基于VGG16和迁移学习的高分辨率掌纹图像识别
2021-10-05吴碧巧邢永鑫王天一
吴碧巧,邢永鑫,王天一
(贵州大学 大数据与信息工程学院,贵阳550025)
0 引 言
掌纹作为一种重要的生物特征,和指纹一样,可用于身份验证、身份识别、公共安全等多个领域。低分辨率掌纹图像的分辨率介于75~150 dpi之间,以照相机、摄像机等采集为主[1],多为非接触式采集的掌纹图像,其研究成果相对较多[2-4]。高分辨率掌纹图像的分辨率在300 dpi以上,采用扫描仪扫描掌纹,属于接触式采集的掌纹图像。高分辨率掌纹图像由于其分辨率高,所以尺寸会较大,对其进行处理的计算成本也更高,但细节特征点很多[5],包含丰富的信息,在公安刑侦领域和法律层面都具有重要的应用。在犯罪现场不仅会留下指纹,还会留下残缺或完整的掌纹信息[6]。
目前,对高分辨率掌纹图像的识别主要采用对掌纹轮廓、掌纹主线、褶皱线、细节特征点、三角点等特征点进行特征提取、匹配的方法。Jain等人[7]以细节为特征,用固定长度的细节描述符,捕获每个细节周围的独特信息。基于对齐的匹配算法用于匹配掌纹,对实时扫描手掌图样和潜在掌纹的识别率分别为78.7%和69%。Feng等人[8]提出了掌纹表示的Gabor幅相模型,将Adaboost算法引入模型训练中,将所选弱分类器的加权线性组合的响应值用于细节可靠性测量和不可靠的去除。Fei等人[9]提出了圆边界一致性,使用加长的Gabor滤波器设计来获取更可靠的细节特征点。Liu等人[10]对掌纹匹配设计了基于细节簇和细节匹配传播的粗略匹配策略,识别准确度为79.4%。由于受到3条主线和噪声的强烈影响以及图像采集时的不规范行为,高分辨率掌纹图像的部分区域图像质量较差,传统的掌纹识别方法在方法设计上复杂,识别时间长且识别效果不理想。
深度学习能够通过自动学习从大数据中获得有效的特征表示并进行识别,免除了繁杂的特征提取算法和掌纹匹配过程,但对训练数据的数量和质量要求较高。目前,高分辨率掌纹数据库大多数据量小且单个的掌纹图像大,直接在深度学习网络使用难以达到好的识别效果。
针对以上问题,本文以VGG16为基础网络,提出基于迁移学习的掌纹识别技术。利用迁移学习,通过共享特征把从源域学习到的信息迁移转换到目标域中,以解决目标域带标签样本数据量较少的识别问题。本文使用由自然图像组成的ImageNet预训练网络模型得到初始化权重,由于ImageNet训练的神经网络偏向于纹理,因而适用于对高分辨率掌纹图像的识别。针对数据量小,单个数据大的问题,可利用图像增强技术将单张的高分辨率掌纹图像进行等大小的裁剪分块,得到同一个掌纹的不同块掌纹作为新的数据集,增大了数据集进行图像的识别,对同一张掌纹图像的不同块掌纹块进行投票得到一个更好的识别效果。
1 卷积神经网路和迁移学习
1.1 卷积神经网络
卷积神经网络源自于Lecun等人提出的LeNet[11],包含一系列的卷积层、池化层和全连接层。卷积层使用一组可训练的卷积核对输入图像进行特征提取,卷积层的参数共享机制大大减少了参数的数量[12],使得参数的数量与输入图片的大小无关,增加了网络的泛化能力。池化层一般在卷积层后,主要有平均池化和最大池化,池化层在保留特征图主要特征的情况下,可以通过减少特征图的大小来减少参数量,防止网络过拟合,提高模型的泛化能力。全连接层的核心操作是矩阵向量乘法,前一层所有神经元与后一层的所有神经元相连。因为全连接层所有神经元都相连的特性,一般全连接层的参数是最多的,存在着一定的参数冗余。全连接层一般位于网络模型的最后几层,处理前面卷积层提取到的高级特征,在整个卷积神经网络中扮演着“分类器”的角色。
1.2 VGG16模型
VGG模型是由Simonyan等人于2014年提出的[13],模型非常简单,只有卷积层、最大池化层和全连接层。VGG模型首次提出了小卷积核的优势,在卷积层使用非常小的(3×3)的卷积核,添加更多的卷积层使得网络变得更深。使用2个3×3的卷积核可以代替5×5的卷积核,使用3个3×3的卷积核可以代替7×7的卷积核[14]。使用更小的卷积核可以减少网络的参数,提升网络的深度,增强了网络的表达能力;同时更多的使用非线性激活函数,可以提高网络的判断能力。VGG网络在图像识别领域的成功运用,代表着更深层的网络,可显著提升图像识别的效果。
VGG网络中所有卷积层的卷积核大小都是(3×3),几个卷积层后面接一个最大池化层为一个block。VGG16的网络结构如图1所示。VGG16共有5个block,每个block的通道数一致,最大池化层减少特征图的尺寸。随着卷积层一层层的运算,卷积核输出的内容越来越抽象,保留的信息也越来越少,特征图的尺寸也越来越小,通道数越来越多,以提取更多的抽象特征。Block5完成后将特征图平铺成一维数据作为全连接层的输入。最后3层为全连接层,前2层每层具有4 096个神经元,使用Relu非线性激活函数,第3层有1 000个神经元(1 000个类别)使用softmax函数。

图1 VGG16网络结构Fig.1 Network structure of VGG16
1.3 迁移学习
迁移学习的目的是将源于学习到的知识应用推广到目标域中[15]。在深度学习中,训练数据的获取至关重要,当训练样本不够时,往往识别效果也不尽如人意。有时因为客观原因无法获得足够的数据样本,或者大量没有进行标注的数据样本,无法直接使用,需要耗费大量的人力去标注,网络无法得到足够的训练。迁移学习则可以将从其它相似数据集上训练得到的网络权重迁移到目标网络,能够更快更好地进行参数的训练,而不必从头训练。
深度迁移学习主要有3种方式:使用其它数据集训练好的权重系数,作为初始化权重参数,进行接下来的训练;使用其它数据集的权重参数,冻结预测层之前的所有权重参数,进行接下来的训练;使用其它数据集训练好的权重参数,有选择地冻结一部分层,对其余层进行参数的更新和训练。
2 基于迁移学习的VGG模型
2.1 数据集以及图像预处理
目前存在的高分辨率掌纹图像数据库主要有2类:一种是公安部门采集的标准掌纹档案库(不公开),其次是实验条件控制下采集的公开用于科研的高分辨率掌纹图像数据库。本文使用的公开数据库为THU高分辨率掌纹数据库[16],该数据库中采集了80人的左右手掌,共有160个不同手掌的1 280张高分辨率掌纹图像。其中,单个手掌有8张掌纹图像。数据库中的每一张高分辨率掌纹图像的分辨率均为500 ppi,大小为2 040x2 040像素,大部分掌纹图像是灰度图像,但有少数掌纹图像是彩色图像。处理数据时,将所有的高分辨率掌纹图像读取为灰度图像。图2中显示了2张THU数据库中的高分辨率掌纹图像。数据库中有的掌纹采集的很完整,整个掌纹的脊线、褶皱、谷线、主线都被清楚的采集到,如图2中的(a)图所示。但也有少数的掌纹只采集到一部分掌纹信息,如图2中的(b)图,三条主线信息全部丢失。

图2 高分辨率掌纹图像Fig.2 High resolution palmprint image
在本文实验中,将采集到的每个手掌掌纹图像中的六张图像,即160×6=960张掌纹图像作为训练样本;其余的160×2=320张掌纹图像作为测试样本。数据集里原本高分辨率掌纹图像大小为2 040×2 040像素,为了减小运算量,提高运算速度,对数据集进行降采样预处理,处理后的掌纹图片大小为510×510像素。
2.2 VGG16深度迁移模型
本文使用在imagenet数据集上训练得到的权重参数作为初始化参数,训练识别高分辨率掌纹图像。虽然这些参数并不是针对高分辨率掌纹图像的,但这些参数对纹理有很好的分辨能力。高分辨率掌纹图像主要依靠纹理进行识别而非形状,理论上此迁移学习会有很好的结果。
将VGG16在imagenet数据集上训练得到的参数信息中卷积层部分的参数,用来初始化本实验的VGG16模型的卷积层参数。将原模型中的flatten操作换成全局最大池化操作,可以有效的较少参数数量,防止过拟合。将第3个全连接层的softmax激活函数换成relu激活函数,并在其后接一个全连接层160个神经元,代表着160个类别。softmax激活,得到预训练VGG16模型,如图3所示。增加一个全连接层能提升模型的非线性表达能力,综合前面卷积层提取到的特征,更好的完成分类任务。

图3 VGG16迁移模型Fig.3 Transfer model of VGG16
预训练VGG16模型的最后4层全连接层使用随机参数初始化方法,前3层的激活函数为relu非线性激活函数,最后一层是softmax激活函数。数据库中的掌纹图像基本为灰度图像,即图像的通道数为1,采用预训练模型的输入通道为3,故将高分辨率掌纹图像的通道复制3次,变成3通道图像。
2.3 在VGG16深度迁移模型上进行图片增强
预处理后的高分辨率掌纹图像大小为510×510像素,对预处理后的高分辨率掌纹图像进行数据增强的等分裁剪。
图4为按照不同的尺寸裁剪后的左上角的第一个掌纹图像块,可以看到,图片裁剪的越小,其包含的有效信息就越少。

图4 裁剪后的掌纹图像块Fig.4 Palmprint image blocks
表1为数据增强的数据,裁剪份数为将一个完整的高分辨率掌纹图像有重叠的等分后得到的掌纹块数量。分别有4组实验数据:4等分、9等分、16等分和25等分。其中,掌纹块为裁剪后单个的掌纹图像块大小,重叠部分为裁剪后2个相邻的掌纹图像块在一个维度上重叠的部分。

表1 数据增强数据Tab.1 Data of data enhancement
在一组实验中,如掌纹图像9等分实验,将训练集和测试集都进行同样的9等分裁剪的操作,会得到960×9=8 640个训练掌纹图像块,320×9=2 880个测试掌纹图像块。训练集会将裁剪后得到的掌纹图像块顺序打乱,送入VGG16深度迁移模型进行训练,得到训练好的参数模型。测试集则不打乱顺序,一张掌纹图像的9个掌纹图像块都是按顺序依次排列。将裁剪得到的掌纹图像块放入训练好的VGG16深度迁移模型进行测试,将得到每一张掌纹图像块的预测值。
将得到的预测结果进行重新排列。例如,对9等分得到的掌纹图像块的预测值处理为:将所有的预测值reshape对应为(320,9)的队列。其中320代表测试集的320张掌纹图像,一行有9个掌纹图像块的预测值,这9个掌纹图像块来自于同一张掌纹图像的不同部分。采用硬投票的方式,即直接用掌纹图像块的类别值,对每一行的9个掌纹图像块的预测值进行投票。基于少数服从多数的原则,票数多的预测值即为这张掌纹图像的预测值,若有2个类别投票结果一致,则随机选择一个预测值。320行每行都会得到一个预测值即为测试集的测试结果,再将该值与每个掌纹图像的标签进行比对,若相等结果为1,否则为0。求取所有结果的平均值,即为最后的测试准确率。
3 实验结果分析
实验均在Ubuntu18.04.4LTS操作系统上进行,采用tensorflow深度学习框架、i7-9700处理器、RTX 2080Ti显卡、32GB内存。所有实验都采用VGG16模型,损失函数默认使用Cross Entropy Loss、Adam优化器,Batch Size为8,学习率为1×10-5。
3.1 VGG16上的识别效果
将预处理后的数据集分别在随机初始化参数的VGG16与使用imagenet比赛中预训练模型参数的VGG16上运行。
图5为随机初始化参数的VGG16与使用imagenet比赛中预训练模型参数的VGG16的训练结果对比图。横坐标为训练次数,纵坐标分别为准确率和损失值。从图中可以看出,无论准确率还是损失值,相比于随机初始化的网络,采用预训练权重网络收敛的更快且更加平稳。
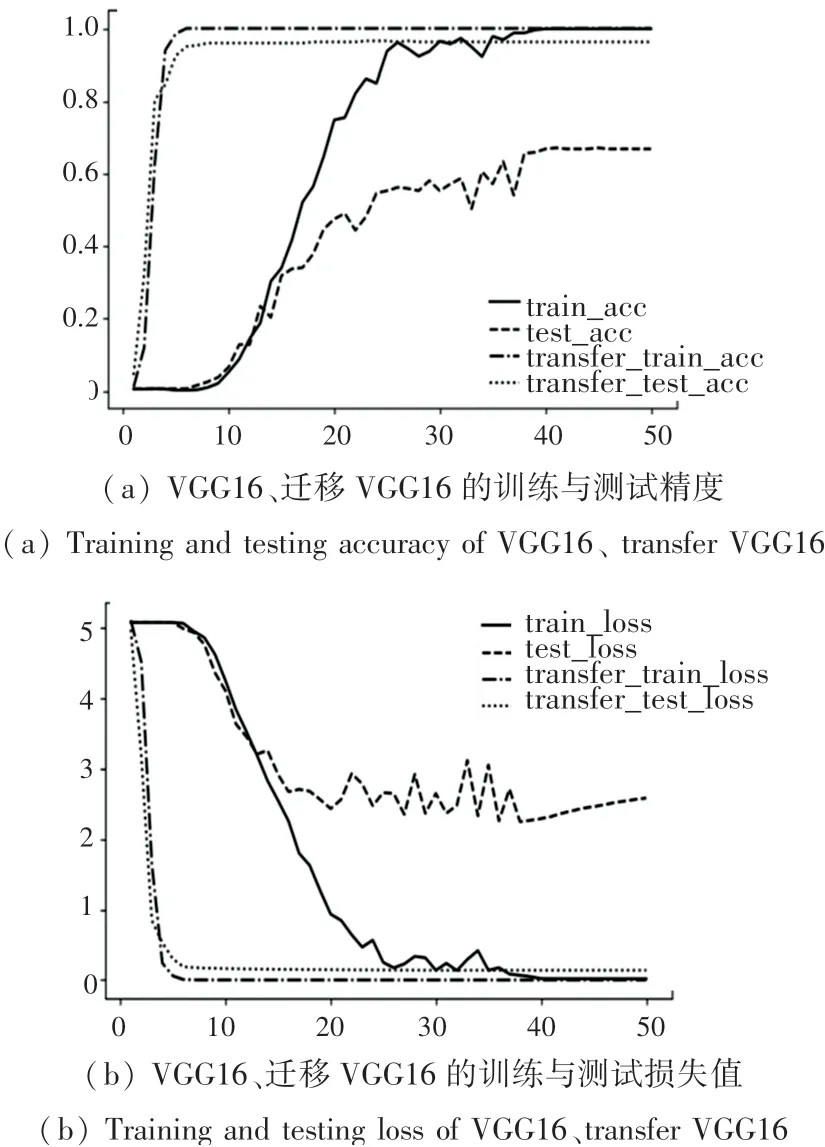
图5 VGG16运行结果Fig.5 VGG16 running results
由图5(a)可以看到,随机初始化参数的VGG16在第38个epoch时,训练达到最好效果。此时训练准确率为99.89%,测试准确率为66.87%。此后,训练准确率和测试准确率没有明显的变化,图5(b)训练损失值不再变化,而测试损失却开始增加,此时网络已经过拟合。而使用训练权重的网络在第5个epoch时训练准确率就已达到100%;测试准确率为95%,测试准确率在第17个epoch时达到了96.56%,之后不再变动。
3.2 基于迁移的VGG16上识别效果
图6为4组实验的准确率曲线图。从左至右分别是4、9、16、25等分掌纹图像块。曲线图的横坐标为迭代次数,纵坐标为准确率。由图可知,掌纹图像块的尺寸越大,包含的有效信息越多,测试准确率越高,而且曲线越平稳,波动越小。
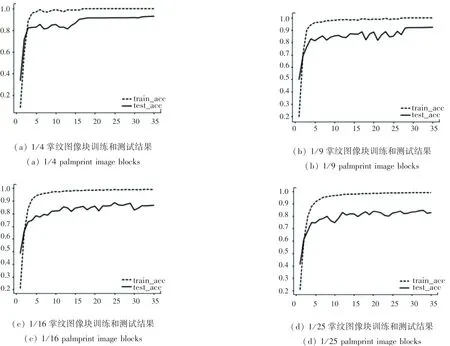
图6 不同掌纹图像块的准确率Fig.6 The accuracy of different palmprint image blocks
图7为裁剪成不同份数的掌纹图像的测试准确率。从图中可以看到,各个准确率曲线都存在一定的波动性,掌纹图像分的越小最后投票得到的掌纹图像准确率的波动性越小。因此尽可能地将图片裁剪,最后投票得到的准确率越高,且结果更加的稳定。25等分的掌纹图像的识别率最好,16等分略好于9等分,最差的是4等分。
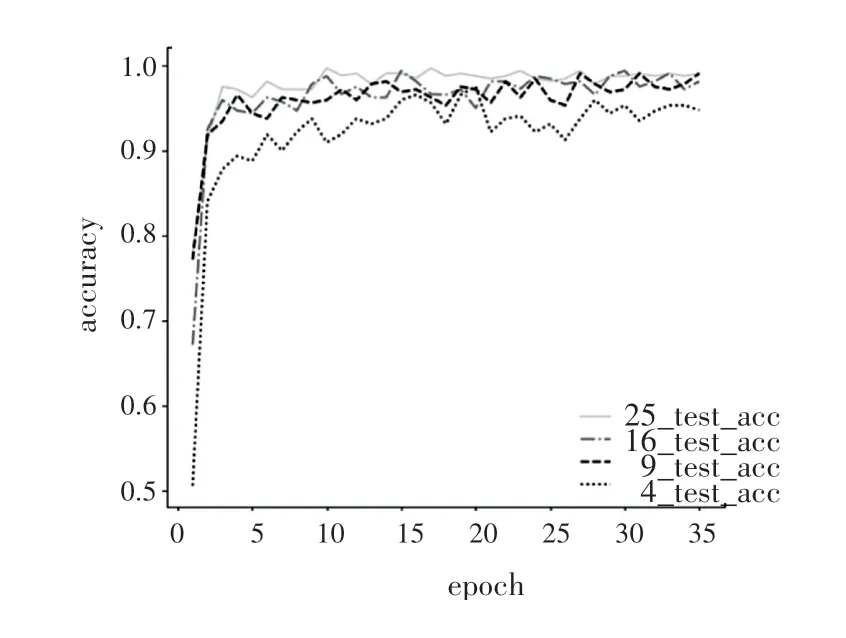
图7 不同裁剪份数掌纹图像测试准确率Fig.7 Test accuracy of palmprint images with different cropped copies
掌纹图片分的越小,就有越多的掌纹图像块参与投票,投票机制的容错率越高。另一方面,掌纹图像分的越多,总的重叠部分越多,4等分的重叠部分为90像素,9等分为180像素,16等分为210像素,25等分为240像素,对纹理的特征提取有更多的冗余,虽然有更好的识别精度,但也增加了计算成本。
表2为一张掌纹图像裁剪为不同的大小后掌纹图像块的测试识别率、掌纹图像的测试识别率与训练时间对比。由表可知,掌纹图片裁剪的越小,掌纹图像块的识别准确率也越低;掌纹图片裁剪的越小,掌纹图像块越小,单张掌纹图像块训练的时间也越少,但总的训练时间有所增加,其中,25等分的掌纹图像块的训练时间是4等分训练时间的两倍多。综合准确率与训练时间,最好的裁剪份数为9。9等分的图像准确率为99.06%,相比于没有裁剪的掌纹图像准确率增加了2.5%,训练时间增加了一倍。16等分、25等分掌纹图像准确率相比与9等分只增加了百分之零点几,训练时间却增加了28%和49%。

表2 不同裁剪份数的测试结果Tab.2 Test results of with different cropped copies
表3为不同算法的识别精度对比,可以看到,迁移学习可以极大的提升网络的识别精度。表中列举了4个其它方法得到的高分辨率掌纹图像识别率,都是采用的传统的机器学习,可以看到,本文提出的方法识别精度远远高于机器学习基于细节特征匹配的方法。

表3 不同算法识别率对比Tab.3 Comparison of recognition rates of different algorithms
4 结束语
目前深度学习的网络模型都需要大量的数据进行训练,数据量不够会出现网络无法训练或者过拟合,本文采用VGG16为基础网络,结合迁移学习的方法,对高分辨率掌纹识别的准确率能达到96.56%,采用了迁移学习的VGG16网络其在准确率、收敛速度和稳定性都优于随机初始化的模型。使用图像增强技术对高分辨率掌纹图像进行处理,以掌纹图像4等分、9等分、16等分、25等分为例,验证了掌纹图像分块识别投票算法的可行性。在实际应用中,考虑到计算成本和计算时间,选择将高分辨率掌纹图像9等分将会是更好的选择。
