基于混合深度学习的蔗糖原料蔗顶芽杂质探测技术*
2021-09-22陈峰练张扬虎李陶深
陈峰练,白 琳,2**,张扬虎,张 茜,李陶深,2
(1.广西大学计算机与电子信息学院,广西南宁 530004;2.广西高校并行与分布式计算技术重点实验室,广西南宁 530004;3.广西医科大学第一附属医院,广西南宁 530021)
0 引言
甘蔗作为我国重要的经济作物,是制糖企业用于制糖的主要原料,甘蔗的质量决定着制糖企业的制糖量。甘蔗顶芽杂质存在于甘蔗的尾部,长度较长,呈黄色、淡黄色或黄绿色,糖分含量少,对于制糖企业而言是一段废渣,没有经济价值。以往蔗糖原料蔗顶芽杂质的识别工作是由有相关经验的工作人员以肉眼判定完成。但制糖厂收购的原料蔗总量巨大,采用人力进行识别判断存在着效率低下、识别环节主观性大、企业用工成本高等缺点。
深度学习自诞生以来不断发展,从图像分类[1]问题开始取得多次突破,在分类识别领域中已超越人工识别,在识别精确度和识别速度上取得了一次次的新高。目前有很多学者将深度学习用于农业,例如张帅[2]研究了深度学习对叶片的识别;王前程[3]将深度学习用于水果的识别;黄小杭等[4]完成了莲蓬快速识别的研究;谭龙田[5]使用深度卷积网络对玉米籽粒的完整性进行识别。石昌友[6]使用数据增强技术对图像进行多角度旋转,扩大紫皮甘蔗图像数据集,并且基于模型输出的边缘概率的卷积[7]神经网络,训练出用于紫皮甘蔗图像边缘检测的识别模型,并对紫皮甘蔗茎节进行识别,模型最终达到94%的精确度,为紫皮甘蔗蔗种自动化切割机器的识别定位模块提供切实可行的模型和理论基础;李尚平等[8]基于改进的YOLOv3[9]模型对输入识别模块的整根紫皮甘蔗的图像进行识别,并提取出紫皮甘蔗茎节的特征,识别、标记出整根紫皮甘蔗上不同茎节位置,再将各个茎节的坐标传递到多刀数控切割台对紫皮甘蔗茎节进行实时切割,其识别的准确率为96.89%,召回率为90.64%,平均识别时间为28.7 ms,达到实时且连续识别紫皮甘蔗茎节的效果,为紫皮甘蔗预切种式智能横向切种机的开发提供模型与数据基础。尽管智能化农业技术的研究不断深入,但甘蔗杂质的智能探测技术的研究仍不充分。本研究将农业生产实践与深度学习结合,基于混合深度学习模型在复杂生产环境条件下对于大规模不同光照下、不规则方向的蔗糖原料蔗顶芽杂质进行识别,这对原料蔗杂化程度判定、提高企业效益和促进农业机械化生产有重要意义。
1 材料与方法
1.1 原料蔗顶芽杂质特征提取模型结构
1.1.1 混合深度学习模型
基于混合深度学习模型的原理,在第一部分使用基于Faster R-CNN[10]的原料蔗顶芽杂质特征提取网络(以下简称模型Ⅰ)和基于Cascade R-CNN[11]的原料蔗顶芽杂质特征提取网络(以下简称模型Ⅱ),第二部分借鉴使用Cascade R-CNN的级联预测部分。混合模型结构如图1所示,识别过程如下:首先B0、B1、B2、B3为预测框输出部分,C0、C1、C2、C3为类别判断;模型Ⅰ和模型Ⅱ分别给出对应的预测框和预测框所对应的特征图;接着在BBox Feature处保留两个模型所输出的特征图,而后将特征图输入Cascade预测部分,对特征图进行多重回归修正与分类;Cascade输出层最终对类别输出C1、C2、C3求平均值,获得类别输出的置信度。最终,Cascade输出层的B3输出原料蔗顶芽杂质的预测框。
在RoIAlign[12]中,RoIAlign的反向传播公式如式(1)所示,xi代表池化前特征图上的像素点,yrj代表池化后的第r个候选区域的第j个点,i*(r,j)是一个浮点数的坐标位置,即前向传播时计算出来的采样点,在池化前的顶芽杂质特征图中,每一个与i*(r,j)横纵坐标均小于1的点都应该接受与此对应的点yrj回传的梯度。d(,)表示两点之间的距离,Δh和Δw表示i与i*(r,j)横纵坐标的差值,这里作为双线性内插的系数乘在原始的梯度上。
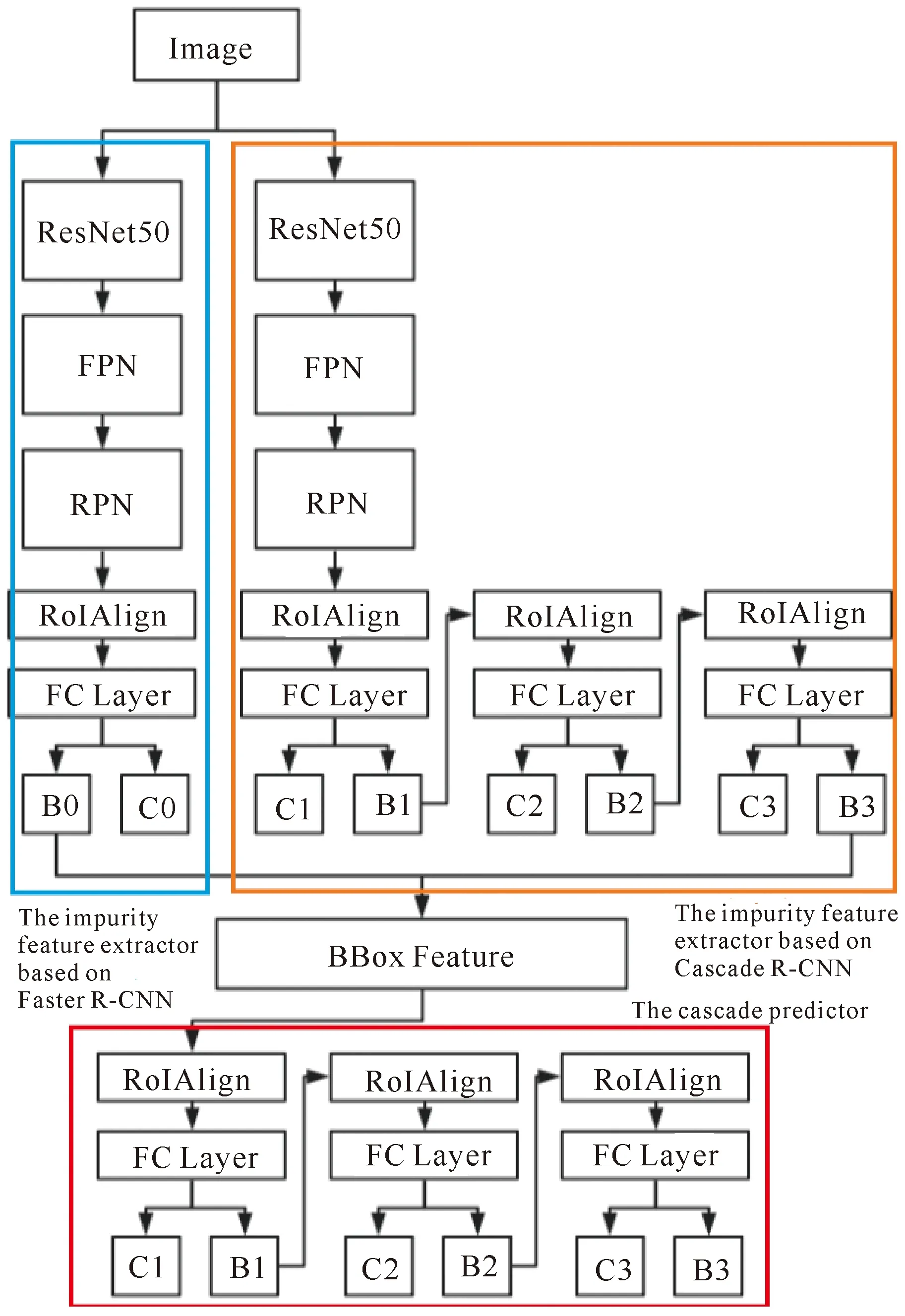
图1 混合深度学习模型架构
(1)
1.1.2 基于Faster R-CNN的原料蔗顶芽杂质特征提取模型(模型Ⅰ)
为了提升模型的识别准确性,本研究选择使用特征金字塔网络(Feature Pyramid Network,FPN)[13]和RoIAlign。一方面,卷积神经网络提取的低层特征蕴含的语义信息比较少,但目标位置准确,而高层特征蕴含的语义信息比较丰富,但目标位置比较粗略。FPN可以将图像目标的低层特征图和高层特征图的语义信息相融合,在得到目标图像丰富的语义信息的同时,也保留更多的位置信息,这使得图像中的小目标识别的精度得到有效提升。另一方面,因为RoIAlign不使用量化操作,使用双线性内插的方法获得坐标为浮点数的像素点上的图像数值,从而将整个特征聚集过程转化为一个连续的操作。
本研究的检测目标——原料蔗顶芽杂质,属于输入图像中的小目标。FPN和RoIAlign可以很好地解决原料蔗顶芽杂质这一图像小目标在定位与识别任务出现的两个主要问题:第一,在原料蔗顶芽杂质特征提取阶段,图像经过多级特征抽取之后,识别目标的图像像素在特征图上发生偏移,产生偏移的像素会对识别结果造成较大影响;第二,在选择检测目标候选区域过程中,经过特征提取工作的图像被缩放、量化后,检测目标候选区域会出现明显的偏差,而这个偏差映射到原图后会更加明显,直接影响识别的准确率。因此,本研究将FPN和RoIAlign整合到Faster R-CNN的架构中,完成模型Ⅰ的设计。

图2 基于Faster R-CNN的原料蔗顶芽杂质特征提取模型(模型Ⅰ)结构
1.1.3 基于Cascade R-CNN的原料蔗顶芽杂质特征提取模型(模型Ⅱ)
在训练和推理阶段,Cascade R-CNN的级联结构能够对图像目标预测框进行多重的预测框回归修正,循序渐进地提高预测框的交并比(Intersection over Unio,IoU),解决IoU阈值设定的问题,使得图像目标检测识别模型的性能得到提高。
通过分析原料蔗顶芽杂质图像的长宽比例特点,发现原料蔗顶芽杂质呈现细长形状的居多,在原料蔗顶芽杂质识别任务的数据中,出现较多宽高比例较大和宽或高像素较低的原料蔗顶芽杂质图像,这些因素导致原料蔗顶芽杂质检测模型产生的检测目标预测框略微偏移,从而进一步造成IoU值极大降低,即容易出现IoU阈值设置偏高的问题。IoU阈值设置过低,会引起模型预测结果欠拟合,而IoU阈值设置过高,会造成过拟合。本研究采用Cascade R-CNN来解决这一问题。此外,将1.1.2节中提及的FPN和RoIAlign也整合到模型Ⅱ中。
图3是模型Ⅱ的结构,输入图片经过ResNet50和FPN的特征提取后得到输入图像的特征图,RPN在这些特征图上生成原料蔗顶芽杂质候选区域,RoIAlign使用无像素偏移的方式对不规则候选区域的特征进行池化操作,使得不同候选区域的特征尺度大小统一,两层全连接网络对特征进行初步的处理,接着输出分支C1对候选区域进行分类及置信度输出,而输出分支B1产生的候选框作为下一级联结构(S2级联结构)的输入,进入FPN得到多尺度特征图,并经过RoIAlign、两个全连接网络后,又得到两个输出分支C2和B2。至此,B1输出候选框得到第一次回归修正,产生B2输出候选框,此候选区域更接近真实原料蔗顶芽杂质边界框(Bounding Box,Bbox)。最后,B2输出候选框继续作为最后一级联结构(S3级联结构)的输入,经过与上一级联结构同样的处理步骤后,得到输出分支C3的分类和置信度输出,输出分支B3的原料蔗顶芽杂质候选框。最后汇总C1、C2、C3的结果平均值为最终的分类准确度,从B1、B2、B3中分别得到不同IoU值的原料蔗顶芽杂质预测框。
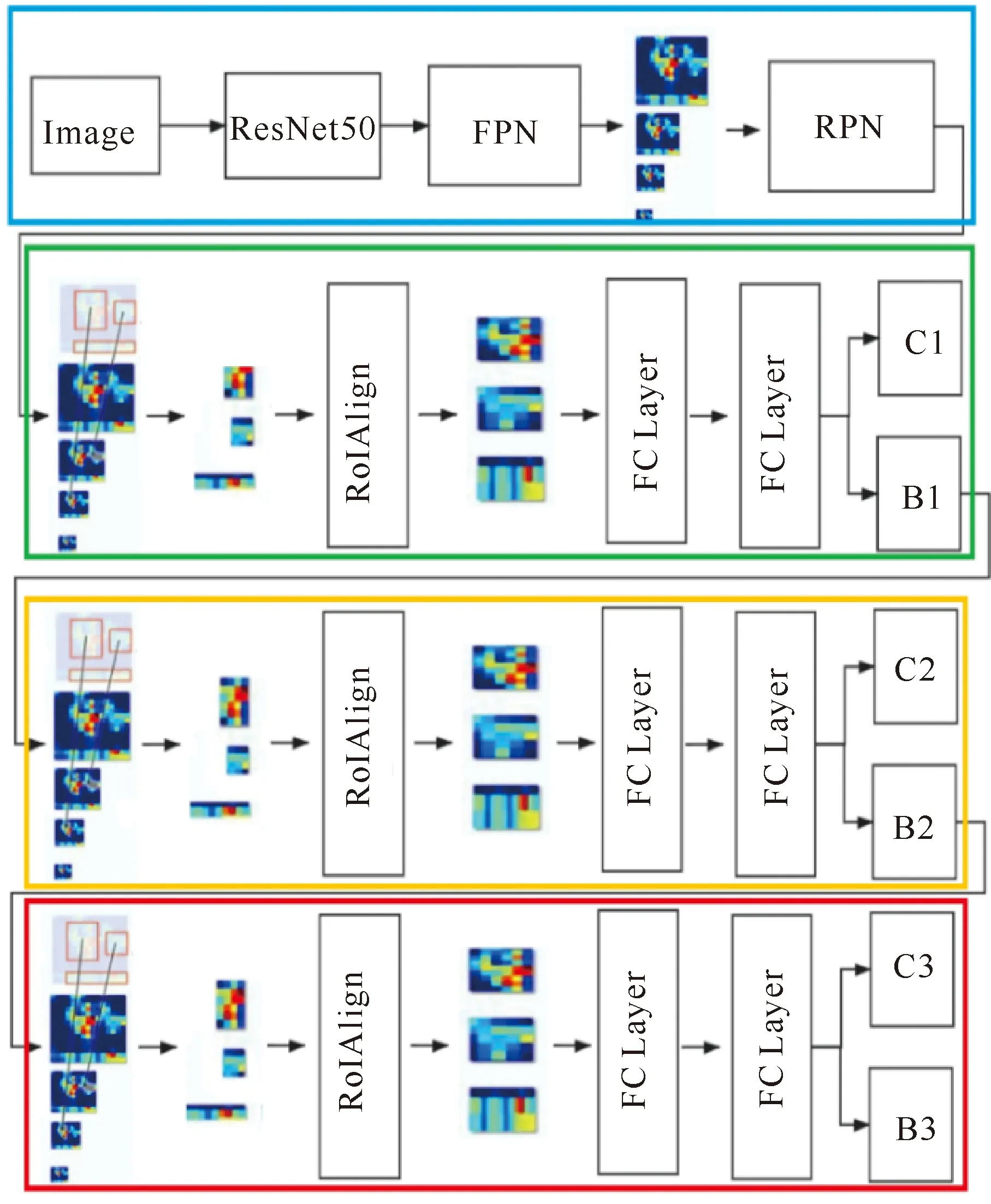
图3 基于Cascade R-CNN的原料蔗顶芽杂质特征提取模型(模型Ⅱ)结构
1.2 数据来源及处理
本研究的实验数据均来自广西南宁某糖厂制糖生产流程中的实地拍摄。在实验开始前,先对实验数据——蔗糖原料蔗顶芽杂质进行简单分析。原料蔗顶芽杂质存在于原料蔗的末端,一般呈现几种不同的单一颜色或者混杂颜色态,这几种色态的部位含糖量极少,属于制糖厂无益制糖生产的一部分。甘蔗生长初期末端部分呈现较深的青绿色,甘蔗尾部直至被切割部分呈现的都是青绿色,且甘蔗与背景图像有明显的边缘分界线,这十分有利于将甘蔗与背景区分出来。甘蔗经过一段时间的生长之后会产生一点青绿色、黄绿色,并在甘蔗尾部的表皮上混杂到一起,且甘蔗边缘与背景区分十分明显。甘蔗再经过一段时间的生长之后,会出现末端表皮上呈现黄绿色与淡紫色相互交杂的情况,也会呈现淡紫色与青绿色混杂的情况,但从整体上看甘蔗依旧呈现出青绿色。甘蔗继续经过一段时间的生长,浅紫色与浅黄色出现混杂现象,甘蔗的末端大部分为浅紫色,但是依旧留存有淡黄色。因此,对原料蔗顶芽杂质作出以下定义:原料蔗顶芽杂质存在于原料蔗的末端上,有明显的颜色特征,其颜色特征呈现为青绿色、黄绿色、淡紫色与青绿色混杂、紫色与黄绿色混杂以及淡紫色与浅黄色混杂(图4)。

图4 蔗糖原料蔗顶芽杂质
1.3 实验设置
将实验数据——原料蔗顶芽杂质图像分成原料蔗垂直(大部分原料蔗以垂直朝向在图像中出现)、水平(大部分原料蔗以水平朝向在图像中出现)和整体数据(包含水平和垂直型数据)3种类型。在此实验数据上对模型Ⅰ、模型Ⅱ、Faster R-CNN和混合深度学习模型这4个模型进行对比试验,探究本研究提出的混合深度学习模型的性能。
少先队员是一种儿童的群众性组织,十九大的胜利召开,对培养少先队员提出了新的要求和目标。在培养少先队员的过程中,要进行组织教育和实践活动相结合的方式。引导广大少先队员听党的话,跟着党走,让他们从小学习怎样做人,树立正确的世界观和价值观,形成良好的行为习惯和学习习惯,有自己的目标,从小立志,做一个正直的人,不断努力提高自身思想道德修养和文化水平,为实现中华民族的伟大复兴而奋斗。
为了更系统地评估本研究提出的模型,实验将统计两项指标数据:平均精度(Average Precision,AP)和马修斯相关系数(MCC)[16]。AP值是对n个样本的数据集,对每个样本的真实标签和预测概率进行计算;马修斯相关系数是应用在机器学习中,用来测量二分类的分类效果的指标,计算公式分别为公式(2)、(3)。
(2)
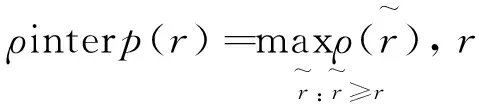
MCC=
(3)
其中,TP (True Positives)表示真正例,表示被标注的原料蔗顶芽杂质被正确的检测出来;TN (True Negatives)表示真负例,为正确地识别出的非原料蔗顶芽杂质候选框;FP (False Positives)表示假正例,即被标注的顶芽杂质未被正确地检测出来;FN(False Negatives)表示假负例,是没有被检测识别出来的非原料蔗顶芽杂质。
2 结果与分析
2.1 整体数据的预测结果
由图5可以看出,对于整体数据,模型Ⅰ和模型Ⅱ的AP与MCC分别至少比Faster R-CNN高0.35和0.4,说明FPN和RoIAlign可有效定位和识别图像中的原料蔗顶芽杂质。
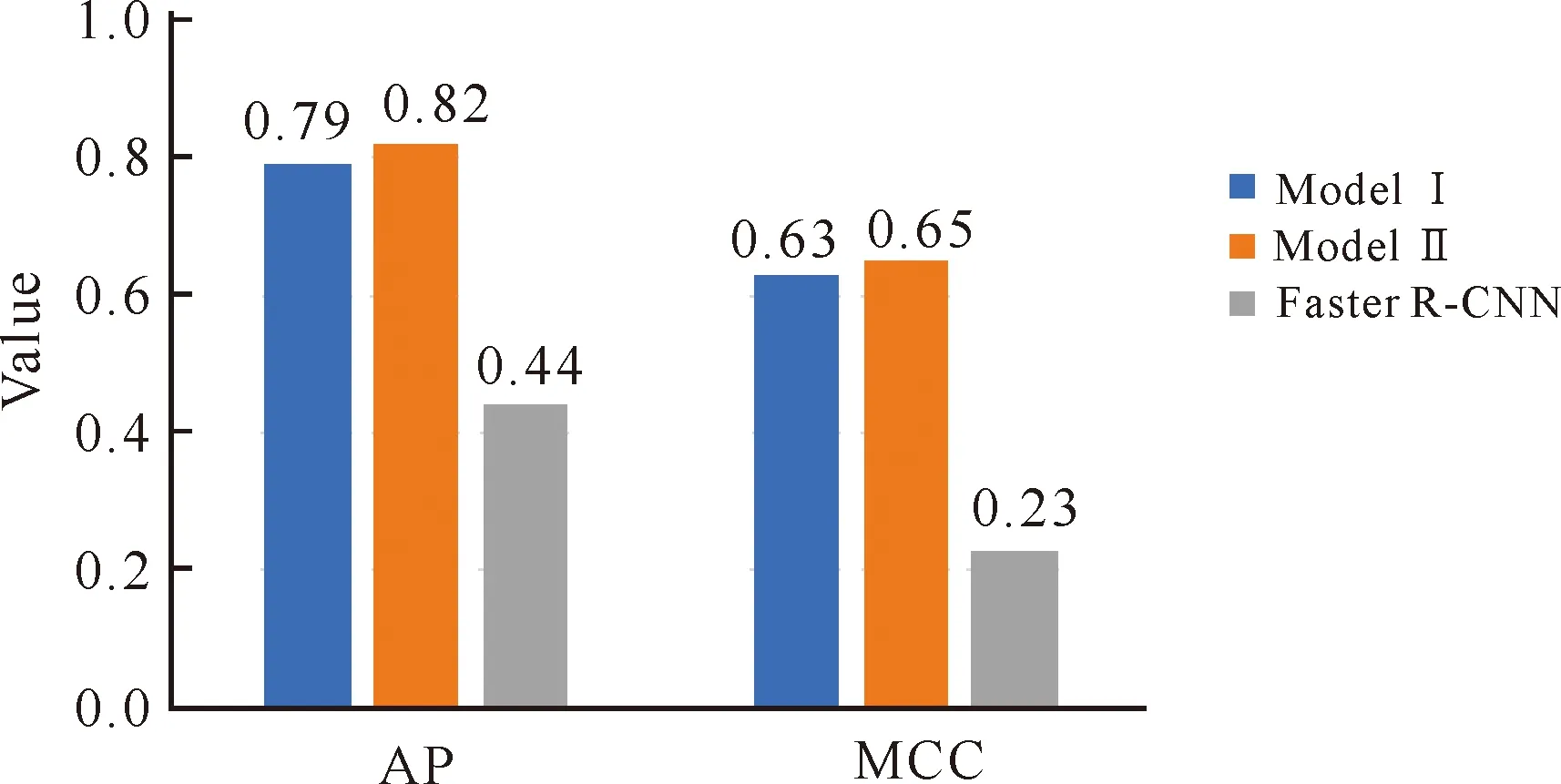
图5 对于整体数据,模型Ⅰ、模型Ⅱ和Faster R-CNN的AP与MCC
2.2 垂直和水平型数据的预测结果
对于垂直型数据,模型Ⅰ比模型Ⅱ得到的AP和MCC略高,分别高出0.05和0.06(图6a);对于水平型数据,模型Ⅱ的表现优于改进模型Ⅰ(图6b)。也就是说,在两种不同类型的数据下,两个原料蔗顶芽杂质特征提取模型的表现各有不同,两个模型有各自的适用场景和优势。
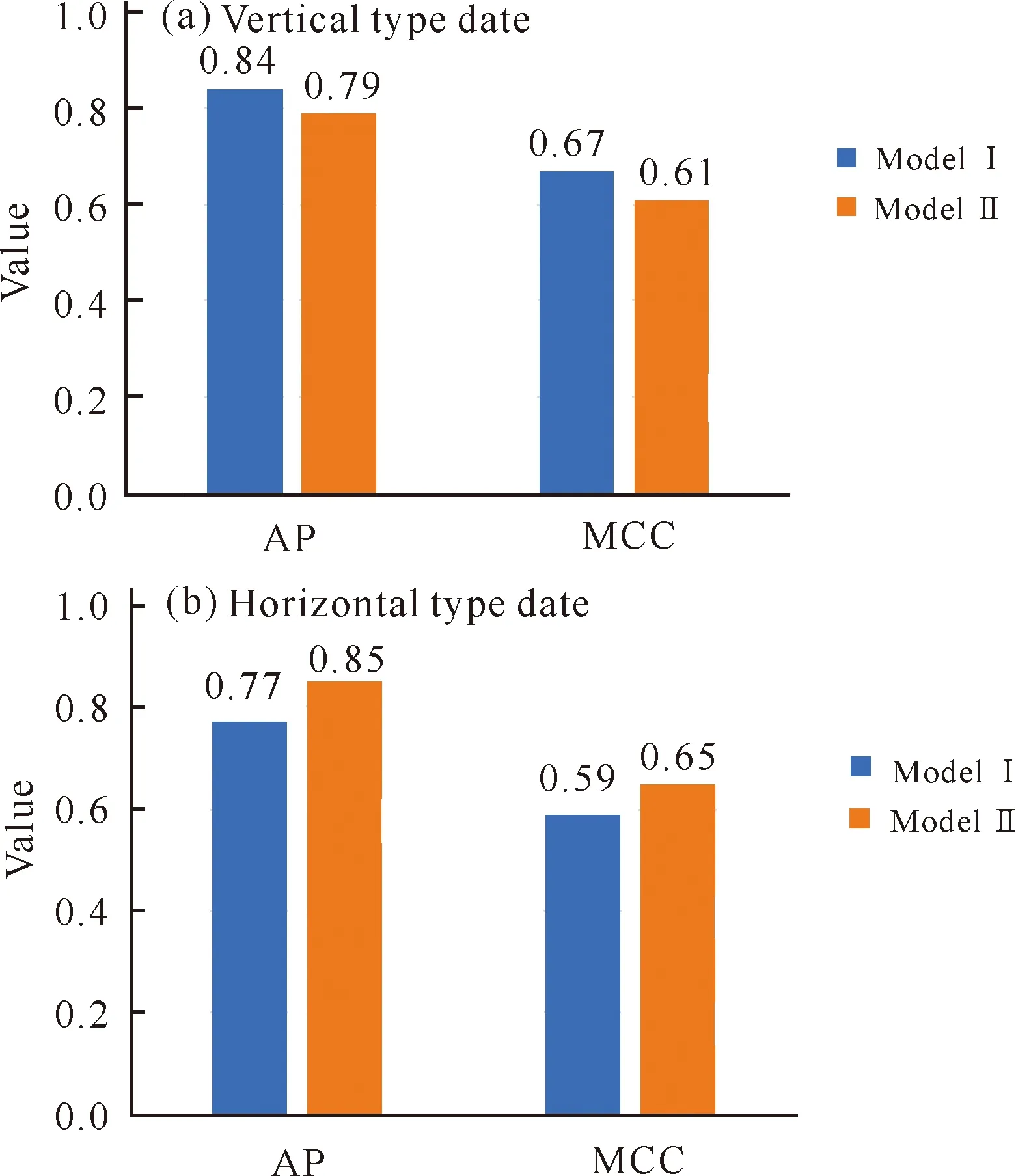
图6 对于垂直型和水平型数据,模型Ⅰ和模型Ⅱ的AP与MCC
2.3 混合深度学习模型对整体数据预测结果
由图7可以看出,混合深度学习模型的表现优于模型Ⅰ和模型Ⅱ。因为模型Ⅰ和模型Ⅱ在不同类型数据下的表现不同,这两个模型有各自的适用场景,所以在整体数据下,两个模型的表现并不一样。

图7 对于整体数据,模型Ⅰ、模型Ⅱ和混合深度学习模型的AP和MCC
从对4个模型的探测识别性能分析中可以看出,本研究提出的混合深度学习模型在整体数据下的表现优于两个特征提取模型,说明此混合深度学习模型融合两个特征提取模型各自的优势,使模型对整体数据的预测准确率得到提高,对不同形状原料蔗顶芽杂质均具有适用性,可以拓展应用场景。
3 讨论
制糖厂使用小型货车一次性运输大批量的原料蔗,当原料蔗运输到制糖厂进行卸载时,原料蔗处于高密集堆积状态下,几百根长度、大小不同的原料蔗朝向不一,相互堆叠,并且原料蔗还会携带着蔗叶、泥土等混杂物,在堆叠原料蔗所形成的空间上形成遮挡、掩盖。这些综合的因素造成原料蔗图像空间背景的复杂性,因此原料蔗顶芽杂质识别模型需要有很强空间鲁棒性,能对不同方向、角度的同一原料蔗进行精准的顶芽杂质识别。
原料蔗抵达制糖厂的时间各有不同,在早晨、中午、傍晚等时间到达的原料蔗,其光照条件有所不同,比如过亮、过暗等,进而导致输入设备拍摄到的原料蔗图片呈现的效果不同,获取到的图片像素值也不同。如果模型对光照的鲁棒性不好,对于不同光照情况下的原料蔗顶芽杂质特征就会出现误识别或者漏识别的情况,因此原料蔗顶芽杂质识别模型需要对不同光照条件下的同一原料蔗进行顶芽杂质的识别。
因此,构建原料蔗顶芽杂质识别模型的困难点在于识别模型需要有极强的空间鲁棒性和光照环境适应性,能在复杂图像空间与外界环境下对不同方向、角度与不同色调、饱和度、亮度的同一原料蔗的顶芽杂质做出准确的识别。
本研究首先对蔗糖原料蔗顶芽杂质图像进行筛选、切分、标注、图像数据增强等工作,将其作为实验的数据集。对原料蔗顶芽杂质图像进行初步研究后发现,实验数据引起的像素偏移问题对顶芽杂质识别影响较大,提出使用FPN多尺度特征融合、RoIAlign池化,将其整合进Faster R-CNN网络中。其次,本研究针对原料蔗顶芽杂质标注框的几何特性所导致的预测框与真实框的IoU不高的问题,提出使用级联回归修正[16]预测框以提升IoU值。最后,基于混合深度模型的设计理念,本研究尝试结合基于Faster R-CNN的原料蔗顶芽杂质特征提取和基于Cascade R-CNN的原料蔗顶芽杂质特征提取两种模型,构建一个混合深度学习模型,融入两个模型的优点,以提升模型的性能。
本研究最终得到有标注的数据集达到1 600张,并且使用Labelme对图像进行标注,得到原料蔗顶芽杂质的标注实例11 200个。由于原料蔗顶芽杂质的数据特征比较明显,其表现多为垂直型与水平型两种。因此本实验除对整体数据进行测试分析外,还对垂直型和水平型两种数据分别进行测试。
4 结论
本研究以混合模型思想和深度学习方法作为指导理念,在分析图像目标检测的国内外研究现状与发展历程的基础上,实现蔗糖原料蔗顶芽杂质的精准检测识别。
本研究详细分析了原料蔗顶芽杂质图像的特点,提出使用级联回归修正预测框,解决原料蔗顶芽杂质标注框的几何特性所导致的IoU值不高的问题,以提升IoU值。通过实验验证了这种做法的可行性,模型得到巨大的性能提升。此外,通过研究发现基于Faster R-CNN的原料蔗顶芽杂质特征提取模型对垂直型数据识别效果较好,而基于Cascade R-CNN的原料蔗顶芽杂质特征提取模型对水平型数据表现较好,两个模型都有各自的优势,借此设计并实现了基于以上两种模型而构建成的混合深度学习模型,该模型结合上述两个模型的优点,丰富了其应用场景,使其具有很强的适应性与良好地扩展性,对整体数据的识别准确率得到提升,更准确地进行原料蔗顶芽杂质识别。
