基于相似度组合的主观题评分方法研究
2021-09-26肖灵云刘军库
肖灵云,刘军库
(广东海洋大学寸金学院 智能制造学院,广东 湛江 524000)
随着互联网技术、信息技术和经济的发展速度的提高,对现代教育以及企业的影响逐渐显现出来,使得现代教育及企业的变革迎来了新的机遇及挑战。在现代教育教学中,许多现代化教育手段(如线上授课、在线考试等)被普遍应用于日常教学中[1]。通过自动评分系统的应用,教师不仅可以减少阅卷的工作量,而且可以使阅卷结果更加公平公正[2]。在企业发展的过程中,企业进行招聘人员及日常考核及培训时,需要进行考试。尤其是经过疫情之后,现代教育中的线上授课及线上考试现象更加普遍,企业的招聘和日常测试的试题也转到了线上。随之而来的问题就更加明显,如何对主观题进行自动评分,就成为困扰教师和企业考核者的难题。
考试作为一种选拔人才及检测考生水平的工具,普遍被用在学校、企业中,考试的题型主要有客观题和主观题。考试中对于单选题、多选题等的自动批改技术已经较成熟,而主观题自动评分方法涉及了自然语言处理、人工智能等多方面的理论知识,使得主观题的评分难度增加。目前的主观题评分方式仍采用人工方式,不仅时间耗量大、工作量大,而且不同批阅者之间的评分标准有差异,易受改卷人主观因素影响,造成评分偏差,体现不出考试的公平性。因此,研究并实现主观题自动评分系统,能提高教师批改试卷的效率及公平性。
由于主观题题型的复杂性,目前还没有完善且成熟的主观题自动评分系统。而在已有的主观题自动评分系统中,其可用性与实际的需求差距还很大。因此,对于主观题的自动评分,不仅是当前亟需解决的问题,也是一件难度很大的问题。通过对文本、语义、关键词等方法计算主观题相似度进行研究,发现文本相似度、语义相似度、关键词相似度计算算法都存在着不同的短板。文本语义所包含的信息较多,能够代表文本所表达的整体意思,但这种方法有时会忽略掉关键词的作用;语句语义能够准确地提取语句的信息,但容易忽略掉语句与前后文之间的关联;关键词相似度能够以更小的单位提取信息,但仅依据一些关键词,往往会将语句信息和文本信息忽略掉,而且会存在只写出关键词就能得高分的弊端,如果这种弊端被考生利用,那么评分也就没有意义。
针对这些不足,本文对主观题自动评分方法进行研究,所涉及的核心技术是基于相似度组合的方法来计算考生得分。它涉及到人工智能(artificial intelligence,AI)、自然语言处理(natuarl language processing,NLP)等多方面理论知识[3],以及一些自然语言范畴的先进关键技术。在理论意义上,将相似度组合模型应用在主观题自动评分上,扩展了主观题评分模型;在应用意义上,可以积累主观题自动评分的经验,为后续进一步深入研究主观题的自动评分提供一定的借鉴与参考。
1 相关技术
文本向量化的作用主要是将文本转化为结构化的数据,即将文本用可以表达文本语义信息的向量来表示。对文本向量化的很多探究都是在Word2vec(词向量化)的基础上来完成,而Doc2vec(段向量化或句向量化)是将文本段落或句子作为文本处理的基础单元进行处理。这里仅介绍Doc2vec模型。
1.1 Doc2vec模型
基于分布假说理论,Word2vec能够较好地挖掘出文本中词语所蕴含的潜在的语义信息,能够计算词语与词语之间的相似度、句子与句子之间或其他长文本之间的相似度。由于该方法没有将文本中的语序信息考虑进去,从而也就丢失了很多的主要信息,所以Word2vec技术存在不足之处。
Doc2vec技术中包含的模型有DM和DBOW两种[4]。在DM模型中,增加了一个段向量,该段向量与词向量的长度相同,也就是说该模型中上下文所包含的范围更广泛。它既涵盖了文本中上下文中的单词,又涵盖了其所对应的段落。它可以通过文本中上下文中的词向量和段向量,对目标词的概率分布进行预测。而且在对文本进行向量训练的过程中,在DM模型中增加了一个paragraph ID,首先将其映射成一个向量。在后面的计算中,可以将段落向量与词向量进行累加,也可以将它们连接起来,并将其输入给softmax层。在对文本中的语句或者整个文档进行训练时,要保证paragraph ID是固定的,它不发生改变,共同使用同一个paragraph vector,相当于每次在预测目标词的概率时,都用到了该句子的整体语义信息。在对文本进行预测时,需要给待预测的语句新分配一个paragraph ID,输入到词向量和输出层softmax的参数,应该与训练阶段得到的参数保持一致;然后利用随机梯度下降算法对待预测的语句进行训练;等误差达到一定的要求,收敛后,即得到待预测语句的段向量。DM模型示意图如图1所示。

图1 DM模型示意图Fig.1 Schematic diagram of DM model
DBOW模型在只给出某个段落的情景下,应用DBOW模型预测相应段落中的一些随机词的概率。DBOW模型示意图如图2所示。
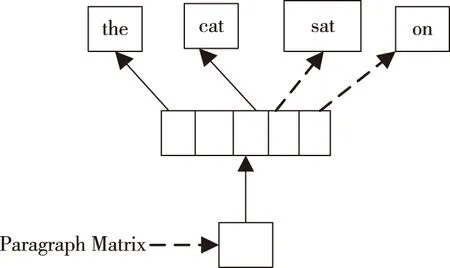
图2 DBOW模型示意图Fig.2 Schematic diagram of DBOW model
应用Doc2vec技术既可以将文本中的语义信息进一步提取出来,又能将文本中的语序信息有效保留。
1.2 文本相似度技术
本文采用余弦相似度[5-6]来计算考生提交的答案和参考答案之间的相似度,其中以参考答案作为标准。将考生答案和参考答案进行段向量化,依据两个文本答案的向量之间夹角的余弦值大小,评估两个文本向量之间的相似程度,计算公式如式(1)所示:
(1)
其中,sim表示相似度,M为已给出的参考答案中文本的语义信息段向量,N为考生提交的答案中文本的语义信息段向量,θ为文本向量M和N之间的夹角,Mi、Ni为文本向量M、N中的各个分向量,n为各个分向量的总个数。
2 基于相似度组合的评分方法
通过分析对比基于TF-IDF相似度算法、Word2vec语义相似度及Doc2vec文本相似度算法,发现各种算法中存在的问题。为了充分应用各种算法的优点,构建了一种基于相似度组合的主观题(简答题、论述题)自动评分模型。
2.1 基于Doc2vec计算文本相似度
利用Doc2vec计算文本相似度的原理为:通过文本中上下文中的词向量和段向量,对目标词的概率分布进行预测,并利用该向量计算文本相似度。具体步骤如下:1)对文本进行预处理;2)将文本向量化;3)进行文本相似度计算。
基于Doc2vec计算文本相似度的具体算法如图3所示:

图3 基于Doc2vec计算文本相似度的具体算法Fig.3 Specific algorithm of text similarity calculation algorithm based on Doc2vec
2.2 评分模型构建
评分模型构建的思想为:1)考虑整体语义的准确性;2)将文本、语义、关键词相似度3种方法组合起来使用,并设置阀值,通过灵活调节阀值的大小来保证评分的公平性,阀值为C,取值范围为[0.85,0.99]。本文设置的阀值为0.9。依次计算参考答案与考生答案的文本相似度、语义相似度及关键词相似度。如果任一种算法的相似度值达到0.9,则将该考生答案判为满分(该道题的分值);如果这3种算法的相似度值都低于0.9,则从这3种相似度中选择最大的相似度值作为该考生答案的最终相似度值,并计算出考生的得分。构建的评分模型如式(2)所示,构建的评分模型流程如图4所示。

图4 评分模型流程Fig.4 Scoring model flow
(2)
式中,yi为第i道题的评分,C为设置的阀值,Si为第i道题的分值,sim为相似度。
3 实验数据收集与评价指标
3.1 实验数据集
本文以《系统建模与仿真》考试中的简答题、论述题构建试题库,共165道题目。55名考生参加考试, 155道题选自《系统建模与仿真》试题库。通过考生答题情况,收集有效数据1 539份,作为实验数据集。将考生作答的答案输入系统中,并由老师对简答题、论述题进行人工评分及系统自动评分,将评分结果存储到系统中。
3.2 实验评价指标
本文采用平均值、方差及偏离率3个指标来衡量相似度组合评分与人工评分的一致程度。平均值的计算公式为
(3)
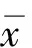
方差是指数据点的离散程度。其数学定义为
(4)

本文采用的偏差率是指实际值比理论值或者估计值的偏差程度[7],用于表征实验效果的好坏情况。偏差率计算公式为
(5)
(6)
式中,D为偏差率,Davg为平均偏差率。
3.3 实验结果分析与对比
为了验证提出的基于相似度组合的主观题自动评分方法的有效性、准确率及实用性,以《系统建模与仿真》试题作为实验数据,并将评分结果与传统方法的评分结果进行对比。
1 539份《系统建模与仿真》试题利用本文构建的基于相似度组合自动评分模型进行评分,并与基于Word2vec算法评分、基于TF_IDF算法评分、基于Doc2vec算法评分进行对比,然后再分别与人工评分进行两两对比。表1仅展示了4种自动评分方法与人工评分结果对比的部分数据。这几种算法计算的简答题、论述题的自动评分结果(共1 539份)的平均值、方差比较如表2所示。自动评分结果的偏差率比较如表3所示。
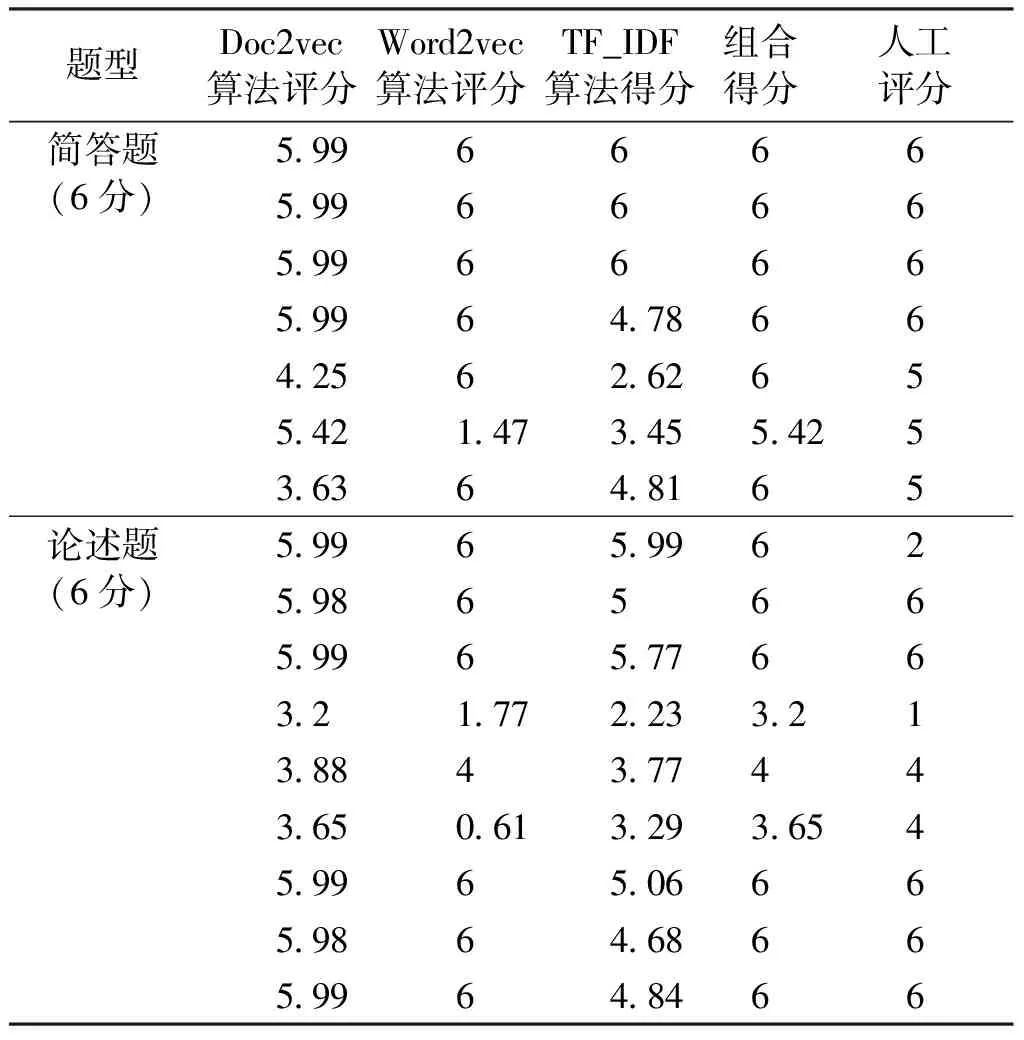
表1 4种自动评分方法与人工评分结果对比表Tab.1 Analysis of four automatic scoring methods and manual scoring results

表2 自动评分结果比较Tab.2 Automatic scoring result comparison
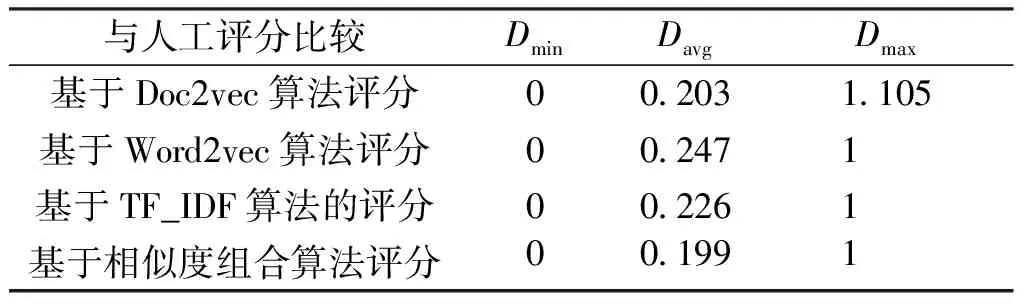
表3 自动评分结果偏差率(D)Tab.3 Deviation rate(D) of automatic scoring results
由表2可知,相对于其他评分方法,本文所提出的评分方法计算得到的分数与人工评分的分数最吻合。本文提出的算法,能够准确进行整体文本语义分析,有效提高文本相似度计算的准确性。而其他评分方法无法准确分析文本语义信息,得到的评分结果与教师评分的结果就有较大的偏差。说明基于相似度组合算法评分较稳定,评分效果较好。
从表3,更能进一步说明本文提出的基于相似度组合算法的评分是有效的,与其他几种算法的自动评分结果相比,基于相似度组合算法自动评分结果的平均偏差率为0.199,偏差率波动范围为1。
4 结束语
本文以《系统建模与仿真》的主观题试题作为数据集,研究中文主观题自动评分问题。针对文本相似度、语义相似度、关键词相似度的不足,提出一种新的主观题评分模型,实现了一个主观题评分系统。
采用本文构建的基于相似度组合的主观题评分模型进行主观题自动评分,通过对比分析,得出评分模型的评分结果波动性较小,稳定性较好,说明提出的评分模型是可行有效的。由于构建实验数据集需耗费大量的人力,导致实验所使用的数据集的科目范围较少,无法全面地评估主观题自动化评分方法的有效性及普适性。因此,如何构建一个文本覆盖面广、涉及多领域的评分数据集,将是后续的一个研究方向。
