基于大数据平台的科研病种库系统设计与实现
2021-09-24王觅也李言生龚后武
王觅也,刘 然,王 尧,李言生,叶 琳,龚后武
(1.四川大学华西医院信息中心,医疗信息化技术教育部工程研究中心,成都 610041;2.西部战区空军医院,成都 610065;3.东华医为科技有限公司,北京 100089)
0 引言
近年来,随着信息化技术的发展,大数据技术在工业制造、智能交通、医疗科研等多个领域得到广泛应用[1]。临床科研作为医疗科研的重要组成部分,其形式有临床科研课题立项、临床案例分享、临床经验总结等。在各种形式的临床科研实施过程中,科学循证是关键,其强烈依赖于大量临床真实数据支撑。目前,建立科研病种库逐渐成为临床科研数据收集、整理和分析的主流模式,而如何将大数据技术与科研病种库结合利用,更加方便地实现科研数据需求的采集、提取和分析,是目前面临的一个重要难题。
20世纪中叶,西方发达国家便开始了对医学临床科研病种库的研究和建设。Greenes等[2]于1969年首次利用数据库技术对临床诊疗数据进行管理和利用。截至目前,国外已形成了大量的多中心单病种数据库,如美国CIRS急诊医学数据库(CIRSEmergency Medicine Databank)、日本心血管外科数据库(Japan Congenital Cardiovascular Surgery Database)等,大大促进了相关学科发展。国内的病种库建设与国外相比还有很大差距,但也呈迅速增长的态势。专业的临床医疗科研人员根据专科常见疾病建立起疾病的相关因素、预期目标和质量评价知识库等,越来越多的医院开始将临床科研数据库的建设工作从线下迁至线上,从单中心研究向多中心研究转变,如南方医科大学建立的在线肺癌病历数据库[3]、军事医学科学院附属医院建立的消化系统肿瘤数据库[3]、中国医科大学附属第一医院建立的基于医疗大数据的省市级肺癌专病库平台[4]等。这些传统的多中心病种库系统大多是围绕某一特定的疾病构建,数据采集工作大多依靠临床医师人工录入,工作量大,数据易出错,数据库运维成本高,数据持续性弱。
本文提出将科研病种库系统搭建于大数据平台上,通过大数据技术全维度治理后的标准数据资源池实现数据的自动采集,达到减少人工工作量、保障数据质量、降低运维成本的目的。大数据平台的支撑解决了数据获取难的问题,临床科研所需数据变得可见、可得,为全院各科室使用系统自行构建病种库提供了很好的应用基础。打造院级层面的科研病种库系统,不仅需要临床科室参与,更需要医院信息部门的技术投入,共同构建“医学+信息”交叉合作的工程应用模式。
1 系统设计
1.1 需求分析
我院是一所综合性研究教学医院,为了给院内大数据的应用服务提供数据能力支撑[5],构建了医疗大数据平台。大数据平台基于先进的大数据系统框架、分布式数据库、人工智能等技术构建,在大数据处理分析方面很具优势[6-7]。
长期以来,很多科室凭借课题和项目的机会构建了一些独立封闭的科研数据库系统,当整个科研项目结题后,这些科研数据库便进入了无持续资金投入、无人维护的状态,造成了数据资源的浪费。因此科研病种数据库系统需纳入医院统一管理,同时为提升科研效率、减少医生工作量并保障数据的持续性和稳定性,临床数据采集需自动化,且数据范围应纳入全院所有临床业务系统的数据。为满足上述需求,亟须构建面向全院的基于大数据平台的科研病种库系统。
科研病种库系统需要集成专病患者全周期数据。患者诊疗过程中的数据,如影像、病理、病历文本等可从电子病历系统中获取到,而患者诊前和诊后的数据需要进行随访采集,随访表单的设计一般通过病例报告表(casereport form,CRF)实现[8]。传统的科研病种数据库构建方式无法同时纳入医院多个系统接口数据,无法实现文本资料的结构化[9-10]。基于大数据技术的科研病种数据库可对全维度临床数据进行数据治理,实现结构化和术语化[11],形成临床科研资源中心,为科研病种库系统的构建提供丰富而完善的数据资源,使科研数据提取效率成倍提升,大大减少科研流程中的人力劳动,满足科研应用需求,为临床辅助、疾病研究和产品孵化等领域提供支撑。
1.2 架构设计
基于大数据平台的科研病种库系统的整体架构如图1所示。医院大数据平台集成电子病历系统、医院信息系统(hospital information system,HIS)、检验系统等数据,基于大数据相关技术,整合、清洗医院多源异构数据,并基于临床科研所需要的数据构建科研数据中心(research data repository,RDR),形成科研病种库系统的数据源。医院大数据平台数据治理的主要工作包括进行数据建模、数据后结构化、数据标准化、元数据管理、主数据管理和数据质量控制等。同时,该平台也汇集了四川大学华西医院医联体的临床数据资源,在开展多中心研究时,通过RDR中的医院标识可自动提供不同医院的数据支持。科研病种库系统根据用户的科研需求实现科研应用,可按病种、项目、科室层面、医院层面多学科联合构建病种库,也可部署外网版支持跨医院的多中心联合共建病种库。系统提供用户管理、项目组管理、项目组成员管理、项目属性维护、CRF设计、随访设计、病例入组、病例浏览、访视进度总览、人工智能(artificial intelligence,AI)随访、大数据检索、CRF检索、数据导出等模块实现临床数据的科研分析,发现病种规律,发掘病种新特征。系统的数据可导出到大数据平台数据挖掘模块,进行数据统计、分析模型的算法开发以及模型的管理和发布等科研活动。

图1 科研病种库系统整体架构图
本系统采用浏览器/服务器(Browser/Server,B/S)体系结构,采用ASP.NETMVC4实现分层技术架构,将展示层、业务层和数据访问层分离。Bootstrap+JQuery呈现用户界面展示层,提供对IE、Chrome、Firefox的全面兼容。在数据访问层,根据Cache特性开发的ORMapping实现基础业务数据访问。针对Greenplum构建的RDR,采用Spring Boot组建数据读取服务,为表单外部数据和数据查询导出提供数据服务支持。将业务层和数据访问层的通用处理能力提炼出来,成为另外一种通用的机制,包括系统授权机制、异常处理机制、日志记录机制、缓存机制和安全控制机制。此外,采用插件机制实现客户化定制功能,如自定义CRF,采用Vue.js+MySQL组合完全解除对科研系统的依赖,除易于维护之外,也便于后续无缝对接移动端随访。
2 系统实现
2.1 系统运行流程
为解决传统专病科研遇到的“科研构思难、数据获取难、想法验证难、数据处理难”等系列问题[12],我院将临床科研全流程进行深度解析和优化改造,包括数据获取、专病库建立、发现问题和提出假设[13]等各环节,设计了面向全院的基于大数据平台的科研病种库系统。本系统以数据为驱动,基于各专科专病进行病种库构建,临床科室根据其需求自行配置专病数据库的数据采集表单、随访模式,信息科负责大数据平台数据治理,为各专病库提供数据接口,辅助临床医生便捷、高效地完成整个科研过程。系统运行流程如图2所示。

图2 科研病种库系统运行流程图
2.2 功能模块
科研病种库系统主要包括项目管理模块、病例管理模块、随访管理模块和数据利用管理模块,具体功能模块结构图如图3所示。
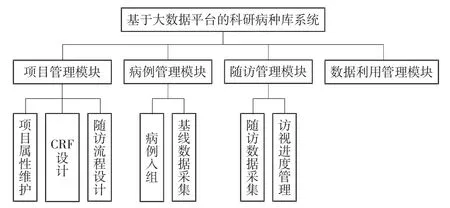
图3 科研病种库系统功能模块结构图
2.2.1 项目管理模块
2.2.1.1 项目属性维护
系统以低耦合的设计方式将病种项目的常规管理和科研数据应用分析分离,确保了系统稳定和科研项目的安全。系统管理员负责各个病种库项目的创建和属性维护,项目属性包括项目名称、级别、责任科室、项目负责人等,项目属性维护界面如图4所示。科研项目管理员负责处理病种数据的增删查改和分析统计。系统提供用户管理和角色管理功能,将不同用户和角色在操作权限上区分和隔离,通过统一授权验证将登录用户信息与对应的配置权限关联,确保在系统使用过程中的权限单一和安全。
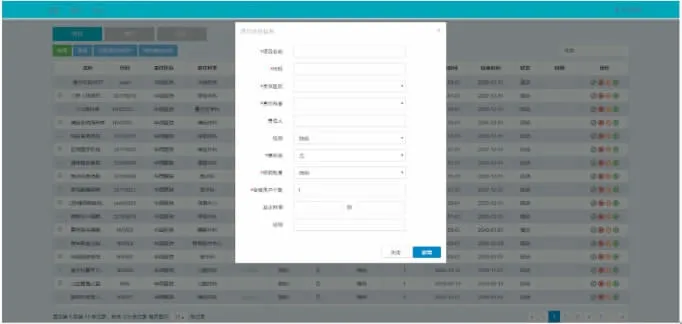
图4 项目属性维护界面
2.2.1.2 CRF设计
不同科研项目需要采集不同的病种相关数据,传统由文件导入或由工程师完成采集会导致数据质量和数据关联较差。科研病种库系统提供一个全面的CRF设计模块,包括表单数据项组件管理、表单设计管理、表单版本发布管理和表单权限管理4个内容。表单数据项组件管理是将CRF的每一个数据项组件作为全局的元数据项目进行统一维护和管理,确保不同表单中的数据项概念一致。表单设计管理是专科医生将相应的数据项组件进行布局和配置,如图5所示。每个数据项组件根据不同科研需要,设置相应的位置、对齐、字体、颜色、名称、函数事件、字典值域等属性信息。同时,组件还可以设置大数据平台业务数据接口,实时抓取数据,减少手工操作误差。在一张完整的CRF中,可配置组件间的数据校验规则,确保表单填写的数据质量。表单版本发布管理和表单权限管理功能可确保每个CRF在限定的权限下,通过标准应用程序接口(application programming interface,API)与不同科研项目、不同病种库的数据进行交换。
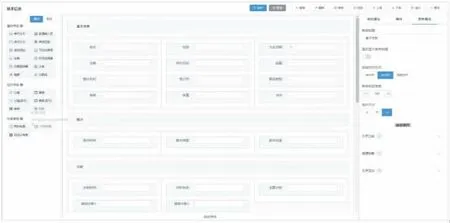
图5 CRF设计界面
2.2.1.3 随访流程设计
系统提供多种随访类型以支持不同的科研需要,有参考点随访、统一随访、自定义随访、无计划随访、参考点和无计划相结合随访等,不同类型的科研项目可选择不同的随访类型。每一种随访类型都可以自定义随访流程,随访流程设计界面如图6所示。随访流程是基于用户常用的5种场景建立数据模型:(1)基于开始时间,完全按计划时间随访;(2)基于开始时间,根据实际随访时间调整计划随访;(3)本次随访完成后,指定下次随访内容和时间;(4)随到随访;(5)第一个阶段按计划随访,第二个阶段随到随访。由于每个随访数据模型差异较大,采用JSON(JavaScript object notation)存储和传递,后台业务处理层通过对象反射机制识别随访模型并计算随访时间计划和表单绑定,从而对每个病种患者生成随访日期排程。

图6 随访流程设计界面
2.2.2 病例管理模块
2.2.2.1 病例入组
系统支持利用大数据平台上的病历检索引擎查询大数据资源池的临床数据,查询符合条件的专病病例进行批量入组。大数据检索的建立,可以实现在千万份病例中的秒级查询,如图7所示。
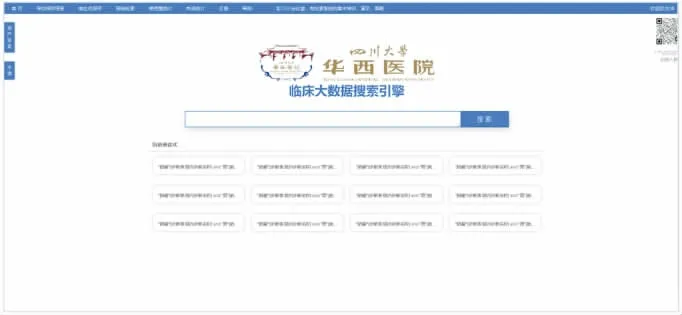
图7 大数据病历检索引擎界面
系统还支持其他多种入组方式:HIS直接入组、手工通过病历号入组、批量导入病历号入组等。系统通过Web Service方式根据病历号、医院编码获取基本信息;通过JQuey绑定验证函数对姓名、性别、身份证号等字段进行验证,病例具有唯一性验证,重复病例不入组。病例入组后系统根据随访流程自动生成该病例的随访计划。在病例列表清单中可配置显示数据表单的填写率,以提醒科研工作者及时进行随访工作。病例入组和列表界面如图8所示。

图8 病例入组和列表界面
2.2.2.2 基线数据采集
将设计完成的CRF导入基线数据采集模块,如图9所示。根据基线数据的要求输入相应的患者唯一ID、访视关联就诊ID和观测阶段3个基线条件,并将基线数据类型、基线值校验、关联校验和规则校验根据科研项目需求进行相应配置,系统提供的基线数据采集模块自动调用标准的Web Service服务完成所有基线数据的采集。基线数据类型和基线值校验可确保每一个单独的基线数据质量,关联校验和规则校验可进一步确保基线数据间的质量,如性别选择“男”时,不显示月经初潮年龄等。基线数据采集模块将数据读出、数据校验、数据处理和数据写入的完整流程按照系统要求实时记录日志,并提供每一个细致步骤的查询和分析。
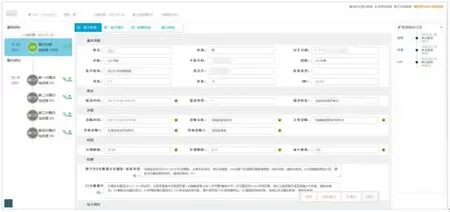
图9 基线数据采集界面
2.2.3 随访管理模块
2.2.3.1 随访数据采集
系统提供人工采集和机器智能采集2种模式的随访数据采集。传统的人工采集方式是科研人员根据所设定的计划拨打随访电话,逐一问询情况并完成CRF的数据填写。机器智能采集提供话术管理、随访执行、语音识别处理和随访结果管理4个功能。科研人员在话术管理中设定随访的问询流程和逻辑处理预案,通过系统提供的环境测试并保存。系统根据随访计划,自动拨号并以保存的话术模板启动人机交互的语音机器人完成随访。通过智能语音识别处理功能,使人机交互的对话信息形成对应的随访信息。最后,随访结果管理将随访信息按照CRF要求完成随访结果的自动填充。AI随访界面如图10所示。所有机器智能采集的语音信息和文字数据均保存在大数据平台的安全存储环境中。随访结果管理还提供语音复播功能,便于科研人员对智能语音识别结果存疑时的复审和修正。

图10 AI随访界面
2.2.3.2 访视进度管理
系统提供全角度的访视进度管理,在授权的科研项目组下所有患者的访视进度和随访状态以不同颜色区分显示,如图11所示。科研用户可以根据参考点随访、无计划随访、回顾性随访、观测阶段等不同的随访类型进行管理和查看,也可以根据研究方向自定义分组规则并管理满足规则的患者当前的随访进度和状态。系统提供已完成、窗口期内、窗口期外、超期、未指定方式5种随访状态的查询。根据不同的随访类型和状态,访视进度管理模块还提供预警提醒和主动干预功能。预警提醒与大数据平台的消息中心实时对接,将访视的异常情况以消息方式实时推送给科研用户,科研用户可以使用主动干预功能,对访视情况特殊的患者及时调整随访计划和随访方式。

图11 访视进度总览界面
2.2.4 数据利用管理模块
数据利用管理模块提供科研病种库数据的查询和导出,授权后的科研用户可以以任意维度检索和导出病种库数据,CRF检索和导出界面如图12所示。不管是实时接入的基线业务数据,还是通过CRF采集的数据,在表单数据项组件的统一管理下,以元数据统一技术实现数据概念层的一致。科研用户可以自定义组合各种检索条件,也可以手动输入结构化查询语言(structured query language,SQL)进行检索。所有检索结果可以直接导出为Excel表格,也可以直接形成含有项目组权限的数据集供外部调用。系统还提供标准的软件开发工具包(software development kit,SDK),第三方系统通过标准API与科研病种库进行对接。为确保数据安全,防止恶意的SQL注入攻击,系统优化SQL语句的智能拼接,并全面采用语言集成查询(language-integrated query,LINQ)技术实现病种库数据动态的查询。
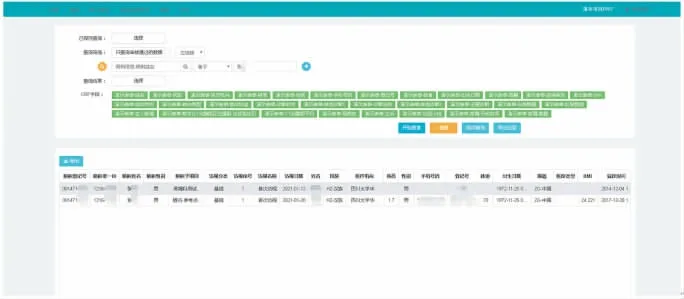
图12 CRF检索和导出界面
3 应用效果
3.1 整体情况
基于大数据平台的科研病种库系统于2020年5月在我院成功上线。医院信息科统一规划信息数据集成工作,负责整合临床诊疗过程的信息数据,实现RDR数据集成和数据治理,在此基础上培训临床科室使用本系统。临床科室主导实施具体科研病种库系统搭建,构建各自的科研项目数据库。迄今为止,累计使用科室数量达45个,用户600余个,累计项目数量达到110个,入组病例数达到80多万例,优化了科研流程,提升了科研效率。同时,数个多中心病种库正在开展,几十家医院参与共建。本系统由于嫁接在大数据平台上,因此具有以下特点:
(1)全新的管理模式。系统支持对全院科研项目的统一集成管理。
(2)灵活的CRF定制。系统支持科研用户自行配置数据表单,无需技术人员参与。
(3)全面的数据集成。系统支持从大数据平台RDR自动获取数据,不需转录,大大减少了科研工作量。大数据平台的数据治理能力使得半结构化和非结构化的数据都能得到充分利用。
(4)精准的检索入组设计。由于大数据平台已经从电子病历系统、HIS、检验系统等获取了海量多维变量,可直接用于多条件检索,因此通过大数据检索引擎进行检索入组,可以更精准地设计患者入组条件,使入组患者更加准确和完整。
(5)便捷的事件流程管理。系统关键事件可以是某次随访,可以是某次就诊,甚至可以是某次服药或者某次手术等,可灵活设置,支撑不同研究目的的科研项目。基线参考点时间可自定义选择或者根据数据采集逻辑自动生成,通过时间线串联各个关键事件节点,以更加直观的方式展示患者从研究开始到结束全程的状态转变。
(6)可支撑多中心项目开展。B/S架构支持在院内跨专业共建科研病种库系统,还支持互联网的部署,支撑异地多中心科研项目的实施和管理。
(7)可支撑医联体数据自动接入。大数据平台不仅集成了本院各系统数据,还集成了各领办型医联体数据,因此对于联盟内开展多中心研究时,其他医院的数据也可实现自动采集,不需像互联网多中心项目那样通过手动录入或者Excel表格导入来实现。
(8)科研病种库的集成更有利于多学科科研的联合开展。当全院科研应用都整合到科研病种库系统时,此系统集成的数据不仅能支撑单科室、单项目的科研统计分析,还能实现全院科研数据的共享应用,支撑临床多学科联合科研。
(9)大数据平台上的挖掘系统可支撑病种库数据的数据分析和数据挖掘。科研病种库的数据可直接导入到数据挖掘系统,该系统集成了常用的统计方法和挖掘工具,方便项目组中的统计师和数据科学家开展模型开发、算法开发工作,医工结合,形成的统计模型和挖掘模型还可作为知识存储到知识库,作为知识积累和传递的途径。
3.2 案例分享
2018年初,国家心血管病中心发布《中国心血管病报告2017(概要)》。据推算,我国心血管病现患人数2.9亿,心血管病死亡占居民疾病死亡构成40%以上,居所有病种首位,高于肿瘤及其他疾病[14]。而急性心肌梗死(acute myocardial infarction,AMI)(以下简称“心梗”)是冠状动脉急性、持续性缺血缺氧所引起的心肌坏死。临床上多有剧烈而持久的胸骨后疼痛,可并发心律失常、休克或心力衰竭,常可危及生命。为尽早发现心梗事件和降低心梗风险,亟须开发一种基于AI的心梗风险预测辅助决策系统,通过该系统,能够对所有住院患者,特别是非心血管专科的住院患者即时评估预警,以支撑一体化、规范化、统筹化地开展院内心梗高危患者信息汇报及预警、病情主动监控、中心调度指挥、救治信息反馈以及数据汇总分析、救护质量控制工作,以减少院内急性心梗事件的发生,提升救治率,从而改善预后。
该系统的开发依托大数据平台上的科研病种库构建心梗患者数据库,通过大数据病例检索引擎,查询RDR数据资源池中诊断关键词包含为心梗、心肌梗死的患者,将查询到的10 937例患者入组入库。通过病史、医嘱等将患者划分为心梗首发患者、心梗复发患者以及1∶1随机抽取的非心梗对照患者,在心梗患者数据库中建立3个项目子组,分别为心梗复发组、心梗新发组、非心梗患者组。随后设计临床CRF,通过RDR的临床数据资源中心自动抓取基本信息、诊断信息、手术信息等数据,完成多维特征的数据汇集。最后利用科研病种库系统的综合查询功能,查询患者维度特征,将数据导出到数据挖掘系统进行机器学习建模。随着时间的推进,将更多符合条件的患者自动纳入病种库,对已有模型进行增量训练,使模型的准确度不断提高。该项目的开展很好地验证了基于大数据平台的科研病种库系统的应用效果。
4 结语
基于大数据平台的科研病种库系统可支撑临床回顾性研究与前瞻性研究,集AI随访和大数据采集于一体,可全方面覆盖临床科研需求,在实际应用中取得了良好的效果,但仍然存在一些不足。例如,在数据采集方式方面,AI随访无论是在语音识别准确率还是在交互智能化方面依然有进步的空间;在数据采集内容方面,大数据平台虽然已经能够提供高维度和及时稳定的数据支持,但目前还不能精准实现电子病历文本数据结构化,仍需用户进行一定程度的结构化处理;在系统功能方面,还未能实现移动端的部署以支撑更多场景的应用。基于大数据平台的科研病种库系统还将继续进行优化,通过移动端、PC端实现多场景的访问。此外,还需将影像数据、音频数据、非结构化数据等多源异构数据纳入系统,完善多渠道的自动采集方式,最终实现多模态科研病种库系统的应用。
