面向NDN 的网络攻击检测技术分析*
2021-10-03王枫皓
王 鑫,王枫皓
(1.解放军91404 部队,河北 秦皇岛 066000;2.解放军61001 部队,北京 100000)
0 引言
现代互联网核心需求已向数据共享转变,致使传输控制协议/网际协议(Transmission Control Protocol/Internet Protocol,TCP/IP)网络由于种种缺点已经不适应这种转变趋势。为了满足需求的转变,迫切需要改变现有的网络架构。
命名数据网络(Named Data Network,NDN)由于理念先进、方案可行、社区活跃,从众多“革命式”的网络架构中脱颖而出,成为一种主流网络架构。它独特的安全机制克服了现有IP 网络的安全缺陷,但也面临着许多新的安全挑战。现阶段针对命名数据网络的攻击手段层出不穷,如兴趣包泛洪攻击(Interest Flooding Attack,IFA)、缓存污染攻击等。如何快速准确地检测相关的攻击手段,以支撑后续的防御方案制定,是学术界研究的一个重点方向。
本文阐述NDN 相比IP 网络的优势,分析其面临的安全威胁,阐述两种典型的网络攻击方式,并分析相应的攻击检测技术及其存在的优缺点,探讨其未来可能的发展方向。
1 NDN 安全优势及面临的威胁
NDN 网络颠覆了IP 网络架构,将网络的核心从主机地址转变为数据内容。此外,独特的内生安全技术有效解决了现有IP 网络中的一系列问题,但也面临着许多新的挑战。
现有IP 网络中面临的主流攻击方式有拒绝服 务/分布式拒绝服务攻击(Denial of Service/Distributed Denial of Service,DoS/DDoS)、嗅探(Snooping)攻击、篡改(Modification)攻击、数据流分析(Traffic Analysis)攻击、伪装(Masquerading)攻击、重放(Replay)攻击以及抵赖(Repudiation)攻击。不同的攻击方式对信息的影响不同,如表1 所示。
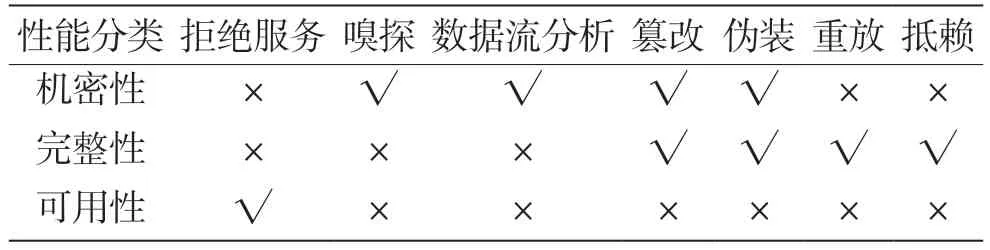
表1 不同攻击方式对安全的影响
嗅探攻击、数据流分析攻击影响信息的机密性,未经授权的用户能够轻易访问网络中的消息。重放攻击、抵赖攻击影响信息的完整性,无法保证数据的准确性和可靠性。篡改攻击、伪装攻击会影响数据的机密性和完整性。拒绝服务攻击通过多种攻击方式,使得目标服务或者主机直接瘫痪,影响信息的可用性。
NDN 网络架构确保了完整性和机密性,避免了IP 网络中存在的主流攻击行为。生产者对内容的签名认证保证了数据的完整性。假设中间节点截获数据,对其进行嗅探,由于数据经过加密,攻击者并不能解析出真正的数据内容。如果攻击者对数据做了篡改,由于数字签名的存在,消费者在接收到数据包后验证不通过,则会丢弃篡改的报文,因此篡改攻击不能生效。伪装攻击的基础是IP 地址。NDN 网络并不通过IP 地址进行路由通信。NDN 架构由于兴趣包Nonce 字段和待转发兴趣表(Pending Interest Table,PIT)表项的存在,能够实现流量聚合,避免重放攻击带来的威胁。签名能够保证数据的不可抵赖性。拒绝服务攻击由于主要攻击信息的可用性,因此在NDN 中仍旧存在拒绝服务攻击的威胁,但是攻击方式产生了变化。
NDN 创新性的架构能够避免现有IP 网络中面临的一系列安全问题,如重放攻击、数据篡改等,也存在新的安全威胁。目前,针对NDN 网络的一系列攻击方式不断更新,主流的攻击方式有兴趣包泛洪攻击和缓存污染攻击。兴趣包泛洪攻击和缓存污染攻击已经成为NDN 实际部署中的巨大阻碍。如何检测上述攻击行为是成功防范攻击的重要前提。如表2 所示,IFA 攻击主要发起者为消费者应用,而缓存污染攻击(Cache Pollution Attack,CPA)的攻击发起需要多方配合。下面结合实例说明具体攻击方式和现有的检测手段。

表2 主流攻击方式及其特性
2 主流攻击方式的检测技术研究
2.1 兴趣包泛洪攻击
兴趣包泛洪攻击的主要目标是网络中的路由节点。攻击者构造大量的兴趣包消耗网络链路带宽源,导致PIT 表项溢出,影响网络中的消费者应用、生产者应用以及路由节点,最终阻碍数据的正常获取。
如图1 所示,攻击者通过向网络中不断发送兴趣包,使得边缘路由节点过载,丢弃用户发出的兴趣包和服务端返回的数据包,最终阻碍了用户正常获取数据。

图1 兴趣包泛洪攻击
GASTI[1]指出DND 中同样存在DoS 攻击,为兴趣包泛洪攻击。作者将DND 中的兴趣包泛洪攻击方式分为3 种,分别为请求大量已存在或者静态的内容(Pre-existing/Static Prefix Interest Flooding Attack,pIFA/sIFA)、请求大量不存在的内容(No-existing Prefix Interest Flooding Attack,nIFA)和请求大量动态生成的内容(dynamic Prefix Interest Flooding Attack,dIFA)。对于第1 种攻击方式,由于NDN 路由节点中缓存(Content Storage,CS)的存在,攻击者发送的重复兴趣包会在边缘节点得到满足,不会对网络中心造成巨大影响。第2 种攻击方式会请求大量不流行的内容,使得整个NDN 网络无法发挥缓存优势,导致正常的兴趣请求会表现出较大的延迟。第3 种攻击方式会请求大量不存在内容,会使路由节点中PIT 表被大量不存在内容占用,使得正常的请求不能够得到满足。这种攻击方式是3 种攻击方式中最严重的。GASTI 提出了一种尝试性的对策来检测兴趣泛滥攻击,但是缺乏具体的方法论述。
SIGNORELLO[2]在上述基础上发展了bIFA 和cIFA 两种新式的攻击方式。bIFA 攻击中请求的数据包混合了存在的内容和不存在的内容,模糊了攻击源真实性,使得针对内容存在性的单一检测体系失效。cIFA 攻击方式主要请求的是不存在的内容,但是内容的命名前缀是可变的,掩饰了攻击源的攻击意图。
上述主流攻击方式中:静态前缀易于检测,对网络影响较小;动态前缀对网络影响较大,尤其是混合前缀攻击很难发现,对网络危害性大。综上所述,兴趣包泛洪攻击作为拒绝服务攻击在NDN 中的现实体现,与IP 网络中一样,深度威胁着网络安全。
2.1.1 兴趣包泛洪攻击检测方法
针对IFA攻击,AFANASYEV[3]从统计模型出发,提出了3 种算法。首先提出了基于接口公平性的令牌桶算法,原理与经典的令牌算法类似,不同之处在于出接口可用的令牌平均分配在入接口上,限制了每个接口可转发的兴趣包数量。其次,提出了一种基于兴趣包满足率的决策算法,以兴趣包满足率为基础产生一个随机数,由此决定是否接收此兴趣包。最后,提出了基于兴趣包满足率的回退算法,在每个接口上都对兴趣包满足率进行限制,然后向全网传播。此方法改进了每个接口的统计数据,提升了全网兴趣包满足率,从而间接缓解了兴趣包泛洪攻击带来的危害。但是,这3 种方法在对接口进行限制时均使用的是概率算法,导致合法的兴趣请求很大概率上被忽视。
DAI[4]为PIT 表设定一个阈值,仅通过检测PIT大小是否超过阈值来判断兴趣包泛洪攻击是否发生。当超出阈值时,合法用户的请求将会被判定成泛洪攻击。这种检测方式过于简单,缺乏细粒度的思考。
COMPAGNO[5]提出了一种名为Poseidon 的方法。Poseidon 为两个参数设定阈值,一是传入兴趣包和传出数据包的比率,二是每个接口的PIT 空间。在某个接口上如果检测到两者均超出阈值,那么就判定此接口受到攻击。与DAI 相比,COMPAGNO在此基础上考虑兴趣包满足率,而与AFANASYEV相比加入了对PIT 大小的考虑,在误检测率上相比两者都低。
TANG[6]将检测分为粗检测阶段和精准识别阶段。它为接口定义了一个相对强度指数(Relative Strength Index,RSI),并预先设定了一个阈值。如果相对强度指数高于阈值,则表示某一时段不断接收兴趣包,返回数据包较少,是受到兴趣包泛洪攻击的显著体现,由此进入精准识别阶段。在精准识别阶段,路由器计算超时前缀的超时率。如果超时率超过设定的阈值,那么表示此前缀的兴趣包为异常兴趣包,很有可能是攻击者发起的攻击。此方法在接口检测的基础上进一步检测命名前缀,实现了细粒度攻击检测,但是并没有考虑到PIT 大小。
WANG[7]提出了基于前缀超时的PIT 禁用策略(Disabling PIT Exhaustion,DPE)。每个路由节点通过一个m-list 表记录每种命名前缀过期的数目,并设定一个阈值。如果超过阈值,则将此前缀指定为恶意前缀,在后续接收到此前缀的兴趣包时不再缓存在PIT 表中,而是直接转发至下游节点。此种方法对cIFA 的效果显著,但是同样前缀的合法兴趣包可能会被误判,直接判定为攻击行为。
之后,WANG[8]又提出了一种基于模糊测试的方法。每个路由器定期监测PIT 占用率(PIT Occupancy Radio,POR)和PIT 超时率(PIT Expired Radio,PER)。POR 是给定时间间隔内当前PIT 条目数与最大PIT 条目数之比。PER 是给定时间间隔内过期PIT 条目数与未决PIT 条目总数的比率。POR 和PER 都充当模糊变量。检测机制使用它们来检测兴趣泛滥攻击。当模糊变量之一变高时,检测到攻击。其中,PIT 表项过多或PIT 表项过期的前缀可被视为恶意前缀。本文中检测基于POR,当兴趣包到达率增加时,POR 会增加。但是,有时POR 也会由于合法的流量突发而增加,可能会导致误报。由于这种方法基于PIT 超时率,因此对聚合兴趣包泛洪攻击无效。COMPAGNO[5]等人的方法优于这种方法。
KARAMI[9]提出了一种基于多目标优化的径向基神经网络(Radial Basis Function-Particle Swarm Optimization,RBF-PSO)方法来检测兴趣包泛洪攻击,能够很好地检测针对已存在命名前缀的攻击、随机前缀以及前缀劫持攻击。RBF-PSO 中选用12 个特征值作为RBF 神经网络的输入层,使用NSGA-Ⅱ多目标遗传算法选择优化RBF 神经网络基函数中心,并利用粒子群优化算法(Particle Swarm Optimization,PSO)优化RBF 的输出权值,训练得到神经网络用于检测兴趣包泛洪攻击。但是,此方法并没有阐述12 个特征值的选取理由。此外,神经网络的训练使用固定拓扑的流量数据,导致RBF-PSO 方法依赖于网络拓扑。不同的拓扑并不能使用同一种分类器进行检测。
TAN[10]提出了一种基于广义似然比检验算法(Generalized-Likelihood Ratio Test,GLRT)的兴趣包泛洪攻击检测方法,以期望的告警概率为参数,计算检测阈值。
VASSILAKIS[11]将焦点集中于边缘路由器,计算单位时间内过期PIT 条目数来检测恶意消费者。
XIN[12]提出了一种基于非参数化递归算法(Cumulative Sum,CUSUM)的方法来检测接口上兴趣包命名前缀的熵平均值。如果熵超过预定义的阈值,则检测到攻击。检测到攻击后,利用相对熵来识别恶意命名前缀。文中的策略通过命名前缀的变化,观察是否遭受到攻击,因此这种方法无法检测cIFA。
DING[13]分析了兴趣包泛洪攻击的3 个特性,即分布式攻击、高请求频率以及请求不存在的内容。这3 种特性在网络中的具象为命名前缀的PIT占用率、PIT 超时率和潜在攻击率(Potential Attack Radio,PAR)。同时,将路由器划分为“正常”“风险”“未知”3 个状态,状态值由3 种特性的具象的平方和的平方根确定。据此开发了一种马尔科夫模型,用以检测是否有攻击存在。这种方法比WANG[8]提出的方法性能要好,因为除了POR 和PER 之外,还将PAR 作为参数。
SALAH[14-15]提出了一种集中控制的检测方法,通过NDN 路由器(NDN Router,NR)收集基本数据,通过监控路由器(Monitor Router,MR)收集相关信息,计算得到PIT 利用率(PIT Used Radio,PUR)和PIT到期率(PIT Expired Radio,PER)。当PUR 超过预定义的阈值且PER 的值为正时,则检测到攻击。检测后,过期的命名前缀被MR 视为是恶意的。但是,过多的信息交互会产生更多的开销。
XIN[16]提出了一种基于小波分析的聚合兴趣泛洪攻击检测方法。与其他流量相比,聚合兴趣泛洪攻击对应的流量的功率谱密度较低,所以利用子带的平均攻击强度来检测攻击,并通过实验选择检测阈值。
KUMAR[17]选取6 个参数通过不同的机器学习方法来检测兴趣包泛洪攻击,并实验比较了不同的机器学习方法,结果显示模拟和实现的兴趣泛洪攻击检测的准确性几乎相同。
ZHI[18]给出了一种基于基尼不纯度(Gini Impurity,GI)的兴趣泛洪攻击检测方法。路由器计算特定时间段内观察到的一组命名空间的GI。当GI 的相对变化超过一定的阈值时,会检测到攻击。检测到攻击后,通过用新集合中相同名称空间的概率替换旧集合中每个名称空间的概率,同时计算这两个集合之间的差异。如果差异为负,则认为前缀是恶意的。因此,这种方法检测cIFA 是可行的,因为在cIFA 中攻击者攻击多个目标前缀时命名前缀的GI 会保持不变。
2.1.2 小结
上述的各检测方法可分为3 类,分别为基于统计模型、基于概率模型和其他方法。相关分类以及特点如表3 所示。
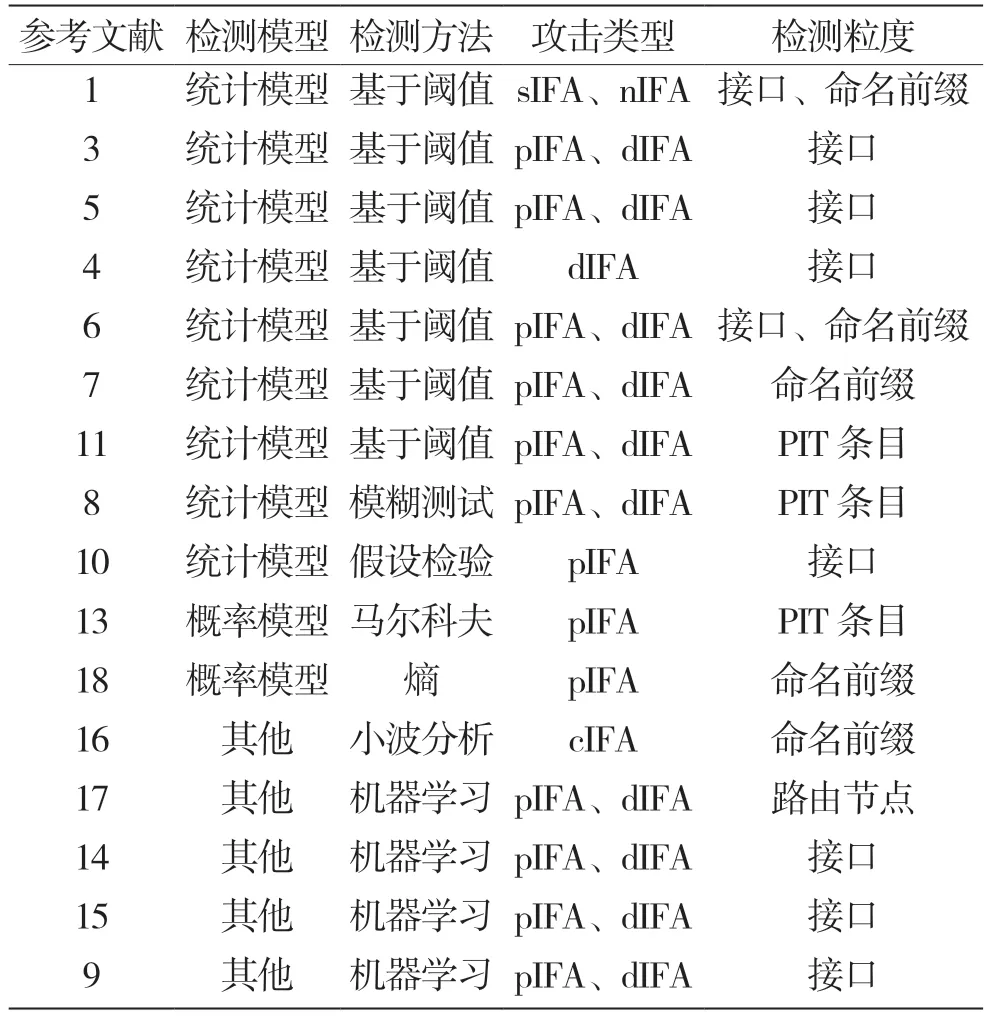
表3 兴趣包泛洪攻击检测方法的对比
从检测模型分类来看,基于统计模型的方法最多的是基于阈值的检测,其次是基于模糊测试和假设检验的测试。基于概率模型的方法有基于马尔科夫模型的检测和基于熵的检测。其他方法则有小波分析和机器学习。
从检测的攻击类型来看,主要关注的是pIFA和dIFA,其他类型的攻击没有必要进行深入研究。对于cIFA 和bIFA,大多数方法没有很好的策略进行检测,所以对cIFA 和bIFA 的检测是未来值得关注的重点之一。
从检测的粒度来看,主要分为路由节点、接口、命名前缀以及PIT 条目。所有的检测方法应该关注细粒度的检测,以精确识别攻击者的意图,从而采取针对性的策略。
此外,IFA 攻击检测应该能够较快速检测出各种攻击行为,同时占用较低的计算存储性能。
2.2 缓存污染攻击
缓存污染攻击的主要目标是边缘路由节点的CS 表。增大数据获取时延的攻击方式分为破坏内容分布特性攻击(Locality Disruption Attack,LDA)和伪造内容分布特性攻击(False Locality Attack,FLA)两种[19]。LDA 和FLA 的攻击看似相似,实际上攻击方式不相同。LDA 是通过请求不流行内容,耗用缓存资源。正常用户在请求流行内容时,因为边缘NDN 节点CS 资源被不流行内容占用,所以缓存命中率会明显下降。FLA 的攻击目的是伪造高热度内容,欺骗NDN 路由节点,取代CS 中真实的流行内容,使得伪热度内容在网络中长期驻留,如图2 所示。

图2 缓存污染攻击
污染目标数据的攻击方式有对已有内容的污染和对未来将要请求内容的污染两种[20]。对已有内容的污染是指攻击者通过控制全网拓扑中某一路由节点,在消费者发送兴趣请求时返回伪造的错误内容,致使沿途的路由节点缓存已污染的错误内容。这样后续用户在请求时,会直接接收到错误内容。对未来将要请求内容的污染是指假设攻击者预测到某个特殊的内容在未来某个时间段会被请求,则可以通过已攻破的一台消费者主机提前请求此内容,同时控制一个内容服务器返回污染的内容,将污染的内容提前缓存在拓扑中的路由节点,之后当消费者在请求此内容时会直接接收到被污染的内容。
2.2.1 缓存污染攻击检测方法
针对缓存污染攻击(Cache Pollution Attack,CPA)攻击,XIE[21]提出了一种缓解缓存污染攻击的方法,称为缓存屏蔽。在这种方法中,CS 存储内容包括名称、频率以及实际内容的占位符。当路由器第一次收到内容时,它的占位符存储在CS 中,计数器最初设置为0。如果路由器接收到占位符已存储在CS 中的内容,则计算屏蔽函数,并决定是否缓存数据。如果缓存内容,则路由器用实际内容替换内容占位符,否则计数器增加。这种方法具有很高的空间和时间复杂度,因为路由器使用额外的空间来存储名称占位符,且每当它接收到内容时都会使用额外的CPU 周期来计算屏蔽功能。此外,作者没有讨论如何在同一个CS 中实现内容缓存和内容占位符。
CONTI[22]提出了一种检测LDA 和LFA 的方法。该方法由两个阶段组成,即学习阶段和检测阶段。在学习阶段,缓存算法通过随机抽样选择内容的ID来创建一个集合。路由器跟踪属于集合的内容,以计算用于检测攻击的阈值。在检测阶段,路由器计算测量的可变性。如果大于阈值,则表明有攻击。此方法相比XIE 的优点在于对内容进行随机抽样,具有占用内存小和计算开销低的优点。该方法的效果很大程度上取决于集合的选择。
XU[23]假设了这样的攻击场景,即攻击者为少量不受欢迎的命名前缀请求大量兴趣包,提出了一种能够检测此种攻击场景的方法,包括流量监控和识别两个阶段。在流量监控阶段,路由器使用轻量级基数估计算法(Lightweight Flajolet Martin,LFM)监控具有公共命名空间的不同兴趣包,并使用蒙特卡罗假设检验计算阈值。在识别阶段,路由器定期监控流量并计算结果。如果超过阈值,则标识正在受到攻击。这种方法内存占用和计算开销相对较低,但是只适用于特定的攻击场景,不能抵抗FLA 攻击。
GUO[24]分析在常规网络状况下同一内容的请求者应该来自于不同的网络域,并基于此提出了基于路径多样性的检测方法。NDN 骨干路由器为CS 中的每个内容维护两条信息,即内容被命中的次数和名为PathTracker 的数据结构(存储请求的兴趣包来源的路径数量)。根据命中次数,利用伯努利分布计算不同路径的预期数,再利用不同路径的预期数和命中数计算阈值,利用不同路径的实际数和命中数计算比较值。如果结果大于阈值,则表明受到了攻击。
SALAH[25]将节点分为3 类,即ISP 控制器(ISP Controller,IC)、监控节点(Monitoring Node,MN)和NDN 节点(NDN Node,NN)。MN 周期性地向IC 发送他们观察到的内容列表和请求内容的时间,然后IC 会根据它们的流行度形成一个命名前缀白名单,并将白名单的内容分发给MN,指示缓存名单中的内容,主要通知NN 缓存不在NN关联的MR 的白名单中的内容。这种方法确保流行数据始终缓存在网络中,减少了互联网服务提供商(Internet Service Provider,ISP)数据请求的数量。此方法通过集中控制全网缓存空间资源,将流行的内容始终缓存在网内,提升了NDN 网络内容分发的性能,但没有明确阐述对内容分发的技术。
ZHANG[26]提出了一种基于内容位置的缓存污染攻击检测和缓解方法。使用每个前缀的变异系数(Coefficient Of Variation,COV)和流行度两个参数来决定是否缓存。当路由器收到兴趣包时,路由器会更新其数据集,其中包含前缀、传入接口和频率等信息,用于计算COV。前缀的流行度是为其请求兴趣包的次数。当路由器收到数据包时,路由器会根据流行度和COV 的值决定是否缓存数据包。
PARK[27]提出了一种利用请求熵检测低速率LDA 攻击的方法。路由器将每个内容对象的名称映射到二进制矩阵,矩阵的索引表示在对名称进行散列并使用两个不同的正整数对结果取模后获得的值。如果对象存在一个特定的映射,则对应的值设置为1,否则设置为0。应用高斯消元后,矩阵的秩值用于检测请求随机行为的变化。指数加权平均用于平滑秩值随时间的变化,当秩超过预定义的阈值时,会检测到攻击。但是,这种方法将消耗路由节点巨大的计算资源。
KARAMI[28]提出了基于自适应神经模糊推理系统(Adaptive Network Based Fuzzy Inference Systems,ANFIS)的缓存替换策略。它使用神经模糊网络计算数据包的优度值,通过收集每个数据包的统计信息,将信息通过模糊神经网络细化优度值,将其用于缓存替换。ANFIS 可以应对大多数攻击,但由于方法独立运行于路由器,路由节点之间并无信息交互,因此有预谋的攻击者可以利用特定的策略攻击边缘路由节点,导致路由节点反而会不断缓存攻击者请求的内容,导致产生缓存污染攻击。
2.2.2 小结
对缓存污染攻击的检测方法同样可分为3 类,分别为基于统计模型的方法、基于概率模型的方法以及其他方法,相关分类和特点如表4 所示。

表4 缓存污染攻击检测方法的对比
从检测的模型分类来看,基于统计模型的方法占优势,基本都是采用基于阈值的检测方法、基于熵的检测方法,少数是基于机器学习的方法。
从检测的攻击类型来看,缓存污染的检测中,LDA 相比FLA 更容易检测。基于本地流行度的检测方案并不能应对FLA 攻击。大多数缓存污染攻击的检测方法都是基于阈值的策略,而阈值是根据路由器接收到的内容数据包计算而来的。如果内容流行度不高,则并不会缓存,所以FLA相比LDA更难检测。
3 展望
NDN 是一个开放的网络架构,使得NDN 攻击的检测更具挑战性。根据本文的分析,未来的研究主要集中在以下方向。
(1)对于兴趣包泛洪攻击的检测,不同的攻击场景应该不局限于一种方法。单一方法应对所有的攻击是不现实的,但是可以用可扩展的框架来囊括对所有攻击的检测,甚至新的攻击方式。
(2)在兴趣包泛洪攻击检测的粒度方面,应该遵循细粒度的原则,精准识别攻击针对的路由接口和命名前缀。
(3)对于缓存污染攻击,应该着重对FLA 攻击方式进行进一步深入研究,综合考虑局部流行度和全局流行度,因为FLA 可以影响局部流行度,依据局部流行度的策略可能会失效。
(4)对于兴趣包泛洪攻击和缓存污染攻击的检测,应该保持较低的内存占用和较少的计算开销。
(5)机器学习方法用于攻击检测,值得进一步探索。在固定网系中,使用机器学习的方式进行检测,即使依赖海量数据采集和大型计算资源消耗也能够实现,因为后台能够提供强有力的算力、带宽等资源支撑。但是,在分布式移动网络中,资源有限,基于机器学习的检测方法面临困境,所以NDN 应用于分布式移动网络,如小型无人机自组网。它的相关的检测技术值得进一步关注。
4 结语
DND 突破了原有IP 架构的限制,是下一代互联网主流的架构之一。但是,NDN 面临着新的安全隐患,如兴趣包泛洪攻击和缓存污染攻击。本文重点介绍这两种攻击方式,论述攻击检测手段,讨论不同手段的方法、检测对象以及有效性,最后强调了未来研究可能的方向,以便后续人员研究借鉴。
