基于时间加权A-T模型的学者相似度计算研究*
2021-10-08陈红伶
李 倩 陈红伶 许 鑫
(华东师范大学经济与管理学部 上海 200062)
0 引 言
学者推荐系统可以准确高效地查找关联的科研人员、学科知识和研究领域等信息,而推荐是依靠计算学者之间的相似度来实现的。学者之间的相似度可以通过对学者之间的显性关系和隐性关系建模计算,显性关系中应用最广泛的是合著关系,隐性关系中则是引用关系,包括耦合关系(共引关系)、共被引关系等,随着研究的深入,也有学者将关键词、主题词等纳入研究的范畴,结合机构、地理位置等多种指标计算学者之间的相似度,量化学者之间的联系,从而实现学者合作推荐等。但以往的研究中往往忽略时间对于知识累积和知识创新的影响,并未找到一个很好的方式衡量时间标签在当中发挥的作用,因此对学者研究方向的衡量缺失动态性和精确性。
基于此本文认为在计算学者相似度时需要综合考量科学文献内部结构、文本语义以及时间维度的影响,以动态的方法对学者的研究主题进行更加客观和全面的衡量,动静结合,在此基础上计算学者相似度才更具意义。
1 相关研究
1.1学者相似度研究学者相似度可以从多个角度来进行计算,如合著关系、耦合关系、同被引关系等。首先,学者相似可直接从合作关系中定义。邓少伟[1]提出了基于论文共同作者的学术关系计算,构建了科研人员之间基于相似度的学者推荐系统,熊回香[2]在合作关系的基础上增加了学者能力因素,通过学者的学术能力来挖掘候选学者,并根据历史合作关系计算合作质量,综合计算学者相似。其次,基于同被引计算学者相似度,学者发表的文献被相同文献引用的次数越多,则研究内容越相似。邱均平[3]基于国内制浆造纸领域构建了学者(第一作者)共被引矩阵,采用社会网络分析方法计算共被引所形成的相似性。马瑞敏[4]从第一作者耦合的角度计算作者相似度,耦合次数越多,研究方向越相似,对同被引计算相似度进行了补充。近期学界更多关注从研究主题、研究领域定义和计算学者相似度。傅城州[5]采集学者社会网络平台的学者信息,通过标签提取的方式,利用学术领域相似的方法计算学者的相似度。陈洁敏通过“用户-项目-标签”三部图扩散算法计算用户的相似度,并引入了用户兴趣主题分布,通过KL距离综合计算用户相似度。孙赛美[6]通过主题模型衡量学者研究兴趣,结合三度影响力理论,融合信任度和研究兴趣相似度计算学者相似度。XU Yunhong[7]综合考虑学者之间的学术关系和研究主题两个因素,根据学者之间的主题词和学者关系构建异质网络,后通过网络计算学者之间的相似度。Chaiwanarom[8]等将作者主题模型扩展而来的语义方法结合共同作者网络,提出了一种寻找潜在合作者的方法。国内学者关鹏[9]、何劲[10]、逯万辉[11]等采用作者主题模型算法, 抽取作者-主题关联矩阵, 追踪学科领域生命周期中的主题强度和作者研究兴趣的变化、对作者-主题关联的学科知识网络进行演化分析,进行作者研究主题聚类等,但并未对时间标签做进一步分析。Peng Hongwei[12]注意到了时间维度上学者的研究兴趣可能会发生转移,在计算学者相似度的过程中通过采集近期的文章来表示学者当前的研究方向和兴趣。通过学者近期的研究成果来衡量学者当前的研究兴趣具有可取性,但直接切断以前的研究成果,对学者研究方向的整体衡量缺失了精确性和动态性。因此需要在时间维度上对学者的研究主题进行分析可以更加客观和全面衡量学者的研究主题,在此基础上计算学者相似度更具意义。
1.2基于时间加权的主题-作者模型研究传统的主题建模方法利用文本的内部特征,忽略了基于语义的文档间词汇的内在结构,且不考虑时间因素的影响,这使得分析结果与真实情况总有所违背[13]。基于时间维度的权重分析较早出现在计算机的推荐系统领域研究中,张磊[14]指出用户对于资源的兴趣基于时间变化,用户评分的重要性也会随时间衰减,通过基于遗忘曲线的相似度计算,提高推荐系统的准确度。陈海龙[15]针对传统算法相似度计算不足的问题,提出了融合用户兴趣变化和类别关注度的推荐算法,将基于时间的兴趣度权重函数引入项目相似度计算中,提高用户推荐准确度。在学术文献挖掘中,闵波[16]基于新文献相对于旧文献更助于科研人员获取科学假设的基础,建立时间加权的文献知识发现方法,提高了发现的准确率。江秋菊[17]指出文献在具备相同被引频次的情况下,近期发表的文献的影响力通常更高,提出了融入主题和时间因素的文献影响力计算,从细粒度层面评价文献的影响力。伍哲[18]同样采用融合学术文献的发表时间因素,通过文献的发表时间增加特征词的时间权重,提出了时间加权的TF-IDF学术文献主题分析方法,使主题的区分度更高。Ho K.T.[19]等提出了一种结合作者主题模型与文本信息的Textual-ABM模型来文档的内容及作者的兴趣进行建模,进而分析社交网络的动态性。当前大多数方法致力于发现静态的潜在主题和用户兴趣,或者仅从文档的文本内容出发来分析主题演变,而没有直接考虑诸如作者、时间之类的影响因素。为了克服这个问题,有学者提出了一种使用带有时间戳的作者和主题的文档的动态用户兴趣模型 Author-Topic over Time(AToT)模型[20],但此类模型广泛用于景点推荐[21]和电子邮件分析[22]等,较少用于研究学者之间的科研主题相似度。
虽然特定主题的概念几乎不会发生改变,但主题和作者之间的混合分布及相关性会随时间而变化。因此,本文将论文题录结构和语义相结合,结合遗忘曲线的思想,给出引入时间加权得到学者的主题重要度和学者相似度计算方法,综合考虑学者发文的主题和时间因素,通过分析学者在某主题和时间序列下的发文规律,沉淀旧主题,突出新主题,有效提高学者关联匹配的准确性。
2 模型与方法
2.1 A-T模型研究A-T模型(Author-Topic Model),即作者-主题模型,是以无监督学习方式从数据中学习主题和作者的分布模型[23],是在LDA模型的基础上发展而来。LDA模型是语料库的生成统计模型[24]。在LDA中,可以将每个文档视为不同主题的混合,并且每个主题的特征在于单词的有限词汇量上的概率分布。LDA的生成模型由一个概率图形来描述 ,但是LDA仅将文档视为概率性主题的混合体,并未考虑作者的重要性,A-T模型在此基础上加以改进,可以同时对文档的内容和作者进行建模。
如果仅根据一篇研究论文对主题进行建模,则称其为文档-主题模型D-T模型;A-T模型不同于D-T模型:当收集了作者的全部研究论文以形成主题模型时,称为A-T模型。如果作者仅发表了一篇研究论文,则A-T模型与D-T模型相同。作者主题是通过汇总作者的每篇研究论文的文档来获得研究主题,更能代表作者的研究兴趣和方向[25]。
通过训练语料库,可以通过A-T模型来限定单词-主题分布和主题-作者分布。本研究中选择Python中的Gensim工具包来训练和更新A-T模型,通过一致性来确定最佳主题数。
2.2学者时间维度的主题分布本文利用A-T模型挖掘隐含的“作者-主题”语义信息。对于每一篇文献将LDA概率最大的主题作为该文献的研究主题。本文默认第一作者对文献的主题贡献最高,通过第一作者-文献的对应关系,将学者和主题对应起来,保留文献的发表时间,从而得到作者的主题和时间两个维度下的发文量分布。以范并思学者为例,如表1所示:

表1 学者时间-主题双维度发文量分布
2.3基于时间加权的主题重要度计算
2.3.1 基于遗忘曲线的时间关注度计算 遗忘曲线是心理学领域中关于人类自然遗忘规律的曲线,是由德国的心理学家Hermann Ebbinghaus[26]提出的,曲线揭示了记忆和遗忘是指数形式的变化,并遵循先快后慢的规律[27]。江志恒[28]基于遗忘曲线,对记忆的保持量提出了定量计算的保持量函数,如式1所示。

(1)
本文采用遗忘曲线拟合学者的特定主题下的发文随时间变化的关注度,时间关注度timeweigh通过遗忘曲线的内涵表示学者近期的研究成果,更能代表学者现在的研究方向和偏好,如公式(2)所示。其中i代表年份,ti表示第i年,to则表示最新年份的时间,本文中to为2019,numi表示ti年份下学者特定主题的发文篇数。timeweigh表示的是根据年份和发文数量的加权和来表示该学者特定主题的关注度。时间距离现在越久,关注度权重越小。
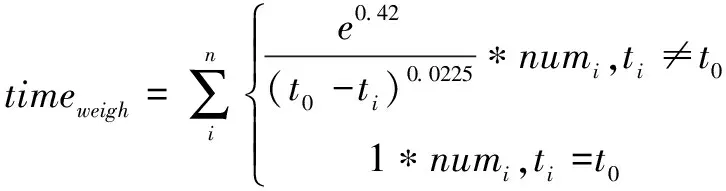
(2)
2.3.2 基于发文间隔的稳定性计算 学者近期的成果更能代表学者现在的研究方向和偏好,在此理解基础上,本文对学者在一个主题下发文的稳定性进行计算,如果学者的发文是连续不断的,可以推断学者在该研究方向和领域有着持续研究和产出,说明该主题是该学者的重点关注和研究的方向,如公式(3)所示。稳定性successionweigh计算了主题下发文时间序列间隔期的方差倒数,其中这一方差用sTopic2来表示,如果发文间隔期的方差越小,则稳定性更高,则稳定性指标的值更高。
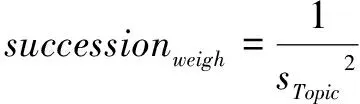
(3)
2.3.3 学者主题重要度计算 本文采用时间关注度timeweigh和稳定性successionweigh的乘积表示学者主题重要度Topicimportance,如公式(4)所示。当一个学者对于某个主题事件关注度越高,且关注越稳定,那么有理由认为这一学者在该主题下的重要度是很高的。这一重要度不再平等看待所有发文,而是加入了时间权重,能有效区别部分作者很早之前所做的主题研究,提高其在近期所做研究主题的权重。
Topicimportance=timeweigh*successionweigh
(4)
2.4基于余弦相似度的学者相似度计算结合上述指标,引入基于时间加权的主题重要度计算方法,形成学者和主题的二维矩阵,数值为学者在该主题下的主题重要度,可以清晰得到学者的主题分布和以及在该主题下的关注度,即学者主题重要度Topicimportance。本文采用余弦相似度计算学者的相似度。余弦相似度用向量空间中两个向量夹角的余弦值衡量两个个体间的差异度大小,余弦值越接近1,两个向量越相似。主题数量属于高维度,采用余弦相似度计算更加适合和直观,学者相似度Similarity公式计算如公式(5)所示,其中向量M和N表示学者的研究主题分布,向量Mi和Ni分别代表向量M和N的分量,即各学者在主题i下的主题重要度。
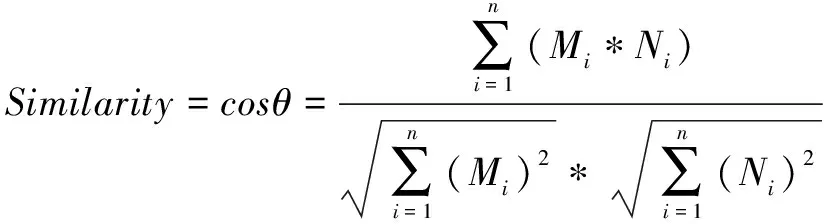
(5)
3 实证研究
3.1数据获取与处理本文的实验数据来源是中国知网CSSCI和CSCD核心期刊数据库,文献分类目录中勾选“图书情报与数字图书馆”,图书情报与数字图书馆领域兼顾人文社会和科学技术研究,比较有代表性,以该领域的文献和作者信息作为实验数据集验证基于时间加权A-T模型计算的学者相似度具有较好的适用性。检索日期是2019年4月29日,最终采集得到96 671条文献题录信息,覆盖年份为1998-2019年。在采集得到的题录数据中,去除掉作者、摘要或第一作者等重要字段为空的非研究类文献,得到有效数据89 177条作为本文的实验数据,涉及11 85种期刊,47 206位作者。
本文通过Python的jieba工具包对文献的摘要做文本预处理,包括分词、去停用词、同义替换以及作者消歧、语义消歧等,之后将所有文献的题名摘要作为语料库训练LDA模型,根据困惑度确定最佳主题数,最终确定返回50个主题,依次标为主题1、主题2、主题3……主题50,并以此作为每一篇论文的标签,即该篇论文的研究主题。
得到每一篇文献的主题后,采用Python的Pandas工具包对学者和主题构建学者-主题-时间矩阵表,导入基于时间加权的主题重要度模型进行计算,导出学者的主题重要度分布数值表,最后采用余弦相似度计算学者的相似度。
3.2实验结果
3.2.1 学者-主题重要度矩阵可视化分析 首先对整体的学者主题关注度表现进行可视化,在学者-主题关注度矩阵当中表达了三维特征,横轴表示主题,纵轴表示作者,值表示主题重要度,这里的主题重要度见前文的公式(4)。本文采用平行坐标图Parallel coordinates plot进行绘制,随机选择了图书馆方向的24位学者及其主题进行主题重要度可视化。如图 1所示,每条竖线表示一个特征,即某一个主题,数值是学者在该主题研究中关注的突出程度,表现在图中即气泡的大小。可以看出大多数作者在主题的重要度上表现较为一致,即不会同时广泛涉猎多个主题且有大量产出,但会集中于某少数主题进行深入研究。因此他们的主题重要度会在某一些主题上突出显示,而在其他主题上显示为零值,少有涉猎的话则会显示较小的气泡。以赵蓉英为例,她在主题39(基于知识图谱的文献计量)、主题24(竞争情报)、主题30(公共图书馆与图书馆联盟)、主题42(基于引文分析的文献计量)、主题43(图书馆学与情报学)上有显示或大或小的气泡,在其他主题上显示为空。在这七个主题当中,赵蓉英对主题39(基于知识图谱的文献计量)中的关注度要显著高于其他几个主题,对主题30(公共图书馆与图书馆联盟)和主题43(图书馆学与情报学)则是稍有涉猎,因为其气泡大小(重要程度)明显小于其他几个主题。
对于部分主题来说学者的主题重要度都较小甚至为0,对于学者的区分度不高,除却此类的主题以外,在少数主题上学者的差异度较大,这些少数主题就是区别学者的重要标志。以主题39(基于知识图谱的文献计量)为例,在图1中显示的20位学者当中,对主题39有所研究并有所产出的学者有7位,分别是邱均平、赵蓉英、张敏、唐晓波、冯佳、侯剑华和严贝妮,而这7位学者当中,虽然邱均平在该主题下的产出有161篇,明显多于其他几位学者,但排除长时间累积的因素,重点关注近年来该主题下的学术产出,赵蓉英学者的主题重要度相对更高。根据上述分析可以发现虽然随机选择的学者研究领域都是图书馆方向,但在细分领域下,经过时间加权后学者的表现具有更高的区分度。
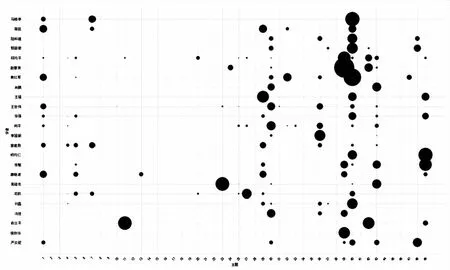
图1 学者和主题重要度平行坐标图
3.2.2 静态学者相似度分析 首先基于整体数据从静态的角度判断学者相似度。由于主题数量属于高维度,采用余弦相似度计算更加直观适合,因此本文基于学者在主题上重要度的余弦距离来计算学者之间的相似度。根据主题重要度之和对学者进行降序排列,选择前8位学者,计算这些学者与其他几位学者的相似度并可视化,如表2和图 2所示,相似度范围为0~1之间,学者和自身的相似度为1,相似度越大,越接近1,颜色越深;相似度越小,越接近0,颜色越浅;相似度为0则表示两位学者并无研究领域的重合。对于高于0.85的相似度加粗表示,可以发现学者袁红军和学者刘磊、马晓亭三者之间都保持高相似度;学者邱均平和学者赵蓉英相似度高,与其他6位学者相似度都较低;而学者吴稌年、王世伟以及王知津三位学者和其他几位学者之间相似度都较低,说明上述3位学者都有自己专注的领域,研究的方向差异大。

图2 前8位学者相似度热力图

表2 前8位学者相似度矩阵

续表2 前8位学者相似度矩阵
为进一步证明上述计算结果的合理性,以选择的这8位学者为例,通过知网学者库的机构、所标识的研究方向和本文得到的结果进行验证,如表6所示,发现赵蓉英和邱均平同为武汉大学的学者,在知网学者库中标识的研究方向都为“图书情报与数字图书馆、高等教育、科学研究管理”,且在主题39(基于知识图谱的文献计量)和主题42(基于引文分析的文献计量)中都有一定的研究,如表3所示。而袁红军、马晓亭和刘磊虽然分属不同机构,但在知网学者库中的研究方向都与计算机软件及计算机应用先关,但也有各自的细分方向,例如袁红军研究“档案及博物馆”,刘磊研究“新闻与传媒”,马晓亭研究“民商法”,3人都对主题40(高校图书馆与信息服务)有所研究,如表4所示。 吴稌年、王世伟和王知津3位学者则明显有自己专注的领域,如吴稌年专注于主题23(图书馆史),王世伟专注于主题30(公共图书馆与图书馆联盟),而王知津对主题42(图书馆学与情报学)研究较多。如表5所示。
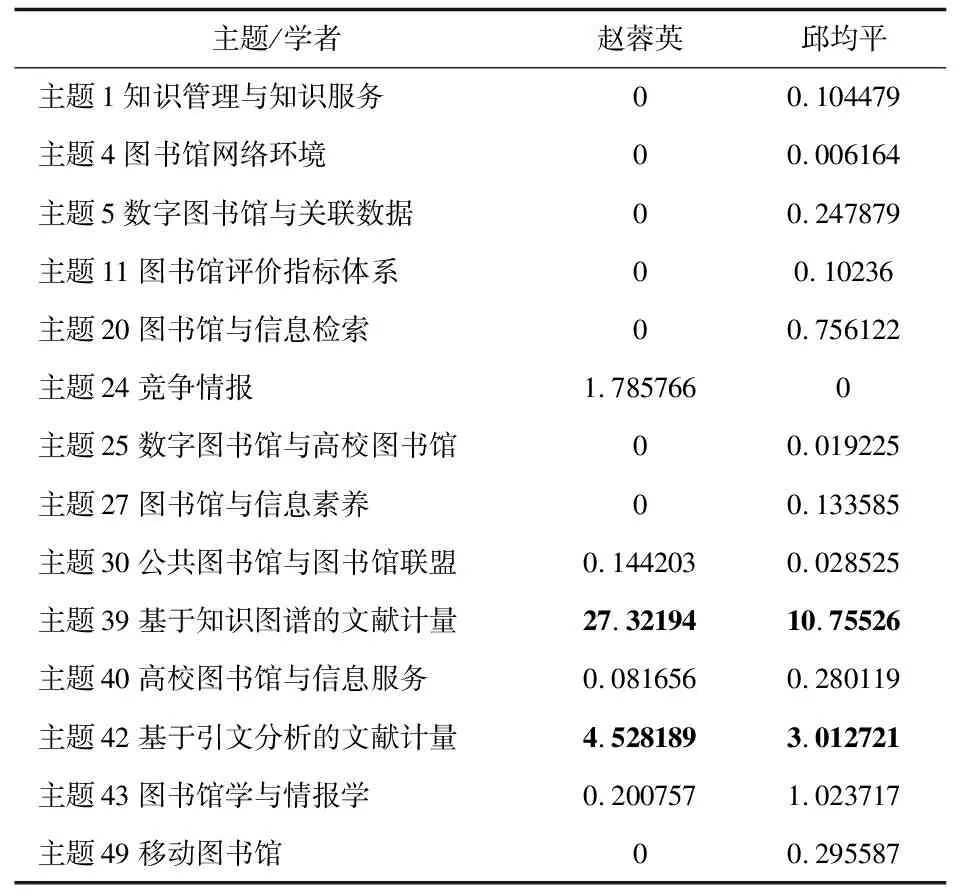
表3 赵蓉英-邱均平主题重要度对比

表4 袁红军-马晓亭-刘磊主题重要度对比
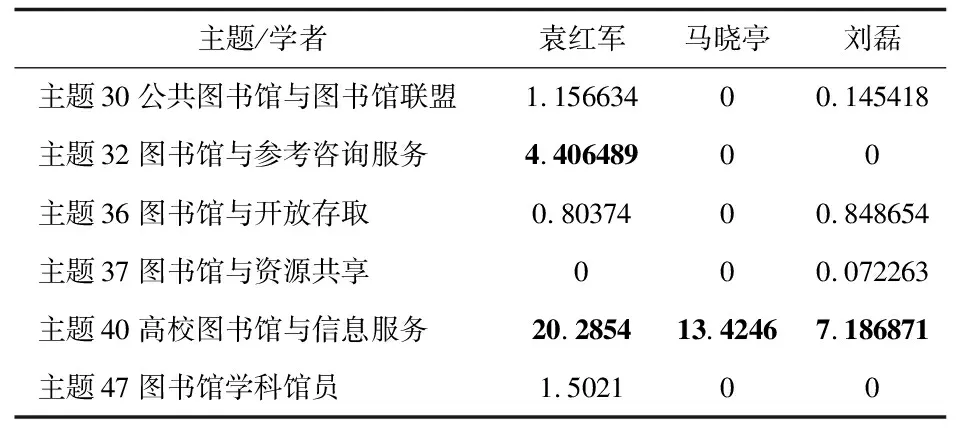
续表4 袁红军-马晓亭-刘磊主题重要度对比
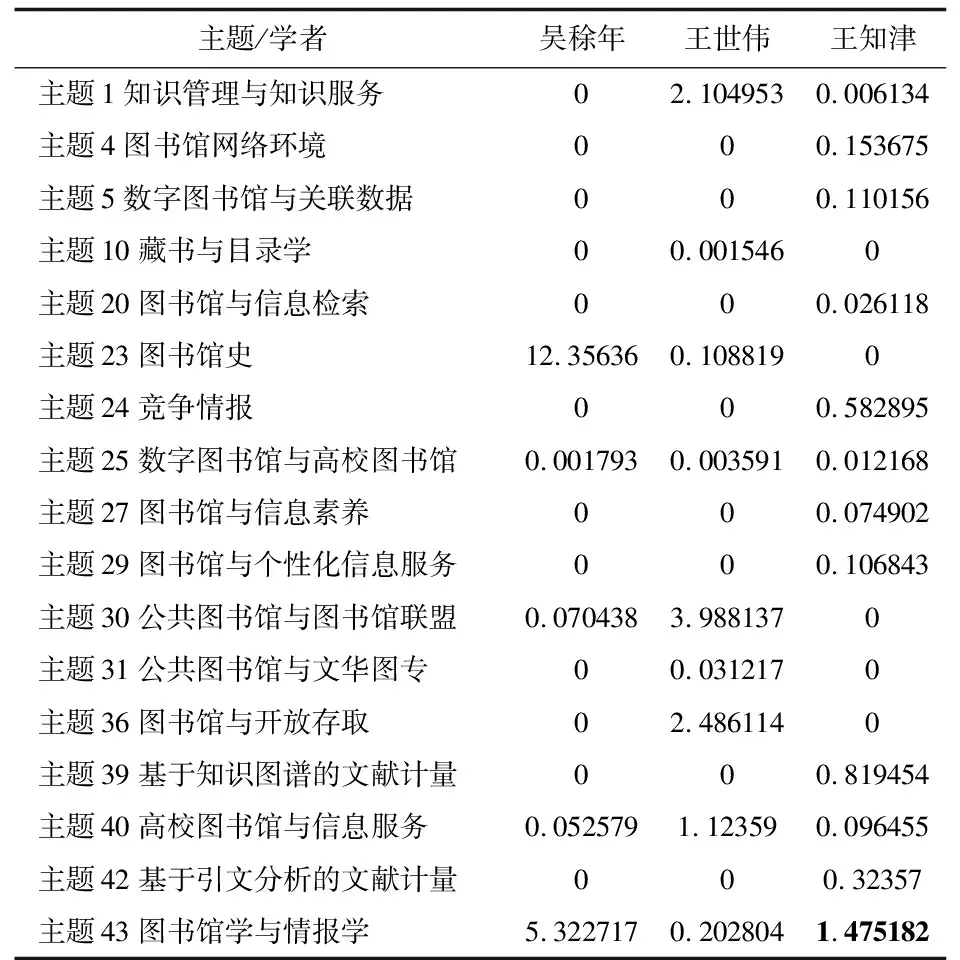
表5 吴稌年-王世伟-王知津主题重要度对比

表6 学者基本信息
上述分析是基于整体数据从静态的角度判断基于时间加权A-T模型识别相似学者的结果,根据回溯作者发文和作者机构可以发现本文提出的方法可以有效计算学者之间的相似度并识别得到在研究主题和方向上相似的学者,整体结果具有可信度。
3.2.3 动态学者相似度分析 由于引入了遗忘曲线计算事件关注度,即在关注主题的同时还考虑了时间变化在判别学者研究主题的影响,因此为了进一步探究本方法中时间加权思想对于学者相似度计算的影响,本文继续深入挖掘不同时间下计算得到的学者相似度的结果,即从动态的角度分析学者之间的相似度。
在未考虑时间加权的背景下运用A-T模型计算作者相似度,为了同考虑时间加权的A-T模型展示效果一致,此处选择输出主题重要度加和排名前24名的作者,并采用R软件根据作者间最小距离(Bray-curtis距离)进行层次聚类(UPGMA聚类),可视化结果如图 3所示,聚类效果如图 4所示。

图3 未考虑时间加权A-T模型24位作者层次聚类

图4 未考虑时间加权A-T模型24位作者层次聚类评估
根据时间加权A-T模型计算作者相似度,并采用R软件根据作者间最小距离(Bray-curtis距离)进行层次聚类(UPGMA聚类),可视化结果如图 5所示,聚类效果评估如图 6所示:

图5 时间加权A-T模型24位作者层次聚类

图6 时间加权A-T模型24位作者层次聚类评估
在聚类评估结果可视化图4、图6中,实色直线和灰色曲线分别为常规线性拟合与Lowess平滑拟合线,根据使用Bray-curtis距离的UPGMA方法得到聚类评估结果可见两次聚类效果都达到了理想状态,在未考虑时间影响的情况下,主题重要度之和与该作者的论文发表数量是一致的,并不能突出显示其在某个主题或某个领域下的关注程度,也不能明确显示近几年该作者关注的主题,在输出的24位学者当中有部分学者在早期有着十分充足的学术成果积累,并且在某些领域已经成为了学术权威,但随着时间的推移和研究的专注,学术产出速度有所下降。就计算学者相似度并实现相似学者推荐而言,不考虑时间因素将上述学术权威作为相似学者进行推荐的结果是不够理想的。与之不同的是考虑时间加权进行聚类的24位学者则是在近期、有持续产出且对某一主题或某些主题有重点关注的学者。从学者相似度聚类结果来看,是近期有相似的学术研究方向或相似的关注主题才会被聚为一类。时间加权的A-T模型计算所得的学者相似度是基于当前以及前一段时间学者的研究主题得到的,这正体现了时间加权的价值,即从动态的角度衡量判断学者最近、最主要的研究主题,计算当下与该学者研究主题最为接近的其他学者,以此实现的学者推荐才能更具现实意义。
3.2.4 讨论 根据上述实验结果,从静态的角度来看,基于时间加权A-T模型计算得到的学者相似度能够在足够宽泛的图书情报与数字图书馆领域下继续辨别、细分更多方向,为学者提供更精准的推荐;从动态的角度来看,基于时间加权的A-T模型对时间足够敏感,能够在不同的时间下识别出与该学者当前研究方向最为相似的学者,有效排除因时间久远导致的旧主题积累等问题。
基于时间加权A-T模型将论文题录结构和语义相结合,考量时间因素对于主题研究的影响,沉淀旧主题,突出新主题,使学者相似度的计算由静态的结果变为动态的过程,能够为学者之间交流合作做推荐提供新思路,为学术共同体的识别和基于学者个人以及整个学术共同体的主题演化提供新方法。
4 结 语
随着时间的变化,学者的研究方向可能会更加深入,也可能会在研究兴趣上有所转移,从时间维度上来对学者的研究进行主题分析才更加全面和客观,基于此,本文提出了基于时间加权A-T模型计算学者相似度的方法,引入遗忘曲线概念,将时间关注度和基于发文间隔的稳定性结合来代表学者-主题重要度,并根据余弦相似度来计算学者相似度,最后在图书情报领域得到了检验,证明该相似度的方法有其合理性,且能够动态识别相似学者,为学术共同体的识别和科研团体合作网络的演化等研究提供了新思路。
本文是基于第一作者和文献主题之间的关系研究学者相似度,其普适性还需放到其他学科和语种下,并同时考虑作者顺序等来进行进一步检验。
