一种基于Python的商品信息采集方法
2021-09-26骆魁永
骆魁永
摘 要:随着电子商务的飞速发展,选择电商平台的商品数据作为实验数据集的科研人员越来越多,为了解决科研人员获取商品数据困难的问题,文章以“淘宝网”作为目标网站,提出了一种基于Python的商品信息采集方法。首先对商品信息接口所需参数进行分析,优化访问链接,然后使用Python提供的第三方Requests和BeautifulSoup库,对商品信息进行下载和清洗,最后将清洗后的数据存储到MongoDB数据库中。
关键词:电商平台;Python;数据采集
0 引言
随着我国互联网的飞速发展,网上购物越来越受到人们的青睐,现在已经成为一种重要的购物方式。淘宝、京东等大规模电商平台每天都会生产海量的商品交易数据,针对这些数据进行分析与挖掘,对于改善消费者购物体验、提高商品销量等具有非常重要的研究价值,因此吸引了一大批科研人员对电商数据进行研究[1]。但网站出于安全和性能的考虑对其中的数据都制定了很严格的保护措施,想要获取平台中商品数据并不容易,为了解决科研人员获取商品数据困难的问题,设计并实现一种商品信息采集方法显得尤为重要。
1 爬虫设计与实现
1.1 接口参数分析
电商平台商品种类繁多,商品数量更是数以万计,为了便于消费者快速定位自己感兴趣的商品,平台通常都会提供“商品搜索”功能,例如淘宝、京东、拼多多。以在淘宝网的商品检索框中搜索“笔记本电脑”为例,通过对搜索返回的前三页结果页面对应的链接分析,发现q后面的值是搜索的关键字,“ie”的值为网页编码格式,“s”的取值与搜索结果的页码相关,并发现s=(页码-1)*44。最后,对搜索结果页面对应的链接优化得到访问搜索结果页面的第n页的URL用Python语言表示为:“https://s.taobao.com/search?q={keyword}&s={page}”.format(keyword=keyword,page=(n-1)*44)。
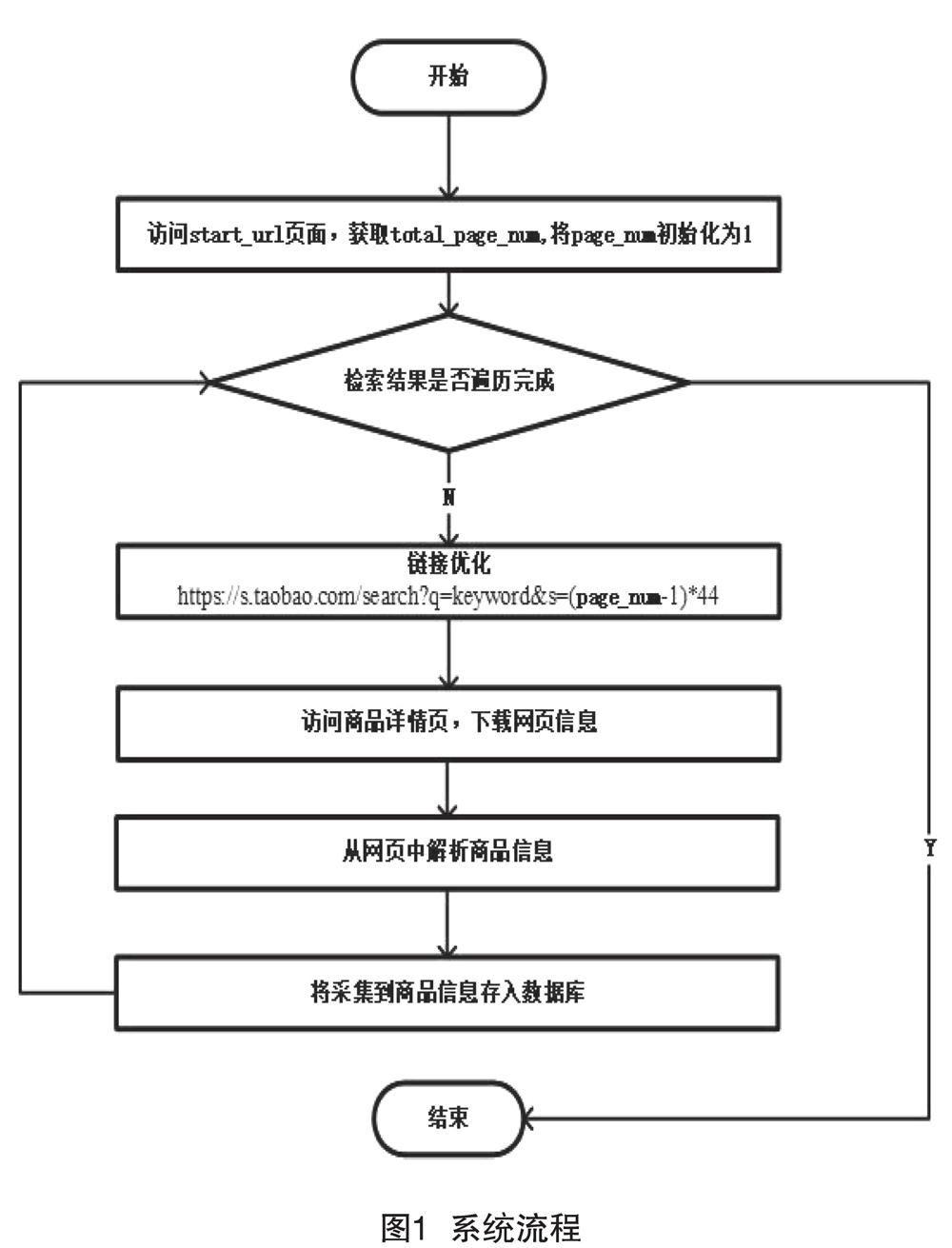
1.2 爬虫算法设计
爬虫程序的流程如图1所示,具体步骤如下:(1)访问start_url页面(我们将点击搜索按钮后返回搜索结果的第一个页面称之为start_url页面),获取返回搜索结果的总页面数total_page_num。(2)判断检索结果页面是否遍历完成,如果完成转到8,否则继续执行3。(3)对待访问的page_num页面的链接进行优化。(4)将检索结果中的第page_num页内容下载至本地。(5)从下载的网页中解析商品详情页包含的商品信息。(6)将采集到的商品信息存入MongoDB数据库。(7)page_num+=1,重复步骤2—7,抓取剩余检索页面中的商品信息。(8)程序运行结束。
1.3 商品信息下载
对于商品信息的下载,主要使用Python提供的第三方库Requests[2],它是基于Python开发的HTTP库,不仅可以重复读取HTTP请求返回的数据,还可以自动识别网页编码,可以轻松模拟浏览器的工作完成网页下载任务。具体实现代码如下所示:
head={‘User-Agent:Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36,Connection: ‘keep-alive}
def get_index(url):
data=requests.get(url,headers=head,timeout=2)
return data
1.4 商品信息清洗
通过对下载的网页源码分析发现,在一个script的标签中可以找到关于商品的所有主要信息,如商品的名称、价格、邮费、付款人数、图片地址、店铺名等,这些数据以json格式被存储。对于商品信息清洗,主要通过BeautifulSoup[3,4]和正则表达式来完成,具体实现代码如下:
soup=BeautifulSoup(response.content,lxml)
goods_list=soup.find(‘script,text=re.compile(‘g_page_config)).string.strip()
pageConfig=re.search(‘g_page_config = (.*?);\n,goods_list,re.S)
pageConfig_dict=json.loads(pageConfig.group(1))
pageGoods=pageConfig_dict[‘mods][‘itemlist][‘data][‘auctions]
1.5 商品信息存儲
由于爬虫采集到的数据具有复杂结构,这里使用MongoDB进行数据存储。在Python中通过开源模块pymongo可以很方便的实现与MongoDB数据库的交互,具体代码实现如下:
client=pymongo.MongoClient(‘localhost,27017)
taobao=client[‘taobao]
goods=taobao[‘product]
def save_to_DB(result):
try:
if goods.insert_one(result):
print(‘存储到数据库成功,result)
except Exception:
print(‘存儲到数据库失败,result)
2 关键问题及解决方法
2.1 Robots协议
对“淘宝网”的Robots文件分析可知,它对爬虫的拒绝机制主要在于User-agent的识别,使用真实的浏览器可以正常访问站点,而使用爬虫程序将会遭到拦截。本爬虫的解决方法是通过为请求添加头部信息,将爬虫伪装成浏览器[5],使其能够正常访问站点。
2.2 IP限制
短时间内使用同一IP账号对“淘宝网”进行高频次的访问,会导致IP账号被拉黑。本文解决方法是设置IP代理池,每一时间间隔都会从代理池中重新获取新的IP账号,从而避免同一IP在短时间内大量访问的情况。
2.3 多进程并发采集
多进程是相对单进程来讲的,单进程即同一时间段内处理器只处理一个问题,只有处理完这个问题后,才开始解决下一问题。为了提高商品信息的采集效率,充分利用多核CPU资源,爬虫程序使用Python提供的多进程包multiprocessing,对商品信息进行并发采集。
3 结语
本文基于Python的第三方库:Requests和BeautifulSoup,实现了一个易定制易拓展的主题爬虫,并以“淘宝网”为例进行商品信息的定向抓取。通过实验证明,该方法能有效降低数据采集的难度,可以帮助科研人员获取商品数据,具有一定的现实意义。但是,该方法距离成熟的爬虫还有一定的差距,在今后的工作中,考虑引入Scrapy框架[6],提高爬虫效率及其鲁棒性。
[参考文献]
[1]丁晟春,侯琳琳,王颖.基于电商数据的产品知识图谱构建研究[J].现代图书情报技术,2019(3):45-56.
[2]常逢佳,李宗花,文静,等.基于Python的招聘数据爬虫设计与实现[J].软件导刊,2019(12):130-133.
[3]温娅娜,袁梓梁.基于Python爬虫技术的网页解析与数据获取研究[J].现代信息科技,2020(1):12-13.
[4]房瑾堂.基于网络爬虫的在线教育平台的设计与实现[D].北京:北京交通大学,2016.
[5]余本国.基于python网络爬虫的浏览器伪装技术探讨[J].太原学院学报:自然科学版,2020(1):47-50.
[6]杜鹏辉,仇继扬,彭书涛,等.基于Scrapy的网络爬虫的设计与实现[J].电子设计工程,2019(22):120-123.
(编辑 何 琳)
Method of collecting product information based on Python
Luo Kuiyong
(College of Information Engineering, Xinyang Agriculture and Forestry University, Xinyang 464000, China)
Abstract:With the rapid development of e-commerce, more and more researchers are choosing data of product from e-commerce platforms as experimental data sets. In order to solve the problem of scientific researchers difficulty in obtaining commodity data, this article takes “Taobao” as the target website and proposes a Python-based method for collecting commodity information. First, analyze the required parameters of the product information interface and optimize the access link, and then use the third-party Requests and Beautiful Soup libraries provided by Python to download and clean the product information, and finally store the cleaned data in the Mongo DB database.
Key words:e-commerce platform; Python; data collection
