面向术语知识库编纂的专用语料库设计
2021-10-08卢华国张雅
卢华国 张雅

摘 要:术语信息的多样化需求对术语数据来源提出了新要求,专用语料库在术语知识库编纂中发挥了愈益重要的作用。文章以气象学科为例,通过与通用语料库比较,从类型定位、语料规模、语料选择和语料加工四方面明确了如何设计面向术语知识库编纂的专用语料库。
关键词:术语信息;术语数据;术语知识库;专用语料库
中图分类号:H083 文献标识码:A DOI:10.12339/j.issn.1673-8578.2021.04.002
Designing Specialized Corpora for Compiling Terminological Knowledge Bases//LU Huaguo, ZHANG Ya
Abstract: Due to the diversified needs of terminological information, new requirements are put forward for the sources of terminological data, and specialized corpora play an increasingly important role in the compilation of terminological knowledge bases. Using meteorology as an example and making a comparison with general corpora, this paper discusses how to design a special corpus for term knowledge base compilation from the following four aspects: corpus classification, text size, text selection, and text processing.
Keywords: terminological information; terminological data; terminological knowledge base; specialized corpora
收稿日期:2021-05-17 修回日期:2021-06-04
基金项目:江苏高校哲学社会科学研究项目“英汉学习词典中多义词认知表征及习得效果研究”(2020SJA0193) ;国家语言文字工作委员会汉语辞书研究中心开放课题“基于描写术语学的英汉专科学习词典语境化设计研究”(CSZX-YB-202013)
引言
为了提高语言内部或语言之间专业交际的效率,术语学家借助术语标准化来消除专业语言中的歧义,其工作原则构成了普通术语学的基本理念[1],其实践成果主要表现为术语库。自20世纪90年代开始,伴随着术语学研究的描写转向[2-4],术语库的宏观和微观结构也发生了显著的变化,不再只是以规范为导向的单语或双语术语集,已经转变为兼具专门用途语言描写的术语知识库。具体讲,收录的术语拓展至名词以外的其他词性;除了种-属和部分-整体等层级概念关系,功能、因果、处所等联想关系日益受到重视;术语的语言维度已然进入编纂者的视野,对句法、搭配以及近义、派生等聚合关系的描写在一定程度上模糊了术语与词语之间的界限。西班牙格拉纳达大学以框架术语学为依托,编纂了生态词库(EcoLexicon)[5],加拿大魁北克学派借鉴词汇语义学相关理论,编纂了环境词库(DiCoEnviro)[6],二者可以看作是描写范式下的术语知识库的代表。
术语知识库多样化的信息类型对数据获取提出了新要求,对内省和文档阅读等传统数据获取方式提出了新挑战。语料库大大突破了编者能够阅读的文档数量,弥补了编者在专业知识储备和外语语感方面的不足,语料库工具的使用又能显著提高数据获取的效率。因此,语料库在术语知识库编纂中发挥了不可或缺的作用。然而,笔者发现鲜有研究系统梳理面向术语知识库编纂的语料库与一般用途的语料库在设计上的共性和差异。一般认为,目的性、代表性和可机读性是语料库应该至少满足的三个要求,也是语料库设计中需要重点考虑的三个因素:目的性确定了语料库的类型特征,代表性制约着语料的规模和选择,可机读性则对语料提出了具体的加工要求。本文将以气象学科为例,从语料库设计的类型定位以及语料的规模、选择和处理四方面探讨如何设计面向氣象术语知识库编纂的气象英语语料库。
1 类型定位
不同类型的语料库对语料的规模、选择和处理有着不同的要求。因此,明确气象英语语料库的类型定位是语料库设计的前提。语料库的分类可从多个角度切入:
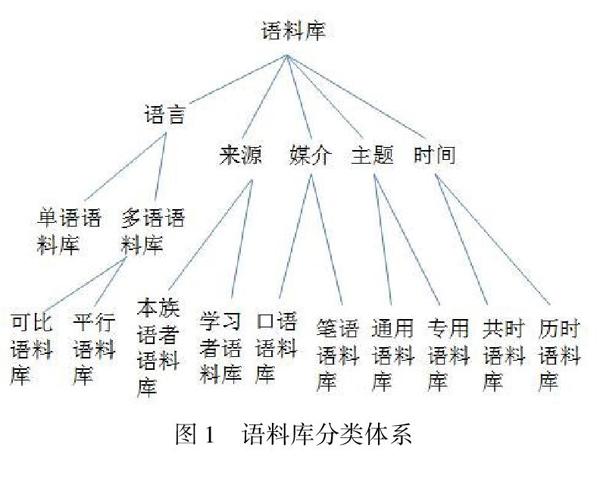
(1)单语语料库和多语语料库。多语语料库根据研究的目的又可以进一步分为平行语料库和可比语料库。在平行语料库中,两种语言的语料相互对应,即一种语言是另外一种语言的译文。在可比语料库中,两种语言的语料的收集虽然参照同一个抽样框架,但二者在内容上并不存在翻译对应关系。
(2)通用语料库和专用语料库。通用语料库广泛采集某种语言的口、笔语形式,取样时尽可能考虑口、笔语的主要社会变体、地域变体、行业变体等各种变异及语言使用的各种场合之间的平衡,力求最好地代表一种语言的全貌。而专用语料库出于某种特定的研究目的,常常只收集某特定领域的语言使用样本。
(3)共时语料库和历时语料库。共时语料库由同一时代(主要是当代)的语言使用样本构成,历时语料库则由不同时代的语言使用样本构成。
(4)本族语语料库和学习者语料库,前者收集的语言使用样本全部源自本族语者,后者的语料则由非本族语学习者语言使用样本构成。
(5)口语语料库和笔语语料库。虽然,在日常生活中,口头交际是最主要的交流方式。但是由于口语语料需要先转写成文本才能由语料库分析软件进行识别和处理,口语语料库的建设需要耗费更多的人力和物力,因而纯粹的口语语料库非常少见[7]4[8]69-74。
综上所述,语料库的分类体系可以用图1表示。
在上述分类体系中,从同一视角对语料库的二元划分只是为了方便讨论,并不能排除两种划分之间的过渡类型。例如,时间跨度只是一个相对的概念,历时语料库和共时语料库之间仅仅存在度的差异,无法截然分开。尽管如此,该分类体系为理解气象英语语料库的类型特征提供了一个可参照的框架。首先,气象英语语料库不关心整个语言的使用情况,仅专注于气象学科,显然应该归于专用语料库,这是气象英语语料库最基本的类型特点。此外,气象英语语料库不以翻译或跨语对比为研究目标。其次,气象英语语料库属单语语料库,仅涉及英语这一种语言,旨在记录和描写气象专业英语的语义/概念或句法特征,所收集的语料源自能够熟练使用英语进行专业交际的气象专家,主要指以英语为母语的气象专业人士,与服务于中介语研究的学习者语料库有着明显的区别。再次,气象交际主要是一种书面语交际,虽然也涉及课堂教学和学术讲座等口头形式,但是本质上属于正式的语体。因此,气象英语语料库可归为笔语语料库。最后,气象英语语料库关注的是当代气象英语的使用情况,并不特别关心气象英语的发展变化,因而本质上属于共时语料库。通过在语料库的整个分类体系中对气象英语语料库进行定位,可以帮助语料库的设计者从宏观上把握其类型特征,为确定语料的规模大小、语料选择的具体标准、语料的加工处理奠定基础。
2 语料规模
语料的规模是指语料库所包含的形符(token)总数(包含多次出现且被重复计入的词),是设计者在语料库建设之初就需要考虑的一个重要方面。20世纪60—70年代,语料的收集主要靠键盘输入和光学扫描,需要耗费大量的时间、人力和资金。受技术水平的限制,能够存储和处理的数据量也非常有限。而现在大部分文本都以电子形式存在,省去了人工输入之苦。就硬件而言,普通的个人电脑已经能够满足语料库建设对海量数据的存储和处理要求。因此,讨论“语料规模需要有多大”比探讨“语料规模能有多大”更有实际意义。
语料规模的大小首先取决于建库的目的。语料库可用于研究语法,也可以用于考察词汇。与词汇相比,语法结构数量少且复现率高,所以用于研究语法特征的语料规模较小。例如,Biber[9]指出1000词的语料就能满足研究英语动词现在时和过去时的需要。用于考察词汇特征的语料规模则需要大很多[10]。由齐普夫定律[11]可知,部分词汇(如and、the)在文本中出现的频率非常高,部分词汇的出现频率却非常低。只有增加语料的规模,才可能增加相对生僻的词汇在语料库中出现的频次。对词典编纂而言,只有当语料库包含的类符总量足够大时,基于语料库产生的词表才能满足词典对收词量的需要,为词典编者提供足够量的索引行作为描写词汇特征的数据基础。Krishnamurthy[12]认为形符量达到1亿的语料库能够满足袖珍词典的编纂需要,但是还不足以用来描写词汇的类连接特征。Atkins和Rundell[8]54指出有时候一个词即使在语料库中出现100次也不足以保证描写词汇特征所需要的确定性(descriptive certainty)。如果被描写的词是多义词,有着复杂的语法结构和丰富的搭配型式,那么语料规模只有成倍增加才能满足编者描写多义词的需要。
语料的规模还与涉及的领域(domain)或主题(topic)的多少和宽窄有关。就通用语料库而言,为了取得平衡的效果,语料往往需要涵盖多个主题,其规模也必然很大。相比之下,“专用语料库往往较小,但是依然能够代表专业语言变体,因为涉及的专业领域越窄,代表该领域所需要的文本数量就越小”[13]408。专用语料库在语料规模方面的这一特点与术语自身的特点是分不开的。首先,与通用词汇比,术语具有专业特殊性(domain-specificity),数量相对少,在专业文本中的分布密集程度高。因此,规模较小的专用语料库也能够满足术语研究对覆盖范围和复现率的要求。其次,由于术语在搭配方面透明度高且规律性强,无需借助对大量语料的频次统计以滤掉那些高度依赖语境的非典型搭配(例如,...went to the graveyard with weeping eyes and hairs 中的轭式搭配weeping eyes and hairs)。最后,在术语中,单义术语占据多数,即使有多义术语,其义项数量与通用语言中的常用词汇(如break)也不可同日而语。因此,描写术语需要的索引行的数量在理论上比描写常用词汇要小。
Bowker和Pearso[14]45指出“不应该想当然地认为(专用语料库)总是越大越好”。李德俊[15]98也提醒说,由于“规模悖论”的存在,语料库的规模并不是越大越好,在语料库建设时,要特别注意“收益递减率”(the law of diminishing returns)。作为典型的专用语料库,气象英语语料库仅涉及气象专业文本,其语料规模无需达到通用语料库的级别。参考同类面向术语知识库编纂的专用语料库的设计经验(如[16]),笔者认为气象英语语料库的语料规模至少达到百万级别,才能满足气象术语知识库术语知识描写对语料规模的要求。此外,考虑到气象英语中新术语、新用法持续出现的特点,气象英语语料库应该呈现出一定的开放性,允许编者根据编纂的实际需要定期补充新文本。换言之,气象英语语料库的语料收集不是一次就能完成的,而是一个在百万级别基础上不断充实的动态过程。
3 选择标准
语料有规模大小之别,但代表性是其共同特点。语料的代表性主要通过对文本的选择来实现。文本选择的标准可以分为内部标准和外部标准两类。就通用语料库而言,语料选择的内部标准是指文本所共享的语言或文体特征。Atkins和Rundell[8]54介绍了基于内部标准的文本选择过程:(1)选择系列来源不同的文本;(2)分析文本中反复出现的词汇或语法特征(如语态、人称、搭配);(3)基于这些特点尝试对文本进行分类;(4)收集更多能够包含这些语言特征的文本,继续分析文本的语言特征,改进其分类,收集更多文本,直至這些特征在语料库中更清晰地反映出来。值得注意的是,依据内部标准从语料中获取的数据可能因循环论证而信度受损[17]171。鉴于此,Sinclair[17]提出按照文本的情景、功能等非语言(non-linguistic)或语言外(extra-linguistic)特征选择语料,这样至少可以使语言特征在语料库建设的开始阶段不受文本选择的影响。语料库的建设者在按照外部标准选择语料的同时,还可以根据从语料分析中获取的语言特征评估和改进语料的代表性[18]150,从而把外部标准和内部标准统一到文本的选择过程中。
专用语料库也可以把语言特征作为选择专业文本的内部标准。Halskov[19]主张把易读性(readability)和专业知识密度作为衡量专业文本质量的重要指标。他认为易读性是学术文本的重要特征,与句子长度、词(包括复合词)长度和被动语态的使用量呈反比关系,与通用词汇密度和人称代词的使用量呈正比关系。专业知识密度是学术文本的另一个特征,与未登录词(out of vocabulary words,指在自然语言处理中没有被词典收录的各类专有名词、缩略语、新增词汇等)和知识型式(主要包含词汇或语法标记语,能够帮助文本读者理解概念的意义和概念之间的关系)的密度呈正比关系。换言之,易读性越低,知识密度越高,文本质量就越高。易读性和知识密度虽然为专用语料库的文本选择提供了参考,但是由于偏好知识密集型文本,容易造成文本类型单一的缺点。
Bowker 和 Pearso[14]51指出,为了保证更全面地覆盖专门用途语言的概念和语言特征,专用语料库应该选择与所涉学科相关的各类文本。他们根据参与方把专业交际分为专家-专家、专家-初学者(initiate)、相对专家(relative expert)-外行(uninitiate)和老师-学生四种类型[20]35-39。他们认为,第三种交际不仅术语密度低,而且对术语的使用也比较随意,因而主张把该类交际中涉及的文本排除在语料库之外。笔者认为在该类交际中,鉴于信息接受者的专业知识水平低,信息发出者为了有效传递专业信息,往往以深入浅出的方式对核心概念进行解释,专业文本因而提供了较丰富的认知语境信息,也值得纳入专用语料库的选材范围。
就气象英语语料库而言,这四类交际场景涉及专著(如Severe Convective Storms)和学术期刊(如Atmospheric Research)、专业教材(如An Introduction to Dynamic Meteorology)、报刊科普或专栏文章(如ScienceDaily网站上有关气象的科普文章)、入门级教材(如Essentials of Meteorology: An Invitation to the Atmosphere)等文本类型。Bergenholtz和Tarp[21]94指出专用语料库在选择文本的时候还应该兼顾各个子学科并根据其重要性确定各类文本在语料中所占的比重。具体到气象英语语料库,对语料的选择应该至少涵盖大气、大气探测、大气物理学、大气化学、动力物理学、天气学、气候学、应用气象学8个学科分支。
4 加工处理
语料库的一大优势是可以借助分析软件对语料进行多文本检索,快速提取所需要的具体信息或统计某一语言特征的整体分布情况。语料的可机读性是语料库发挥这一优势的前提。为此,首先需要对选取的语料进行清洁处理。用于气象英语语料库建设的语料资源多是PDF和HTML数字文本,在投入使用之前,需要统一转换成纯文本。在此过程中,还会产生一些不合规范的符号或格式,若不加以清理会导致词汇分析、搭配统计不准确以及词性赋码出错或无法进行[7]32。此外,由于语料来源于各种类型的出版物,被选取的文本可能还包含致谢、版权页、页头书名、图表公式、索引目录、参考文献等内容。它们对气象术语知识库编纂没有参考價值,也需要从文本中清理出去[8]85。
在进行必要的清理之后,还需要对语料做进一步的处理,以便借助软件从语料分析中得到更准确的结果:(1)分词处理(tokenization)是语料预处理中的一个常见步骤,指将一连串的字符转换成相互分离、容易识别的形符。梁茂成、李文中和许家金[7] 45指出,如果不对语料进行分词处理,一来容易导致检索困难,二来可能会使语料库的频率统计出现误差,还可能会影响语料库的标注和后期加工。(2)词目还原(lemmatization)是语料预处理中的另一项基本操作,是指将词汇的各种屈折形式映射至原形,使分析软件能够把它们归并为同一个类符,从而把与词目相关的各类统计信息汇总在一起。气象英语语料库同样有必要进行分词和词目还原,但是由于某些分析软件(如术语提取软件TermoStat、搭配关系和概念关系提取软件Sketch Engine)已经整合了这两项功能,语料库的建设者无需对语料再做这方面的处理。
Leech[22]4指出“为了从语料库中提取信息,经常得先从输入信息开始”。对语料进行清理、分词和削尾处理之后,语料库已经可以投入使用,但是为了让使用者更合理地解读由软件获取的分析结果,还需要增加元数据(meta-data)标记,尽可能恢复在语料采集中丢失的语境信息。在各类元数据中,文本分类信息和结构信息对合理解读从语料库中获取的数据特别重要[18]155。就英语气象术语知识库而言,前者旨在明确某一具体文本在气象学学科体系中的定位,可以帮助编者确定某一术语或特征的学科分支来源。后者旨在说明文本的各组件之间的界限(如学术论文的摘要、综述、结论等组件)。这类信息可帮助编者确定某一语言特征在文本中的不同位置,从而结合文本结构对数据做出更全面的解读。
语料还需要进行必要的标注。对术语数据库创建而言,术语、搭配和概念关系这三类信息至关重要,一般需要利用正则表达式设置复杂的检索条件才能加以提取。以下是两款软件从语料中提取术语、搭配和概念关系等信息类型所使用的检索语法:
TermoStat的名词术语检索语法[23]:
(A|N)? (A|N)?(A|N)?(A|N)?(A|N)?N
Sketch Engine的“动词+名词”搭配检索语法[24]:
1: "V" "(DET|NUM|ADJ|ADV|N)"* 2: "N"
Sketch Engine的种属关系检索语法[24]:
HYPONYM,|(|:|is|belongs (to) (a|the|...) type|category|...of HYPERNYM
从以上检索语法可知,增加词性标注是提取以上信息类型的前提。因此,对语料进行词性赋码是面向术语数据库的语料加工处理的基本内容。术语提取软件TermoStat默认对上传的语料进行赋码处理。语料库检索软件Sketch Engine为英语就提供了11种词性赋码集,语料库建设者根据需要选择其中一种赋码后,软件自动完成对语料的词性赋码。
5 结语
语料库设计是从语料库中提取可靠数据的关键。为了建设面向术语知识库编纂的语料库,编者需要首先在语料库分类体系中为专用语料库定位以明确其类型特征,然后根据语料库的建设目的和涉及的主题范围确定语料的大致规模,并根据数据提取中出现的新情况向语料库中添加新语料。为了保证语料库的代表性,编者还需要根据专业交际的特点和学科的内部构成确定语料选择的标准。最后在使用语料之前,还应该对收集的文本进行必要的格式转换、内容清理、信息标注等处理。
参考文献
[1] WSTER E. The Machine Tool Dictionary. An Interlingual Dictionary of Basics Concepts[M]. London: Technical Press, 1968.
[2] SAGER J C. A Practical Course in Terminology Processing[M]. Amsterdam: John Benjamins Publishing Company, 1990.
[3] TEMMERMAN R. Towards New Ways of Terminological Description: The sociocognitive approach[M]. Amsterdam: John Benjamins Publishing Company, 2000.
[4] CABR M T. Theories of terminology: Their description, prescription and explanation[J]. Terminology, 2003, 9(2): 163-200.
[5] FABER P. A Cognitive Linguistics View of Terminology and Specialized Language[M]. Berlin/New York: Mouton de Gruyter, 2012.
[6] LHOMME M-C. Lexical Semantics for Terminology: An Introduction:Vol. 20[M]. Amsterdam: John Benjamins Publishing Company, 2020.
[7] 梁茂成, 李文中, 许家金. 语料库应用教程[M]. 北京:外语教学与研究出版社, 2010.
[8] ATKINS B T, RUNDELL M. The Oxford Guide to Practical Lexicography[M]. Oxford University Press, 2008.
[9] BIBER D. Representativeness in corpus design[C]// ZAMPOLLI A, CALZOLARI N, PALMER M. Current Issues in Computational Linguistics: In Honor Of Don Walker:Vol. 9. Springer Science & Business Media, 1994:377-407.
[10] LAUDER A F. Data for lexicography: The central role of the corpus[J]. Wacana:Journal of the Humanities of Indonesia, 2010 (2): 219-242.
[11] ZIPF G K. The Psycho-biology of Language[M]. Cambridge: Houghton Mifflin, 1935.
[12] KRISHNAMURTHY R. The corpus revolution in EFL dictionaries[J]. Kernerman Dictionary News, 2002(10): 1-6.
[13] NESI H. ESP and corpus studies[M]//PALTRIDGE B, STARFIELD S. The Handbook of English for Specific Purposes:Vol. 120. John Wiley & Sons, 2013: 407-426.
[14] BOWKER L, PEARSON J. Working with Specialized Language: A Practical Guide to Using Corpora[M]. Routledge, 2002.
[15] 李德俊. 語料库词典学理论与方法探索[M]. 南京:译林出版社, 2015.
[16] TERCEDOR SNCHEZ M, LPEZ-RODRGUEZ C I. Integrating corpus data in dynamic knowledge bases: The Puertoterm project[J]. Terminology, 2008,14 (2): 159-182.
[17] SINCLAIR J. Corpus and text: Basic principles[C]// WYNNE M. Developing Linguistic Corpora: A Guide to Good Practice. Oxford, UK:AHDS, 2005:1-20.
[18] XIAO R.Corpus creation[M]//INDURKHYA N,DAMERAU F J. Handbook of Natural Language Processing (2nd Revised Edition). CRC Press, 2010: 147-165.
[19] HALSKOV J, HANSEN D H, BRAASCH A, et al. Quality indicators of LSP texts-selection and measurements measuring the terminological usefulness of documents for an LSP corpus[C]// European language resources distribution agency. Proceedings of the Seventh International Conference on Language Resources and Evaluation, 2010.
[20] PEARSON J. Terms in Context:Vol. 1[M]. Amsterdam:John Benjamins Publishing Company, 1998.
[21] BERGENHOLTZ H, TARP S. Manual of Specialised Lexicography: The Preparation of Specialised Dictionaries:Vol. 12[M]. Amsterdam: John Benjamins Publishing, 1995.
[22] LEECH G. Introducing corpus annotation[C]// GARSIDE R, LEECH G, MCENERY V. Corpus Annotation: Linguistic Information From Computer Text Corpora. London: Longman, 1997: 1-18.
[23] DROUIN P. Term extraction using non-technical corpora as a point of leverage. Terminology, 2003(1):99-115.
[24] LEN-ARAZ P, SAN MARTN A, FABER P. Pattern-based word sketches for the extraction of semantic relations//DROUIN P, GRABAR N, HAMON T, et al. Proceedings of the 5th International Workshop on Computational Terminology. Osaka, Japan, 2016: 73-82.
作者簡介:卢华国(1979—),男,博士,副教授,加拿大蒙特利尔大学(导师Marie-Claude LHomme)和英国曼彻斯特大学访问学者,长期从事术语翻译和专科词典学研究,2017年当选为中国辞书学会双语词典分会理事,担任International Journal of Lexicography期刊匿名评审,发表SSCI论文5篇、CSSCI论文7篇,主持翻译类、词典类各级各类课题7项,参与翻译类国家社会科学基金重点项目、一般项目和教育部人文社会科学研究项目各1项,合作撰写专著1部,参与编纂辞书2部,合译书籍3部。通信方式:louisluhuaguo@163.com。
