基于SVM-RFE特征选择的规则提取方法
2021-09-29吴璐
吴 璐
(上海市规划和自然资源局 信息中心, 上海 200003)
0 引言
由于支持向量机(Support Vector Machine, SVM)具有坚实的统计学习理论基础和良好的泛化性能,已经被应用到客户分类和管理、银行信用风险评估、故障检测、地理遥感信息等[1-4]众多领域中,并取得了较好的成果。然而SVM和人工神经网络一样也存在着固有的缺陷,即其“黑箱模型”。人们很难理解其模型代表的意义,也无法对模型的预测结果做出一个合理的解释。SVM 学习到的知识蕴藏在由占样本总数很少的支持向量及其权重系数(Lagrange系数)所得到的决策函数中,用户无法了解SVM 到底学到了什么、能处理什么样的任务,也无从知道SVM 如何进行分类和预测、为什么得出这样或那样的推理结论。由于缺乏透明性,在数据挖掘和决策支持领域、以及在安全性要求很高如医疗诊断方面等关键应用方面,支持向量机和神经网络一样往往被认为是不可靠的和难以理解的,使其应用受到一定限制。
将支持向量机训练后生成的决策模型转变成更加直观、更易理解的知识的过程被称为支持向量机规则提取方法。它主要分为基于学习的方法和基于结构分析的方法两大类[5]。前者比较典型的算法如TREPAN、GEX、BUR等[6],后者如SVM + prototypes、RulExSVM算法等[7-9]。虽然这些方法在实际应用中取得了一些成果,但从总体上看,这些规则提取方法产生的规则大都数量比较多、精度不高、规则的前提条件项数太多、结构较为复杂,不便于人们的理解和解释。此外,这些方法对于研究领域的数据维度较高也不能很好地适应。
造成上述问题的主要原因主要在于过于强调准确率和忠实度指标,对可理解性重视不够以及没有对样本属性进行降维处理提高可理解性。对此本文提出了一种基于SVM-RFE特征选择(SVM-BASED Recursive Feature Elimination,SVM-RFE)的序列覆盖规则提取方法,将特征选择作为整个规则提取的一部分来进行综合考虑,并在规则生成和裁剪上通过采取包括生成的规则必须满足最低的精度要求、覆盖率大的规则优先选取、限制搜索深度和采用FOIL增益对条件项的增加进行评估对可理解性与准确率和忠实度指标之间进行平衡。
1 SVM-RFE特征选择算法简介
SVM-RFE特征选择算法是一种以支持向量机的分类性能作为特征选择评价标准的后向递归消除特征选择算法,具有较高的识别性能。它最早是由Guyon等[10]在基因选择中首先提出来的,并将其应用于癌症分类问题中进行基因选择,取得了非常好的效果。在这之后许多人又对 SVM-RFE方法进行了进一步的改进以提高它的性能和效率[11-12],目前已经被广泛应用于基因表达数据分析、蛋白质功能预测、图像检测、文本挖掘等多个领域。
SVM-RFE起始于全部特征,然后每次移去一个特征直到特征集合为空,移去的特征是所有特征中‖w‖2最小的一个。这样对某一变量i,排序评价准则如式(1)。
(1)
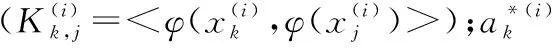
SVM-RFE方法通过不断迭代方式将具有最小排序系数的特征移除,然后利用SVM对剩余的特征重新训练以获取新的特征排序,最后得到一个特征的排序列表。利用该排序列表,定义若干个嵌套的特征子集F1⊂F2⊂…⊂F来训练SVM,并以SVM的预测正确率评估这些子集的优劣,从而获得最优的特征子集。
2 基于SVM-RFE特征选择的规则提取方法的实现
2.1 算法总体框架
基于SVM-RFE特征选择的规则提取方法的总体架构,如图1所示。
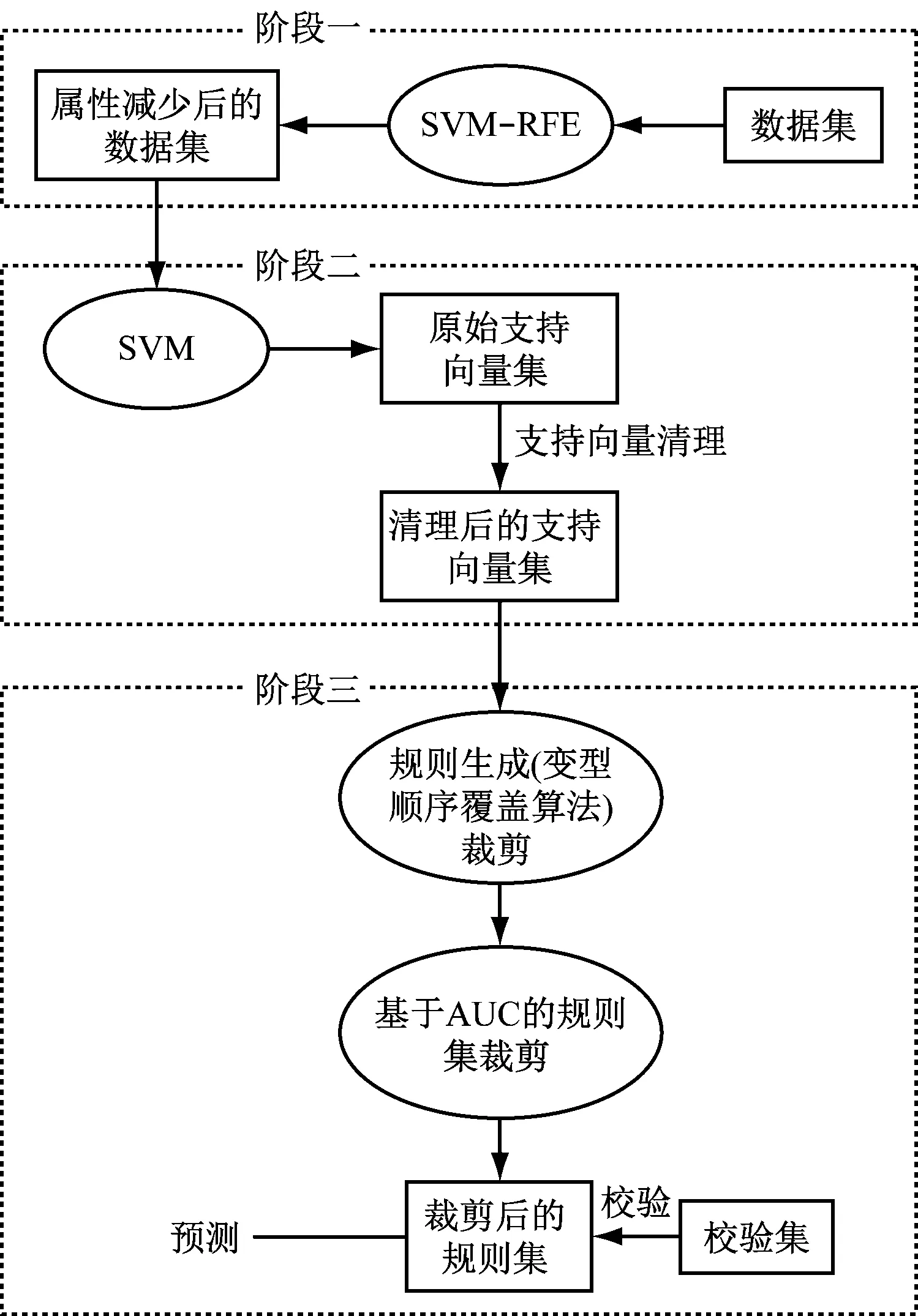
图1 基于SVM-RFE特征选择的规则提取知识表示方法的总体框架
主要包括基于SVM-RFE特征选择、支持向量机学习、规则生成和规则集裁剪等3个阶段。
首先,对初始数据集基于SVM-RFE特征选择算法进行属性约简。根据它们在SVM分类器的权值进行重要性排序,得到最优特征子集并去除原属性集中不相关和弱相关的属性。在使用SVM-RFE算法进行特征选择时,为了减少SVM-RFE算法对训练集的选取较为敏感、特征排序不太稳定的问题,我们通过在样本集随机生成多个训练集并综合排名的方式进行了优化和改进。
其次,用得到属性减少的样本集对支持向量机进行训练和学习,得到全部支持向量集。去除其中预测分类与样本原有的类标签两者不一致的支持向量,从而生成清理后的支持向量集。
最后,通过一种变型的顺序覆盖规则学习算法对这些清理后的支持向量集进行归纳学习生成规则集,然后通过AUCs的差异显著性对规则集进行裁剪,得到裁剪后的规则集。用验证集来对其进行验证,以确保其准确率(accuracy)满足规定的要求,通过上述验证后我们就可以使用得到的规则集来进行预测。本节后面重点对上述提到的这两部分进行说明。
2.2 基于优化的SVM-RFE算法特征选择
通过特征选择可以使提取规则的可理解性得到很大的改善,还能够提高分类器的识别率。这里采用基于支持向量机的特征选取方法,主要是由于它和支持向量机算法本身结合得更好,能够保证甚至提高支持向量机的识别精度。
基于支持向量特征选择选取方法主要分为Wrapper 、Filter和Embedded等[13]3种方法。考虑到Wrapper方法与学习分类器密切相关,构造的特征子集能够带来较高的学习能力,因此我们选择SVM-RFE这种方法,它在处理高维方面能力更强。当然SVM-RFE这种方法也有不足之处,处理速度相对比较慢。但是考虑到对于规则提取来说,特征选择的好坏更加重要,因此选择SVM-RFE这种方法还是比较值得的。
在使用SVM-RFE算法进行特征选择时,针对 SVM-RFE算法对训练集的选取较为敏感、特征重要性排序不太稳定的问题,我们通过在训练样本集随机生成多个训练子集并采用综合排名的方式进行了优化和改进。具体说明如下。
(1) 对于样本集{(x1,y1),(x2,y2),…,(xl,yl)},其中xi∈Rd,yi=±1,随机生成m个训练子集和测试子集对,其中m的取值根据样本的数量,属性维度和特征选择的精度要求等确定。
(2) 对每一个训练子集分别用SVM分类器进行训练,并用径向基函数作为支持向量机的核函数,这是由于在很多实际应用中发现它们具有较好的效果。惩罚参数和高斯核函数中的参数σ的值通过Grid search和10-fold交叉验证来确定。
(4) 对于每个特征根据其在最优特征子集出现的频度和位置,生成一个新的特征排序表。对每一个特征,按照式(2)进行加权求和并按照权值大小降序排序,得到一个新的特征排序表。
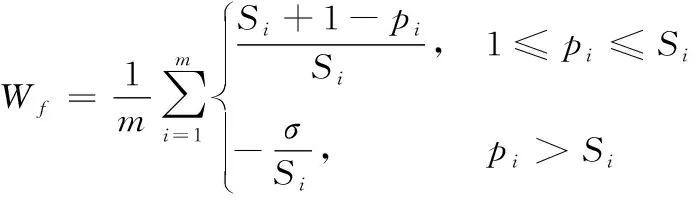
(2)
其中,Si为第i个随机训练子集上最优特征子集中特征的数量;pi为特征f在第i个随机训练集中最有特征子集中的位置;σ为惩罚系数(σ≥0),当其值越大特征出现的次数对权值的影响更大。
(5) 根据新的特征排序列表生成d个嵌套子集,在所有的随机训练子集上用这些嵌套子集重新训练SVM分类器,并将这些嵌套子集所训练的SVM在测试子集上的分类精度进行算术平均,算术平均值最高的所对应的嵌套子集作为最终的最优特征子集。
2.3 基于变型顺序覆盖算法的规则生成
在规则生成和裁剪阶段,从基于特征选择的规则提取的架构上来看,原则上基于学习的规则提取方法如TREPAN、C4.5、BUR、CART等和基于结构分析的提取方法如SVM+ prototypes、RulExSVM都可以直接用来进行规则的提取。 基于在规则提取算法设计和实现上把提高可理解性作为一个重要目标,兼顾可理解性与准确率和忠实度之间的平衡原则,我们还提出了一种变型的顺序覆盖算法(Sequentail Covering Algorithm)将前面所述的一些提高可理解性的策略应用到该算法的实现中以提高生成规则的可理解性。该算法通过对清理后的支持向量集进行归纳学习来生成规则集。
该算法采用从一般到特殊的柱状搜索方式,它在搜索过程中保留前面k个性能度量较高的选择以降低只保留最高性能选择容易造成的局部最优问题。另外它只产生覆盖正例支持向量的规则,即对于规则没有覆盖的实例默认为负例。为了提高规则的可理解性,该算法在学习单个规则的核心子程序Learn-One-Rule的中主要特点说明如下。
(1) 迭代过程中对属性值的划分采用动态方式,随着约束条件的增加不断调整,并且属性划分采用信息增益即式(3)进行性能评估选取最佳分割点;另外在同样性能条件下,离散属性优先,如式(3)。
(3)
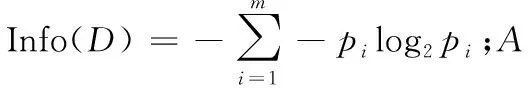
(2) 在搜索过程中为了保证生成的规则有较好的可理解性,强制其最大搜索深度为5,即条件前提项的项数不能超过5,这是因为当前提条件项数超过5个以后一般情况下人们已经不能很好理解。
(3) 在规则性能的度量上,采用FOIL增益即式(4)评估约束条件项增加前后的增益,当该值大于0时增加约束项才是有价值的。在此我们选取该方法的主要原因是与其他性能度量方法相比,FOIL增益更倾向具有高准确率并且覆盖许多正例的规则,这样有利于提高规则的可理解性。
(4)
其中,pos(neg)、pos′(neg′) 分别为条件项增加前后规则覆盖的正(负)例的数目。
(4) 生成的每一条规则都必须满足一定的精度要求,即其TPR/FPR>(TPR/FPR)min不小于(TPR/FPR)min,从而确保生成的规则有较高的精度。
Learn-One-Rule整个规则生成和裁剪的算法如下。
输入:
SVs(来自SVM学习阶段的结果——调整后的支持向量集)。
特征排序列表F(按照属性重要性降序排列,来自SVM-RFE的特征选择)。
(TPR/FPR)min(最小可接受的正例覆盖率/负例覆盖率比值)。
输出:
命题规则集R。
处理:
① 初始化S=SVs。
② 初始化Best_hypothesis=φ,Candidate_hypotheses={Best_hypothesis}。
③ 对于F中的每一个属性fi, 根据其属性值在S中的取值范围,寻找其最佳的阈值aib,它能在所有的样例S中根据式(3)得到最大的信息增益。
④ 按照上述排序顺序,对于F中的每一个属性fi分别用与其相应的在③中得到的阈值aib生成一个约束ci,生成约束集C。
⑤ 对Candidate_hypotheses中的每个假设h,按照特征排序列表F的顺序添加约束集C中没有添加过的约束,如已无法添加则直接删除。对于添加后的规则用式(4)评估其添加约束前后的FOIL增益,当其小于0时,将该条规则予以删除。这样得到新的假设集New_candidate_hypothesis。
⑥ 对New_candidate_hypothesis中的每个假设h,确定该条规则覆盖样本集S上的正例和负例数量,并由此计算它的TPR和FPR。如果假设h的TPR/FPR大于Best_hypothesis的TPR/FPR,则Best_hypothesis←h。
⑦ 选取New_candidate_hypothesis中TPR/FPR性能最好的k个规则来更新Candidate_hypotheses。
⑧ 如果Candidate_hypotheses=φ,返回到⑤。
⑨ 如果Best_hypothesis在样本集S上的TPR/FPR≤(TPR/FPR)min,将该规则添加到规则集R中,并将它所覆盖的SVs 从S中删除,并转到②。
⑩ 重复上述步骤②至⑨直到Stp中的所有SVs被覆盖或者生成的规则因不满足要求而被拒绝,规则生成算法终止。
3 实验结果及分析
本节进一步对本文所提出的基于SVM-RFE特征提取的规则提取算法的性能进行了验证。本算法是用MATLAB 7.8.0 (R2009b) 实现的,运行环境是一台CPU 为 Intel Core 2-Quad processor,主频2.8 GHz, 内存容量为4 GB的PC机,所用的SVM 软件工具是较为流行的Libsvm (3.1.7),其他对比的分类算法使用的是Weka 3.2相应的实现。
在实验中我们主要用可理解性(comprehensibility)、正确率(accuracy)和忠实度(fidelity)等指标来进行评价。可理解性用规则的数量以及规则中前提条件平均项数来对其进行度量;正确率用被正确识别的样本数占总样本的比率来度量;忠实率用抽取的规则与支持向量机预测相一致的样本数占总样本的比率来表示。实验主要采用了来自UCI库的10个数据集,在所有的数据集上用于训练和测试的数据比例为70:30,70%的数据通过10折交叉验证法(10-folders cross validation)用来对分类器进行学习和提取规则,剩下的30%用于评估所产生的规则集的性能指标。
下面以Heart desease数据集为例进行说明,该数据集共有13个属性和270个样本,其中属性1,4,5,8,10,12是连续值属性,其他则为离散值属性。在该数据集上随机生成60个训练和测试子集对,然后用SVM-FRE方法分别在这60个子集对上进行特征排序并确定其对应的最优特征子集,并按照式(2)对每一个属性在这60个子集上的最优特征子集中出现的频度和位置进行加权平均得到属性排序列表,如表1所示。
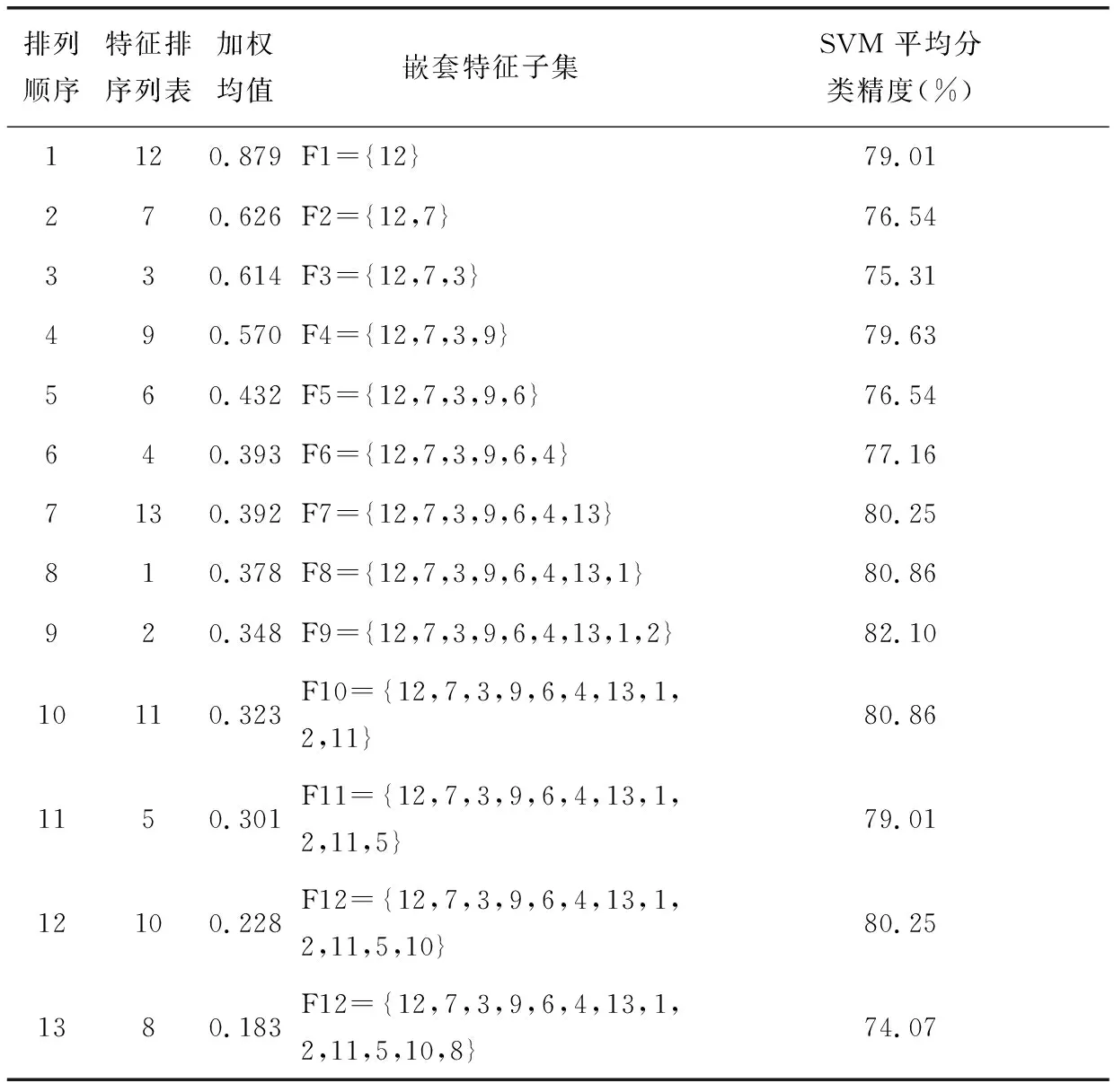
表1 Heart disease 数据的分析结果(分类器个数M3=60个)
将生成的嵌套特征子集在前面随机产生的60个的测试集上计算SVM平均分类精度得到最优特征子集并最终得到最优特征子集{12,7,3,9,6,4,13,1,2}。用包含这些特征子集的数据集对SVM 进行训练得到支持向量,并用生成的支持向量机模型对这些支持向量进行分类预测,去除预测分类结果与样本原有的分类标签两者不一致的支持向量,得到清理后的支持向量。采用3.3节的方法生成5个规则(其中含1个默认规则),我们分别计算每条规则增加前后的AUC的变化,如图2所示。
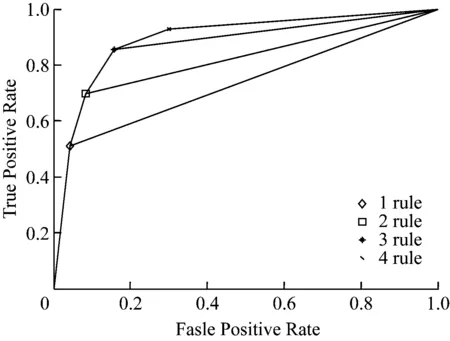
图2 规则集在Heart desease 数据上的ROC图
分别为:0.69,0.78,0.85,0.87。由于第4条规则增加后变化不显著我们将其裁剪,得到规则集如式(5)。
R1:IFX13=7 ANDX3=4 THEN Occur=2
R2:IFX1≥59 ANDX9=1 THEN Occur=2
(5)
R3:IFX12=1 ANDX2=1 THEN Occur=2
Default: Occur=1
为了更好地对本文所提出的算法的性能进行评判,我们选取了两个有代表性的规则提取方法,一个是直接从样本中提取规则的C4.5算法,另一个是基于结构分析的SVM+ prototypes算法与本文提出的基于SVM-FRE特征选择的规则提取方法进行比较。
这三种算法在5个数据集上的结果,如表2所示。
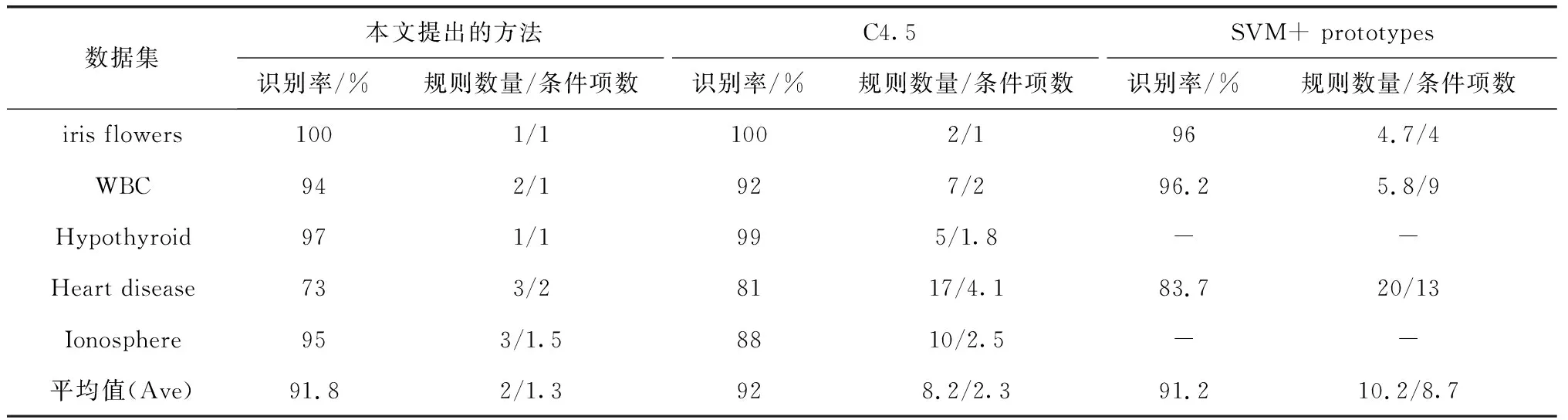
表2 本文提出的方法、C4.5算法和SVM+ prototypes算法的性能比较
从表中我们可以看出本文提出的算法在识别率上基本上和另外两种相差不大,但所产生规则集中规则的数量以及规则前提中的条件明显比另外两种要小,提高了提取规则的可理解性。
4 总结
本文提出了基于SVM-RFE特征选择的规则提取方法,该方法采用优化的SVM-RFE来获取重要属性集,并采用一种变型的顺序覆盖规则算法结合AUC进行规则生成和裁剪。实验表明该方法在保持较高的精确度和忠实率的前提下提高了提取规则的可理解性。
