基于Python语言的高敏数据动态抓取方法研究
2021-09-22彭文良吴红虹
彭文良,吴红虹
(1.池州职业技术学院 电子信息与传媒系,安徽 池州 247000;2.池州职业技术学院 经济与管理系,安徽 池州 247000)
随着互联网信息的频繁交互,互联网高敏数据增多,需要结合优化的数据和信息处理方法实现对互联网高敏数据的检测和识别,结合动态数据抓取方法进行互联网高敏数据动态特征分析,实现互联网高敏数据动态抓取。通过融合相似度特征分析和特征重组,提高互联网高敏数据的抓取能力,从而实现对网络信息的实时监管。研究互联网高敏数据的动态抓取方法,在互联网高敏数据的挖掘和动态分析中具有重要意义,相关的互联网高敏数据动态抓取方法研究受到人们的极大关注[1]。
对互联网敏感数据动态抓取的设计是在敏感信息的特征分析和空间融合参数识别的基础上,构建互联网敏感数据的参数特征辨识和重构模型[2],结合关联空间融合性重组的方法,实现对互联网敏感数据的提取和大数据分析,提高互联网敏感数据的动态信息检测和识别能力。互联网敏感数据的抓取方法主要有基于模糊PID识别的互联网敏感数据动态抓取方法、基于相似度特征分析的互联网敏感数据动态抓取方法以及基于粒子群寻优的互联网敏感数据动态抓取方法等[3-5],通过模糊信息特征匹配,进行互联网敏感数据动态抓取,利用上述方法进行互联网敏感数据动态抓取的特征辨识度不高,信息融合水平不好。对此,本研究提出基于Python语言的高敏数据动态抓取方法。首先构建互联网高敏数据的存储结构模型,采用模糊语义本体信息匹配滤波的方法,建立互联网高敏数据交互的模糊语义本体信息检测模型,结合特征分析方法,实现对互联网高敏数据线性输出的稳定性控制和自相关约束检测,建立互联网高敏数据的控制参数集,通过统计特征分析实现对互联网高敏数据的关联性调度,分析互联网高敏数据的语义相似度,采用语义信息交换的方法实现互联网高敏数据的动态特征检测,根据信息融合和大数据聚类结果,实现对互联网高敏数据的动态抓取。最后采用Python语言实现对互联网高敏数据的动态抓取,设计仿真实验,展示本设计方法在对互联网高敏数据动态抓取能力方面的优越性能。
1 互联网高敏数据信息分布和特征表达
1.1 互联网高敏数据信息分布
为了实现基于Python语言的高敏数据动态抓取,构建互联网高敏数据的存储结构模型,采用模糊语义本体信息匹配滤波的方法进行数据分析,并构建互联网高敏数据分布模型[6],得到的互联网高敏数据分布情况如图1所示。

图1 互联网高敏数据分布模型
根据图1所示的敏感数据分布模型,采用过滤式和包裹式方法,得到互联网敏感数据多样本方差的参数匹配模型为:
(1)
式(1)中,(xi,xj)表示互联网敏感数据中筛选的多样本匹配参数,b为互联网敏感数据的相似度分布系数,K表示互联网敏感数据的耦合系数。采用主成分线性相关决策的方法[7],得到互联网敏感数据的主成分信息索引的数据匹配集为:
(2)
采用冗余信息滤波检测,得到互联网敏感数据的欠采样解析控制参数,结合邻阶信息的回归分析,建立互联网敏感数据的回归样本拟合模型,表示为:
(3)
式(3)中,αj表示互联网敏感数据冗余度,采用最大概率密度分析方法,进行互联网敏感数据的最近邻点匹配,得到互联网敏感数据检测和滤波分析的统计向量为:
(4)
式(4)中,αi表示互联网敏感数据的自适应输出系数。SR,SS和SE分别表示互联网敏感数据的参数调度集,通过三阶自相关信息匹配的方法,进行互联网敏感数据的分布式检测,提高互联网敏感数据的检测识别能力。
1.2 互联网敏感数据特征表达
采用K近邻的欠采样的方法,进行互联网敏感数据的深度学习和特征分解,构建互联网敏感数据的数据特征分析模型[8-11],得到互联网敏感数据的多维参数检测模型为:
(5)
式(5)中,x(t)表示互联网敏感数据的离散样本,基于深度学习的数据特征分析方法,得到互联网敏感数据的差分信息特征匹配结果为:
(6)
式(6)中ωj=(ω0j,ω1j,…,ωk-1,j)T表示互联网离散区域敏感数据的相似度,根据自适应的信息加载方法,得到互联网高敏数据检测的阈值控制因子分布模型为yi,采用互联网高敏数据的关联检测方法,得到互联网敏感数据动态抓取的特征规则模型为:
(7)
通过三层全连接层参数识别的方法,进行互联网敏感数据的欠采样和特征提取,得到的互联网高敏数据的特征检测识别模型如图2所示。
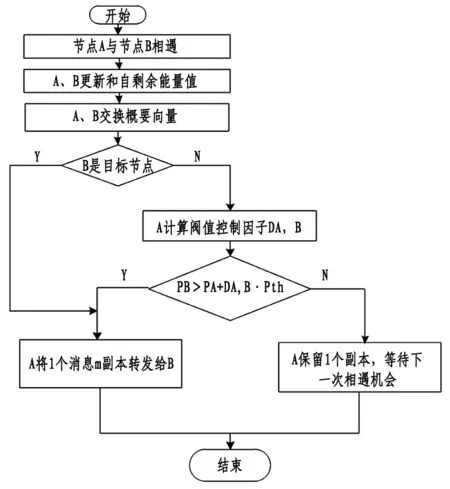
图2 互联网高敏数据的特征检测识别模型
在图2所示的互联网高敏数据的特征检测识别模型中,抓取统计特征量,实现对互联网高敏数据的线性输出稳定性控制和自相关约束检测[12-14],得到关联分布系数SP和互联网高敏数据的信息特征分布矩阵Q′,更新互联网高敏数据的聚类中心点,则互联网高敏数据的特征表达式为:
(8)
建立基于最小二乘规划模型,进行互联网高敏数据的信息检测和动态抓取,可以提高互联网高敏数据的检测识别能力[15]。
2 互联网高敏数据动态抓取融合控制与优化输出
2.1 互联网高敏数据动态抓取融合控制
建立互联网高敏数据的控制参数集,通过统计分析实现对互联网高敏数据的关联性调度,分析互联网高敏数据的语义相似度性,得到互联网高敏数据的线性包络融合向量和线性空间融合矩阵Q,存在逆矩阵Q-1,使得互联网敏感数据动态抓取的概率模型满足正定条件:
(9)
公式(9)中,QS表示高敏数据的捕获异常概率,由上述条件可知互联网高敏数据检测和动态抓取的语义本体参数分布模型满足:
det(Q′)=(yT)e-2π+det(Q)
(10)
式(10)中,det(Q)表示互联网高敏数据的融合调度参数,采用包络分析建立互联网高敏数据的分类和线性识别模型,得到互联网高敏数据的线性多维空间融合输出:
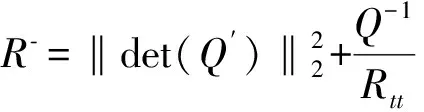
(11)
式(11)中,Rtt表示互联网高敏数据的融合空间维度,对于∀iSS,在互联网敏感数据的融合分布区域中采用子空间聚类方法,得到互联网高敏数据的模糊信息聚类融合分布子空间的语义相似度参数uM和采用动态线性标记的方法,得到互联网高敏数据的融合属性集为Com(U,c):
(12)
式(12)中,uij为第j个互联网高敏数据属性分布集中的相似解,分析互联网高敏数据的动态输出参数规律,得到互联网高敏数据动态抓取的融合控制中心为:
(13)
式(13)中,uaj和ubj表示互联网高敏数据的分布维数,根据上述分析,进行互联网高敏数据的动态融合控制。
2.2 互联网高敏数据动态抓取优化输出
采用语义信息交换的方法实现互联网高敏数据的动态特征检测,根据信息融合和大数据聚类结果,得到互联网高敏数据的输出结果[16],采用关联维检索的方法,建立互联网高敏数据动态抓取的检测统计输出量为:
(14)
式(14)中,EcJ表示互联网高敏数据的输出向量集,ScJ表示互联网高敏数据的自适应空间组合函数。建立互联网高敏数据的线性映射组合输出分布矩,表示为:
(15)
式(15)中,g11,g12表示互联网高敏数据的线性映射分布参数,根据互联网高敏数据的动态输出分布式检测结果,进行互联网高敏数据的相干处理,通过模糊度检测和动态识别技术,实现对互联网高敏数据的动态抓取识别,得到互联网高敏数据的动态抓取的联合迭代函数为:
(16)
式(16)中,cauchy(θ,α)为标准柯西分布,θ=0,α=1,分析上述过程,得到互联网高敏数据抓取输出的聚类参数为:
(17)
式(17)中,pj(t)为互联网高敏数据的动态抓取的过程控制函数,η1,η2均为[0,1] 之间的随机数,结合参数寻优控制方法,得到互联网高敏数据的动态抓取的优化控制输出为:
(18)
式(18)中,φ(x)表示互联网高敏数据的输出效率,Xmax,Xmin分别为互联网高敏数据动态抓取交互的下界和上界分布阈值。根据公式(18)可知,可以通过调控数据输出效率实现高敏数据动态抓取交互优化控制。
3 仿真实验与结果分析
为了验证本文方法在实现互联网高敏数据动态抓取的有效性,采用Python进行仿真测试。文献[1]方法、文献[15]方法以及本文方法的参数设置如下:互联网高敏数据的特征采样样本长度为1300,互联网高敏数据融合的聚类样本序列为520,互联网高敏数据的动态抓取参数匹配系数为0.38,模态数量为12,K=4,N=1000,γ=0.05,根据参数设定,得到的互联网高敏数据检测统计特征量和包络幅值分布如图3所示。

图3 互联网高敏数据检测统计特征量和包络幅值分布
根据图3的互联网高敏数据检测统计特征量和包络幅值检测结果,实现对互联网高敏数据的动态抓取,将本文方法与文献[1]和文献[15]的方法进行对比,得到的互联网高敏数据动态抓取结果如图4所示。

图4 互联网高敏数据动态抓取结果
分析图4得知,当数据抓取时间为2 s时,文献[1]方法的高敏感数据动态抓取输出幅值为0.173 dBm,文献[15]方法的高敏感数据动态抓取输出幅值为0.176 dBm,本文方法的高敏感数据动态抓取输出幅值为0.184 dBm。当数据抓取时间为8 s时,文献[1]方法的高敏感数据动态抓取输出幅值为0.188 dBm,文献[15]方法的高敏感数据动态抓取输出幅值为0.195 dBm,本文方法的高敏感数据动态抓取输出幅值为0.199 dBm。本文方法的高敏感数据动态抓取输出幅值明显高于其他两种方法。说明本文方法能有效实现对互联网高敏数据的动态抓取,数据输出的特征聚类性较好。测试不同方法进行互联网高敏数据抓取的误差,得到对比结果如表1所示。
分析表1得知,当实验迭代次数为100次时,文献[1]方法的互联网高敏数据抓取误差为0.236,文献[15]方法的互联网高敏数据抓取误差为0.146,本文方法的互联网高敏数据抓取误差为0.113。当实验迭代次数为200次时,文献[1]方法的互联网高敏数据抓取误差为0.134,文献[15]方法的互联网高敏数据抓取误差为0.132,本文方法的互联网高敏数据抓取误差为0.043。本文方法的互联网高敏数据动态抓取的误差低于其他方法,说明其高敏数据动态抓取的准确度较高。

表1 互联网高敏数据抓取误差对比
4 结论
通过融合相似度特征分析和特征重组,提高互联网高敏数据的抓取能力,从而实现对网络信息的实时监管,本设计提出基于Python语言的高敏数据动态抓取方法。采用语义信息交换的方法实现互联网高敏数据的动态特征检测,根据信息融合和大数据聚类结果,得到互联网高敏数据的特征提取结果,通过模糊度检测和动态识别技术,实现对互联网高敏数据的动态抓取识别。研究得知,数据抓取时间为8 s时,本设计方法的高敏感数据动态抓取输出幅值为0.199 dBm。实验迭代次数为200次时,本设计方法的互联网高敏数据抓取误差为0.043。本设计方法的高敏感数据动态抓取输出幅值明显高于其他两种方法,说明本设计方法能有效实现对互联网高敏数据的动态抓取,数据输出的特征聚类性较好。本设计方法的互联网高敏数据动态抓取的误差低于其他方法,说明其高敏数据动态抓取的准确度较高。
