基于关联规则的数据挖掘技术在高职院校招生中的应用
2021-09-26梁健
梁 健
(锦州师范高等专科学校 成人教育部,辽宁 锦州 121000)
0 引言
近年来,我国职业教育迅猛发展,各院校之间竞争日趋激烈,越来越多的院校意识到拥有更多优质生源在竞争中的重要性[1].如何从招生的海量数据中获取有价值信息呢? 数据挖掘技术的产生解决了这一问题.数据挖掘技术就是从大量的实际数据中,提取隐含在其中的有用信息和知识的过程.关联规则则是数据挖掘技术中最为简单、有效的挖掘方法之一.利用数据挖掘技术对数据进行全面分析,提取出隐藏在海量的招生数据中深层次的、潜在的、有价值的信息,为决策者提供决策支持是十分必要的[2].
1 基于关联规则的数据挖掘
关联规则在数据挖掘技术中应用范围广泛,是实际应用当中比较容易理解而且实用性强的规则,它所采用的是描述型模型,体现出数据的特征.应用关联规则进行数据挖掘最为经典的应用是美国沃尔玛超市的“购物篮”问题,它可以寻找出不同商品之间所隐藏的联系,让经营者明确消费者的购物习惯和喜好,从而更好地提供决策帮助.
数据挖掘过程整体上比较复杂,我们可以简单地把数据挖掘分为三个步骤:第一,从特定的数据源当中搜寻一些用户相对感兴趣的数据,同时将这些数据组织成为更适合数据系统挖掘的组织形式;第二,借助于相应的算法来完成知识积累的过程;第三,对生成的知识模式进行评估和评价[3].
2 招生数据分析及预处理
本文进行挖掘的数据来自某高职院校近年来招生存档数据,以Excel表格的形式提供.通过挖掘学生性别、专业、生源地、毕业类别、成绩等对报到率的影响,找出影响学生报到率的因素,为院校的招生宣传、专业规划及招生计划的投放提供决策依据[4].
在数据挖掘过程中,数据的预处理是其中的重要阶段.由于数据量大,一些数据项会存在错误,比如数据值冗余、异常和丢失等情况,这些问题都会对数据挖掘工作造成不良影响,所以需要选择相应的数据预处理方法对原始数据进行相应的处理[5].在数据表中,准考证号第一位和学生类型相关,因此只需要对准考证号的第一位数据进行捕捉即可,舍弃其他位的信息;一个学生由一个唯一的序号来表示,所以学生姓名在本次挖掘过程中没有作用;总成绩的分布可以看作是离散的,但是离散程度太大,实际过程中还需要采用分段的方式进行归纳.表1为预处理后数据表结构.

表1 预处理后数据表结构
3 关联规则在数据挖掘中的应用
3.1 基本情况分析
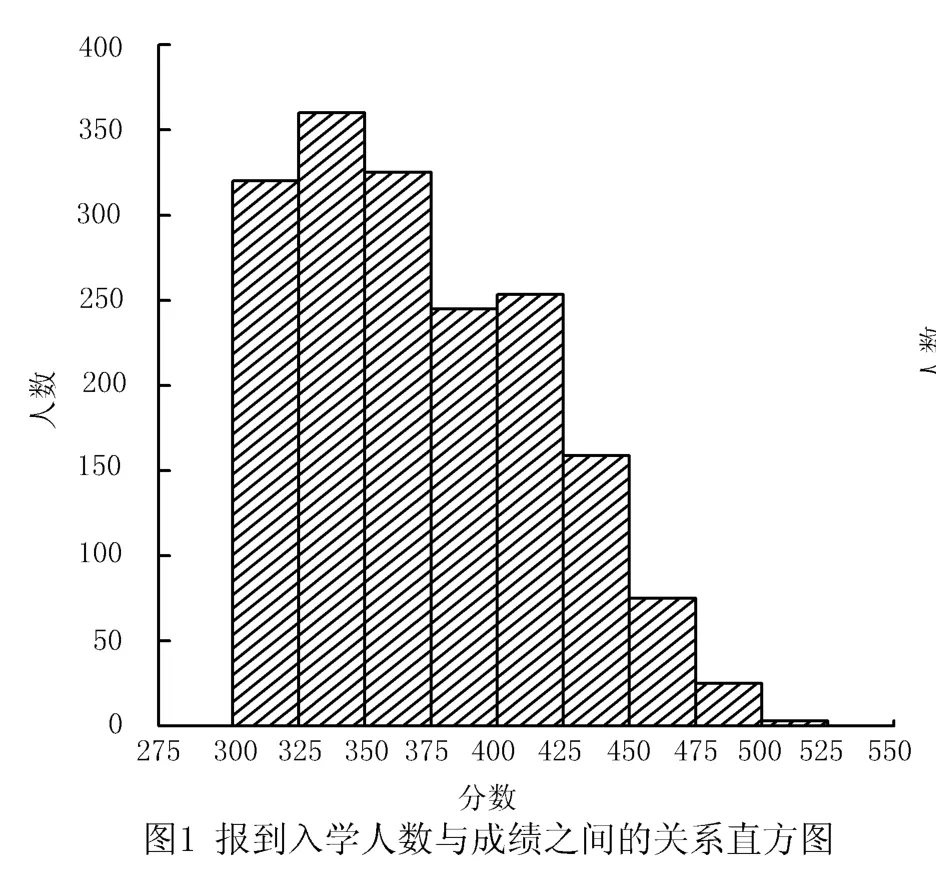
该高职院校2018年入学的学生中,325~350分区间人数最多,为370人.从学生的成绩来看,报到入学的学生成绩主要是在300~475分之间,475~500分以及500分以上的人极少.影响新生入学的因素比较多,以下将结合学生的类别属性和成绩来对学生的报到率进行分析.图1为该高职院校报到入学的学生人数与成绩之间的关系直方图结果,图2为该高职院校在2018年录取的不同类别、不同生源地的学生入学情况.通过对数据进行简要的分析之后发现,该校的新生报到率与未入学率结果主要如下:
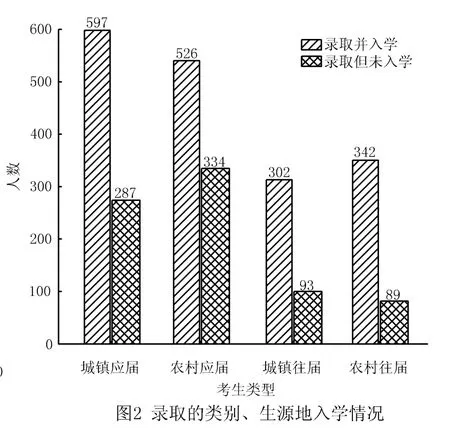
(1)2018年该高职院校录取的新生中城镇应届生与农村应届生入学率分别为20%与14%,城镇应届生与农村应届生未入学率分别为12%与14%;城镇往届生与农村往届生入学率分别为13%与14%,未入学率分别为5%和4%.由此可以看出该高职院校往届新生入学率普遍低于应届新生入学率.
(2)对该校2018年入学学生的成绩进行分析发现,城镇地区应届学生,成绩处于一般水平的入学率较高,为76%;未入学率为24%;成绩处于中等水平的入学率次之,为59%;成绩处于高等水平的入学率最低,为27%.农村地区应届学生,成绩水平一般的入学率为62.5%;成绩处于中等水平的入学率为38.5%;成绩处于高等水平的入学率只有1.4%.
我们能够发现生源地不同、类别不同,学生的录取率也会随之发生相应的变化.图中数据呈现出的结果为,农村应届生报到入学以及未报到的人数均高于农村往届生比例;城镇应届生报到入学及未报到的比例也都高于城镇往届生.从整体上来看,农村往届生和城市往届生的总人数与农村应届生与城市应届生相比明显更低.
3.2 利用平台进行数据挖掘
综合该高职院校新生的报到信息数据,在对高考成绩进行挖掘之前需要对其进行概化处理,即将其分为不同的成绩范围值;在对户口所在地进行数据挖掘之前需要将新生分为不同的类型,如“城镇新生”“农村新生”;考生类别则是分为“应届”与“往届”.本次设计的基于关联规则的数据挖掘平台,其置信度控制在20%左右,支持度设置在0.1%左右.利用对本次所设计的影响新生报到入学的因素数据挖掘平台进行数据挖掘之后,所获得的关联规则共达到了400余条,挑选其中比较有代表性的10条数据,如下所示:
(1)关联规则:农村应届录取新生>入学报到;[sup=20.8%;conf=60.5%]
(2)关联规则:城镇应届录取新生>入学报到;[sup=23.8%.conf=65.9%]
(3)关联规则:城镇应届/女生>入学报到;[sup=8.15%;conf=72.3%]
(4)关联规则:城镇应届/男生>入学报到;[sup=14.6%;conf=62.8%]
(5)关联规则:农村应届/女生>入学报到;[sup=7.6%;conf=68.1%]
(6)关联规则:农村应届/男生>入学报到;[sup=12.8%;conf=58.7%]
(7)关联规则:城镇应届/女生/省会>入学报到;[sup=0.6%;conf=61.8%]
(8)关联规则:城镇应届/男生>入学报到;[sup=1.3%;conf=66.4%]
(9)关联规则:农村应届/女生/省会>入学报到;[sup=0.2%;conf=55.6%]
(10)关联规则:农村应届/男生/省会>入学报到;[sup=0.8%;conf=54.9%]
根据关联规则分析结果,我们能够看出城镇应届生报到率与农村应届生报到率相比明显更高;女生的报到率与男生相比更高;成绩处于“好”范围之内的学生报到率与成绩处于“较好”与“一般”范围的学生相比其报到率会更低一些.这些规律在实际的工作当中我们也有所体会.比如农村地区的一些学生受到家境及经济条件等因素的影响,他们可能会选择学费更低的学校学习或者是希望考上更好的学校,但并未如愿,而选择放弃,直接就业.
4 结语
随着招生制度的改革,各院校的招生向着自主化、多元化的方向发展.如何利用好现有的数据来解决招生决策中面临的问题,变得十分重要.通过对新生报到影响因素数据挖掘系统的研究分析能够发现在高职院校录取工作过程中所出现的表象或是潜在的特征与规律,这样可以帮助学校实现更好的针对性管理,让学校在教学管理、学生公寓安排、专业设置、班级设置等方面提前做好准备和调整,避免由于招生盲目性所带来的不良影响.
