基于混频模型的中部某省卷烟销量趋势预测
2021-09-26石涛李根栓李鹏飞郑飘
石涛,李根栓,李鹏飞,郑飘*
1 河南中烟工业有限责任公司,河南省郑州市榆林南路16号 450016;
2 河南省社会科学院,河南省郑州市丰产路21号 450002
近年来,随着烟草行业供给侧结构性改革和市场化取向改革的深入推进,卷烟销售业务流程逐步由“工-商-零-消”向“消-零-商-工”转变,消费者具有更大选择权和主动权,卷烟市场需求导向性日益凸显。尤其是卷烟消费不断向个性化、多元化升级,卷烟需求的不确定性明显增加,给卷烟营销工作带来新的挑战,对卷烟消费需求预测的科学性和准确性提出了更高要求。从宏观角度,需要通过精准科学需求预测,准确把握市场真实需求,敏锐感知消费需求变化趋势。从微观角度,需要通过精准科学的卷烟需求预测,切实加强工商协同和货源衔接,提高货源供给与市场需求吻合度,保证卷烟市场供给总量和结构与需求变化相适应;畅通卷烟产业链,提升工商企业各环节的高效协同,提高工商企业运行效率和经营效益,提高响应市场的速度,精准满足市场需求。因此,精准科学预测卷烟销量对进一步提高响应市场的速度、适应市场的能力和服务市场的水平,进一步提高卷烟营销水平具有十分重要的意义。
1 研究进展
近年来,国内学者围绕我国卷烟销量预测问题进行了诸多研究,邹亮[1]、程幸福[2]分别构建季节趋势分解模型、ARIMA模型等时间序列模型预测月度、季度卷烟销量;蒋兴恒[3]采用BP神经网络对卷烟月度销量进行预测;吴明山[4]等多位学者构建组合预测模型对卷烟季度、月度销量进行预测,以克服单一模型预测精度不高的缺陷,提高预测的精准性。上述学者构建的预测模型均是基于卷烟销量自身的时序数据进行预测,虽然取得了较好的预测效果,但忽略了某些影响卷烟消费的因素,例如国内生产总值(GDP)、全社会消费品零售总额等宏观经济指标和消费者特征。王运鸿[5]、汪世贵[6]、席昊[7]分别构建回归预测模型研究宏观经济指标与卷烟销量之间的关系,并基于宏观经济数据对卷烟销量进行预测。上述研究以年度数据和全国整体数据为主,数据的时间和空间粒度较粗,不能有效满足季度和月度卷烟消费需求预测的需要;且研究以同频数据的自回归模型为主,不能有效捕捉宏观经济环境等外部因素对卷烟销量的影响。
国际学者的研究方法对克服上述问题具有一定启发。Ghysels等[8]首先提出混频数据抽样(MIDAS)模型,提取不同频率数据信息来进行分析预测。该模型的提出最初是为了运用混频数据对股票市场的波动进行分析预测。由于 MIDAS 模型在预测方面具有较高的准确性,因此国内外学者将该模型拓展应用到宏观经济、旅游、能源、环境等各个领域进行预测研究。Bai等[9]通过MIDAS模型与状态空间模型对美国GDP预测精准度的对比,证明MIDAS模型预测效果更好。唐成千和莫旋[10]运用“三驾马车”对中国宏观经济进行分析和短期预测,指出投资增速的放缓和出口增速的下滑是引起当前中国宏观经济下行的重要原因,证明MIDAS 模型在对中国宏观经济的短期预测精确性方面具有一定的优势。刘汉和王永莲[11]以美国来华游客人次为研究对象,开展入境旅游需求的混频预测研究,并与传统同低频预测模型进行比较分析,结果表明,基于网络搜索数据的混频预测模型的预测精度相比传统同低频数据模型有近50%的提升,预测精度和方向上均有显著提高。秦梦等[12]根据MIDAS 模型的建模理论,构建基于季度GDP增长率数据和年度能源消费总量增长率数据的混频模型,证明了混频模型在预测能源消费总量方面的准确性与时效。秦华英和韩梦[13]将MIDAS模型用于碳排放量预测研究,分析高频季度GDP滞后阶数变化效应及其对低频二氧化碳排放量的影响效应,结果表明,MIDAS模型对二氧化碳排放量的预测合理,且在中国二氧化碳排放量的短期预测方面具有较高的预测精度,在实时预报方面具有显著的可行性和时效性。
从上述学者的研究成果来看,目前国内学者对卷烟销量预测在数据上以低频的同频数据为主,预测模型以自回归模型为主,鲜有学者基于高频数据,运用混频模型来分析宏观经济要素对卷烟销量预测的适用性,这为本文的研究提供了一定的空间。为此,本文将基于2008—2019年的月度宏观经济数据和季度卷烟销量数据,运用混频MIDAS 模型分析饮料烟酒类商品零售价格指数、工业增加值增长率以及全社会消费品零售总额等宏观经济要素作为先行指标来预测卷烟销量,并运用样本内和样本外数据进一步校验模型的精度,验证混频模型的合理性和可行性。
2 模型设定与变量选择
2.1 模型设定
正如上文指出,现有学者对卷烟销量的预测研究主要是基于时间序列数据,多为低频或者观测长度较短的同频数据,难以有效分析被观测对象的周期性,尤其是可能存在信息遗漏问题。同时,对卷烟销量等趋势性数据的预测需要构建一个宏观先行指数来预测其走向,即以高频先行指数来预测低频卷烟销量数据,而这是混频数据模型相对其他方法的优势(Foroni C,Pierre G和Marcellino M,2015)[14]。类似于卷烟销量等时间序列数据,往往会存在自相关关系,需要分析变量自身存在的自相关关系。而传统MIDAS模型的好处在于能够运用月度高频数据来估计低频的季度数据,但是并不能显示宏观经济变量可能存在的自相关关系,而向前h步预测的MIDAS(m,k,h)-AR(p)模型具有对预测对象实时预报和修正的特点,设定如下:
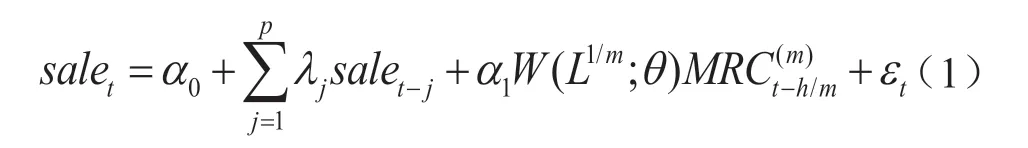
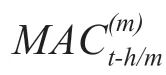
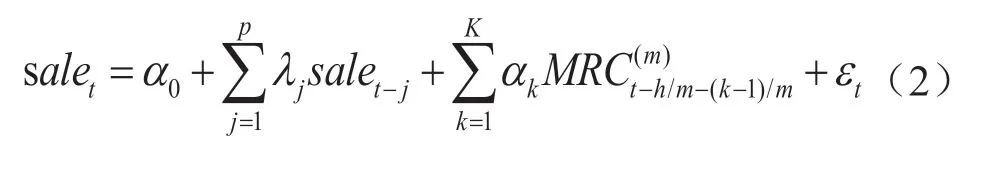
一般而言,当高频数据与低频数据之间的倍差较小时,无约束的MIDAS模型估计效果较好。
2.2 变量选取及数据来源
2.2.1 变量选取
为相对完整地捕捉高频宏观经济因素对卷烟销量的影响,参考现有学者的研究成果[16-17],结合月度数据可得性,变量选取主要围绕宏观经济环境、消费者特征及价格水平等三个维度,其中宏观经济环境由工业增加值增长率来表示,消费者特征由全社会消费品零售总额来表示,价格水平由饮料烟酒类商品零售价格指数来表示,具体详见表1所示。

表1 变量选取及数据描述统计Tab. 1 Variable selection and data description statistics
2.2.2 数据来源
本文所用数据为中部某省宏观经济月度数据和季度卷烟销量的时间序列数据,考虑数据可得性,时间范围为2008—2019年。以上数据未经特殊说明,宏观经济指标数据来源于该省统计局以及国家统计局网站,卷烟销量数据来源于烟草统计年鉴及统计报表,对于部分缺失数据采用移动自回归平滑处理。为了更好地反映模型估计的有效性,参考机器学习的思路,将样本数据划分为两个时间段:一是样本内训练样本,时间为2008.1—2018.12,用以学习训练估计参数;二是样本外预测样本,时间为2019.1—2019.12,用以验证估计参数的有效性。
3 实证结果及分析
3.1 MIDAS模型选择
由于卷烟销量与饮料烟酒类商品零售价格指数、工业增加值增长率以及全社会消费品零售总额等高频数据不同频率,样本滞后期较多,形成多种混频数据抽样估计模型,因而主要以均方根误差(RMSE)最小为主,AIC最小及拟合优度为辅进行最佳模型选择(丁黎黎等,2018)[18]。本文采用Matlab软件的MIDAS2.3模块进行相应模型估计,分别以饮料烟酒类商品零售价格指数、工业增加值增长率以及全社会消费品零售总额变量作为自变量,相应选择U-AR(4)-MIDAS(3,6)模型、Almon-AR(4)-MIDAS(3,6)模型及U-AR(4)-MIDAS(3,9)模型为各自预测卷烟销量的最佳混频估计模型,模型均方根RMSE参数估计结果如表2~4所示。同时,U-AR(4)-MIDAS(3,6)模 型、Almon-AR(4)-MIDAS(3,6)模 型及U-AR(4)-MIDAS(3,9)模型的多项式权重分别在(-15,10)、(-1.5,1)及(-0.6,1)范围内波动,且不同时期内的权重值均不相同,表明估计模型权重变动具有合理性,饮料烟酒类商品零售价格指数、工业增加值增长率及全社会消费品零售总额均对卷烟销量具有持续12个月的正负效应。同时,两个模型的拟合值分别为0.914、0.9075、0.9181,表明U-AR(4)-MIDAS(3,6)模型、Almon-AR(4)-MIDAS(3,6)模型及U-AR(4)-MIDAS(3,9)模型在模拟宏观经济变量与卷烟销量之间关系时合理性强。
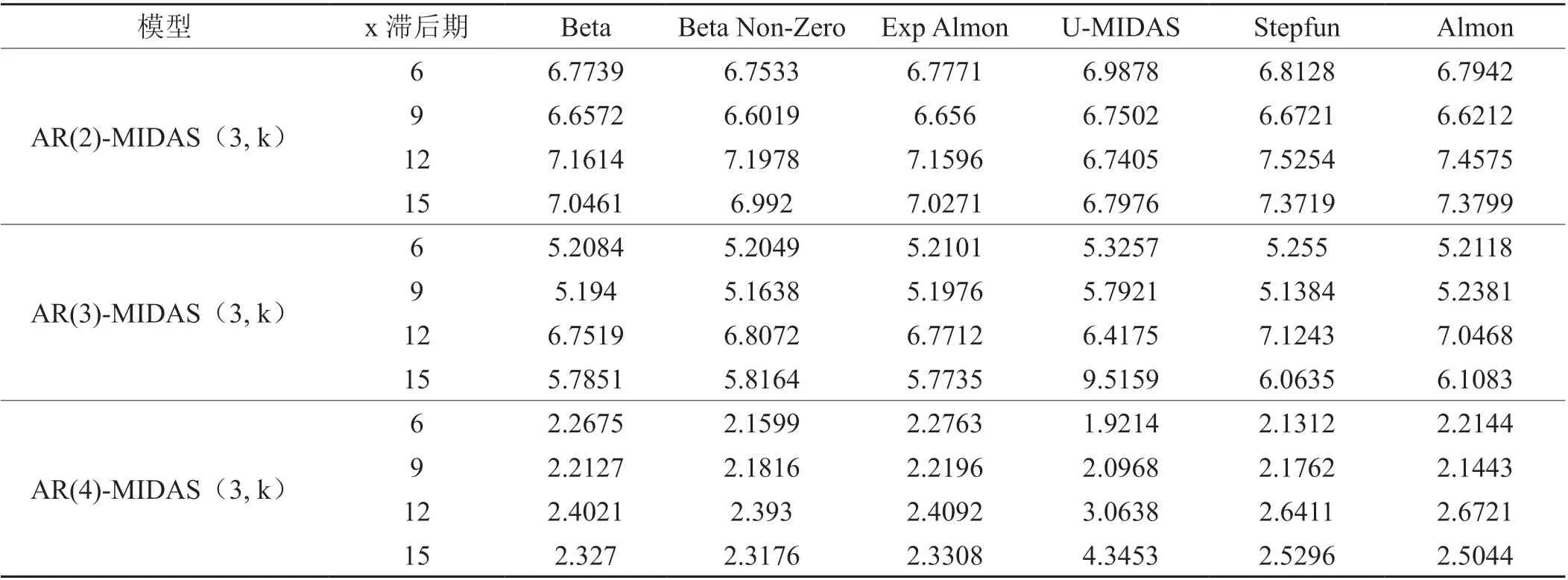
表2 不同混频样本内的RMSE估计结果-基于饮料烟酒类商品零售价格指数Tab. 2 Estimation results of RMSE in different mixing samples - Based on retail price indices of beverage, tobacco and alcohol products
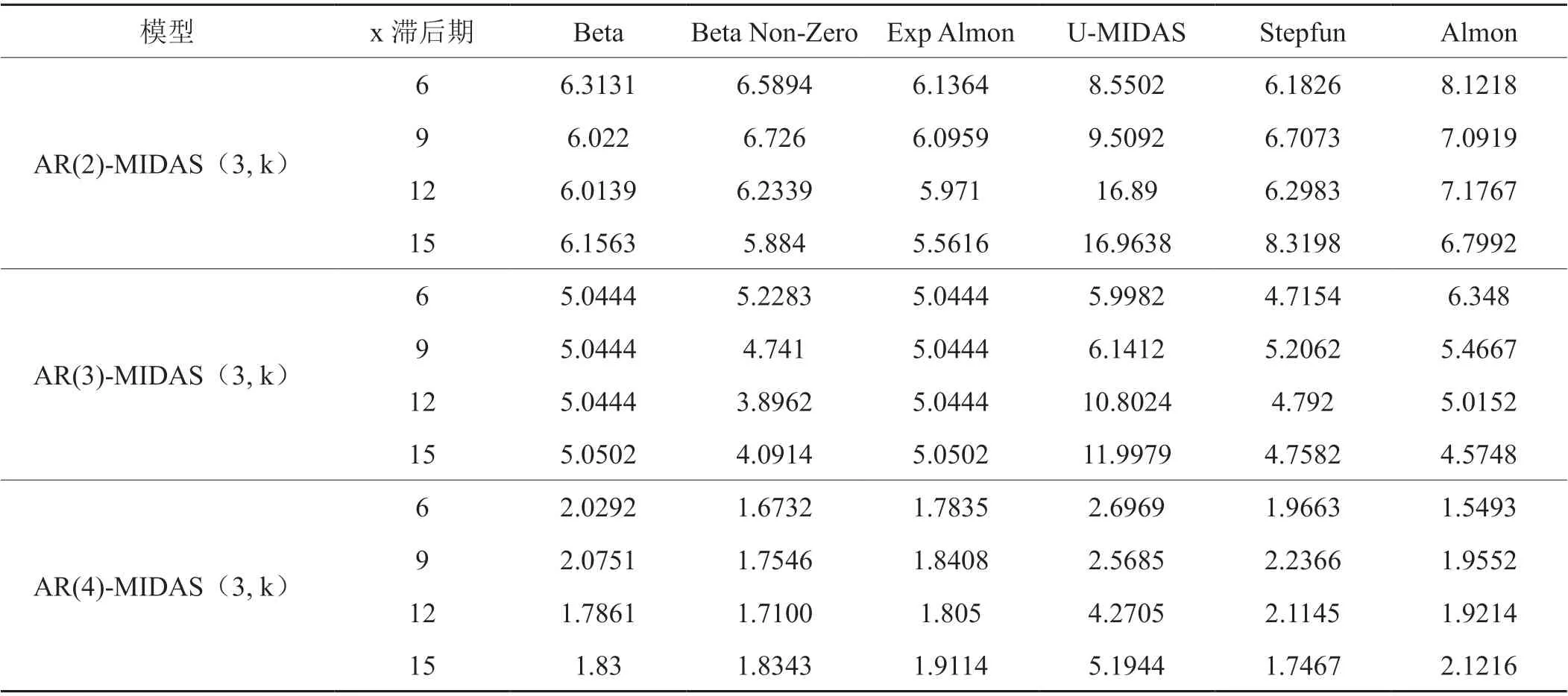
表3 不同混频样本内的RMSE估计结果-基于工业增加值增长率Tab. 3 Estimation results of RMSE in different mixing samples- Based on growth rate of industrial added value
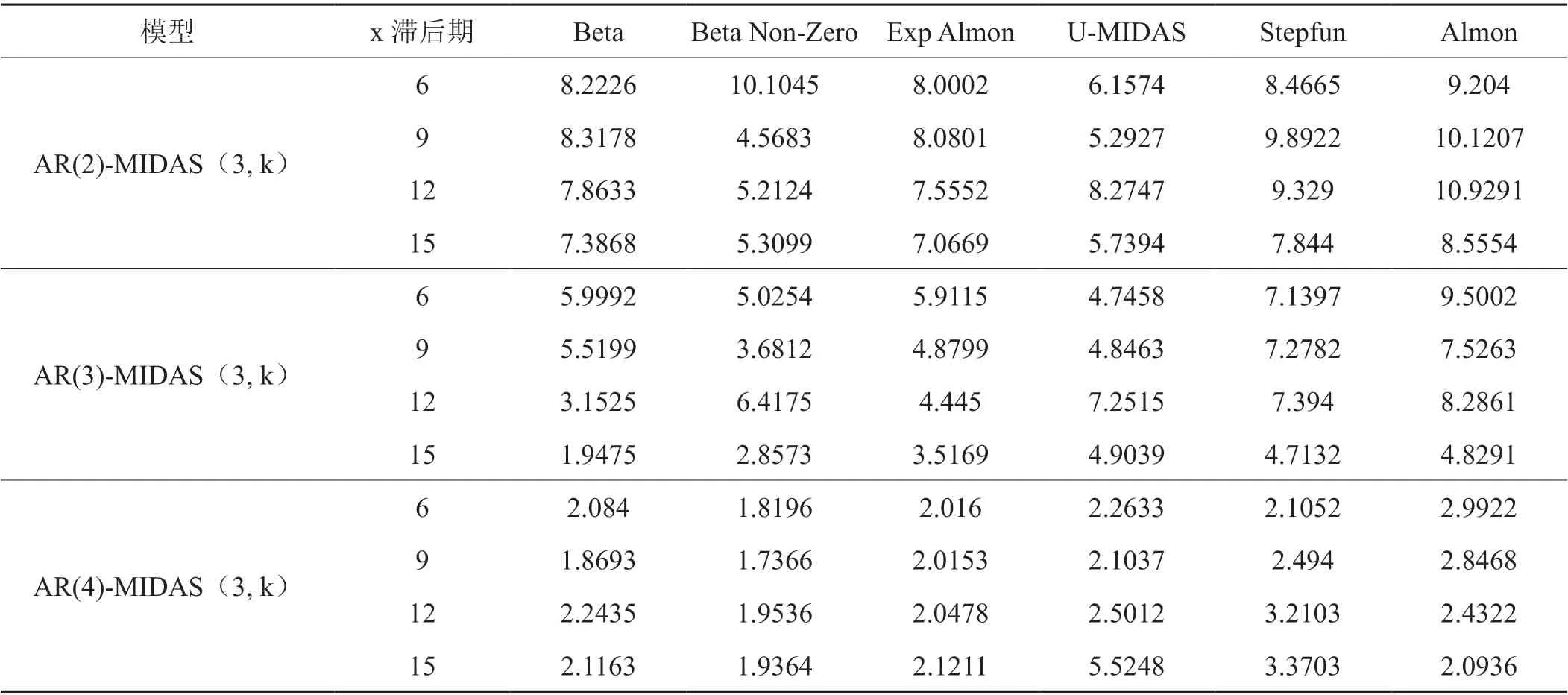
表4 不同混频样本内的RMSE估计结果-基于全社会消费品零售总额Tab. 4 Estimation results of RMSE in different mixing samples - Based on total retail sales of consumer goods
3.2 估计结果分析
表5显示了U-AR(4)-MIDAS(3,6)模型、Almon-AR(4)-MIDAS(3,6)模型及U-AR(4)-MIDAS(3,6)模型的估计参数,三种模型估计结果具有符号一致性。其中,饮料烟酒类商品零售价格指数系数与其他变量系数相反,与传统经济学中价格与销量之间呈现负相关关系一致。以U-AR(4)-MIDAS(3,9)模型估计参数为例,该省卷烟销量受到自身4个季度变化的影响,影响系数分别为-0.2172、-0.0311、-0.1619、0.5651,表明随着向前1季、2季度、3季度卷烟销量增长率的放缓,当季卷烟销量也会相应增加;向前4季度卷烟销量的增加,当季卷烟销量也会增加,即向前4季度卷烟销量绝对值的增加,会导致当季卷烟销量绝对值的增加。
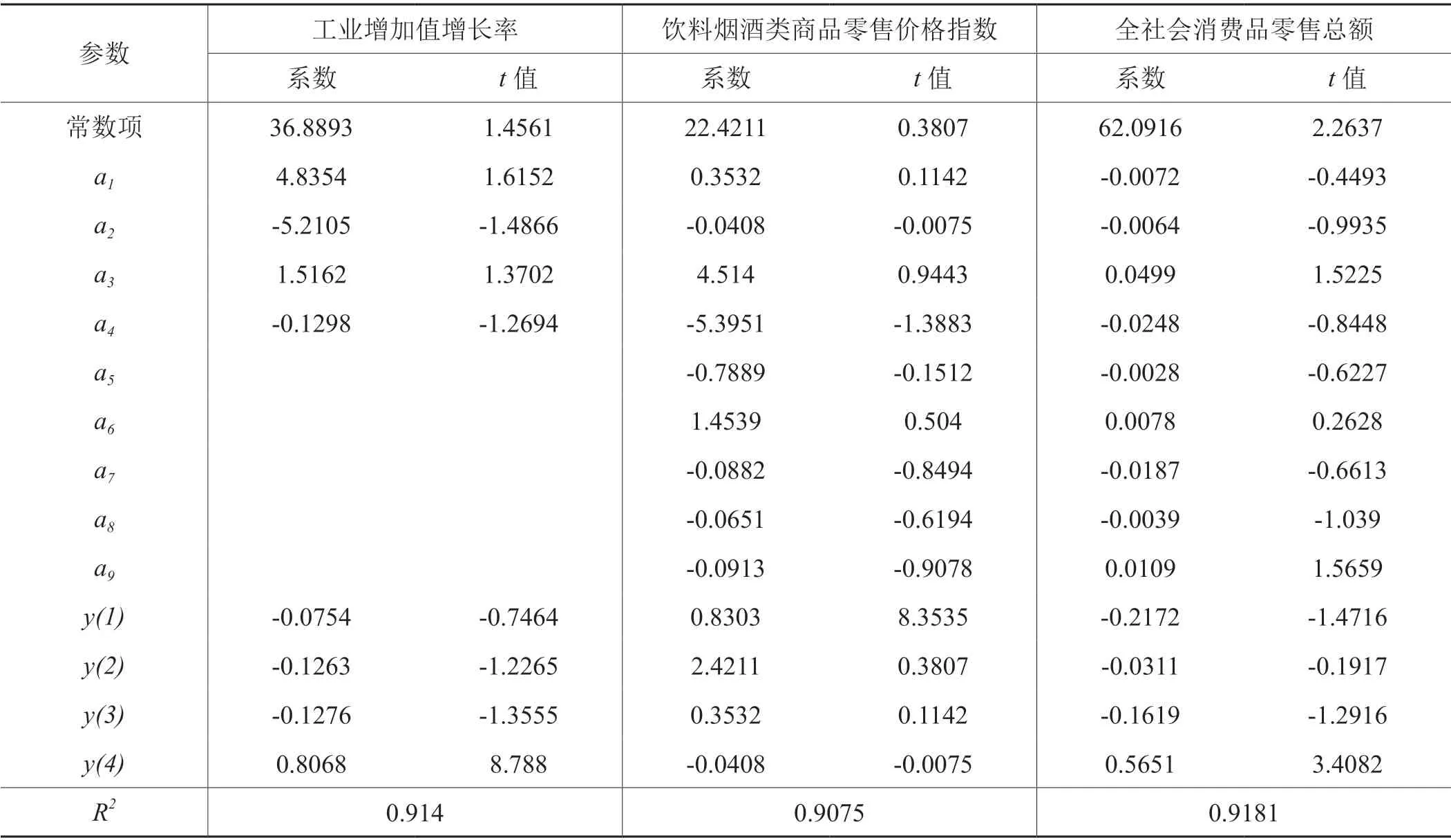
表5 基于不同变量的混频模型的参数估计结果Tab. 5 Parameter estimation results by mixing models based on different variables
3.3 基于混频模型对中部某省卷烟销量的预测对比分析
3.3.1 样本内预测值对比
图1至图3显示了基于混频模型的样本内预测值对比趋势。从该图中,我们可以看出:基于混频模型,饮料烟酒类商品零售价格指数、工业增加值增长率及全社会消费品零售总额三个自变量的预测估计值方向均具有一致性。具体来看,饮料烟酒类商品零售价格指数、工业增加值增长率及全社会消费品零售总额的统计误差率分别为2.4180%、2.4843%、2.2085%,总体控制在2.5%以内,且预测值整体较为平稳,尤其是1季度的数据预测未出现过于偏离该季度实际值的奇异点,表明样本内预测值相对较为精准。
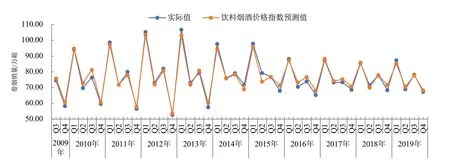
图1 基于饮料烟酒类商品零售价格指数的季度样本内卷烟销量预测值Fig.1 Predicted value of quarterly in-sample cigarette sales based on retail price indices of beverage, tobacco and alcohol products
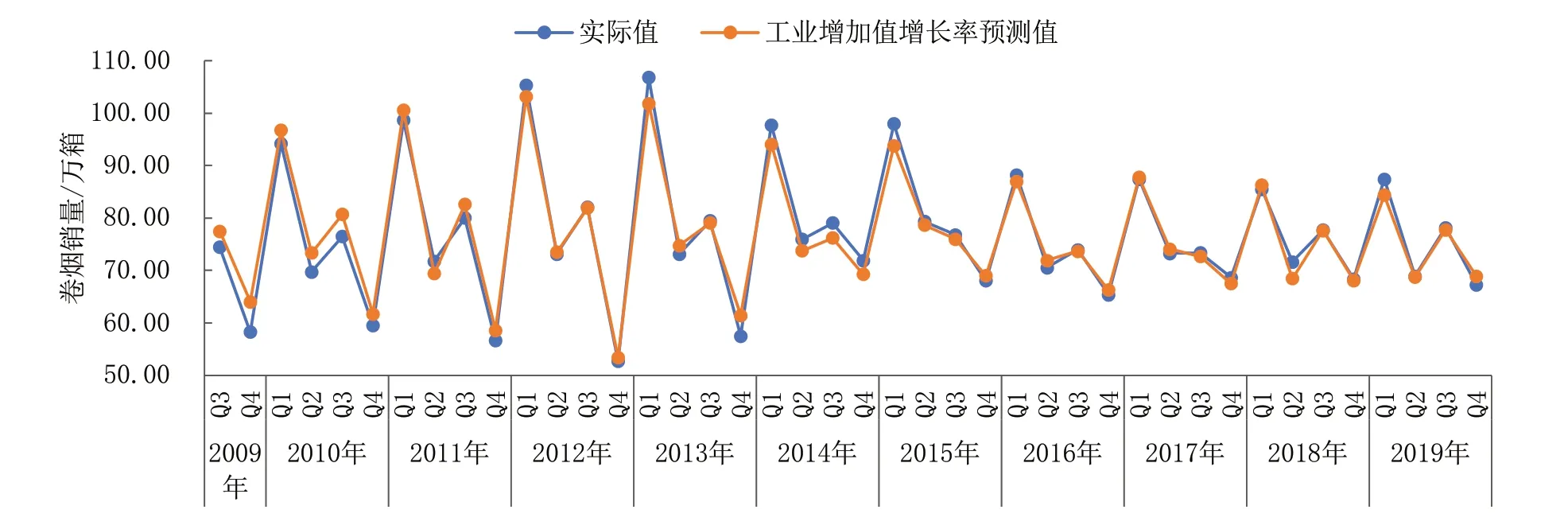
图2 基于工业增加值增长率的季度样本内卷烟销量预测值Fig.2 Predicted value of quarterly in-sample cigarette sales based on growth rate of industrial added value
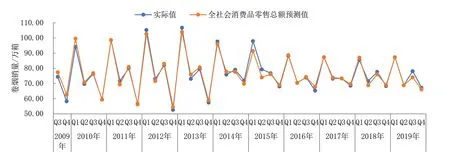
图3 基于全社会消费品零售总额的季度样本内卷烟销量预测值Fig.3 Forecasted value of quarterly in-sample cigarette sales based on total retail sales of consumer goods
3.3.2 样本外预测值
进一步地,利用混频模型进行样本外预测,预测结果如表6所示。该表中,饮料烟酒类商品零售价格指数、工业增加值增长率及全社会消费品零售总额三个自变量的样本外预测值误差率分别为2.2492%、1.4109%、1.7820%,略小于样本内预测值误差率,均在2.25%左右。而当前卷烟销量组合预测模型(ARIMA模型和回归模型)、Levenberg-Marquardt算法改进BP神经网络模型、非线性组合预测模型(ARIMA模型、基于梯度下降算法的BP神经网络模型和基于LM算法的BP神经网络模型)等模型预测值的误差率分别在3%、5%、6%左右,高于MIDAS模型样本外预测值的误差率。由此可见,混频MIDAS模型在预测精度上略好于现有预测模型,对该省卷烟销量预测值的估计效果较好。
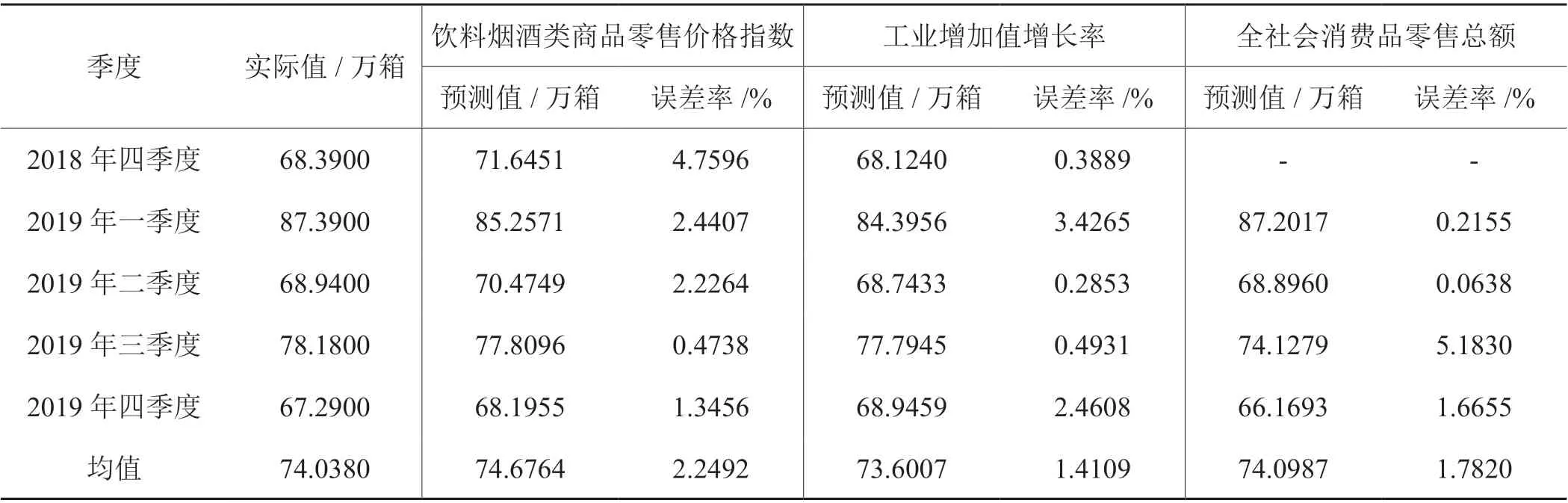
表6 2018—2019年样本内卷烟销量预测值Tab. 6 Predicted value of in-sample cigarette sales in 2018~2019
4 研究结论
基于中部某省2008—2019年宏观经济先行月度数据和季度卷烟销量数据,本文利用混频MIDAS模型对该省卷烟销量进行预测。研究发现:一是饮料烟酒类商品零售价格指数、工业增加值增长率及全社会消费品零售总额等三个月度宏观经济变量对季度卷烟销量都具有较好的预测性,可以作为判断卷烟销量的先行指数参考。二是U-AR(4)-MIDAS(3,6)模 型、Almon-AR(4)-MIDAS(3,6)模 型 及U-AR(4)-MIDAS(3,6)等三个模型在预测精度上相对较高,其中三个模型样本内预测值误差率均值在2.5%以内,预测精度较高。三是基于混频模型,对该省2019年四个季度的卷烟销量进行样本外预测,误差率均值在2.25%以内,进一步说明混频模型的预测值相对较为精准。
与传统的ARIMA等自相关模型不同,本文的创新点在于:更多地考虑外部冲击对卷烟销量的影响,尤其是通过高频数据来对卷烟销量进行适时播报和混频预测,且实证结果表明预测精度相对较高,为行业构建卷烟销量预测先行指数,以及探索大数据预测工具、制定月度季度商业销售政策提供了有益参考和实证依据。
