基于局部异常检测的告警误报缓解*
2021-10-03范晓波胥小波
袁 齐,范晓波,胥小波
(中国电子科技网络信息安全有限公司,四川 成都 610041)
0 引言
随着网络应用和互联网技术的高速发展,计算机网络在提供生活便利的同时,也产生了大量的安全漏洞。互联网上充斥着各式各样的网络攻击,很多拥有大量网络资产的大中型企业,往往成为黑客的首要攻击目标,因此企业往往会部署多种安全设备。在这种背景下,企业内部的多种安全防护设备每天会产生大量的安全告警,一个中等的企业每天的安全日志告警数量通常在百万级别[1],企业安全运营人员难以对这些安全告警逐一分析调查,也无法定位出真正高威胁的告警。因此,安全运营人员疲于处理大量安全误报,而真实的恶意攻击行为被淹没在警报中没有得到及时处理。
告警误报缓解[2]旨在去除大量的误报,从而使得安全运营人员集中精力分析真正的高危告警。告警误报缓解是异源多构网络空间知识高质量转化的需要,海量网络空间信息的正确决策对智能化程度有更高的要求。网络空间行为是由信息主导的,但制约正确决策的并非是信息本身,而是从海量数据中提取重要信息的能力。告警误报缓解是网络态势理解的前提,只有进行过整理、解释、选择后生成的知识层面的网络空间信息才能有效用于态势理解。一方面,应着重关注网络空间信息大数据挖掘的研究,从而加强对网络空间态势的抽象理解,如网络空间态势的感知判断,信息内部因果关系的理解,网络空间知识的搜索、判断、归类和度量,对不同格式数据(结构化和非结构化)的自动分析等;另一方面,应当对专家知识等已有的成果和结论加以高效利用,比如可以组织经验丰富的网络安全专家为生成的样本集添加标签,形成数据资产,以提高网络空间信息处理能力。
一般来说,传统的告警缓解方法大都基于规则[3]采用前件与后件的工作方式,当告警满足前件时则忽略该告警或者将该告警置于优先级较低的队列。近年来,由于规则方法的局限性,很多工作探索数据驱动的方法进行告警缓解,如将告警看作是一种特殊的“语言”采用递归神经网络进行分析[4],或是基于生成对抗网络的进行系统日志级检测[5]等。而在文献[6]中,作者利用先验知识采用聚类的方法进行告警关联验证。
本文提出一种新的基于局部异常检测的告警误报缓解方法对攻击网际互连协议地址(Internet Protocol,IP)进行画像,该方法蕴含的1 个基本前提是绝大部分告警都是使用自动化工具发起的尝试性攻击,真正高威胁的攻击相对是比较少的。那么,从攻击阶段、攻击频次、攻击者地域特征等维度去刻画,真实高威胁的攻击会偏离正常范围。
1 模型和框架
网络安全监控已经逐步走向成熟,目前很多工具旨在监控并发现针对自身网络里的攻击行为,如防火墙、入侵检测系统(Intrusion Detection System,IDS)[7]、入侵防御系统(Intrusion Prevention System,IPS)[8]、主机监控设备等,以全局、“自上而下”的方式监控每个服务和设备。每个监控设备都会产生大量的日志,安全信息和事件管理中心(Security Information and Event Management,SIEM)[9]对所有的安全日志进行归一化处理和保存,以便对企业的安全状态有一个全面地认识,典型的SIEM 中告警日志处理流程如图1 所示。
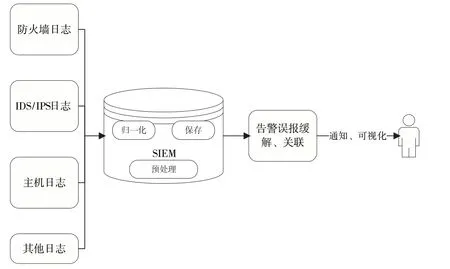
图1 SIEM 中日志处理流程
通常来说,一方面,监测设备为了不遗漏攻击事件,发现任意攻击特征就上报事件,这种攻击特征检测是非常宽松的;而另一方面,糟糕的开发者通常对用户的输入不进行过滤、转义等处理,两者相互配合造成大量误报,开发者编码不规范,导致这种误报更加泛滥,从而掩盖真实攻击。
本文提出的基于异常检测的告警误报缓解系统如图2 所示。图中特征层基于数据拉取模块拉取的数据,定期通过特征工程计算源攻击IP 最近一段时间的统计特征,在特征空间中刻画源IP 的行为特征,并将特征数据存入数据库中。在训练阶段,对于某个攻击IP 来说,获取其前一段时间的特征数据用于训练异常检测模型,模型评估与验证模块对训练的模型进行交叉验证,若通过验证则保存模型。检测阶段则用保存的模型对当前的告警日志进行实时检测,输出真实、高危的告警。告警误报缓解可以去除大量的误报,从而使得安全运营人员集中精力分析真正的高危告警。值得注意的是,由于数据漂移等问题存在,在经过一段时间后,模型可能并不适用当前数据分布情况,因而模型需要定期进行更新。
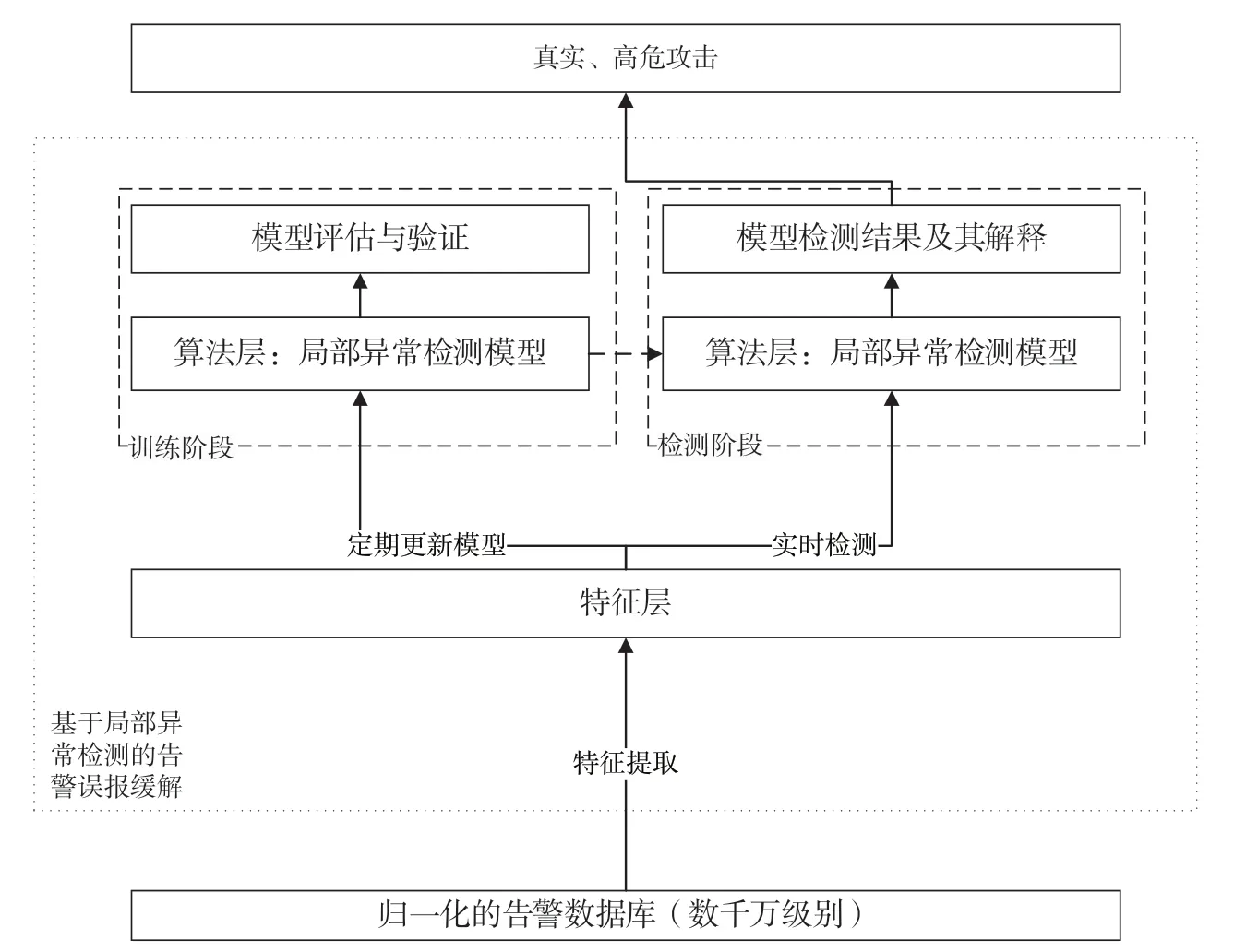
图2 基于异常检测的告警误报缓解流程
2 局部异常检测
2.1 特征工程
对于机器学习模型来说,数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限。本文异常检测的特征主要分为基本属性特征和统计特征两大类。不管是统计特征还是属性特征,都需要将原始日志如事件类型、执行的动作、设备源等通过配置文件中的特征字典映射为对应的数值编码,并通过数值编码来表示严重等级或者可信程度。属性特征用0-1 就可以进行编码,表明攻击者是否具备某个属性,如是否命中威胁情报字段,可以用1 表示命中,而0 表示未命中。模型主要的属性特征如图3 所示。
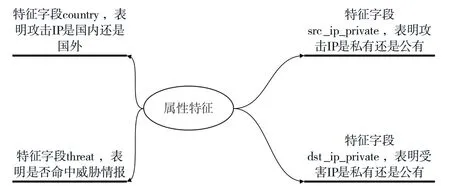
图3 属性特征及说明
针对告警阶段等强相关数值特征,则采用统计特征分别从总量特性sum、最大值特性max、唯一值特性unique 3 个维度进行刻画。如图4 所示,其中攻击阶段是指告警事件在网络攻击生命周期杀伤链(kill-chain)7 个阶段中所处的位置。杀伤链7个阶段用来拆分恶意软件的每个攻击阶段,包括侦查跟踪、武器构建、载荷投递、漏洞利用、安装植入、命令与控制、目标达成等。
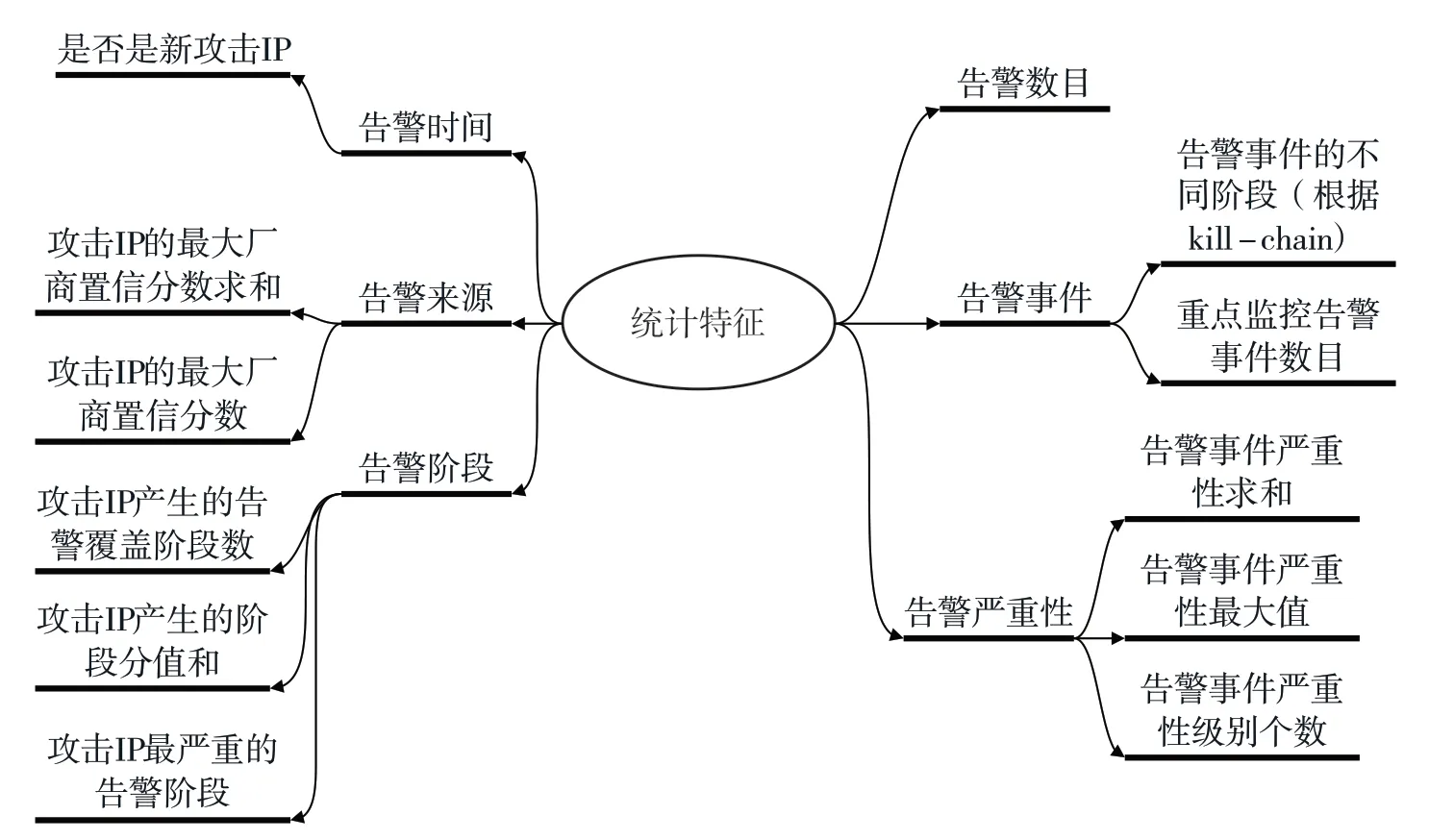
图4 统计特征及说明
属性特征和统计特征的具体说明如下文所述。
(1)属性特征说明:例如源IP 是国内或国外、是否命中威胁情报、源IP 和目的IP 的内外网类型。
(2)统计特征说明:通过主键(源IP 和资产标识两个字段)进行聚合之后对每个原始日志字段进行对应的聚合函数(主要是求和函数sum、最大值函数max、唯一值函数unique)得到对应的特征字段。
2.2 异常检测算法
真实的攻击日志通常和实际监控网络环境(拓扑、业务、资产、漏洞等)息息相关。通过将上述系统部署到真实的线上环境中,抽取高维特征数据进行可视化分析,告警日志通常会形成相关簇。例如,对于提供公网服务的企业来说,在外网中部署的设备较多,使得产生的告警日志中外网占了大部分,内网少部分;相反,对于内网业务系统较多的企业来讲,内网中部署的设备较多,使得产生的告警日志中内网占了大部分,外网少部分。此外,内网和外网的安全设备类型也不一致,产生的告警类型也不同。因此,内网和外网产生的告警数量以及类型不同,其通过特征工程后形成了两种相对独立的分布。如果选择孤立森林(Isolation Forest,iForest)[10]或者直方图异常(Histogram-based Outlier Score,HbOS)[11]这种全局的异常检测算法,在进行检测的时候会将少量的簇判定为异常,从而造成误判。
不同的攻击方向关注的告警类型也不一样,在3 种攻击方向外网到内网、内网到内网、内网到外网中,其特征显然是不一样的。如从外到内更多关注的是扫描、漏洞攻击、挑战黑洞(Challenge Collapsar,CC)攻击、暴力破解等,内网之间则更关注横向渗透、内网服务、蠕虫传播等[12]。
本文在异常检测中采用局部异常因子算法(Local Outlier Factor,LOF)[13-15]。LOF 局部异常检测依赖每个点p和邻域点的密度来判断该点是否为异常,点p的密度越低,越有可能是异常点。而点的密度是通过点之间的距离来计算的,也就是说,LOF 算法中点的密度是通过点的k邻域计算得到的,而不是通过全局计算得到。LOF 的计算依赖如下几个定义。
(1)k-邻近距离。在距离数据点p最近的几个点中,第k个最近的点跟点p之间的距离称为点p的k-邻近距离,记为k_distance(p)。
(2)可达距离。可达距离的定义跟k-邻近距离是相关的,给定参数k时,数据点p到数据点o的可达距离reach_dist(p,o)为数据点o的k-邻近距离和数据点p与点o之间的直接距离的最大值,计算方式为:
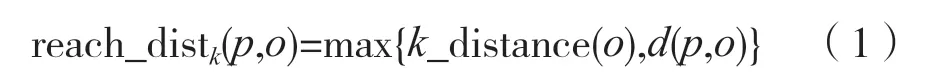
数据点p的局部可达密度(local reachability density,lrd)的定义是基于可达距离的,为它与邻近的数据点的平均可达距离的倒数,具体为:

式中:Nk(p)是那些跟点p的距离小于等于k-distance(p)的数据点集合。
(3)局部异常因子。根据局部可达密度的定义,如果一个数据点跟其他点比较疏远的话,那么显然它的局部可达密度就小。但LOF 算法衡量一个数据点的异常程度,并不是看它的绝对局部密度,而是看它跟周围邻近的数据点的相对密度。局部异常因子即是用局部相对密度来定义的。数据点p的局部相对密度(局部异常因子)为点p的邻居们的平均局部可达密度跟数据点p的局部可达密度的比值,计算方法为:
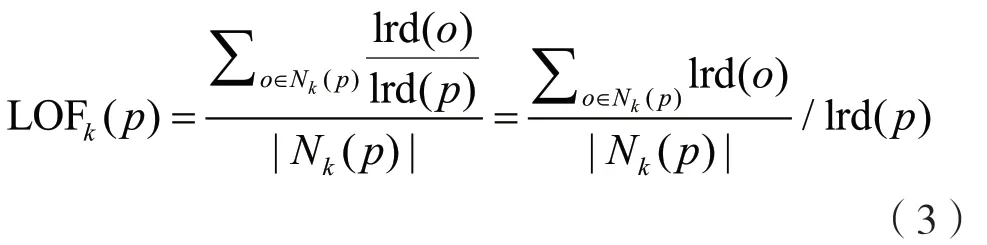
根据局部异常因子的定义,如果数据点p的LOF 得分在1 附近,表明数据点p的局部密度跟它的邻居们差不多;如果数据点p的LOF 得分小于1,表明数据点p处在一个相对密集的区域;如果数据点p的LOF 得分远大于1,表明数据点p跟其他点比较疏远,很有可能是一个异常点,从而实现异常检测。
3 实验结果与分析
本文系统在公安部组织的2021 年针对国内基础设施系统的大型攻防演练中进行实验。攻防演练持续14 天,采集了流量侧日志(绿盟综合威胁探针uts、天眼分析平台)、防火墙日志和终端告警日志,日志分布情况如图5 所示,从图中可以看出大部分日志为流量侧日志。
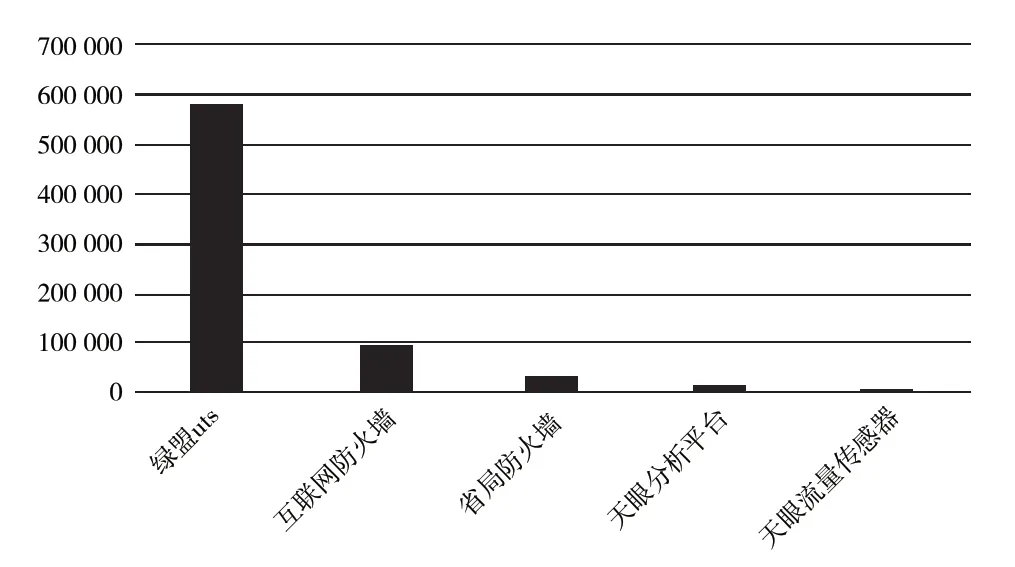
图5 日志分布情况
在攻防演练中的每一天,都统计上报被封的IP数目、算法检测IP 数目及算法检测的真实攻击IP数目,记录结果如表1 表2 所示。
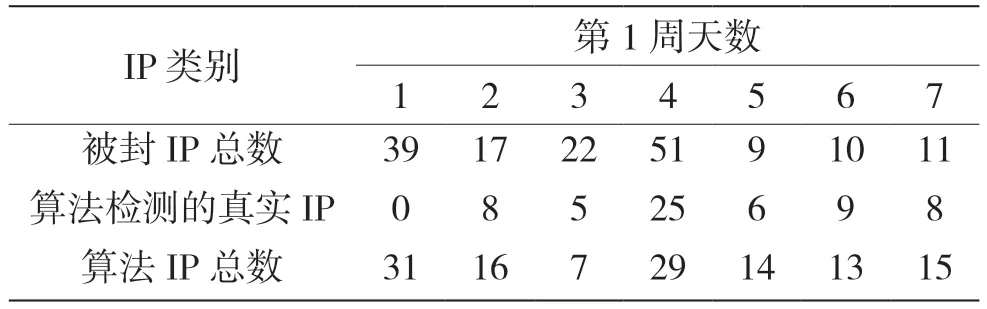
表1 第1 周IP 数统计
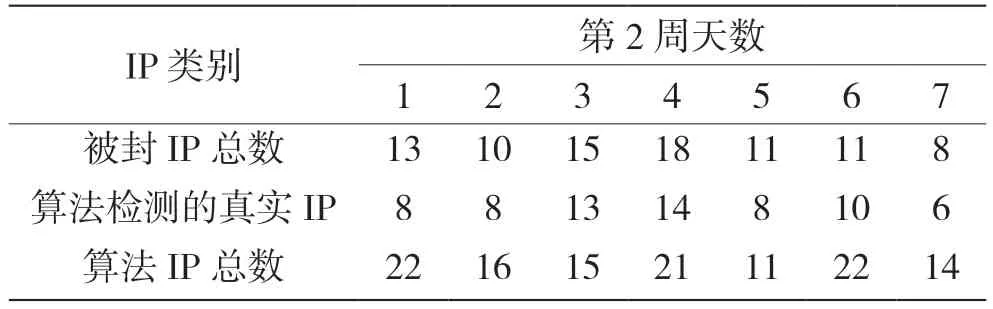
表2 第2 周IP 数统计
值得注意的是,表中仅包含安全分析人员通过分析网络态势感知系统攻击日志进行上报的IP 数,不包括通过主机上的普通业务日志进行研判封堵的IP,也不包括其他厂商上报的IP,因为这些IP 无法从攻击日志中进行分析得到。
由表1和表2中可以看出,攻防演练开始的时候算法检测的性能较差,其原因是:一方面,异常检测算法需要训练数据的沉淀;另一方面,需要根据实际情况进行算法调优,包括超参数和特征等。除去开始的第1天,后面13 天的平均检测精度P(Precision)为0.59,平均召回率R(Recall)为0.69。精度的定义是算法检测的正确攻击IP 数,占检测IP 总数的比例;而召回率为检测的正确攻击IP 数,占实际攻击IP 的比例。两者计算如下:
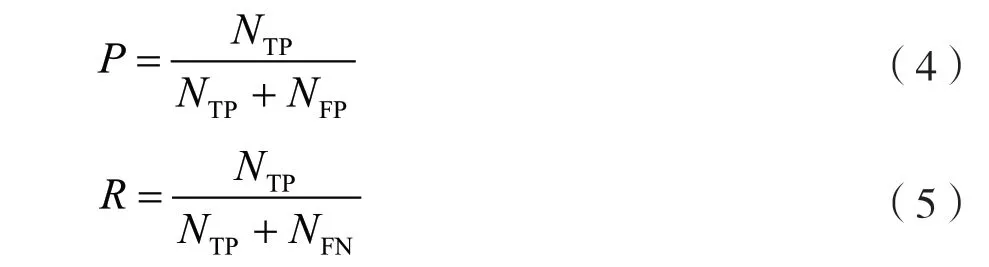
式中:TP 为被判定为攻击IP,NTP为攻击IP 的数目;FP 为被判定为攻击IP,NFP为正常访问的数目;FN为被判定为正常访问,NFN为攻击IP 的数目。
根据精度和召回率的定义,本文提出的基于局部异常的算法检测出IP 中接近六成的IP 属于真实的攻击IP,且检测的真实攻击IP 占所有真实攻击IP 总数的七成。
此外,将本文提出的算法性能和监控设备内置的规则进行比较,规则输出将所有的告警日志分为4 类:很高、高、中、信息,从而在日志量巨大的情况下使得安全分析人员关注等级为“很高”的日志。图6 为基于规则的不同等级占比显示每个等级的日志占比,由于整个攻防演练期间,被封的真实IP 总数为245 个,而等级为“很高”的日志数目为24 718,其最高精度为245/24 718 ≈1%,与之对应的,本文算法精度为59%,和只采用规则相比,该算法可以极大减少分析人员的时间。
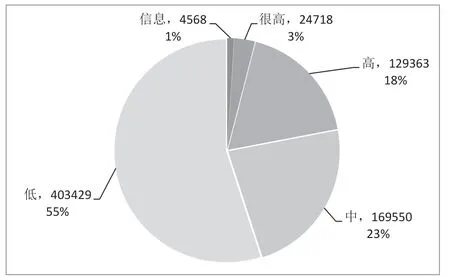
图6 基于规则的不同等级占比
4 结语
针对企业安全运营中存在的海量告警问题,本文提出一种新的告警误报缓解方法,基于真正高威胁的攻击相对是比较少的事实,该方法采用局部异常检测算法从攻击阶段、攻击频次、攻击者地域特征等维度去刻画攻击IP 的偏离正常范围的程度,从而去除大量的误报,使得安全运营人员集中精力分析真正的高危告警。该方法在大型网络攻防实战中进行部署,结果表明具备较好的检测性能。
