卷积和残差操作,在三个不同卷积操作尺寸下分别进行检测输出。在卷积操作中,通过改变卷积核的步长来改变张量的尺寸,从而获得不同尺度的特征图。残差操作通过包含多个残差单元的残差模块完成,用于获取更多低层小目标的位置信息,通过不同的残差模块分三级进行输出。Scale1为13×13特征的输出,Scale2为经过上采样操作将13×13与26×26特征融合而成的输出,Scale3为经过上采样操作将13×13、26×26与52×52特征进行融合,形成最终的输出。增加SPP模块后得到的YOLOV3优化模型,其图像尺寸不变性得到提高,图像的过拟合现象也大大降低。
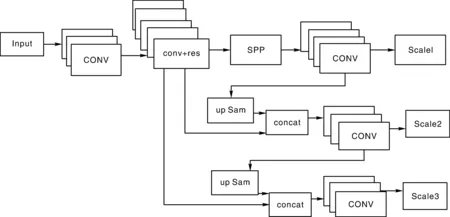
图4 YOLOV3优化模型的网络结构
2 结果与讨论
2.1 结果
模型的性能采用精度(P)和召回率(R)两个指标进行衡量[29]。精度P、召回率R的定义为:
P=VTP/(VTP+VFP);
(2)
R=VTP/(VTP+VFN)。
(3)
式(2)、(3)中:VTP为正类判定为正类的数量,VFP为负类判定为正类的数量,VFN为正类判定为负类的数量。精度P表示样本中被正确判定为正例占预测为正例的比例,召回率R表示样本中被正确判定为正例占实际为正例的比例。对于深度学习网络模型,通常采用平均精度均值(mean average precision,mAP)作为检测精度的指标[30],即先计算每一类的平均精度(average precision,AP),然后再计算所有类的平均精度AP的均值。由于本实验中只有茶树嫩芽一个类别,所以mAP值即为AP值。
使用训练数据集分别对YOLOV3模型和YOLOV3优化模型进行训练,在训练过程中每隔1万次输出一次权值文件(weights),本实验模型阈值取为0.5。经过10万次训练,得到的两个模型的mAP和R值,结果如图5所示。
从图5可以看出,随着训练次数的增加,YOLOV3模型的mAP呈现先上升、后下降的趋势,在5万次左右达到最优87.5%,最后稳定于85.8%;YOLOV3优化模型的mAP随着训练次数的增加呈现波动上升趋势,在8万次左右达到最优91%,最后位于89.5%。选择最高的mAP值的权值文件作为本模型实验验证,YOLOV3的mAP为87.5%,优化模型的mAP达到91%,提高了3.5%。由于模型出现过拟合的原因,随着训练次数的增加,在9万次之后两者的mAP均有所降低。两种模型的性能对比如表1所示。YOLOV3的召回率R为71%,优化模型的召回率R为75%,较优化前提高了4%。使用测试集对模型的时间性能进行比较,YOLOV3每张图像的平均检测时间为0.375 5 s,而优化模型的平均检测时间为0.387 2 s,较优化前时间开销增加0.011 7 s,这是因为优化后的网络复杂度增加,导致检测时间稍有增加。综合来看,YOLOV3模型经优化后,平均精度均值mAP和召回率R均有一定提高,表明YOLOV3优化模型比YOLOV3模型更适合用于茶树嫩芽的识别。

表1 两种模型的性能对比
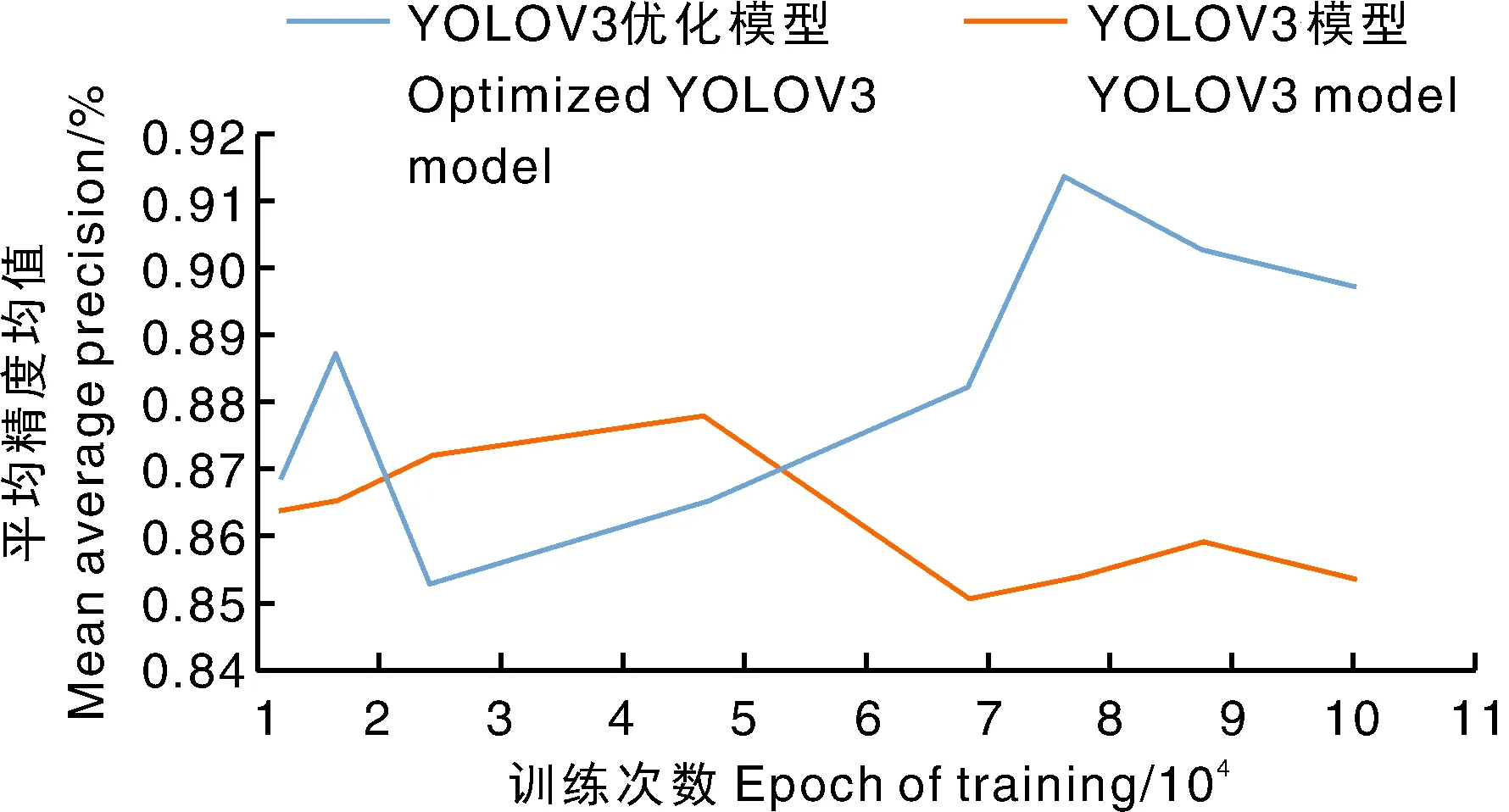
图5 两种模型的mAP值随训练次数的变化曲线
2.2 讨论
从实际应用来看,嫩芽大小和数量的不同,拍摄距离和角度的变化,以及自然场景下光照的干扰,都会导致采集的原始图像有很大的波动,从而对模型的识别结果产生影响。下面通过几个实例,讨论分析两种模型在不同场景下的识别结果。
图6为在不同嫩芽数量下两种模型的识别结果。对于含有较少嫩芽的图像,两个神经网络模型均能检测出茶树嫩芽,且准确率均较高。而对于含有较多嫩芽,可以看到图像底部的一个嫩芽没有被YOLOV3模型检测到,而能被YOLOV3优化模型检测到,其原因是该嫩芽目标较小,说明改进后的YOLOV3优化模型对于多个目标中的小目标的识别性能有较大提升。

图6 两种模型在不同嫩芽数量的识别结果
图7为在不同的光照条件下两种模型的识别结果。光照均匀的情况下,两种模型均有较好的识别结果;在强光照射的情况下,嫩芽区域的亮度发生明显变化,两种模型均未能识别出图像下方的一个嫩芽,原因可能是不同光照条件下的训练样本不足导致模型的适应性下降。

图7 两种模型在不同光照条件下的识别结果
图8为两种模型在不同的拍摄角度下的识别结果。对于正面和侧面拍摄角度,两种模型都能够很好地识别到嫩芽目标,嫩芽的大小和位置也较为准确,表明不同拍摄角度对于模型的识别影响较小。这是因为采集的茶树图像样本数量较多,涵盖了多种角度的嫩芽图像。

图8 两种模型在不同拍摄角度下的识别结果
3 小结
为了解决复杂背景下茶树嫩芽的精准识别问题,本文基于卷积神经网络的YOLOV3模型进行研究,并通过增加一个SPP模块对YOLOV3模型进行优化,提高模型对小目标的识别能力。实验结果表明,YOLOV3优化模型识别茶树嫩芽的平均精度均值mAP为91%,召回率R为75%,比YOLOV3模型的87.5%、71% 均有一定提高,每张图像的平均检测时间为0.387 2 s,比YOLOV3模型的检测时间0.375 5 s稍有增加。综合来看,YOLOV3优化模型更适合用于茶树嫩芽的识别。
YOLOV3优化模型能够更准确地识别图像中较小的嫩芽,对拍摄角度也表现出较高的鲁棒性,并且保持了YOLOV3模型的良好时间性能,但抗强光干扰的能力不理想。当茶树冠层中可能出现与嫩芽相似的其他作物或有杂草时,需考虑增加这类样本来增强模型的抗干扰能力。另外,本文也没有研究不同茶树品种对识别结果的影响。下一步将从提高数据集的丰富性和多样性入手,扩充强光环境下的训练样本,增加不同茶树品种的训练集,从而提高模型的抗干扰和泛化能力,使其更适于复杂环境下不同茶树品种的嫩芽识别。
