基于文本挖掘的国内食品安全热点分析
2021-10-05李菲路阳马强
李菲,路阳,马强
(黑龙江八一农垦大学信息与电气工程学院,大庆 163319)
食品安全领域研究与人民生活息息相关,随着社会和信息技术的迅速发展,食品安全领域相关文献的数量成几何增长,研究者如何从大量的数据中快速把握和获取该领域的研究热点,对于分析当下食品安全领域研究现状具有宏观上的辅助作用。文本挖掘(Text Mining,TM)又称文本数据挖掘(Text Data Mining,TDM)或文本知识发现(Knowledge Discovery in Texts,KDT),是使用自然语言处理技术和智能算法等从文本数据中抽取出隐含的、以前未知的、潜在有用的模式、规则、规律的过程[1-4]。利用文本挖掘技术,能够有效地从各领域的结构化、半结构化和非结构化数据中提取相关知识[5-7],进而提出新的实验假设,得到新的科学结论。文本挖掘技术在各个领域的应用十分广泛。例如,文本挖掘在商业智能领域的应用:通过分析客户对商品的反馈意见,挖掘客户的兴趣和需求,以此来提升产业竞争力[8-12];文本挖掘在教育领域的应用:刘三女牙等对[13]国内外利用文本挖掘技术促进学习分析的现状进行研究,提出文本挖掘在帮助学习者快速定位和检索关键信息、提供个性化学习辅助、指引学生不断反思等方面将发挥重要作用;文本挖掘在生物、医学领域的应用:涉及利用文本挖掘技术对领域学术研究的现状、热点进行挖掘和分析[14-17],采用文本挖掘技术对领域内的实体及关系进行抽取分析,挖掘领域中隐含的知识[18-20]等各个方面;此外文本挖掘在社交媒体、web 等领域的研究也不断深入[21-24]。
因此,借鉴文本挖掘在各个领域应用成功的经验,收集CNKI 数据库中2009~2019 年收录的食品安全领域研究的高被引文献记录,抽取其中关键词,利用词频统计、文本向量空间构建和聚类分析技术对关键词处理和分析,挖掘食品安全领域研究主题,并综合类标签和共词分析方法评估主题及关键词热度,从而总结当前国内食品安全研究的热点和趋势,以期为食品安全领域的研究提供借鉴。
1 数据收集和方法
1.1 食品安全领域的数据收集和预处理
关键词作为文献特征分析的重要属性,是文献内容的精炼。以中国知网数据库收录的食品安全领域研究文献的记录为数据样本,即采用主题词为“食品安全”,发表时间为2009 年1 月1 日至2019 年12月20 日的检索策略,筛选出被引频次大于11 的高被引文献(2018~2019 年文献被引频次最低为5),共得到2 430 篇文献的相关记录。将文献中的关键词抽取出来,统计该领域关键词词频,同时考虑到关键词出现的频次越高,可能越具有普遍性的特点,在单纯考虑文献关键词词频信息的基础之上,加入了关键词出现于不同文献的文档信息,即计算关键词的词频-逆文档频,以此作为衡量关键词重要程度的指标,其计算如公式1 所示:
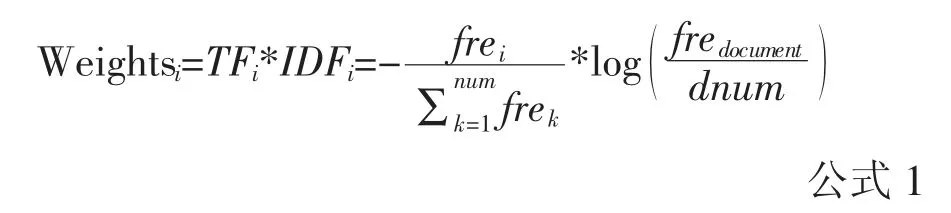
式中,关键词权重是词频与逆文档频值的乘积,TFi是关键词的频率,等于该关键词出现在样本文献数据的频次与总关键词个数的比值,逆文档频是含有关键词i 的文献频数与总的样本文献数目的比值取负对数,frei是关键词i 的频次,fredocument是含有关键词i 的文献频次,表示样本数据中的所有关键词个数,其中,k 表示第k 个关键词,num是不重复出现的关键词个数。dnum是样本数据中的总的文献篇数。
基于文献关键词具有唯一性,即不可能在一篇文章中同时出现两个完全一样的关键词,文献关键词词频就等于关键词所在的文献频,进而计算出关键词的逆文档频值,得到文献关键词的权重信息。权重值越大说明该关键词在领域当中所占的比重越高,作为领域核心关键词的可能性也就越高,表1 为得到的文献关键词的权重(重要程度)信息。可以发现尽管“食品安全”关键词词频最高,但其权重值却低于“监管”关键词。
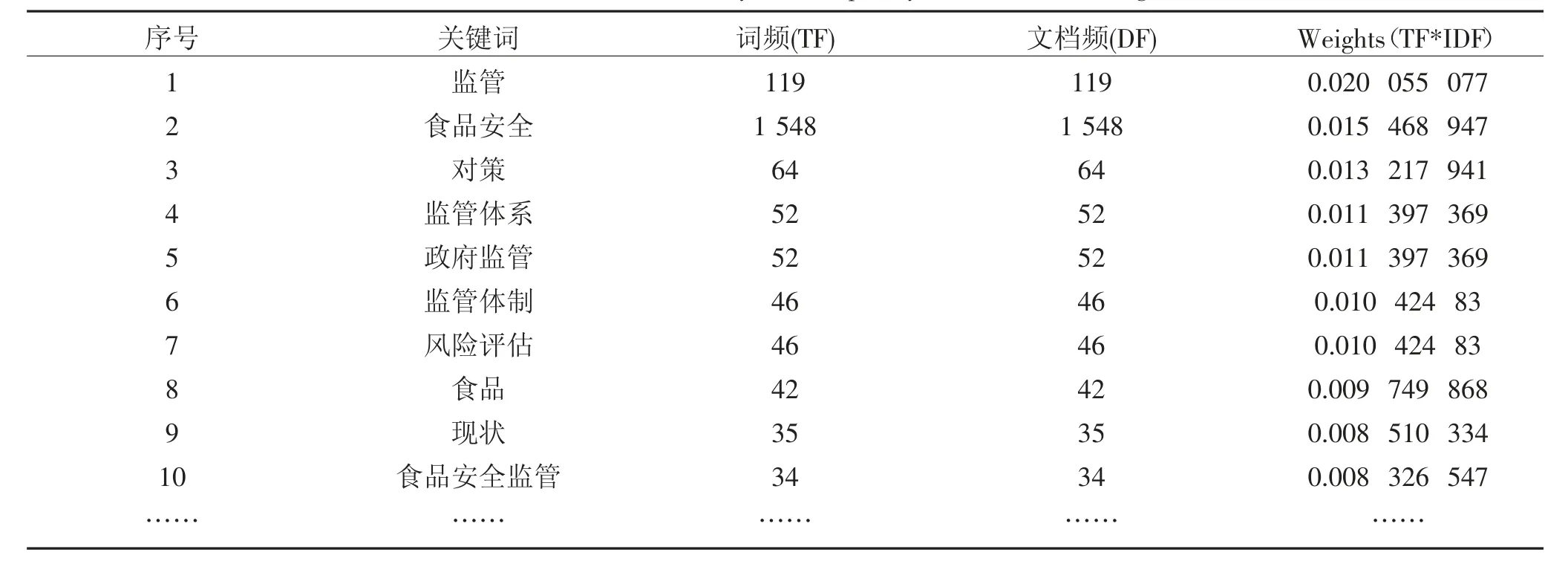
表1 关键词词频,文档及权值信息Table 1 The information of keyword frequency,document and weight
依据权重值得到食品安全领域的核心关键词还包括“对策”“监 管体系”“政 府监管”“监 管体制”“风险评估”等。
在衡量了关键词在文献中的权重之后,利用文本挖掘技术将文献关键词文本内容进行特征向量化表示,构建文本向量空间模型[25-26](Vector Space Model),进而挖掘文本主题,具体的实现算法如下:
定义1.待分析文献集D:D={D1D2D3…Dn},其中Di表示第篇文献。
(1)预处理操作
将文献记录中的关键词以分号进行分割提取。其中抽取的每一个关键词都作为一个维度,筛选出文本特征词(关键词)集合:KW={k1,k2,…,km}。
(2)文档的向量化表示
文献集合D 中任一文献都可向量化表示为:Di=(wi1,wi2,…,wim),其中,Wik就是第i 篇文献中第k 个关键词的权重。
(3)量化特征项集合,构建文献—关键词的文本向量空间模型,图1 为文献—关键词空间矩阵:

图1 文献—关键词空间矩阵Fig.1 The space matrix of‘keyword—documents’
1.2 食品安全领域研究的聚类分析
将向量空间模型输入到gCLUTO[27]软件中进行聚类分析,系统聚类方法选择聚类效果较好的基于层次聚类的双聚类算法,表2 为相关的参数设置。

表2 层次聚类相关参数设置Table 2 Related parameter settings for hierarchical clustering
其中,层次聚类算法[28-29](Hierarchical Clustering),简称HC。它是将数据集划分成树型结构的一种分类方法。根据分类时采用的方法不同,主要分为自下而上的凝聚层次聚类算法和自上而下的分裂层次聚类算法。重复二分聚类算法就是分裂层次聚类算法中的一种,它通过将整个数据集作为一个群集,重复分割成对的群集,直至获得所需数量的群集或所有对象已分割至指定阈值而不能再分的聚集树时停止。
由于构建的文献—关键词向量空间中的权重值具有处在[0,1]区间的特点,因此采用简单的计算两向量夹角余弦值的方式度量文献之间的相似性,如公式2 所示。

对数据元素进行层次聚类的类型合并融合标准函数选用I2,即采用k-means 聚类算法中常用的质心合并方式[31],计算如公式3 所示。
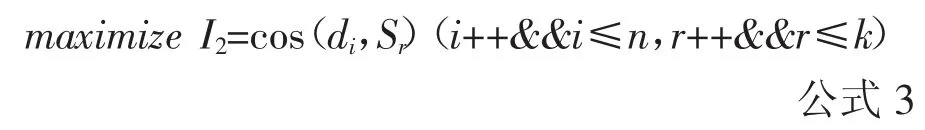
式中,k 为划分的类别个数和质心数目,通过计算文档di分别到k 个质心的余弦夹角值,取得最大值,即最大相似度,将该文档di合并到该质心Sr周围,其中,n 为文献总篇数。
为了更加直观地观察和评价层次聚类算法对文献关键词的聚类结果,采用两种可视化方式。首先把文献中的关键词序列代表文档进行显示,得到图2(a)所示的基于层次聚类的双聚类结果矩阵式可视化。其中,带有深浅颜色的小方格代表向量空间中原始数据的值(权重),白色代表0,红色的深浅代表词汇权重值的高低;属于同一簇的行列分别聚集在一起,行聚类中聚集到一起的文献说明彼此之间距离较近,围绕同一个主题聚集的可能性较高。最底层的列聚类表示的是关键词的聚类,依据关键词之间的相似程度可以衡量两者之间的语义相似度。

图2 基于二分层次聚类的双聚类结果可视化Fig.2 Visualization of bi-clustering results based on bisecting hierarchical clustering
其次,“山形可视化”(Mountain Visualization)是一种帮助用户理解高维数据集内容的聚类结果可视化方法[27]。在构建的向量模型中,具有数千到数万个维度,采用“Mountain Visualization”可视化方式显示聚类结果,每个山峰代表簇集中的单个簇(类别),平面上一对峰之间的距离表示簇间的相对相似性。峰的高度代表同一簇中数据对象的相似程度,高度越高表示簇中对象整体越相似,峰的体积与簇中对象的数量成正比。峰的颜色代表簇中对象的内部标准偏差,红色代表低偏差,而蓝色代表高偏差。图2(b)中显示的是聚类结果的十个簇,可以看到各簇之间具有很好的区分,聚类效果明显。
为了更加客观地评价聚类结果的合理性和有效性,采用计算其类内相似度和类间相似度的方式评价其聚类效果。表3 为聚类结果的评价信息:
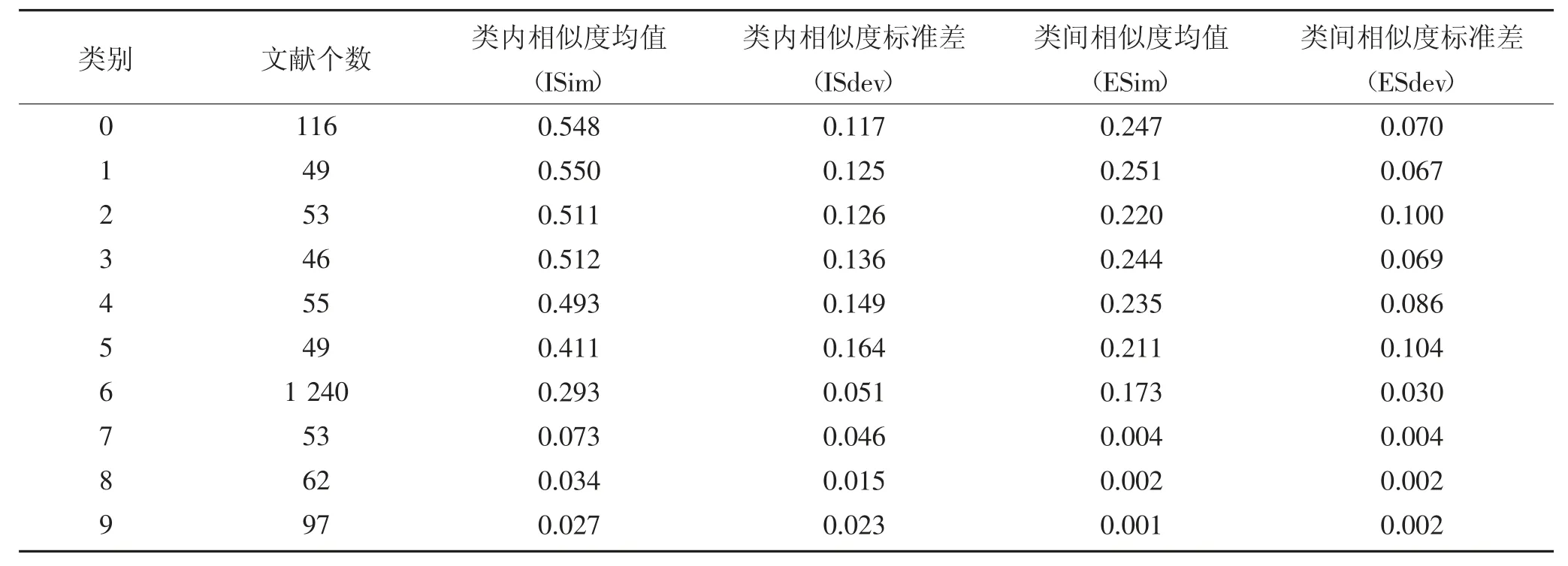
表3 聚类结果评价信息Table 3 Evaluation of clustering results
其中,类内相似度衡量的是同一簇中元素之间的紧密程度,ISim 值越大且ISdev 值越小,说明类内元素之间越相似且元素间属于同一簇越稳定;类间相似度用来衡量不同簇间的区分程度,ESim 值越大且ESdev越小,表明簇间的区分越明显,形成不同的簇越稳定。
2 基于文本挖掘的聚类主题抽取
完成聚类分析之后,综合类标签与共词分析方法挖掘类簇中隐含的主题,进而分析食品安全领域研究的热点。
首先,利用gcluto 软件评价各关键词对聚类结果的贡献率,衡量指标分别是Descriptive 描述性和Descriminating 区分度,选取各类别中贡献度最高的关键词作为该文献的类标签,依此来反映文献研究的主题内容,表4 为聚类评价的描述度和区分度结果。
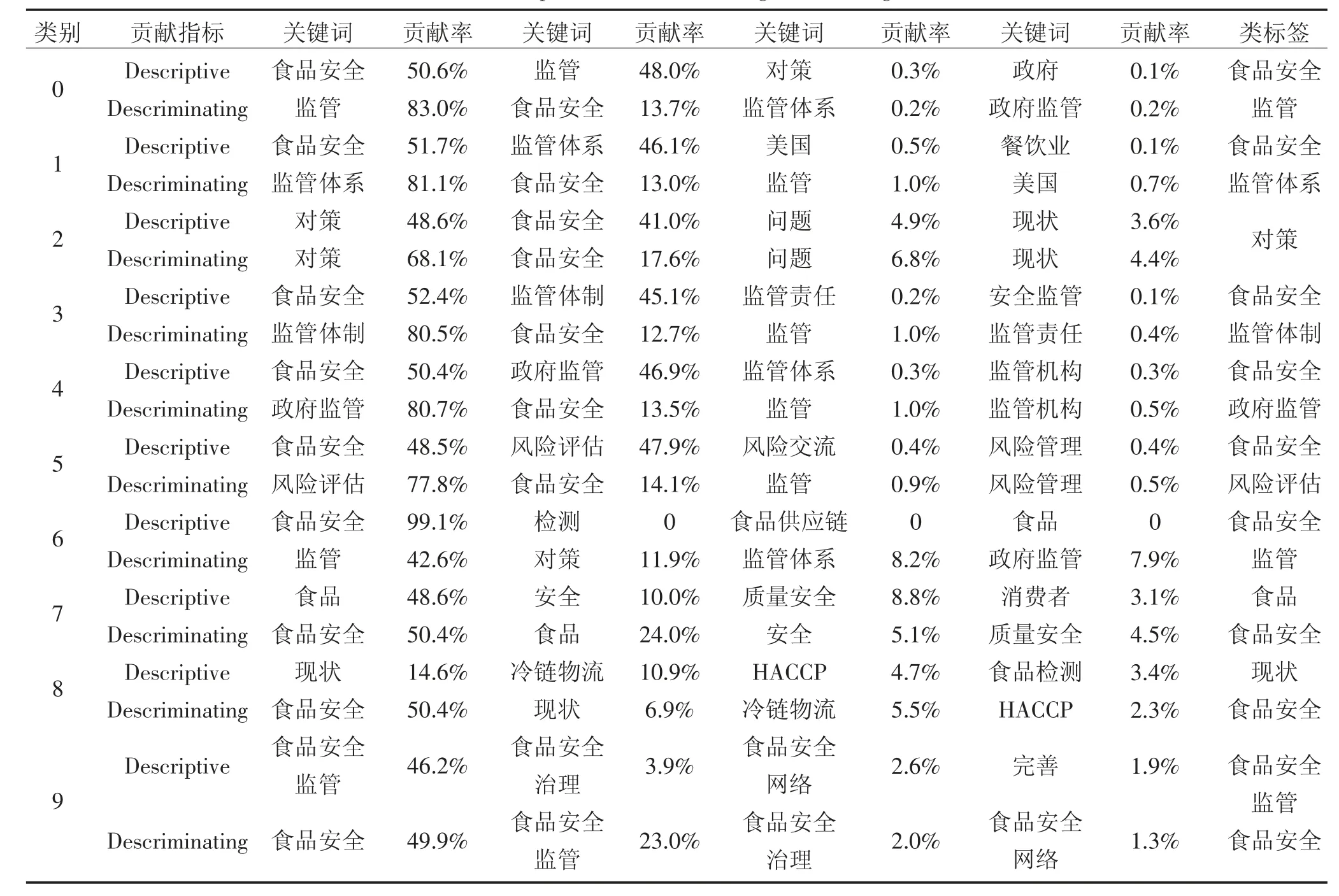
表4 聚类评价的描述度和区分度Table 4 Descriptive and discriminating of clustering results
其次,共词分析法[32]作为建立在统计关键词或主题词等词频基础之上,依据词频和共现频次信息,分析词语所代表的学科、研究热点、发展趋势、主题的一种文献计量方法[33-34]。为全面分析文献关键词之间的关系,挖掘食品安全领域研究现状,采用共词分析方法对文献关键词的出现频次和与之共现的词语序列个数进行统计,计算出关键词之间的连接强度——Total link strength(公式4)。
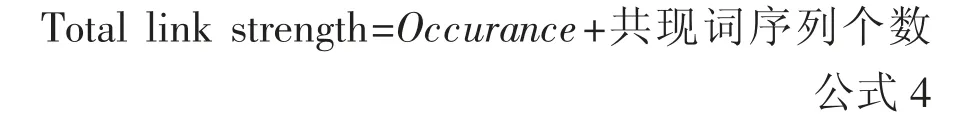
Occurance 表示各关键词出现的频次信息,Total link strength 是用来衡量关键词之间的关联强度,一般认为,当两关键词共同出现在不同文献中的次数越多或某一关键词与多个关键词出现在不同文献中越多,说明关键词间或与之关联的单个关键词的关联强度越强。
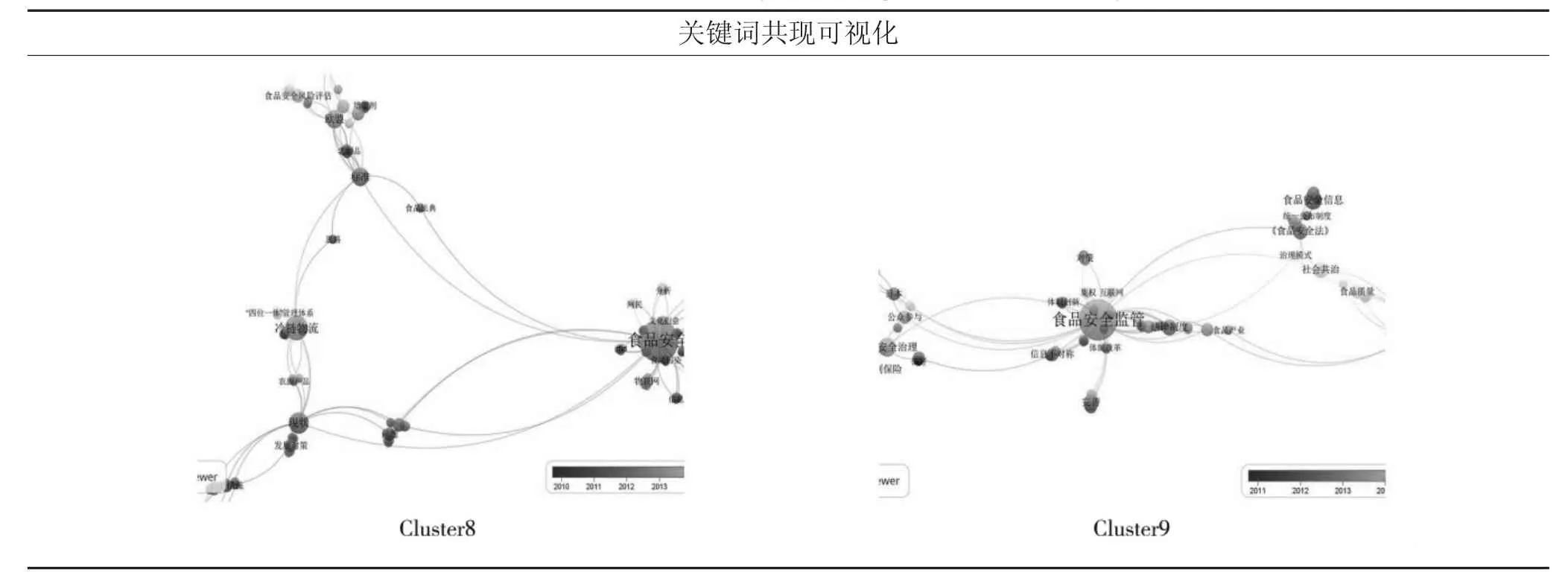
关联强度作为衡量两个词语之间紧密关系的重要指标之一,使用可视化方式可以显示关键词之间的共现关联关系,即将各关键词以圆圈表示,线条指示关键词间的关联关系,圆圈的大小反映关键词的关联强度强弱,圆圈越大说明关键词的关联强度越强,反之,则越弱。表5 为聚类结果中每类文献的关键词共词分析和可视化结果。

表5 关键词共现分析可视化Table 5 Visualization of keyword using co-occurrence analysis method
续表5 关键词共现分析可视化Continued table 5 Visualization of keyword using co-occurrence analysis method
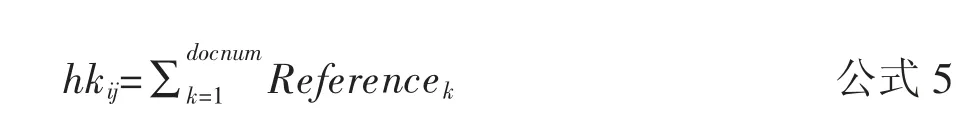
最后,采用综合类标签和共词分析方法,发现在食品安全领域研究的主题主要包括:食品安全监管、食品安全监管体系、食品安全对策、食品安全监管体制、食品安全政府监管、食品安全风险评估、食品安全与食品、食品安全与质量安全、食品安全现状、食品安全标准、食品安全与冷链物流等。
3 国内食品安全领域主题热度分析
由于食品安全领域的研究主题是随着时间动态变化的,为了分析文献研究中的关键词热度,采用一种基于文本挖掘和文献计量[35]的关键词热度[36]计算方法,用包含关键词i 并且发表在第j 年的论文的引用频次之和来表示词i 在第j 年的热度hyij。
式中,i 代表关键词,j 表示论文发表的年份,k 代表文献,Referencek表示包含关键词的文献k 在第j 年所被引用的频次,对其进行求和,即可得到关键词i 在第j 年的热点,docnum 表示总的高被引文献个数(篇)。
由于新发表的文献存在内容较新,熟知的人数较少,总体呈现被引用次数低于发表年份久的文献。因此,为了更加客观地衡量关键词的热度,将公式5更新为公式6:
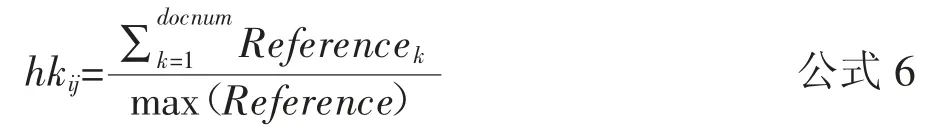
式中,max(Reference)是含有关键词i 且发表在第j 年的最高被引文献的引用频次。使用公式6 可以得到文献关键词在相应年份中的热度值,图3 为构建的关键词——年度热度矩阵。
图3 关键词—年度热点矩阵Fig.3 The hotspots matrix of‘keyword—year’
一般情况下,发表时间较新的文献往往能指示新的研究趋势,成为研究热点的可能性越大,因此,考虑到这个条件,为关键词赋予一个年度权值,即发表年度较近的关键词赋予较高权重,反之,赋予较小的权重。权值计算如公式7。
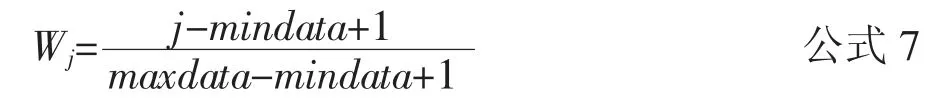
式中,maxdata 和mindata 分别代表文献发表年度的最大值和最小值,j 是当前的年份。将关键词i 在不同年度的热度值加权求和,即得到关键词i 的热度heati,计算如公式8。

图3 为收集的高被引文献中的关键词热度分析结果。
图4(a)中可以总结出食品安全领域研究的基础性文章呈现明显的阶段性特点。具体体现在:自2009~2013 年食品安全领域研究热点主题单一,主要集中在“食品安全”主题研究,其他研究主题发展缓慢;2013~2017 年期间波动,在2013~2015 年食品安全领域研究热度稍缓,随后一年热度迅速增加。并且在2013~2017 年间,有关“监管”主题热度迅速上升,统计历年食品安全事件发生情况,发现在2013~2017年的食品安全事件较之前呈现上升趋势;2017~2019年度,研究主题呈现多元化且“食品安全”主题热度下降,“食品”“标准”“质量安全”“对策”等研究主题热度不断升温,“政府监管”主题热度下降。
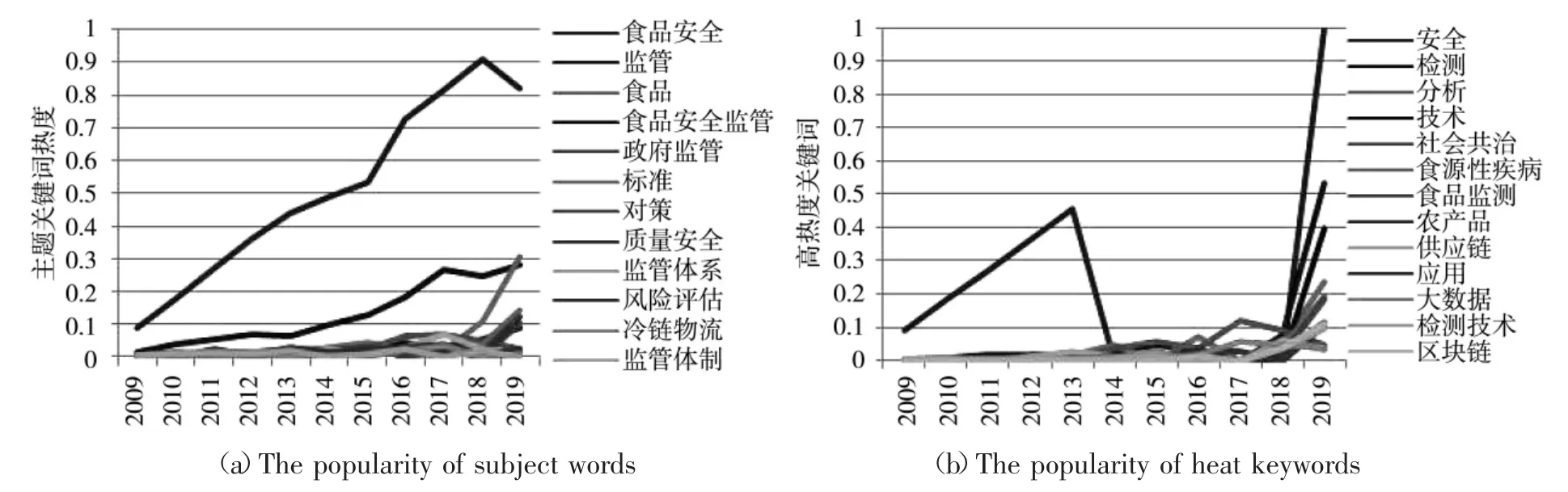
图4 食品安全领域关键词热度趋势Fig.4 The popularity of keywords in the food safety field
此外,除了主题关键词热度之外,还出现一些其他的高热度关键词,图4(b)中可以看出,在2017~2019 年两年内,新的关键词呈现出两个方面的研究热点:一个方面是有关新技术领域的研究热点,表现在“检测”“分析”“技术”“供应链”“大数据”“检测技术”“应用”“区块链”等关键词热度不断增强;另一方面,集中在社会存在的主要问题方面,热度较高的关键词如“安全”“社会共治”“食品检测”“农产品”“食源性疾病”等有所体现。
4 结论
随着网络信息化的不断发展,使得每天产生的数据量以指数式增长。非结构化的文本文献也迅速增加,文本挖掘作为可以从大量文本数据中抽取出有用信息,进而形成知识以此帮助人们进行决策的有力工具,在各个领域中的应用研究不断加强。食品安全领域作为与人们生活和社会发展息息相关的重要方面,挖掘其研究热点对于把握社会发展方向和了解人们生活需求有重要作用。通过收集中国知网中有关“食品安全”的文献,抽取各文献中的关键词进行聚类分析,并综合类标签和共词分析等量化方法,挖掘食品安全领域研究主题,评价其主题相关的关键词热度,从而较为客观地反映了本领域内的研究现状和发展趋势。以下是相关研究的总结。
国内关于食品安全的研究一直是热点,并且在2009 年至今仍不断升温。分析其受重视的原因可能体现在:食品安全问题与人类生活息息相关,并伴随着社会发展速度的加快和人们生活水平的不断提高,食品安全问题将越显突出。同时,食品相关的标准、质量安全、对策、技术方面的热度也不断上升,而政府监管、监管体制热度则下降,这从侧面反映出随着信息公开化程度的加深,公众监管越来越发挥重要作用。
随着Bigdata、AI、Cloud Computing 等新技术的发展,未来如何将食品安全领域与新技术相结合,是研究者面临的一个新的前景和挑战。
