基于特征提取和集成学习的雷电预测能力提升
2021-09-22陈靖宇汤德佑伍光胜胡鹏
陈靖宇,汤德佑,伍光胜,胡鹏
(1.华南理工大学,广东 广州510006;2.广州市突发事件预警信息发布中心,广东 广州511430)
1 引言
雷电是一种伴随着剧烈的放电过程的强对流天气现象,一直以来都严重威胁着公共安全和人民生命财产安全[1],雷电灾害已被联合国列为“最严重的十种自然灾害之一”。伴随着电子产品的广泛应用,社会对雷电灾害的监测和预防的需求也逐渐增大[2]。
雷电最典型的例子就是雷暴云层产生的对地闪电,目前利用大气电场数据进行雷电预警的方法多以预警阈值[3-5]和预测方程的方法[6-7]为主。主要的方法是针对电场的快速抖动和闪电发生的0—1对应关系,对电场数据进行分解并从中提取预测因子,根据经验数据分析得出阈值点或建立多元回归的预测方程。这些方法准确率较高,但在针对不同地区、不同季节需要人工进行阈值、权重等参数调整。且由于雷电的生成机理复杂,具有一定的非线性特征,定量分析预测因子的过程十分繁琐且不具备泛用性,应用性较局限。
为了解决非线性问题并建立具有适应性和容错性的模型,也有人尝试采用机器学习的方法进行气象特征对事件的映射从而预警雷电:吕伟涛等[8]集成了决策树和区域识别的方法,建立了雷电临近预测系统。周明薇等[9]采用了支持向量机对NCEP资料建立了雷电潜势预警模型,应用相关系数大于0.3的特征,并与其他分类模型进行了比较。陈勇伟等[10]提取了对流参数作为神经网络的输入因子,预测了雷电活动的潜势。田浩等[11]运用BP神经网络,提取以30分钟为时间片的大气电场特征,预警未来的雷电发生事件。
目前运用在雷电预警的机器学习方法大多采用单一分类器,而使用集成学习的方法较少。基于上述分析,本文提出基于大气电场数据和闪电定位数据,通过挖掘提取有关特征和集成基分类器的方法提高预测模型的精度,为雷电预警提供可参考的新方法。
2 资 料
广东省属于热带和亚热带季风气候,处于雷电高发区,雷电发生频率位于全国第二位[12],研究广东地区的雷电预警有重要意义。本文利用来自广州市气象局的2019年和2020年广州市黄埔区的大气电场仪资料和全闪雷电监测系统提供的组网地闪资料,提取其中有显著雷电发生的数据。大气电场仪的地理分布如图1所示。
大气电场仪是通过导体在电场中产生感应来测量电场强度,当电场仪探知大气中电场发生变化时,可反演雷暴云中的电场变化,从而对雷电的发生进行预警。大气电场数据提供了探测范围内基于时间序列的大气电场强度,单位为kV/m。如图1所示,在广州市黄埔区共有5台大气电场仪同时进行观测试验,图中的5个圆为大气电场的探测范围,半径均为15 km,它们的中心是大气电场仪布置的位置。

图1 大气电场仪站点分布图
地闪资料来源于闪电定位仪获取的组网全闪资料,探测范围覆盖全广东省,它是一种自动化雷电监测设备,能够有效捕捉云层放电产生的电磁波,从而形成易于分析的地闪资料。地闪资料具有精准度高、探测范围广等特点,提供了包含闪电发生时间、雷击的经纬度位置等闪电信息。在本文中,地闪资料一方面反映当前的雷电特征,另一方面也反映未来是否有雷电事件作为标签,使得特征和标签之间的紧密型更强。
考虑到雷电云层的移动速度,统计一个以30分钟为时间片内大气电场仪接收的大气电场数据和其探测范围内的地闪数据为一个样本。本文采集了2019年的样本数量共14723条,并以7:3的比例随机划分出训练集和验证集,再采集2020年的部分样本作为测试集进行对模型的评价。
3 方 法
大气电场仪在一段时间内得到的电场时间序列包含了电场波形变化特征,本文的试验中先进行特征分析与挖掘,得到能够映射雷电发生事件的预测因子,再进行建模。本文采用集成学习的方法对雷电预警进行试验研究。集成是一种把多个学习器组合起来,捕获数据中线性和非线性关系的方法,能更有效地描述特征和雷电之间的关系,能够降低模型的方差或偏差,使得模型更加稳定,并在一定程度上降低过拟合。
3.1 特征提取
3.1.1 预测量分析
本文的试验利用闪电定位数据中的地闪资料来确定雷电过程。首先确定以30分钟为一个时间片,接着采集一个时间片内的数据特征作为预测因子,预测量则是在紧接着的下一个时间片中,以大气电场仪为中心,15 km为半径的圆内的闪电事件,预测因子和预测量的关系是特征值到事件的映射。将预测量作为模型的输入标签,发生闪电事件,预测量标签为1;不发生闪电事件,预测量标签为0。
3.1.2 预测因子分析
为了准确预测雷电的发生,国内外研究人员提出了许多基于大气电场和闪电定位数据的参数因子[10,13],本文对两种数据进行预处理提取有关特征,并根据大气电场的性质重新进行特征的分析与筛选。
大气电场仪提供的数据根据样本的设置是切分在大小为30分钟的时间片中,内容为大气电场强度值的时间序列。若将时间片内所有电场强度值作为特征输入到模型,会造成信息冗余,因此从每个时间片中提取最大值、最小值、方差、反转次数等能够反映时间序列的聚合特征。为了更有效地分析波动现象的曲线,对大气电场序列进行一阶差分处理,一阶差分是指在序列中用连续相邻的两项做差,达到近似导数的效果,从而减轻了数据间不规律的波动,使曲线更加平稳,它更多的提供包含其趋势性、窗口差异性、自相关性的复合特征。
对提取的特征进行了相关性分析,用于分析这些预测因子与作为预测量的下一时间片内闪电事件的相关性,计算预测因子X与预测量Y的协方差和标准差,运用下式计算出皮尔森相关性系数,其系数值在-1.0~1.0之间:
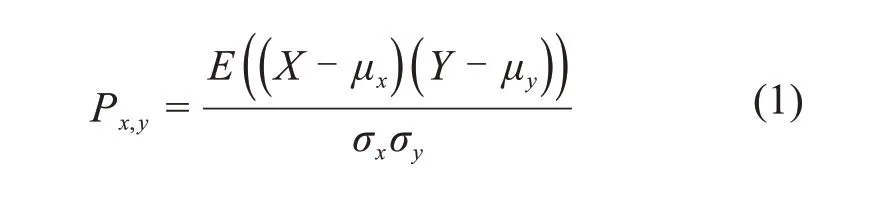
经过对每个预测因子和预测量对应的相关性计算后,结果表明电场探测量、电场全距、极性反转、电场值差分全距、电场值差分最大值、电场值差分绝对值均值、接近闪电这7个预测因子的相关性系数达到0.3以上,可认为是与闪电事件有相关性,因而选取这7个预测因子作为模型的输入特征。预测因子的分析结果见表1。

表1 预测因子及其相关性分析
3.1.3 归一化处理
预测因子的量级、单位不统一,若直接采用原始数据,可能会在模型的迭代过程中导致梯度消失或梯度爆炸,从而严重影响模型的性能。为了防止预测因子之间的量级差异过大,需要对预测因子进行归一化处理,将数据特征值映射到范围为[0,1]的区间内,使得模型能够对不同预测因子进行加权运算。归一化表达式如下:
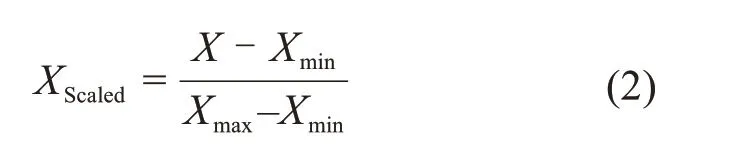
3.2 神经网络
神经网络是集成学习中的同质模型较常用的分类器,并且也是在雷电及相关领域较常用的模型之一[14-16]。本文中采用的神经网络是BP神经网络(Back Propagation Neuron Net Wok)。BP神经网络结构上与传统神经网络一样,包括输入层、隐含层和输出层,每层的神经元都与下一层的神经元完全相连(图2)。
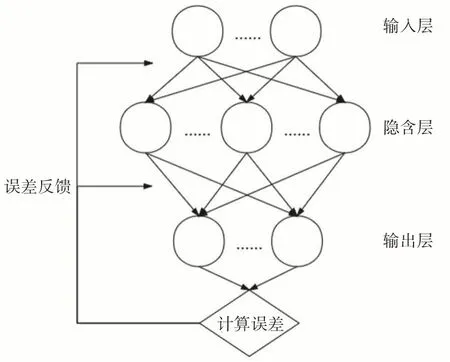
图2 BP神经网络结构
BP神经网络的特点是信号正向传播,误差反向传播,它通过误差反馈不断地调整网络的权值和阈值,使得输出结果的误差逐渐降低,从而逼近期望输出。BP神经网络的训练过程主要分两步。
步骤一:正向传播。从输入层导入训练样本,计算各层的输入和输出:
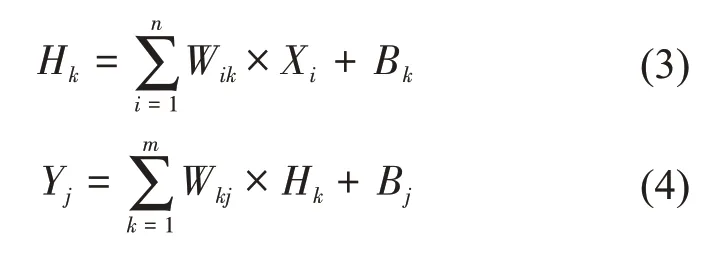
式(3)和式(4)分别是输入层到隐含层、隐含层到输出层的传播关系,其中X是输入层样本,H是隐含层的值,Y是输出层的值,其下标分别是该层对应的神经元编号;W是神经元之间的连接权值,B是神经元的阈值。
步骤二:逆向反馈。计算在输出层得到的数据与训练样本之间的误差,反向传播到输入层和隐含层,通过梯度下降的方式修正连接权值和阈值:
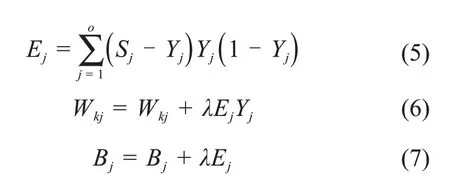
式(5)是计算每个神经元的误差,S是训练样本,Y是输出层的值;式(6)和式(7)是对连接权值和阈值的修正,λ表示学习速率。
3.3 集成方法
Bagging和Boosting是两种集成学习应用在同质弱分类器常用的方法,将弱分类器融合形成精确度更高、鲁棒性更好的强分类器。
3.3.1 Bagging
Bagging也可称为“套袋法”,通过并行训练多个基分类器,使用投票的方式统计它们的预测结果,从而有效提高模型整体的准确率。具体的流程为:(1)有放回地随机抽取n个样本,重复k次,得到k个训练集;(2)每个训练集训练一个基分类器,共得到k个模型;(3)上述的k个模型拥有相同的权值比重,采用投票法得到分类器结果。
3.3.2 Adaboost
Boosting与可并行的Bagging不同,它是通过串行训练弱分类器,再进行集成。其中Adaboost是最具代表性的Boosting方法,它能够自适应弱分类器的训练误差率,通过把每个弱分类器的学习经验传递到下一个弱分类器。具体的流程为:(1)初始化所有样本的权重都相同;(2)利用样本训练基分类器,计算训练误差率;(3)根据训练误差率调整样本的权重分布,被误分的样本权重增大,分类正确的样本权重降低;(4)迭代(2)、(3)过程k次,基分类器的权重随着迭代次数增加而增大,最后将k个基分类器按权重组合得到强分类器。
4 试 验
4.1 验证方法
由于本文中的模型是一个二分类模型,因此可采用混淆矩阵(confusion matrix)及其相关指标来帮助评价模型并进行对比。混淆矩阵中,列为真实值的正负标签,行为预测值的正负标签,矩阵中的值是用于统计分类模型的归类正负的数量(表2)。
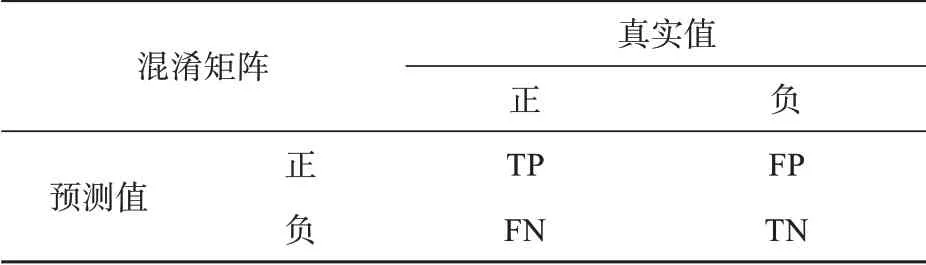
表2 混淆矩阵
基于混淆矩阵,可得出精确率、召回率和F1值三个指标。
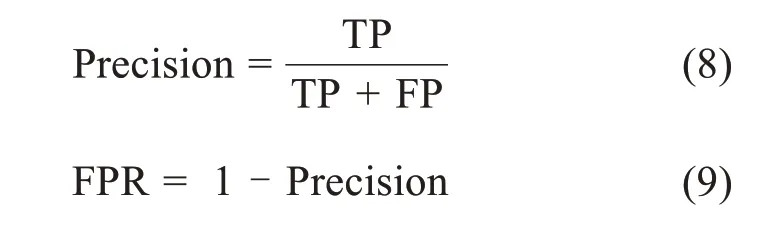
精确率(Precision),即正确预测为真值占所有预测为真值的比例,是针对预测结果,同时也可用于得到更易于解释的误报率(FPR)。公式如下:
召回率(Recall),即正确预测为真值占所有真实为真值的比例,是针对原始样本,同时也可用于得到更易于解释的漏报率(FNR)。公式如下:
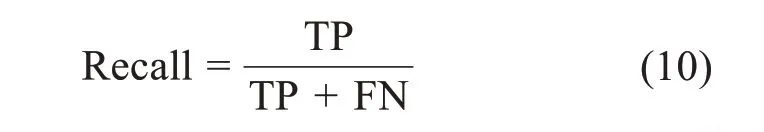
F1值是精确率和召唤率的调和平均值,公式如下:
4.2 试验结果与分析
4.2.1 特征提取对比试验
本文利用特征分析后重新选择的特征与田浩等[11]采用的大气电场6项特征进行对比试验,通过训练相同的样本和采用BP神经网络作为模型,并以2020年的部分样本作为测试,图3的柱状图是两种不同特征采样在误报率、漏报率和F1值上的结果。
从图3可看出,6项特征的误报率和漏报率较高,不适用于本文试验中的数据。在经过重新采集特征后,BP神经网络模型的误报率降低了16.83%,漏报率降低了15.19%,证明了经过特征分析后选取的预测因子更适合广州地区的电场与地闪资料进行雷电预警。
4.2.2 集成学习对比试验
在经过特征的分析与筛选的前提下,本文的试验采用BP神经网络作为基分类器,与其用Bagging和Adaboost集成后的强分类器作对比,通过利用同样的训练样本训练模型,测试验证样本计算评价指标。图4是在训练样本、验证样本和其他条件与4.2.1节相同的情况下,BP神经网络和分别与Baggging、Adaboost集成模型指标上的结果,同样展示其误报率、漏报率和F1值。
从图4中可看出,BP神经网络集成后,其模型的准确率有所提升。其中Bagging的方法提升幅度相对较小,Adaboost的方法提升幅度相对较大。在上述所有集成方法和单一弱分类器的对比中,平均的误报率降低了11.46%,平均的漏报率降低了4.73%。
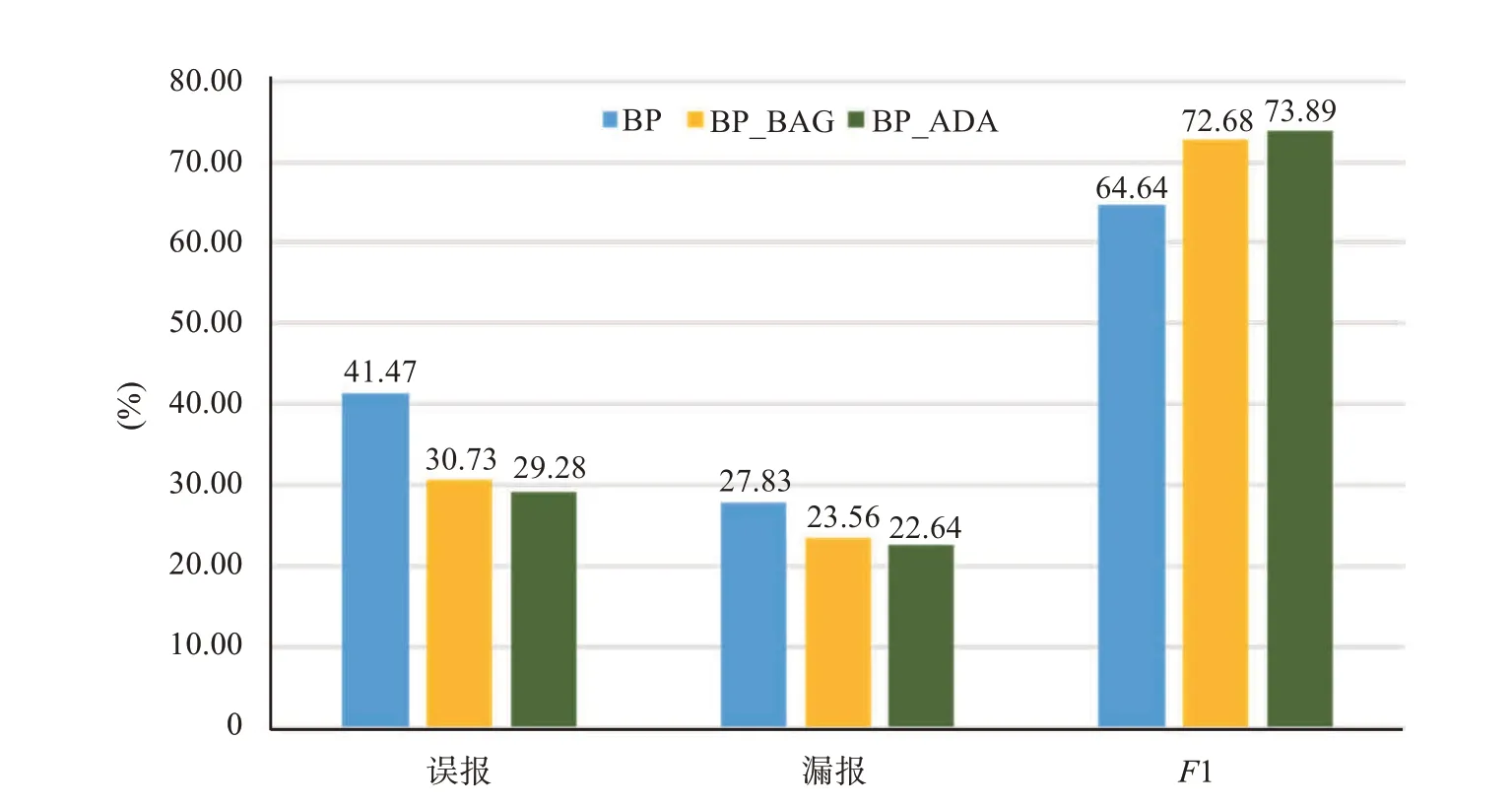
图4 BP神经网络与使用集成模型后的对比
综合考虑上述模型中预警雷电的误报率和漏报率,BP神经网络的Adaboost集成模型的F1值最高,其值为73.89%,比集成前提高了9.25%,对应的误报率降低了12.19%,漏报率降低了5.19%。
从数据中可分析得出,使用集成方法后对比原始的基分类器在预测准确率上有较好的提升,这是得益于集成模型能有效捕获到数据的线性和非线性关系,从而学习到雷电事件发生的规律,并集合多个基分类器修正预测结果,使模型拥有更好的容错性。但同时也可见模型的漏报率降低幅度较小,可能的原因是数据的来源只有大气电场资料和闪电定位资料,缺乏其他能影响雷电天气变化的气象特征,从而限制了集成模型的提升。
5 结论与讨论
(1)大气电场资料和地闪数据与大气电场仪探测范围内的雷电事件有一定的相关性,通过挖掘其中的特征能更有效地提取预测因子,结合规定好以30分钟为单位的时间片作为预测量,能直接应用于常用的BP神经网络模型中。经过特征分析和选择后的预测因子在广州市黄埔地区的电场和地闪资料上表现得更好,试验结果比当前研究采取的6项特征误报率降低了16.83%,漏报率降低了15.19%。
(2)采取了在雷电预警常用的基分类模型BP神经网络,分别利用Bagging和Adaboost的方法分别集成的强分类模型进行训练与预测,通过相关指标来评价它们的结果。结果表明利用集成学习后预测性能都有所提升,其中以Adaboost方法最显著,其最高的F1值能达到73.89%,对应的误报率降低了12.19%,漏报率降低了5.19%。
本文提出的集成方法通过试验证明了集成模型在雷电预警中的有效性和可靠性,并为不同的基分类器的集成提供了指导方向。但本文的方法是以广州市黄埔区的大气电场资料和地闪资料为对象进行分析与探讨,在实际的应用中需要收集足够多的样本,并根据地区差异调整模型参数进行验证。
