基于差分拉曼光谱对一次性塑料杯盖的分类研究
2021-09-27吴克难杨金颉
郭 琦,姜 红∗,吴克难,杨金颉,段 斌,刘 峰
(1.中国人民公安大学侦查学院,北京 100038;2.武汉理工大学计算机科学与技术学院,武汉 430070;3.南京简智仪器设备有限公司,南京 210049)
0 前言
根据相关规定,不同构成成分的塑料制品分为7类,并分别用数字1~7加以标示,分别为:1-PET、2-高密度聚乙烯(PE-HD)、3-聚氯乙烯(PVC)、4-低密度聚乙烯(PE-LD)、5-PP和6-PS、7-PC其他类[1]。随着电子商务迅猛发展,以一次性包装、一次性餐具为代表的塑料制品用量快速增加[2]。一次性塑料杯盖类塑料物证在案件现场出现频率明显提升。
塑料生产厂家一般会用内标数字的三角箭头标明塑料产品成分,但市面上存在大量“三无”塑料杯盖产品,案件中也常见杯盖污损、标识模糊等情况。根据用途不同,杯盖分为冷/热饮;根据形状不同,杯盖分为圆弧形、直饮式等,不同生产厂家生产制品的成分与填料含量也不同。一次性杯盖外观形状差异小,对于其种类及品牌的溯源存在困难。
在法庭科学中,红外光谱法、X射线荧光光谱法和拉曼光谱法等都是常见的塑料制品检验方法[3-4],差分拉曼光谱技术运用相关算法分离2个激发激光的差分信号和基线偏差,有效消除了荧光干扰,可以用于更准确的特征谱图[5]。 Knipfer等[6]利用差分拉曼光谱技术采集离体口腔癌样本,有效区分恶性和良性组织的光谱,为非侵入性客观诊断口腔癌提供了新的诊断思路。
支持向量机(SVM)是一种有监督的机器学习方法,即在已知训练数据类别的前提下,建立一个或多个分类超平面,该曲面能够正确分类不同种类样本,且使分类后的样本点距离此决策平面最远,由此将训练数据按照类别识别,并预测未知数据对应类别[7]。李志豪等[8]以两类易制毒化学品和易燃易爆化学品为例,采集拉曼图谱,对比分析公安工作主流机器学习算法的预测准确度均高于70%。王梓笛等[9]利用拉曼光谱技术对乳制品进行采样,将光谱数据数据作为表征数据输入支持向量机模型,实现3种品牌乳制品分类准确度100%。支持向量机模型对于小样本、非线性及高维模式识别时有很大的优势[10]。
本实验首先利用人工分析塑料杯盖官能团对应峰位的区别后,对数据进行K-均值聚类,并引入Calinski-Harabasz(CH)指标优选类别数,最后提取差分拉曼光谱谱图的方向梯度直方图和灰度共生矩阵2个特征向量,建立支持向量机模型,输入图谱即可得到较为准确的分类及预测。
1 实验部分
1.1 主要原料
不同来源、不同种类的一次性塑料杯盖样本48个,涵盖30个市面常见的餐饮业品牌,包括奶茶品牌“一点点”、“coco都可”,快餐品牌“肯德基”等。
1.2 主要设备及仪器
便携式差分拉曼光谱仪,SERDS Portable-standard,南京简智仪器设备有限公司。
1.3 样品制备
将样本分别剪取成1 cm×1 cm的单层矩形,用酒精棉片擦拭,置于通风处晾干,依次放在金属垫台上,使用仪器进行检验。
1.4 性能测试与结构表征
差分拉曼光谱实验条件设置为:激发光源波长分别为785、785.5 nm;激光功率为220 mW;积分时间为20 s;
稳定性性能测试:为了验证仪器的稳定性,以确保实验结果可靠性,随机选取1#“嘻哈有饮”不透明直饮式杯盖样本,在上述实验条件下进行10次测定检验(如图1所示,1~10分别表示第1~第10次测试)。
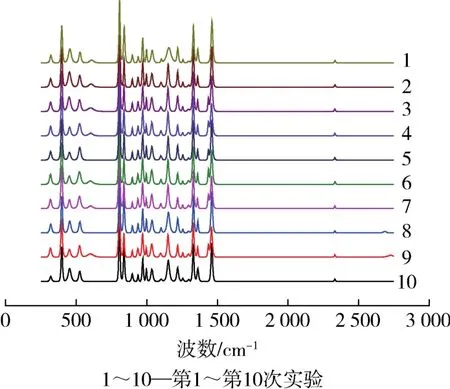
图1 1#样本10次重复检验的差分拉曼光谱图Fig.1 Differential Raman spectrogram of sample 1#with ten repeated tests
2 结果与讨论
2.1 差分拉曼光谱分析
分析48个样本的差分拉曼光谱谱图,根据主要组成成分基团对应的波峰[11-12],可以将样本分成3类,分类结果如表1所示,3类样本的种类分别是PP、PS、PET,表2展示了3类样本相应振动基团的对应峰位。

表1 48个样本的分类结果Tab.1 Classification results of 51 samples
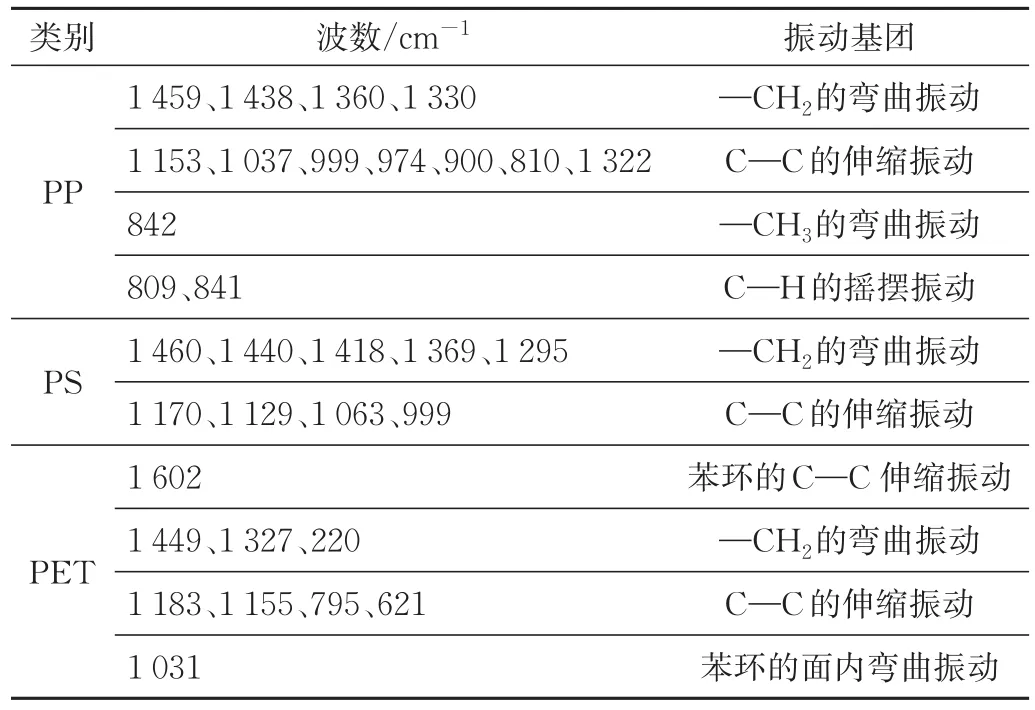
表2 振动基团对应峰位表Tab.2 Table of corresponding peaks of vibrational groups
3类谱图中除了PP、PS、PET的特征峰,还有其他特征峰存在,这是由于在塑料的生产过程中,为了提高性能,降低成本,通常会添加增塑剂、抗氧化剂、阻燃剂等辅助化学试剂[13]。不同厂家添加助剂的种类和多少具有特异性,因此选择特征样本进行区分:
对于同一品牌不同系列,选取5#“便利蜂”热饮杯盖和17#“便利蜂”冷饮杯盖谱图对比,5#样本构成成分为PS,而17#样本构成成分为PET,谱图容易区分。对于同一品牌不同款式,选取20#“肯德基”大杯冷饮杯盖和23#“肯德基”中杯冷饮杯盖谱图对比,2个样本组成成分均为PS,但是同一波长对应峰高不同,可根据相对峰高比进行区分。对于不同品牌同一材质选取24#“四云奶盖贡茶”和25#“斯卡酸奶”样本谱图进行对比如图2所示,2个样本组成成分均为PP,但是可以根据1 127 cm-1处是否有峰,判断是否有硬脂酸钙[14]的添加,从而进行不同品牌的区分。

图2 不同样品的茶粉拉曼观光普谱图对比Fig.2 Comparison of spectra of different samples
2.2 优选K值进行K⁃均值聚类分析
通过分析谱图可以人工将所有样本区分开,但是此方法费时费力,且无法避免偶然误差影响,因此引入多元统计学方法对一次性塑料杯盖样本进行区分[15]。K-均值聚类是一种根据数据变量与聚类中心的相似情况,迭代更新聚类中心位置,降低类簇的误差平方和(SSE),直至SSE停止变化或目标函数收敛时,分类停止的一种无监督性聚类方法[16]。但是该算法受初始K值影响极大,为了优选最佳类别数,本实验使用Calinski-Harabasz(CH)评价指标[17]以确定最优类别数,该指标是一种基于样本的簇内距离和簇间离差矩阵的测度[18],其判断函数如式(1)所示:
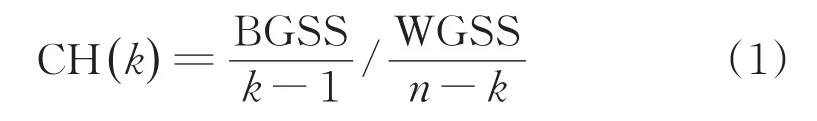
式中n——数据样本数目
k——类别数
簇内平方误差和(WGSS)用来度量簇内的紧密度,如式(2)所示:
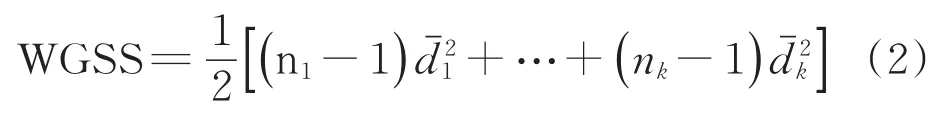
nk——第k簇的样本数量
簇间平方误差和(BGSS)用来度量簇间的分离度如式(3)所示:

ni——第i簇的样本数量
簇内距离越小,簇间离差距离越大,则CH指标越大,聚类效果越好,即可优选最合适的类别数,图3为CH指标随类别数变化的曲线。由图3可知,CH指标先上升,在类别数为5时达到最高点后快速下降,当类别数大于8时,K值逐渐增加,但是仍然小于最高值,因此,当K值为5时,分类效果最佳,以此进行K-means聚类,优化质心初始化后,设置每次迭代的最大次数为300,用不同的质心初始值运行算法的次数为10次,得到样品聚类结果见表3。
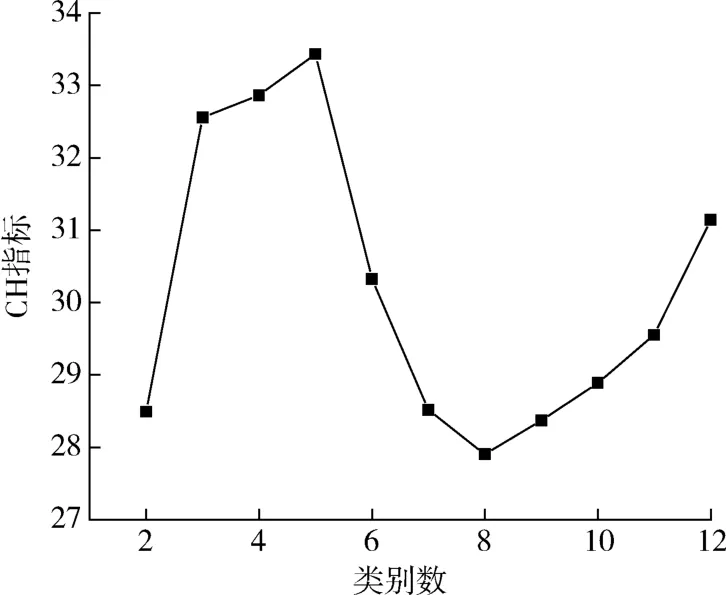
图3 CH指标可视化曲线Fig.3 Visualization curve of CH index

表3 K⁃means聚类结果Tab.3 K-means clustering results
可以看出,PP类样本被细化分为第Ⅰ类和第Ⅲ类,PET类样本被细化分为第Ⅱ类和第Ⅳ类,可能由于PS类型样本的官能团与其他类样本差异明显,所有PS类样本被分至第Ⅴ类。此分类结果并未出现受初始质心随机选取容易陷入局部最优解的显著错误,从而反证优选K值为5是合理的。
2.3 支持向量机算法数据分类
图4介绍了支持向量机模式分类识别算法的具体实施步骤,为了确保测试集数据涵盖性广,使用randperm函数实现在每一类样本中随机抽选样本数,总和达到总样本数的83%(40个)构建数据训练集,以剩下的17%(8个)样本数据作为测试集搭建支持向量机模型。

图4 支持向量机分类识别步骤Fig.4 Classification and recognition steps of support vector machine
本实验提取谱图的方向梯度直方图和灰度共生矩阵2个特征。方向梯度直方图计算并统计局部区域特征,灰度共生矩阵提取整体纹理特征,合并特征向量后训练构建支持向量机模型。选择可以将样本特征从低维输入空间映射到高维特征空间的径向基核函数,用于解决非线性关系[19]。
使用软件自带的训练svm函数中的fitcecoc函数建立多分类支持向量机,可以用predict函数进行预测分类,然后通过图像窗口直观看到输入数据的分类结果。多次训练得到支持向量机模型后,将随机选取的测试集样本提取特征向量输入支持向量机模型,得到结果如图5所示,分类结果可直接显示在图下。

图5 测试集样本识别结果示例——分类结果:1Fig.5 Sample recognition results of test set——classification results:1
混淆矩阵是一种用于评价分类结果的方法。混淆矩阵中的行对应变量的真实类别,列对应支持向量机的识别类别。对角线上的元素表示分类器正确识别的数量,若非对角线元素不为0则表示存在错误分类,可以通过计算混淆矩阵对角线上的值占每行总数的比值来评价结果[20]。由表4可得,测试集样本的识别准确率为100%。这一结果与K-均值聚类结果相互印证,同时,经过大量数据训练出的支持向量机模型,能够实现对未知样品的分类。

表4 混淆矩阵及准确率Tab.4 Confusion matrix and accuracy
3 结论
(1)实验采用位移差分拉曼光谱技术对一次性塑料杯盖做无损性检测,根据PE、PET、PP 3类塑料官能团对应峰位不同对其人工分类,并探讨了同一或不同类别的不同样本的谱图差异;
(2)对数据进行系统聚类后为优选最佳类别数,实验引入CH指标为评估方法,作出CH指标随类别变化的折线图后得到,当类别为5时,CH指标数值最大,因此可以将K值定为5,K-means聚类结果是PP、PET等粗分类的细化,进一步证明K值较优;
(3)随机抽取样本数据集83%作为训练集建立支持向量机模型,随剩余17%作为测试集的数据做混淆矩阵判断其准确率,结果显示,该方法有效支持向量机运行时间长的缺点,并实现了测试集准确率100%的成果。
