基于部分卷积的文字图像不规则干扰修复算法研究*
2021-09-23瞿于荃邵玉斌杜庆治
段 荧,龙 华,2,瞿于荃,邵玉斌,2,杜庆治,2
(1.昆明理工大学信息工程与自动化学院,云南 昆明 650504;2.昆明理工大学云南省计算机重点实验室,云南 昆明 650504)
1 引言
在各行各业中为了更容易地对文件进行储存或管理,通常是将带有文字信息的纸质文档通过数字化的方式扫描转化为图像后进行识别,以减少人工录入工作。目前对于规范的文档图像的光学字符识别OCR(Optical Character Recognition)已在各种领域中得到应用,但是,在数字化的过程中,大多数文档都无法达到理想的状态,且带有一定的干扰信息,例如文档之中用于标记重要内容的横线等,致使识别率下降。虽然可以通过二值化[1]等算法进行预处理,但是对于与文字进行粘连的干扰部分却依旧无法进行处理[2]。对于不能识别的拒识字也有学者利用上下文信息的相关性进行后处理[3,4],进一步提高了准确率,当初步识别效果较差时,相关性匹配的方法并不能显著地提升准确率,并且它依赖于一个健全的候选字库和上下文信息(即语言学知识)。因此,如何有效地去除干扰,对于减少文档图像拒识字,提升识别准确率具有不容忽视的作用,同时也给修复污损的文字作品提供了新思路。随着历史更迭发展,部分古籍文献、金石碑文以及书画作品在流传过程中,由于各种不稳定的保存因素,比如自然的老化、发霉受潮、动物撕咬等,导致完整的汉字字迹变得模糊不清或是局部残缺。针对文物字画和碑刻的破损书法作品,使用传统的手工方法修复不仅流程繁复[5 - 7]而且耗时较长,除了考究修复人员高超的复原技术和耐心之外,还要求其对历史事实持有科学而又严谨的态度。
目前,文档图像去除干扰的工作可以分为2类:一是类似于表格或是下划线与文字信息没有粘连的干扰[8],此类干扰可利用线条的结构性特征进行去除;而另一类则是与文字信息产生粘连的干扰[9]。以上方法仍是针对线条类的干扰进行修复,而对于不规则图案的干扰却没有合适的算法。近年来,基于深度学习网络的图像修复(Image Inpainting)发展迅速,在2016年的CVPR(Computer Vision and Pattern Recognition)会议上,Pathak等人[10]结合CNN(Convolutional Neural Networks)和GAN(Generative Adversarial Networks)网络首次提出图像修复算法。在此算法的基础之上许多作者又提出了改进算法[11,12],如:Pathak等人[10]和Yang等人[13]假设的干扰图案是一个大小为64×64的矩形框,且位于128×128的图像中心,但此类方法的修复只是集中于图像中心的矩形区域,不适用于文字图像的修复工作。而Iizuka等人[14]和Yu等人[15]则突破中心矩形框的干扰假设提出了对不规则图案进行修复的算法。但是,此类算法往往需要依赖复杂的后处理,例如:Iizuka等人[14]采用快速行进算法(Fast Marching)[16]和泊松融合(Poisson Image Blending)[17]的方法对图像进行修复。此外,还有基于Patch的方法[18,19],通过在图像中没有干扰的部分搜索相关的Patch进行图像修复,而这样的搜索需要耗费大量的计算成本,虽然之后研究者提出了更快的Patch搜索算法—— PatchMatch[20],但该算法主要是利用非缺失部分的图像统计信息来填充缺失部分,其处理速度无法满足实时应用的需求,且不能进行语义感知的Patch选择。NVIDIA公司Liu等人[21]所提出的PConv(Partial Convolution)层使用传统的卷积网络,不依赖额外的后处理,通过不断学习缺失区域和原始照片,对不规则的干扰部分进行修复。通过一系列的实验研究表明,PConv方法优于PatchMatch[20]、GL(Globally and Locally consistent image completion)[14]和文献[15]的方法,文献[21]使用堆叠的部分卷积运算和自动掩码更新步骤(Automatic Mask Update Step)来执行图像修复,论证了图像需要修补的部分会随着层数的增加和更新而消失,因此该方法不受限于形状或纹理。这种修复方法与文字图像、碑刻或书法作品所要求的修复条件相符,即修复的纹理以及颜色是不唯一、不固定的。
本文为解决不规则干扰文字图像中,字符缺损导致识别准确率下降的问题,提出了基于部分卷积的文字图像不规则干扰修复算法,以部分卷积作为卷积方式,基于U-Net框架和自动更新步骤,循环对缺损区域进行逐层修复训练,并将此算法应用于古代文字图像的修复之中,以进一步对书法、碑刻等文字作品修复进行理论及实践探究。
2 PConv和U-Net
2.1 PConv
NVIDIA在2018年ICLR会议上公布了PConv层[21]对图像进行修复的成果,并将PConv层表示为式(1)所示:
(1)
其中,WT是卷积滤波器的权重,b为对应的偏差。X是当前卷积(滑动)窗口的特征值(像素值),M是相应的二进制掩膜(mask)图像,⊙表示逐像素乘法,比例因子sum(1)/sum(M)应用适当的缩放比例来调整有效(屏蔽)输入的变化量。由式(1)可得出,输出值仅取决于非屏蔽输入。sum(M)表示滑动窗口M中有效像素点的个数。由式(1)可知,卷积运算的输出值主要取决于有效像素点。
自动掩码更新步骤如式(2)所示:
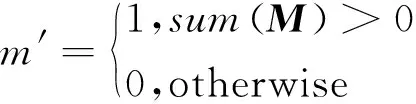
(2)
将输入图像包含至少满足一个条件的像素点,标记为有效像素。在部分卷积层有足够的连续应用的情况下,不断修复图像直至将所有无效像素点的值修复为1,即表示图像修复完成。
2.2 U-Net
U-Net网络模型大多数情况下是应用于医学图像分割领域,网络形状呈现为U型。降采样的特征图与同维度大小的上采样特征图通过Skip Connection将高低层次的特征进行融合,适用于样本量少的应用场景,且运算速度快。U-Net采用了2006年Hinton等人[22]在深度信念网络DBN(Deep Belief Network)中首次提出的编码器-解码器思路,除语义分割外U-Net网络结构可用于图像去噪,在训练阶段将原始图像与噪声进行融合后放入编码解码器中,目标是将加扰图像还原后得到原始图像。
在U-Net网络结构中编码器的作用是对输入图像的特征进行提取,降采样的理论意义是增加对输入图像的一些小扰动的鲁棒性,比如图像平移、旋转等,减小过拟合的风险并降低运算量,同时增加感受野的大小。而解码器则是利用前面编码的抽象特征来恢复到原始图像尺寸的过程,最终得到去除干扰后的结果。
3 文字图像修复模型
3.1 数据采集及预处理
目前就深度学习来说,并没有完整公开的中文文档识别数据集或者书法作品数据集,因此如何构建训练测试数据成为文字图像修复的主要任务。本文数据集主要分为文本图像数据集和mask数据集。
3.1.1 文本图像数据集
本文所采集到的文档图像数据集中数据,均为二值化处理后的纯净文本图像。为使模拟生成数据尽可能地贴合实际场景中的文字图像,本文按照如下标准对数据集图像进行采集:所有生成图像均为白底黑字,使用宋体、楷体、黑体等若干常见字体进行数据模拟,并随机生成文字图像的大小以及文字的字号。为进一步通过上下文关联性对识别内容进行校正,采集的文本图像均为具有表意的文段,文字之间具有信息关联性,主要包含白话文、诗词和散文3种体裁。
在图像修复领域中,为提升不同种类图像的修复效果常使用标注标签的方式进行训练,如Im- ageNet数据集中含有上千个数据类别,分类标签训练的目的是使模型更好地对不同种类的缺失部分进行修复。鉴于此方法的有效性与可行性,本文将此思想应用于文字修复之上。在修复实验过程中发现,被修复文字的字体大小与修复后的效果有着密切关系,当修复区域汉字大小有较为明显的差异时,修复较大汉字字形笔画时内部会出现缺失的问题,即空心现象,如图1所示,进而致使图像修复效果不理想。

Figure 1 Hollowing out due to font differences图1 字体差异造成的空心现象
(3)
此时,Stotal为当前图像的总像素值,当Class<0.02时,则将当前图像类别归为D01,其余图像全部归为D02,不同分类标签的结果如图2所示。

Figure 2 Example of text data classification tag 图2 文本数据分类标签示例
此方法旨在缓解由于字体差异过大而导致的空心问题。
本文首先采用单字切割算法对图像中的单字进行切分。目前,单字切分算法主要有先验知识法[23]、连通域法[24]和投影法[25]3种。先验知识法是一种利用汉字字符的标准和规律的方法,其原理是对规范文本的宽度以及间距进行估算后对单字进行切分,适用于处理小批量规范型汉字,但对于批量处理不同间隔和宽度的文档图像缺乏灵活性;连通域法则是根据图像领域中的生长算法设计的,该方法可以对图像中所有的连通域进行查找和抽取,并且能对一些小的噪声进行过滤,具有较强的抗干扰能力,但此方法在批量处理数据时需耗费大量的计算资源;投影法是通过对文档图像中的有效像素点(与文字同色的像素点)进行水平和垂直方向上的叠加,利用文本行之间和单字之间有效像素值为零的特点对单字进行切分,该方法思想简单且运算量合理,对于规范的文档图像较为适用。由于汉字的结构性特点(如左右结构、左中右结构),投影法容易导致文字的部件分离,如“行”字容易切分为 “彳”和“亍”。根据先验知识可知,在文档图像中除标点符号外,字符宽度基本趋于一致且呈块状,故本文采用先验知识与投影法相结合的方法对单字进行切分,具体步骤如下所示:
步骤1输入若干文本行;
步骤2利用垂直投影法获取当前切分宽度的最大值,作为单字固定宽度;
步骤3将低于固定宽度的字符部件根据阅读顺序合并为单字图像。
3.1.2 mask数据集
本文使用的mask数据集为文献[21]中公开的mask数据集和随机生成的干扰图像,并在训练过程之中随机对当前mask图像进行拉伸、翻转和裁剪,以保证训练修复的mask图像种类足够充分。
为对比不同干扰程度修复效果之间的差异性,本文使用如式(4)所示的指标mrb将mask图像分为10个等级,干扰程度随着等级的增加而增大。
(4)
其中,mrb为mask干扰比,G为满足干扰条件的像素点数,而H和W分别代表当前mask的长与宽。
3.2 文字识别模型框架
对文本图像进行修复的难点是准确预测残缺汉字的缺失信息,复原干扰点与文字部件粘合的部分。对于场景图像的修复来说,修复时可以依据干扰图像边缘多样的彩色纹理信息,对缺失内容进行预测,而在文本图像中干扰图像边缘的纹理信息却没有那么丰富,因而预测缺失的文字部件具有一定难度。
本文网络模型建立于U-Net架构之上,分为编码部分和解码部分。输入图像Iin的大小为CIin×H×W,mask图像M的大小与Iin相同,其大小为CM×H×W,其中,C为通道数,H和W分别为图像的高和宽。将Iin和M转为列向量后的个数设为1×n,对Iin和M进行融合,如式(5)所示:
vGin={xi|xi=vIin[i]+vM[i],i=1,…,n}
(5)
其中,vIin是由Iin所转化的列向量,vM是由M所转化的列向量,且vIin∈Rn,vM∈Rn。Gin为Iin和M融合后的图像,那么vGin则为Gin所转化的列向量,此时Gin的特征通道数为CIin+CM。
根据设定的网络层数对图像Gin进行部分卷积,为使生成的图像Iout与Iin的大小相等,编码层部分负责提取Gin的特征值与信息,而解码部分则是将当前图像Inow与其对应编码层中的特征信息Tnow在通道维度上进行拼接,如式(6)所示,对文字图像的风格进行融合与逼近。由上文所述Inow和Tnow的大小相等,设Inow和Tnow转为列向量后的大小为1×m,那么根据式(6)将Inow和Tnow进行融合后得到Gnow。
vGnow=[vInow,vTnow]∈R2m
(6)
其中,vGnow、vInow和vTnow分别为Gnow、Inow和Tnow所转化的列向量,且vInow∈Rm,vTnow∈Rm。
在编码部分和解码部分分别使用ReLU和Leaky ReLU作为激活函数,除首尾2个PConv层之外,每个PConv层和激活层之间都有批量归一化BN(Batch Normalization)层[26]。卷积核内核大小分别为7,5,5,3,3,3,3,3,通道大小分别为64,128,256,512,512,512,512,512,解码器中包含8个上采样层,解码器中PConv层的输出通道数分别是512,512,512,512,256,128,64,3。
对于汉字来说长宽比和内部细节是重要特性,若图像尺寸归一化不当,会致使汉字内部结构粘合在一起,这样会加大后续识别难度。对文本图像数据集的图像计算后H∶W最小达到1∶3.76,依照图像尺寸取整原则,选取H∶W为1∶1,1∶1.5,1∶2,1∶2.5,1∶3和1∶3.5共6种情况。经4.2节实验后,依据峰值信噪比PSNR(Peak Signal to Noise Ratio)[27]数值越大表示失真越小的原则,可知当H∶W=1∶3时,能够取得最优效果,经计算后确定输入图像尺寸为512×1536,经解码器的8次特征提取后,特征图尺寸缩小为2×6。根据上文所述网络结构以及输入图像尺寸得出图3所示网络架构图,其中“I”代表文本图像,“M”代表mask图像。
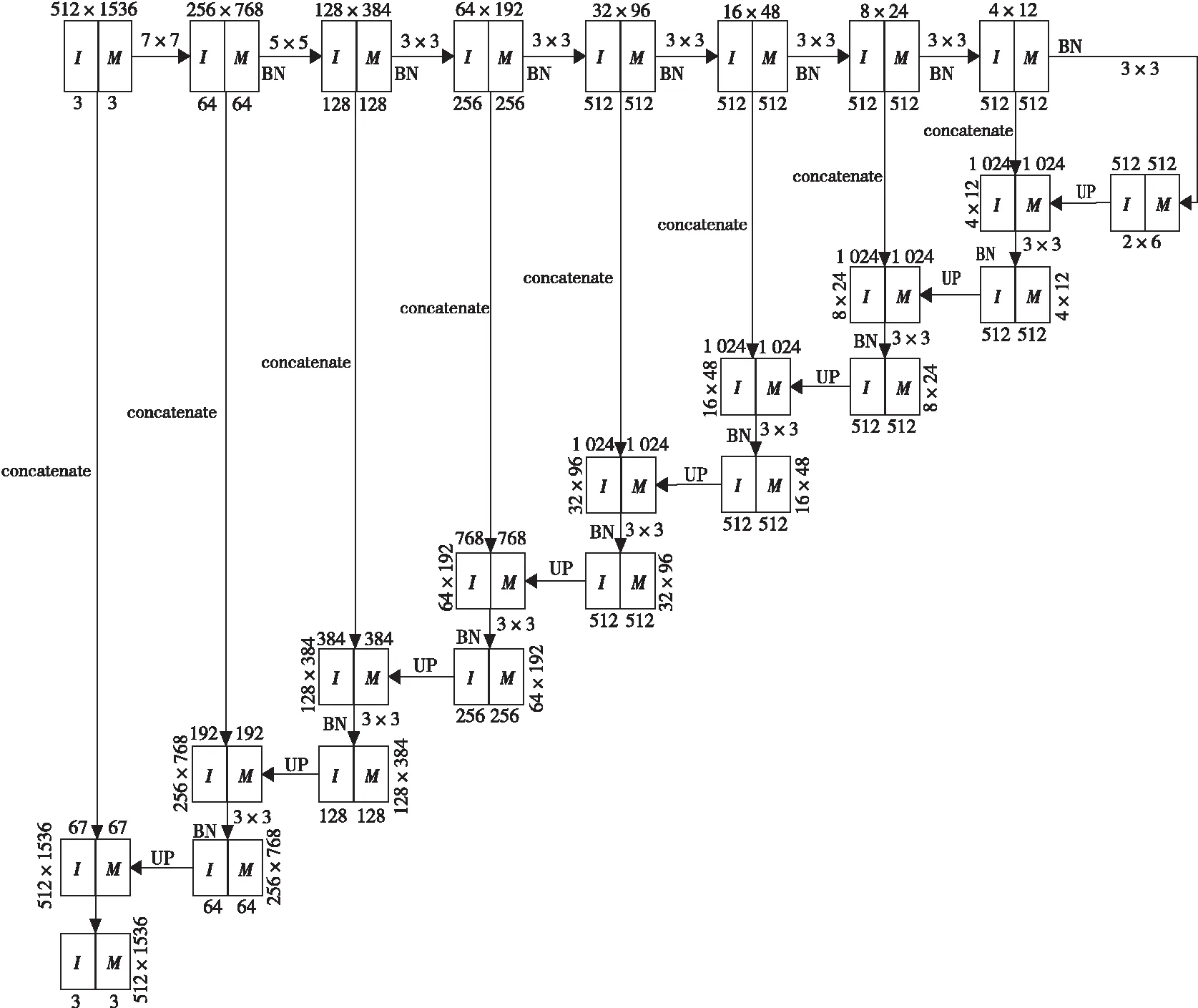
Figure 3 Network architecture diagram图3 网络架构图
3.3 评价指标
目前,尚未有针对于文档图像所设计的评价指标,考虑到文档图像的特殊性,本文采用图像质量评价指标与识别率相结合的方式对实验结果进行评估。使用PSNR[27]和结构相似性SSIM[28]对修复前后的图像进行评测,虽在后续研究中针对不同分辨率问题,多尺度结构相似性[28]的评估效果更优,但它基于人为设定的经验值,无法客观评价图像的复原效果。同时,在有不规则干扰的文字图像中,基于多尺度结构相似性评估的方法的文字识别准确率会大大降低,通过本文算法对文档图像进行修复后,识别准确率的变化可更直观地体现出算法的有效性,因此本文采用修复前后的文字识别率对算法的复原效果进行判定。
PSNR用于计算原始图像与修复图像之间的信噪比,是基于误差敏感且使用最广泛的一种客观评价指标。定义一个大小为m×n的干净图像S和噪声图像K,均方误差MSE的定义如式(7)所示:
(7)
而PSNR(dB)则通过MSE得到,如式(8)所示:
(8)
其中,MAXS为图像S可能的最大像素值。
SSIM是一种衡量原始图像与修复图像相似程度的指标,结构相似性的基本原理是,认为自然图像是高度结构化的,即相邻像素间具有很强的关联性,而这种关联性表达了场景中物体的结构性。SSIM取值为[0,1],值越大表示图像失真越小。设x和y为原始图像与修复图像,那么其亮度l(x,y)、对比度c(x,y)和结构s(x,y)之间的关系分别为:
(9)
(10)
(11)
SSIM(x,y)=[l(x,y)α·c(x,y)β·s(x,y)γ]
(12)
将参数σ,β,γ均设为1,可得:
(13)
3.4 损失函数
在计算损失值LOSS时,定义Iin为带有干扰的文字图像,M为初始的二进制mask,Iout为经过网络预测后的输出图像,Igt为期望得到的原始文字图像。
首先定义逐像素LOSS(Per-pixel Loss)为:
(14)
(15)
其中,NIgt表示图像Igt之中特征大小为C×H×W,Lhole和Lvalid分别代表有效像素区域和无效像素区域的网络输出损失。
根据文献[29],将感知LOSS定义为:
(16)

然后,计算Icomp和Iout类型损失项,如式(17)和式(18)所示:
(17)
(18)
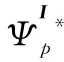
定义总体变化TV(Total Variation)损失为Ltv,如式(19)所示:
(19)
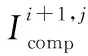
最后,将上述损失项根据文献[21]进行结合后得到Ltotal,如式(20)所示:
Ltotal=Lvalid+6Lhole+0.05Lperceptual+
120(Lstyleout+Lstylecomp)+0.1Ltv
(20)
4 实验与结果分析
4.1 mask数据集
根据式(4)所计算出的mrb值,将mask数据集分为A~J共10类,如表1所示,表中mrbmin为当前等级的mrb值下限,mrbmax为当前等级的mrb值上限,Train和Test栏分别代表当前训练集和测试集中的图像数。其中训练集共有55 219幅,测试集共有12 060幅。根据表1进行分类后,A~J各个等级示例图像如图4所示,其中白色像素点为干扰部分。
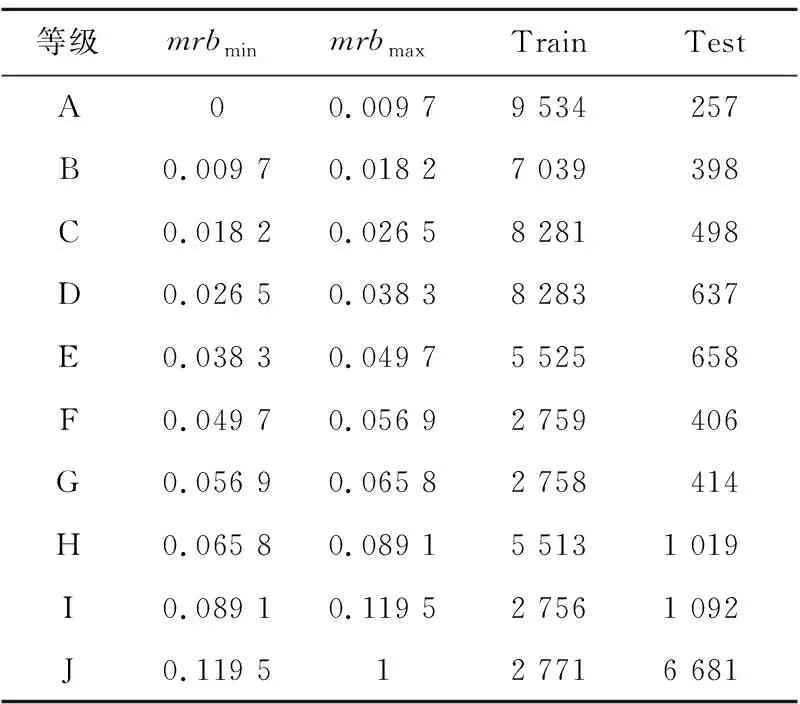
Table 1 Statistics table of different grade images表1 不同等级图像统计表
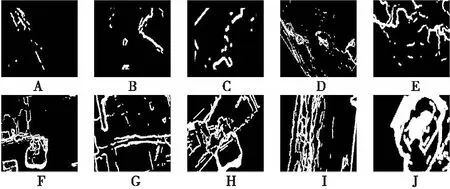
Figure 4 Example of interference level division图4 干扰等级划分示例
4.2 选取输入尺寸
本文对文本数据集图像的长宽比进行计算之后,选取1∶1,1∶1.5,1∶2,1∶2.5,1∶3和1∶3.5共6种情况,使用相同数据集进行测试得出表2,测试结果显示当H∶W=1∶3时取得较优效果,因而确定输入图像大小为512×1536。
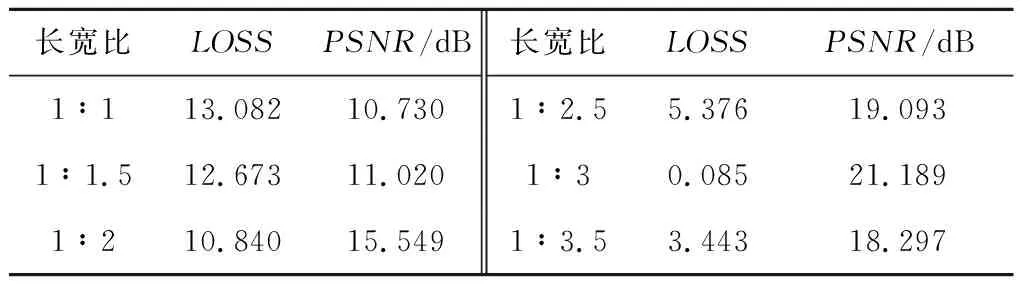
Table 2 Experimental results of different proportions of width and height表2 不同宽高比的实验结果
4.3 实验过程
首先对单幅图像进行预训练,将训练所得的权重值作为批量训练初始值,以加快训练模型的收敛速度,每轮训练2 000次,共训练10轮,此时LOSS=0.852,PSNR=21.1893 dB,预训练修复效果如图5所示。
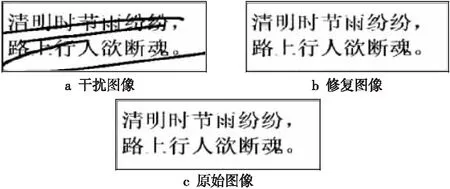
Figure 5 Prediction results of single text image 图5 单幅文字图像预测结果
在mask数据集不考虑旋转、翻转和裁剪的前提下,各个等级的干扰图像与文字图像进行融合后,产生的数据量分别为:训练集249 600幅、验证集10 160幅以及测试集16 500幅。分别将10个等级的干扰文字图像数据集各训练30轮,使用BN层进行归一化,每轮训练10 000次,共训练20轮,无BN层的情况下每轮训练5 000次,共训练10轮。最后将不同程度干扰的干扰文字图像数据集进行混合共训练55轮,其中经过BN层规一化的数据集每轮训练10 000次,共训练40轮,无BN层情况下每轮训练5 000次,共训练15轮。为实现数据集的定量实验,使用同一训练集对各个等级的干扰进行训练。由实验结果可知,本文算法在A等级时分别取得训练集、验证集和测试集的最佳效果,其中PSNR值最高达到32.46 dB,SSIM值最高达到0.954,LOSS值最低达到0.015。随着干扰程度的加深,PSNR值和SSIM值呈下降趋势,在LOSS值的约束下模型达到较好的收敛效果。对于污染程度达到F~J的干扰图像来说,对残损文字图像并没有因为分类训练而达到理想的修复效果,且评价指标低于混合掩码的评价指标。结合图6的各个等级修复效果图,通过主观视觉可得知本文算法可对字体的内部细节做出预测,且修复边缘平滑自然。由于汉字图像的特殊性,修复前后图像在亮度、对比度和结构上没有明显差异,因而不同等级之间的SSIM值对于文字图像的区分度较小。选取各个等级训练中训练集、验证集和测试集上的最优评价结果,统计后可得表3。前15轮各个等级图像在训练集、验证集上的LOSS和PSNR的变化情况如图7所示。
各个等级图像去干扰效果如图6所示,其中每类图像从上到下的排列顺序为加扰图像、修复图像和原始图像。由实验结果可知,本文模型能够根据已有笔画细节对缺失部分进行预测,并保持缺失汉字的字体形状和笔画走向,对于完全遮挡的汉字(如:J类),在人工也无法辨明的情况下,本文模型在尽可能去除干扰的前提下同样也进行了预测。
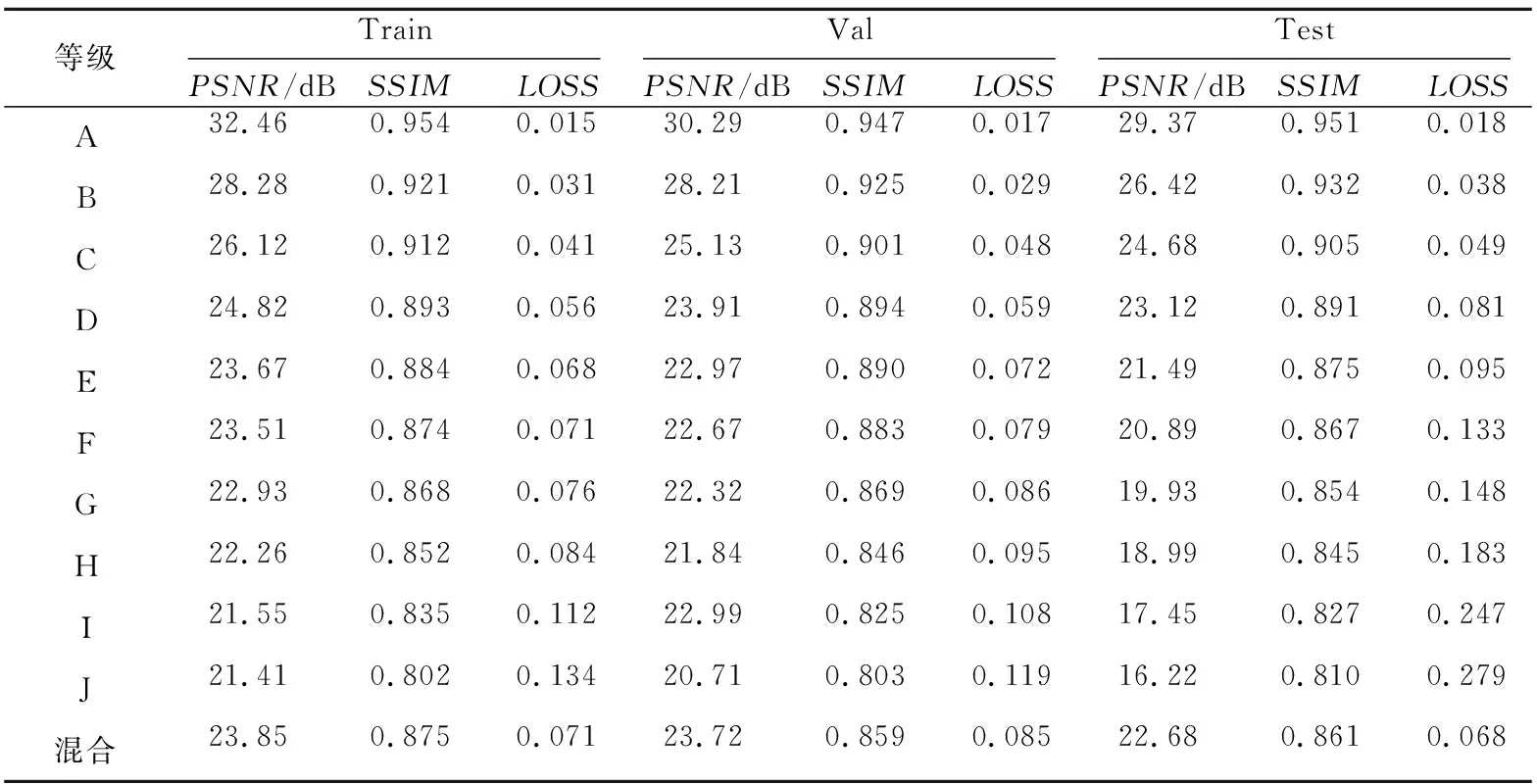
Table 3 Comparison of experimental results at different levels表3 不同等级实验结果对比

Figure 6 Decontamination effect diagram of each level image 图6 各等级图像去干扰效果图
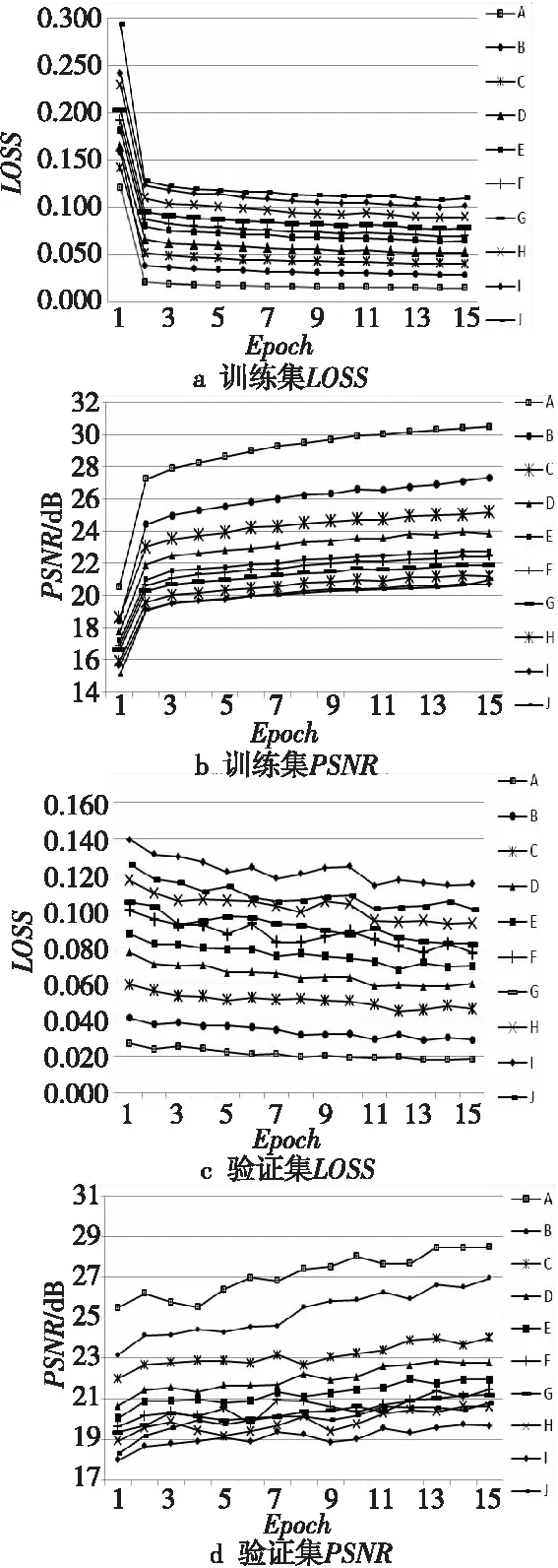
Figure 7 Changes of LOSS and PSNR for the first 15 Epochs图7 前15轮LOSS和PSNR变化图
对于文字来说,内部细节微小的误差会导致误识字和拒识字,为验证本文模型对于残缺汉字内部细节的修复是否有效,本节通过修复前后识别率的变化对修复效果进行评估。随机选取测试结果不同干扰等级各100幅,共计1 000幅图像,将加扰图像和对应的修复图像放入百度OCR接口,进一步计算识别准确率的变化情况,为便于展示本文仅给出前120次识别结果,如图8所示,在此处识别率定义为识别正确字符数与总字符数的比值。由实验结果可知,百度OCR对于有干扰的图像的平均识别率约为62.29%,而本文模型对图像修复后识别率约为90.14%,相较于未修复图像识别率提升了约27.85%。该实验表明,通过本文模型所修复出的文字部件对于提升汉字识别率是有效的。
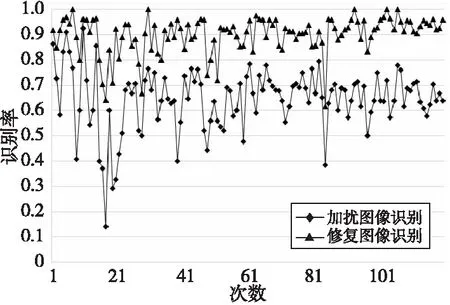
Figure 8 Baidu OCR recognition rate changes before and after interference removal图8 去干扰前后百度OCR识别率变化图
结合上述实验结果观察可知,模拟汉字图像通过前期实验达到了较好的修复效果。本文算法除了可以修复日常生活中被污染的印刷体文档外,还可应用于古籍碑刻以及书法拓片的修复,该项任务的探究在文字修复领域具有一定的研究意义。以下工作是本文对古代文字图像修复的探索。受各种因素的影响,国内对于这类珍贵文字图像的研究鲜为人知,针对它的数据库更是寥寥无几。本文联合云南师范大学汉语言文学专业人员分别梳理出隶书、篆书、甲骨文、行书4种书法字帖图像,构成实验数据集。此次实验旨在模拟缺少真实古代文字数据集的情况下,尽可能还原现实环境中古代文字的磨损情况以及修复过程和实验结果。上述实验和结果已表明该模型对于简体汉字图像的有效性,接下来将此模型进一步应用于古代文字图像的修复之中,将4种书法字体的古代文字图像数据集采用相同的干扰掩码数据集进行融合,充分模拟真实环境下的磨损和风化情况。为增强模型对多风格文字和干扰的修复能力,每类字体的干扰文字图像数据量分别为:训练集10 000幅,验证集4 000幅,测试集6 000幅。训练方法与上述实验保持一致,对各个等级mask图像和混合等级mask图像进行训练。实验结果表明,本文模型在修复甲骨文时取得了最优效果,PSNR值为30.15 dB,且SSIM值为0.964,分析后可知,甲骨文相较于其他古代文字来说年代久远、种类较少、字与字之间间隔较大,本文模型对于等级较低的污染具有较好的修复效果。表4给出了各等级最优结果。

Figure 9 Inpainting effects on different fonts图9 对不同字体的修复效果
古代文字修复效果如图9所示,其中每类从上到下排列顺序为加扰图像、修复图像和原始图像。由实验结果可知,对于不同种类的古代文字,本文模型可以根据不同种类的字体类型做出预测,对缺失字体进行修复,结合主观视觉观察可知,修复的文字部件与当前字体风格一致。
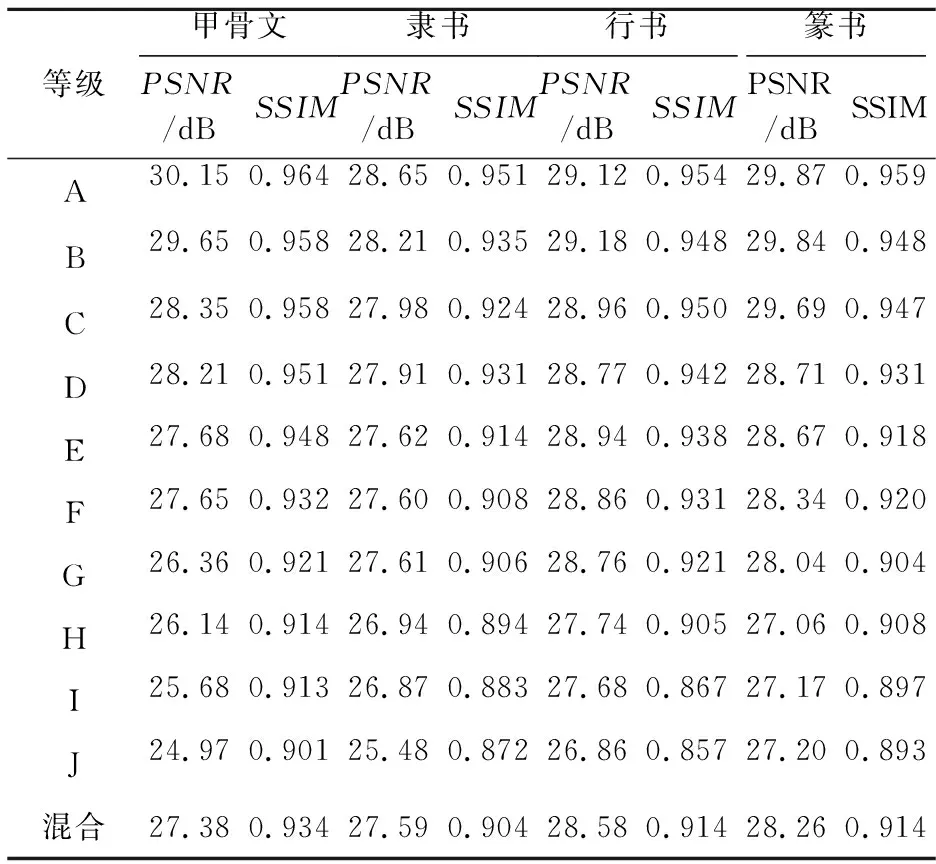
Table 4 Statistical results of objective evaluation indicators of archaic writing表4 古代文字客观评价指标的统计结果
5 结束语
本文基于U-Net框架和PConv运算建立文字图像修复模型,旨在解决由于各种不规则干扰而造成字符破损,导致识别准确率下降的问题,同时使用古代文字字体进行训练并达到了良好的效果,为修复书法、碑刻等文字作品的残缺笔画提供了可行方案。本文根据测试图像的字体、形状和笔画走向对文字缺失部分进行预测,PSNR最高达到32.46 dB,SSIM最高为0.954,LOSS最佳达到0.015。为研究对不同等级图像的修复效果,本文将mask 分为A~J 10个等级,使用同等的训练环境对实验数据进行训练,测试结果表明,各个等级之间的差值随着等级的升高而逐渐变小,对于E、F、G、H、I、J等级来说,使用混合mask训练效果更佳。将各个等级的干扰图像和对应的修复图像的测试结果放入百度OCR进行测试后,修复图像的识别率提升了27.85%。最后使用隶书、篆书、甲骨文和行书4种古代文字字体,使用本文模型进行训练后,PSNR达到30.46 dB,SSIM最高为0.964,实验表明该模型可针对不同古代汉字字体风格的残缺情况,对破损图像进行修复并取得良好效果。
