基于大数据技术的AI岗位需求分析研究*
2021-09-22徐正丽文博奚谢梅英
徐正丽,文博奚,谢梅英,蔡 翔**
(1.桂林电子科技大学,广西桂林 541004;2.广西建设职业技术学院,广西南宁 530007; 3.南京信息工程大学,江苏南京 210044)
0 引言
近年来,我国人才市场出现供需失配的结构性矛盾,尤其是在人工智能领域。准确感知并描述劳动力市场的需求是解决该问题的重要手段。人工智能(AI)技术已成为全球新一轮科技革命和产业变革的着力点,对于推动产业转型升级至关重要,越来越多的公司把AI视为竞争力的关键要素[1]。根据2017年Gartner的统计显示,到2021年,AI预计将创造230万以上相关岗位,但人才缺口却非常严重[2]。由于AI是应用领域非常广泛和快速发展的新技术[3],人力资源管理部门对AI领域的专业认知更新却比较缓慢,对AI岗位职责及所需技能的认知往往是模糊、主观和过于简化的理解[4],甚至会将“AI”与“大数据”“机器学习”“深度学习”等概念混为一谈[5]。AI岗位内容的广泛性及所需工作技能的复杂多样性[6,7]给准确把握AI岗位的需求带来很大的挑战。
为准确感知并描述劳动力市场对AI的需求,本研究采用大数据分析手段,对AI岗位簇的工作角色及所需技能进行类型学研究,为基于大数据分析AI岗位簇的角色及其所需技能需求提供了一个结构化框架,可有效提升人力资源管理部门的科学决策水平,同时促进高校提高AI人才培养的针对性。
1 算法框架
本算法主要包括4个部分:第一步,使用网络爬虫技术从招聘网站爬取AI相关岗位的招聘信息,然后实施数据清洗;第二步,利用K-means聚类与专家判断相结合的方法,分析AI的岗位簇;第三步,利用概率主题模型(Latent Dirichlet Allocation,LDA)与专家判断相结合的方法,分析AI相关领域的技能集;第四步,通过构建岗位簇与各技能集之间的需求矩阵,评估工作技能集对工作岗位簇的重要性,从而更准确地把握工作AI各岗位簇对工作技能的需求程度(图1)。

图1 算法步骤
2 数据来源及清洗
2.1 数据来源
选择智联招聘作为数据来源。相比其他招聘网站,智联招聘的招聘岗位页面HTML结构的标准化程度高,数据可获取性较好,Web抓取可行性更高[8]。在2019年3月-2019年5月期间,采用WebCollector爬虫框架对智联招聘网站在2018年全年的招聘岗位标题、岗位描述或岗位要求中包含关键词“AI”的岗位信息进行抓取,最终获得10 656条与AI相关的招聘信息。获取的招聘信息包括招聘信息ID、公司名称、招聘岗位名称、岗位要求、薪酬、工作地点、工作年限要求、学历要求、信息公布时间等内容。
从需求时间看,2018年AI岗位人才需求旺盛,呈现爆发式增长态势,尽管7月份达到最高峰(正值我国应届毕业生的毕业时间),但是下半年对AI的需求是上半年的5.29倍(图2)。从需求地域看,2018年AI专业人才需求主要集中在一线城市(北京、上海、广州、深圳)以及15个新一线城市(成都、杭州、武汉、南京、长沙、天津等)。这些经济发达城市AI产业发展迅速(图3)。从学历要求看,2018年AI领域对本科学历的需求最大,一定程度上表明了企业对AI应用开发的需求旺盛,而对AI研发人才的需求要小(图4)。

图2 2018年智联招聘发布的AI岗位招聘数

图3 2018年AI岗位工作地点分布
2.2 数据清洗
数据清洗按以下步骤进行:第一,使用网络爬虫获取的10656条招聘信息中,有小部分为同一企业在不同时间点发布的对同一岗位的招聘信息,因此需要去掉这部分重复信息。第二,一些企业在互联网上发布招聘信息并不规范,例如招聘岗位名称中填写“博士”一词。这类招聘岗位名称属于无效值,不能作为岗位名称进行分析,需要视为无效数据予以剔除。如果某个岗位的招聘岗位名称中的技能词与AI岗位无关,那么这条招聘信息也属于无效数据而予以剔除。第三,鉴于中文的书写方式与英文不同,词汇之间缺少明显间隔,需要对中文文本采取“jieba中文分词”处理,使计算机能准确地识别中英文词汇,分词之后需要对去除分词结果中的停用词和无效词(如“和”“或”“与”等),以消除停用词和无效词对数据分析的不利影响。然后,利用这些词构建岗位名称词典。岗位名称词典的构建还可以采取机器学习的方法[9],考虑到算法的成熟度,本文采用“jieba中文分词”工具。
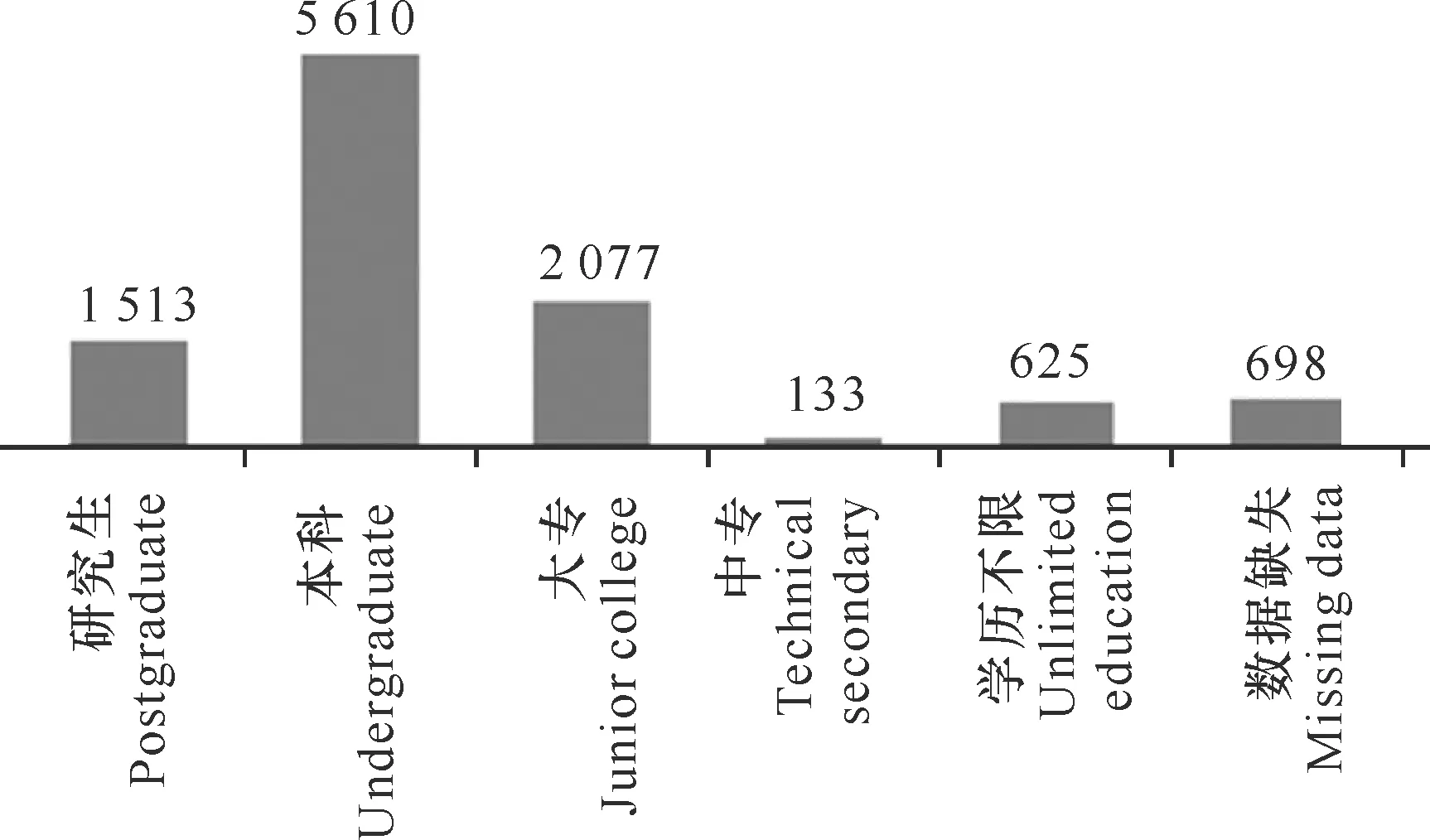
图4 2018年AI岗位的学历要求分布
在对招聘岗位名称进行分词和去停用词处理后,进一步选取在结果中出现次数超过5次的194个名词构成岗位名称词典,将招聘岗位名称中不包含岗位名称词典中词汇的招聘信息标记为无效数据予以剔除。图5展示了出现次数最多的前50个岗位名称名词的可视化词云图。每个名词的字体大小与每个名词出现的次数成正比。

图5 AI岗位名称中重复出现的前50个单词
对岗位要求进行预处理时,参考IT职业技能图谱,预先选择了与AI领域相关的232个技能词,将各个招聘岗位的岗位要求描述转化成技能词的集合。在前面处理的基础上,将岗位要求中不包含AI领域技能词的招聘信息标记为无效数据予以剔除。表1显示了岗位要求中词频最高的前50个技能词。

表1 频率前50的岗位要求技能词
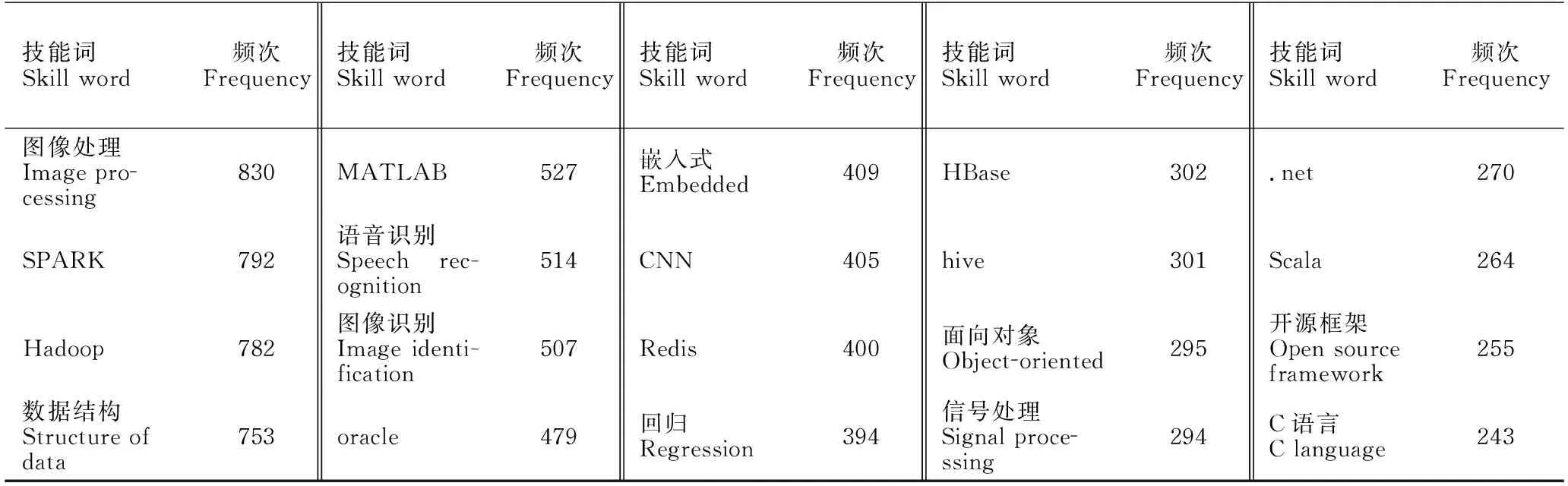
续表1
通过去重和两次清洗剔除重复数据和无效数据,最终保留6 705条数据作为有效样本数据。据此,可以对岗位名称进行K-means聚类分析获取岗位簇,并对岗位要求进行LDA分析获取技能集。
3 数据分析
3.1 岗位簇识别
目前尚未有明确的AI岗位类别划分。因此,本研究使用AI招聘岗位名称作为输入,通过K-means聚类算法将获取的岗位名称进行聚类,从而识别出AI岗位簇[10]。为实现岗位簇的提取,需要将所有的岗位名称向量化,通过词袋模型,利用数据预处理时得到的岗位名称词典,将各个岗位名称分别转化为一个194维的0-1向量(岗位名称中出现词典中的单词记为1,未出现记为0)。将岗位名称向量化之后,再使用K-means聚类算法对所有岗位名称进行聚类。
K-means聚类需事前确定聚类数量,因此本研究利用肘部法则(图6)确定聚类数量为4。然后统计各簇中词对的出现频次。表2展示了各簇中出现频次最高的15项。这里需要特别指出的是,由于某些岗位名称书写不规范,致使通过分词和去停用词后该名称只剩一个名词。通过专家分析,将4类AI岗位簇分别命名为产品架构师、算法工程师、产品经理和软件工程师。
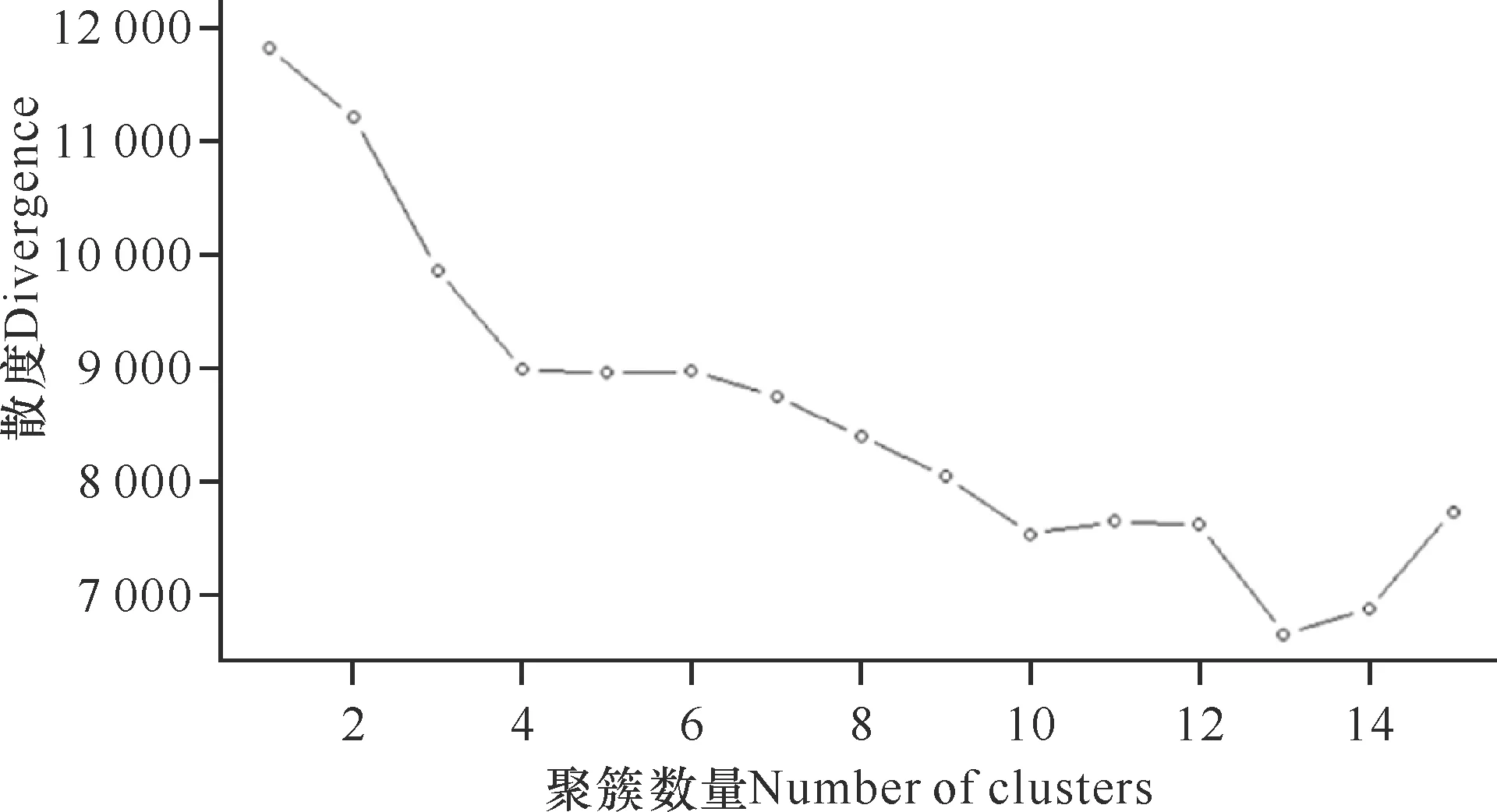
图6 K-means聚类肘部法则分析图

表2 K-means聚类分析得出的4个岗位簇

续表2
3.2 技能集识别
按照“能岗匹配”和“胜任力”理论,同一类型岗位所需的技能也应该是相似的[11]。反过来,相似的技能更有可能出现在同一份岗位说明书中。为分析岗位簇所对应的技能集,继续使用聚类分析方法对岗位簇所需的技能词进行聚类。为了识别工作岗位中的技能集,采用LDA进行聚类[12-14]。
LDA的输入是招聘信息中的招聘岗位要求和需要识别的主题数量。为得到合适的主题数量,首先计算了主题数量k分别为2-10时的多个结果,然后组织专家对这些结果进行评估,最终得出主题数量k为5最合适,因此将技能集划分为5类最合理。表3显示了通过LDA分析出来的5个技能集,以及每个技能集中出现频次最高的15个技能词。组织专家对技能词所涉及的工作内容进行综合研判,确定将这5个技能词集合分别命名为数据库、机器学习、模式识别、大数据和程序设计。

表3 基于LDA的技能集分析
3.3 需求矩阵设计
在使用LDA分析技能集时,会输出每个岗位任职要求属于每个主题(技能集)的概率。每一项岗位任职要求代表一个工作岗位,因此该结果可理解为每个岗位对于每个主题(技能集)的需求程度。
为了得到各岗位簇对每个技能集的需求情况,首先选取位于同一个岗位簇中所有岗位对每一个技能集需求程度的平均值,将其作为该岗位簇对每一个技能集的需求程度,从而得到4个岗位簇对于5个技能集的需求矩阵C。然后,将需求矩阵C的每一列除以其平均值来归一化矩阵C,得到矩阵T(表4)。由于分析的工作岗位都是AI相关,同时岗位要求分析中用到的词都是和AI相关的词汇,因此不同岗位簇对技能集的需求程度区别不大。其中,元素Ti,j表示岗位簇i对特定技能集j的需求程度。为了更清楚地描述岗位簇对各个技能集需求的重要程度,采用以下方法予以简化处理,得到表5。
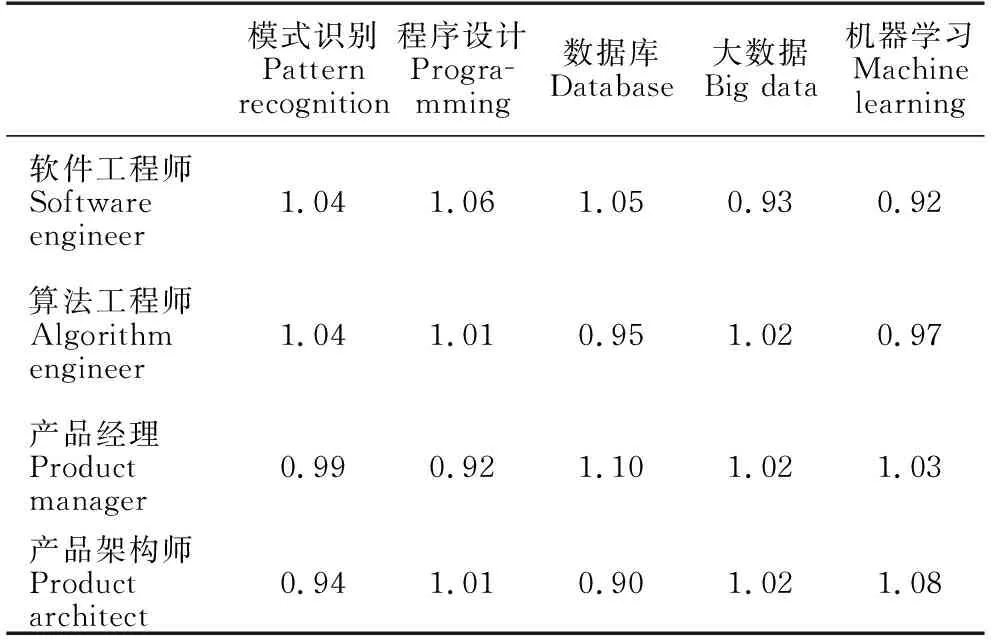
表4 AI岗位簇对所需技能集的需求矩阵(Ti,j)

表5 岗位簇对所需技能集的需求评估
—T_(i,j)≥1.00:技能集j对岗位簇i特别重要;
—T_(i,j)<1.00:技能集j对岗位簇i不是特别重要。
4 结果可视化与分析
根据上述方法,可画出岗位簇映射技能集的冲击图,如图7所示。在图7中,对每一个AI岗位簇设置了识别标签,对岗位簇与所需技能集的映射关系进行了可视化处理,更为直观地描述了岗位簇对技能集的需求程度。其中,左侧是4类岗位簇,右侧是5类技能集,中间连接线的宽度表示各岗位簇对每个技能集的需求程度或相关度。
4.1 软件工程师
软件工程师的主要角色是从事AI软件开发相关工作。具体来说,AI软件工程师主要负责AI产品软件设计与构架、编写项目的核心代码、解决在产品的研发过程中遇到的技术难点、协调项目组成员之间的合作并参与代码开发规范编制。为此,AI软件工程师既要熟练掌握程序设计,又要了解模式识别[15]。根据图7可发现,程序设计对于AI软件工程师最为重要,其次是数据库和模式识别。该岗位簇的招聘信息中也多次提到对于程序设计(精通C#或Java语言,精通面向对象分析和设计技术,有足够的.net或Java开发经验)、模式识别(熟悉深度学习、AI、机器学习、神经网络等技术在图像处理领域的应用)以及数据库(熟练掌握MySQL、Oracle等数据库,有SQL性能调优经验优先)等技能要求。
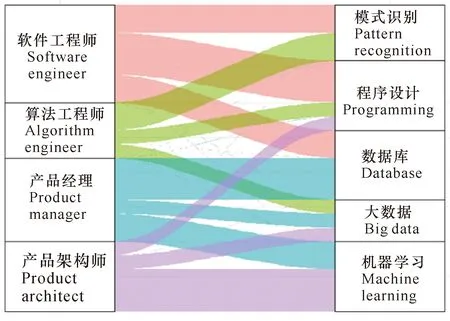
图7 岗位簇映射技能集的冲击图
4.2 算法工程师
算法工程师是AI领域的稀缺核心岗位,其主要角色是通过模式识别等算法来完成不同的逻辑运算和优化业务。算法工程师的工作职责主要包括利用模式识别相关的手段分析大数据,然后将算法用伪代码描述出来,交由软件工程师实现[16]。根据图7可发现,模式识别对算法工程师最重要,其次是程序设计和大数据。该岗位簇的招聘信息中多次提到对模式识别(有图像处理、模式识别等项目经验优先)、程序设计(熟悉UI、.net和云计算、android和C#/C++等编程语言)和大数据(熟悉数据挖掘、spark、Hadoop和分布式存储)等技能要求。
4.3 产品经理
产品经理是需要将AI技术和行业知识相结合,并通过AI产品和项目的落地,最终实现企业商业目标的复合型岗位,需对AI产品进行规划设计、提炼使用场景、推动用户交互使用体验、推进产品上线。为此,AI产品经理既要掌握AI技术,同时又要熟悉商业分析和产品开发管理,在工作中需要与产品构架师、算法工程师和软件工程师等充分沟通协作,保证产品功能落地[17]。根据图7可发现,除了行业市场知识、项目管理技能外,产品经理岗位对数据库、机器学习和大数据技术等有较强的技能需求。该岗位簇的招聘信息中多次提到对数据库(熟悉MySQL、Oracle等数据库)、机器学习(对TensorFlow、Caffe等算法有初步了解)和大数据(熟悉Hadoop底层文件系统,对大规模数据并行计算传输处理等有丰富的经验)这些领域的技能需求。
4.4 产品架构师
产品架构师是将AI落地解决问题的执行者、不同业务场景下的技术统筹人,主要着眼于AI系统的技术实现,需对产品全局掌控并能够及时洞悉局部技术瓶颈,并依据具体的AI业务场景给出解决方案。其主要职责是负责AI系统架构设计和技术架构选型,主导功能模块设计、数据结构设计、对外接口设计,针对行业客户设计场景化的解决方案,承担系统核心功能的研发工作和系统优化,负责制定AI业务规划等。为此,产品架构师必须能够熟练地与软件工程师、算法工程师以及AI产品经理沟通,充分了解AI的前沿理论与技术动态[18]。根据图7可发现,深度学习的理论与技术对产品架构师最重要,其次是大数据和程序设计能力。该岗位簇的招聘信息中多次提到对机器学习(深度学习、计算机视觉等领域工作经验,熟悉TensorFlow/Caffe框架)、大数据(丰富的Hadoop实战经验,熟悉Hadoop底层文件系统及分布式计算框架)和程序设计(熟悉.net、WCF、WPF等相关技术开发优先)等技术领域有要求。
5 结论
与发展迅猛的AI技术领域比较,AI领域的人力资源实践和研究均明显落后太多,人力资源管理实务界和学术界均迫切需要对AI岗位及所需具体技能有一个清晰的完整性理解。本研究基于WebCollector爬虫框架抓取了10 656条AI岗位的网络招聘数据,采用文本挖掘、K-means聚类分析、主题模型构建、专家判断的半自动分析模型等方法,对AI岗位的岗位簇和技能集进行了类型学分析,得出如下结论:①AI岗位可分为软件工程师、算法工程师、产品架构师和产品经理等4个岗位簇,以及数据库、机器学习、模式识别、大数据和程序设计等5个所需的技能集。②基于岗位簇对每个技能集的需求矩阵和基于冲击图的映射关系可视化结果显示,程序设计对于AI软件工程师最为重要,其次是数据库和模式识别;模式识别对算法工程师最重要,其次是程序设计和大数据;产品经理岗位对数据库、机器学习和大数据技术等有较强的技能需求;机器学习对产品架构师最重要,其次是大数据和程序设计能力。
本研究结果为精准感知劳动力市场对AI人才的需求提供了可能,对AI岗位词典编撰有一定贡献,有助于人力资源管理学术界和实务界对AI岗位及所需具体技能有一个清晰的完整性理解;从实践指导上可以帮助人力资源管理部门制定更精准的岗位管理、招聘遴选、培训开发方案,完善绩效管理等流程;高等学校也可根据本研究结果完善AI专业培养方案和课程体系建设,培养符合企业AI岗位所需专业人才,缓和AI领域的人才供需失配的问题。
由于本研究仅对智联招聘网站上的AI招聘岗位数据进行爬取,且未能考虑到欧美和日本、韩国等AI产业发展较好的其他地区和国家的情况,如何进一步高效拓展数据的爬取范围,将是下一步的工作重点。
