基于两阶段聚类的设备状态异常检测方法
2021-09-18吴英友胡刚义唐静严谨许腾腾
吴英友,胡刚义,唐静,严谨,许腾腾
(1.广东海洋大学,广东 湛江 524005;2.中国舰船研究设计中心,湖北 武汉 430064;3.北京石油化工学院,北京 102617;4.远光软件股份有限公司,广东 珠海 519085)
0 引言
为保障运行及作业,大型船舶与海洋工程平台的机舱装备了由数以百计的机电设备构成的大型装备系统。由于海上运行环境恶劣,高温、高湿、高盐,因此船舶与海洋工程平台机舱的设备、系统的故障率远远高于陆上。如果无法及时检测并诊断设备异常,将造成系统无法正常运行,可靠性降低,严重时整船停止运行或出现严重的生产安全事故,带来巨大经济损失。因此,设备异常检测方法的研究对于及时发现异常、降低设备故障损失具有积极的实际意义。
异常检测是指检测给定数据集中不符合已建立的健康状态模式的过程[1]。异常检测技术已经成为数据挖掘领域中的研究热点。一般异常检测方法包括基于统计学方法[2]、基于分类方法(如支持向量机、神经网络)[3–4]、基于距离的方法[5]、基于密度的方法[6]、基于聚类分析的方法[7]等。
目前国内对于机械系统的异常检测主要从以下2 个方面进行:1)针对局部设备进行异常检测和故障诊断;2)通过整理大量的设备故障经验数据建立知识库,开展基于机器学习等方法的异常检测。该方法对于实际应用场景下的设备异常检测,存在一定的局限性。首先,该方法针对局部设备的异常,对系统的运行缺乏整体性把握,且不易扩展应用;机械系统的故障类型众多且故障重复频率低,较难构建完备的故障数据知识库。
针对以上问题,本文提出基于两阶段聚类的设备异常检测的方法。该方法对获取的时间序列数据进行预处理后,通过第一阶段聚类获取特征数据的离群时间信息,采取第二阶段聚类算法评估系统异常情况。本文所提出的基于两阶段聚类评估系统异常的方法,从无监督学习的角度出发,不需要大量的专业知识经验,仅从最近的历史数据学习,配合少量的业务经验,即可快速的确定故障位置和对应时间。该方法采用两阶段聚类思想减少了一次聚类的不确定性,可有效提高异常检测的准确性。
1 基于聚类的异常检测方法介绍
一般的异常检测方法包括:基于距离的异常检测、基于密度的异常检测,以及在此基础上发展的基于聚类的异常检测[8]:
1)基于距离的异常检测
基于距离的异常值检测方法计算某个数据点与周围其他数据之间的距离,结合设置的距离阈值判断异常。对于异常数据距离的度量方法可以根据数据集的分布情况进行选取,一般有欧式距离、曼哈顿距离等。
2)基于密度的异常检测方法
该方法建立在基于距离的检测方法基础上,主要思想是结合数据点之间的距离和设定范围内的数据点数目2 个参数,进而获得“密度”概念,通过密度的计算判断异常[9]。
3)基于聚类的异常检测方法
基于聚类的异常检测方法是通过聚类分析将数据归为不同的簇中,异常数据则是不属于任何簇或者远离簇心的数据点[10–12]。包括基于距离聚类、基于密度聚类和基于层次聚类等[13]。
该方法作为一种无监督学习方法,在不需要大量标签数据的条件下就可以实现异常检测,适用于多种数据类型且具有较广阔的应用范围。但仅仅使用一次聚类方法进行异常检测具备一定的局限性,异常检测结果受聚类簇结果的影响,如果聚类簇的效果不够理想,异常检测结果也相对较差。
本文提出的基于两阶段的聚类异常检测方法,采用两次聚类分析检测系统异常,通过一次聚类构建离群时间段矩阵,再通过层次聚类分析对离群时间段矩阵进行异常检测和定位。该方法有效缓解基于一次聚类进行异常检测的局限性,进一步降低异常检测的误报率。
2 基于两阶段聚类的异常检测方法
基于两阶段聚类的异常检测方法通过系统测点数据预处理进行特征计算,利用特征聚类算法构建系统多测点离群时间矩阵,采取层次聚类算法并结合专家经验实现系统异常信息检测。本文提出的异常检测方法框架如图1 所示。
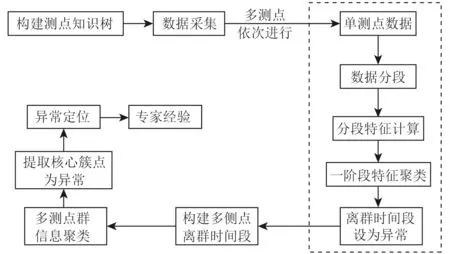
图1 异常检测方法框架图Fig.1 Frame diagram of anomal detection method
2.1 构建离群时间段矩阵
一般而言,获取的测点数据为时间数据序列,具备高维度、高特征相关及有序等特点,因此为降低数据挖掘所造成的计算成本同时提高数据挖掘的准确性,本文采用静态数据分割方法对测点数据进行分段信息提取。
为了在数据维度简约的基础上最大化保留数据特征,选取三角极值点线性分段方法[14]对测点时间数据序列进行分段操作。该方法通过评估相邻极值点之间的变化幅度进而获取关键点序列。
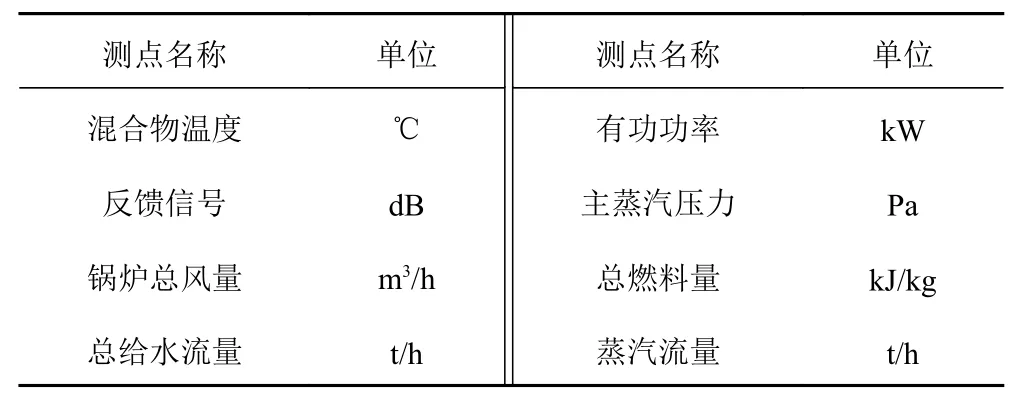
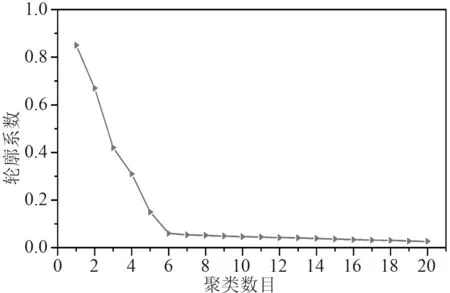
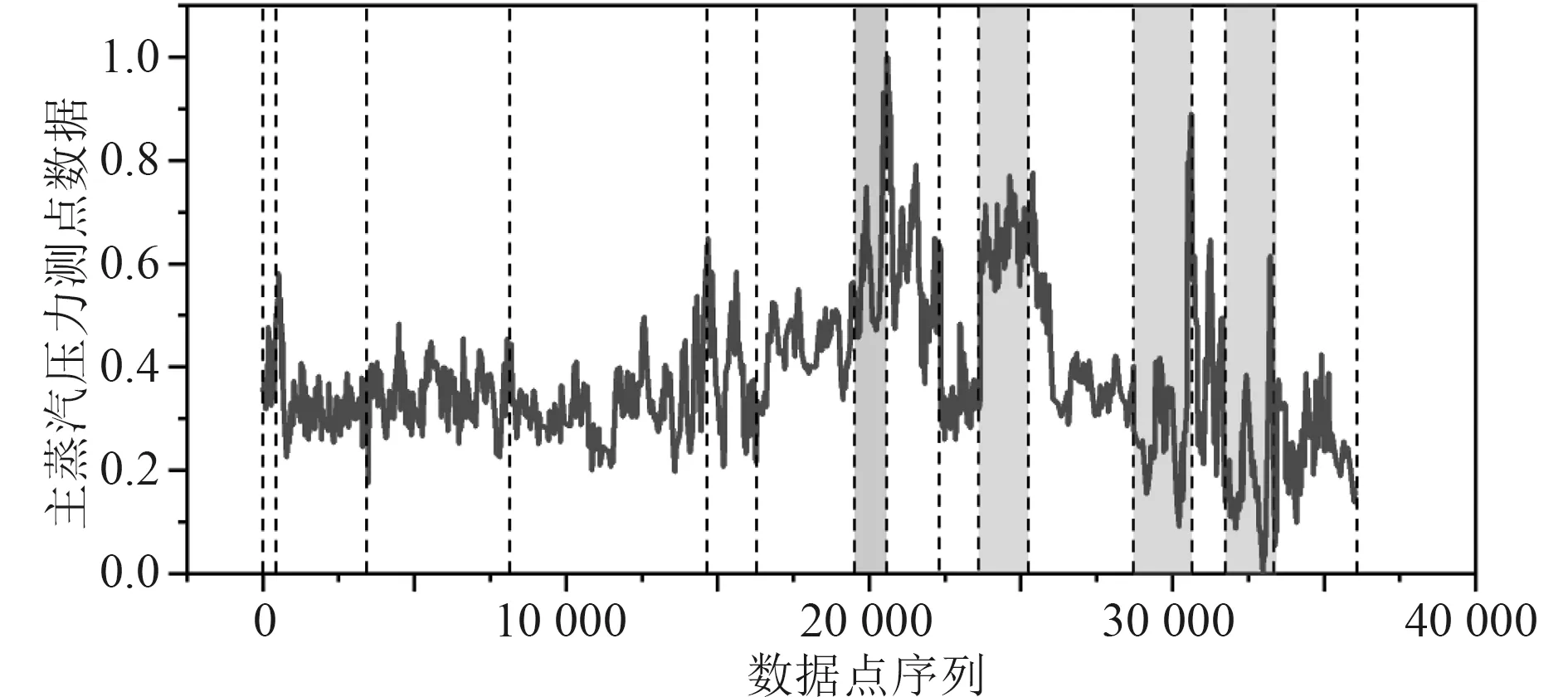
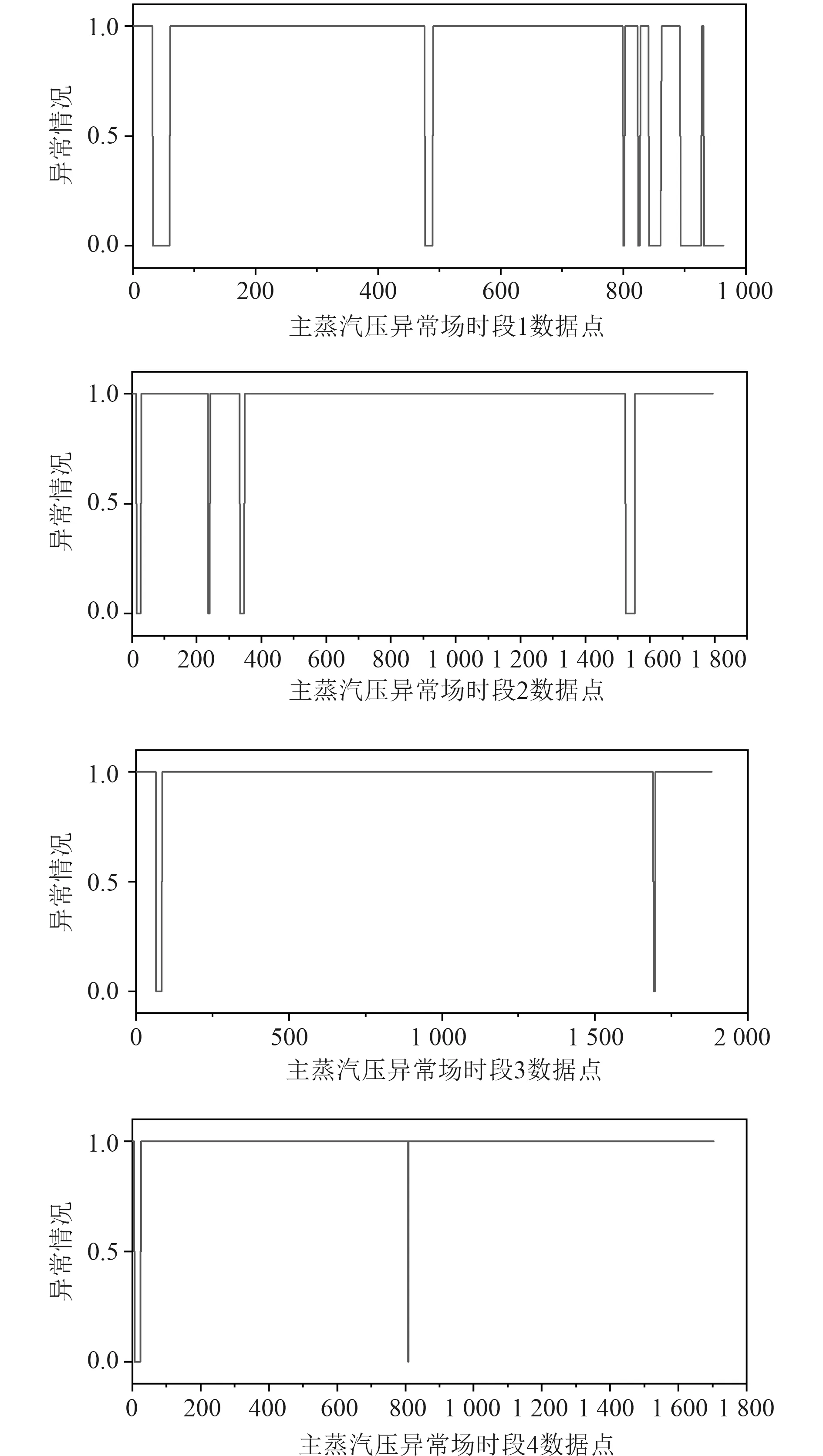
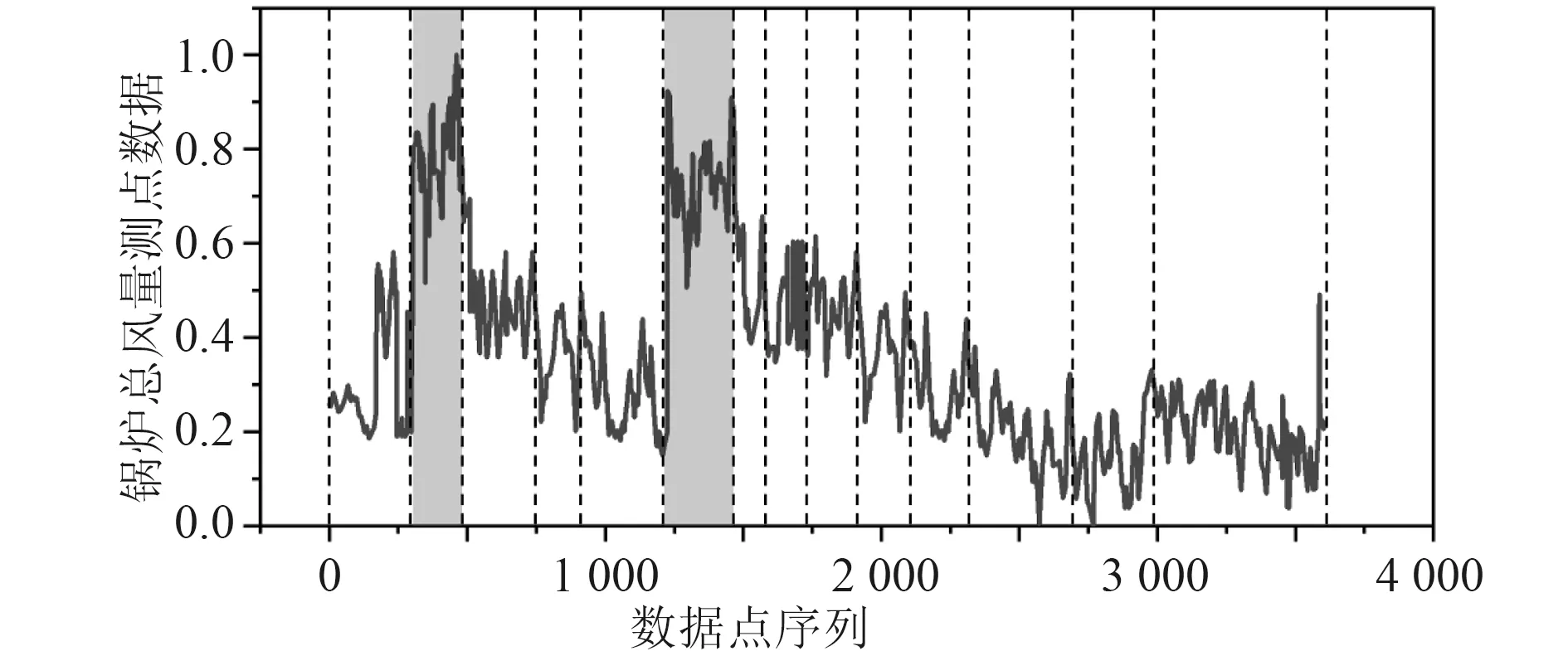
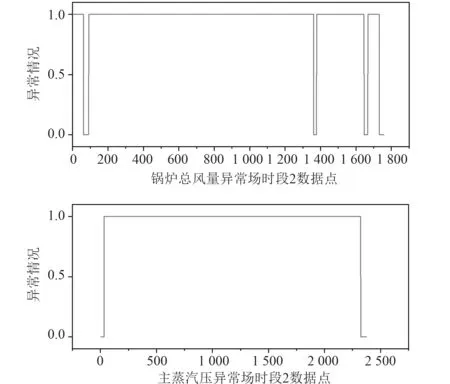
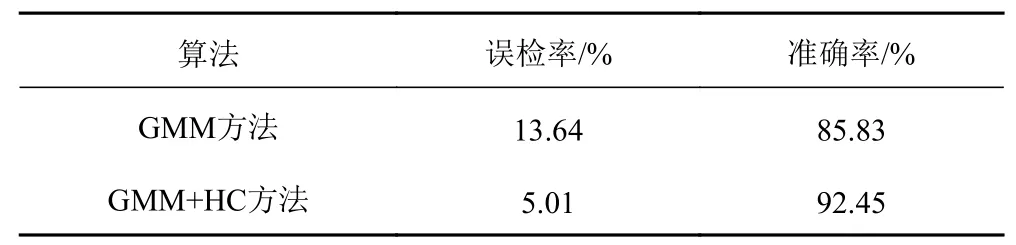
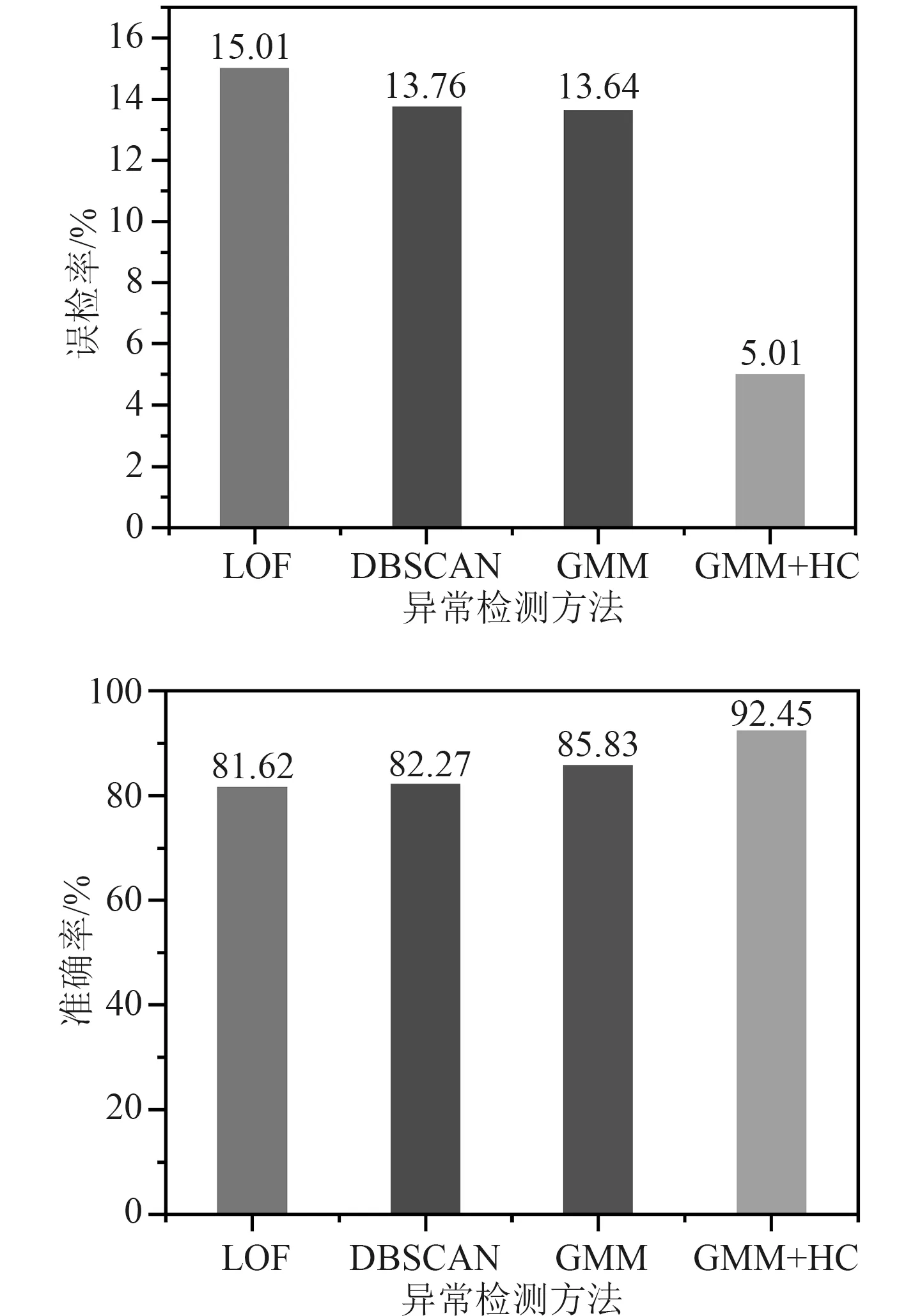
首先,通过遍历时间数据序列,按照顺序寻找极值点。假设oi(i=2,3,4,···) 作为时间序列O的某个数据点,如果存在oi>oi+1,oi>oi−1(或者oi 其中,h表示点oi到线段|oi−1oi+1|的距离,即△oi−1oioi+1的高。 由此可得,在确定极值点oi−1和oi+1情况下,取决于极值点oi,越大,oi成为关键点的可能性越大。该问题可以转换为oi到线段|oi−1oi+1|的距离h和的关系,则h越大,oi成 为关键点的可能性越大,相反地,h越小,oi成为关键点的可能性越小。因此,可利用h表示极值点oi的线性偏离度,h越大,偏离程度越大,oi作为分段点的重要性越高。依次对三个连续的极值点计算线性偏离度,进而得到线性偏离度序列hi(i=1,2,···,n;n=length(O′)−2)。通过设置线性偏离度阈值进行判断,当hi大于该阈值时,将其作为分段点进行时间数据序列的分段操作;当hi小于该阈值时,表明该极值点不可作为分段点,则剪掉该极值点,保存数据趋势特征,降低噪声的干扰。 完成时间序列数据的分段处理后,对分段的数据进行特征提取和特征降维操作。为反映数据异常变化,提取测点数据相关特征信息,主要包括反映数据趋势的指标、反映波动的指标、反映分布特征的指标和反映变异的指标。 由于各指标之间存在一定的信息重叠,为了避免后续聚类的效果受数据量和簇的个数的影响,需进行降维处理,减少信息冗余,采用机器学习中常用的主成分分析法进行数据特征的降维处理。 本文采用EM 算法[15]对降维处理的特征数据进行第一阶段聚类构建离群时间段矩阵。EM 算法是一种通过模型进行聚类的方法,主要用于包含隐变量的概率模型参数的极大似然估计或极大似然概率估计。采用混合高斯模型[16]通过EM 算法进行测点多个分段数据的聚类。假设某个测点的分段数据符合高斯分布,该算法利用计算确定的每个高斯部件的参数拟合给定的分段数据,获得模糊聚类结果。即由确定的参数决定每个数据实例属于各高斯分布的概率。 对于一个完整数据集 (x1,x2,···,xn),其中xi的每一列表示每个时段数据的特征向量,将引入的隐含变量用zi表示。 假设zi独 立同分布M 类,那么其对应的概率分别为π1,π2,···,πM,通过xi确定zi的密度函数为因此数据所对应的似然函数为: EM 算法迭代过程分两步进行:1)E-step,通过观测向量xi和当前的参数估计,计算获得似然函数L(θk,πk,zik|x)的条件期望值zik;2)根据E-step的计算结果,获得最大化似然函数值的参数估计,包括均值、所占权重和协方差矩阵。 基于聚类分析结果,将每个测点可能出现异常的时间段构建为测点的离群时间段矩阵,然后通过第二阶段聚类分析检测系统具体的异常情况。 通过一阶段聚类筛选初始各测点异常信息,由于该过程未考虑多测点之间的联动性,无法准确定位异常情况,因此应在多个测点的离群时间段上采用层次聚类方法进行二次聚类评估,寻找聚类的核心簇点,进而确定系统具体的异常情况。 基于层次聚类的异常检测方法通过对第一阶段聚类结果进行相似度计算,采用自底向上或者自顶向下的方法对离群时间段数据进行层次划分,进而形成树形结构图。本文采用凝聚算法即自底向上的聚合方法进行聚类操作,首先将每个离群时间段数据作为初始的聚类簇,其次聚合相似度最高的两个类别,接着不断迭代聚合过程直至分类完成。具体过程为: 1)将离群时间段数据矩阵SA=(X1,X2,···,Xn)中的每个实例Xi表示为一个类别,即只具有单成员的类ci=Xi(i=1,2,···,n) 构建为样本集SA的初始聚类,表示为: 综上所述,随着时代的发展,很多新的理论与技术都应用于现如今的电力系统继电保护当中,和以前相比,相关工作人员应该具备更多的业务知识来满足时代发展的需求,由此可见,相关工作人员在实际工作过程中,只有通过不断加强实践操作,对电力系统相关知识领域进行不断探索与研究,才能为我国电力事业做出贡献。 2)利用全连接算法度量各实例类别之间的相似性,如下式: 其中:c1,c2表示簇;Xi,Xj表 示离群时段数据对象。 3)通过上式计算,合并相似度最大的2 个类别为新的类别,因此构成新的聚类。 4)再进行步骤2,反复迭代直至达到终止条件。 5)返回层次聚类的结果。 根据层次聚类结果,找出各类别的核心簇点,该簇点对应的时间段一般为异常发生的时间段,同时核心簇点的监测数据为子系统在各测点对应的异常数据。将获得的各测点对应的异常数据反馈到,第一阶段聚类和第二阶段聚类,用于真实评价异常的结果,标记异常对错,决策学习和优化异常的阈值参数。通过以上流程,能够有效监测除绝大部分系统变化异常的测点,对于未检测到的小部分导致异常变化的数据,利用专家系统进行筛选。 考虑到船舶或海洋工程平台开展实验的复杂性及经济性,在方法研究初始阶段,可用已有的同类数据开展验证。证明方法可行性后,下一阶段可到船舶或海工平台开展深入实验验证。目前普遍装备有安全仪表系统,较方便获取足够的数据,而且数据类型多,可验证方法对不同类型数据的适应性。本文以某系统的实时运行数据进行实验分析。通过对测点运行数据进行两阶段聚类获取异常情况,采用相应的评价指标对实验结果进行有效性验证,同时和其他异常检测方法进行性能对比。 选取系统的主要测点如表1 所示。采集7 月16 日02:00:00 至7 月16 日 22:00:00的测点 数据,采 集频率为2 s。 表1 选取的系统主要测点Tab.1 Selected main measuring points of pulverizing system 为了消除数据属性之间的差异性,提高聚类效果的准确性,采取常用的离差标准化算法对测点数据进行标准归一化处理。设某测点数据集为Xi=(xi1,xi2,···,xin),那么标准化过程为: 为了更加直观地验证本文提出的异常检测方法性能,根据实验结果对比系统数据异常缺陷单进行对比验证,采用相应的评价指标进行分析。评价指标为:指标包括误检率(FAR)和准确率(PR)。 其中,误检率是指没有被正确判断出所属类别的数目E与检测数据集中总的正常数目RN之比,即 准确率是指被正确判断出所属类别的数目RA与总的数目N之比,即 在进行层次聚类时,根据聚类效果进行参数的调整。由于实验数据是无标签的,因此采用轮廓系数法进行聚类性能的评价。轮廓系数的计算公式如下: 其中,a代表样本与同类数据中所有其他点之间的平均距离,b代表样本与下一个最近聚类簇中所有其他点之间的平均距离。最终整体的轮廓系数是计算出所有样本的轮廓系数后取平均值得到的,因此轮廓系数得分越高,说明此时的聚类结果使得同一种类之间聚集的比较紧密,同时不同的类之间聚集的比较远,据此可以判定此时的聚类效果较好。 本文选取层次聚类的不同簇间距离度量方法为最大距离标准方法,同时考虑聚类数目选择的实验区间至20 种,分不同的情况进行实验进而得到聚类的轮廓系数。实验结果如图3 所示,其中横坐标表示聚类数目,纵坐标表示轮廓系数的值。由图可知,最佳聚类数目为6。 图3 聚类最佳数目Fig.3 Optimal number of clusters 根据二次聚类异常检测结果,进而获聚类核心簇点,获取精准异常测点和对应的时间段。由实验结果可得,系统出现异常的测点分别为主蒸汽压力测点和锅炉总风量测点。图4 为检测到主蒸汽压力测点出现异常情况,其中虚线表示时间段分割,灰色区域表示异常检测数据所分布的时间段。该测点异常时段包括4 个,分别为12:54:02 至13:24:16,15:02:26-16:06:18,17:54:12-18:56:04 和19:26:12-20:30:36。 图4 主蒸汽压力测点对应异常时段Fig.4 Corresponding abnormal period of main steam pressure measuring points 图5 为时间段内的数据点异常情况,其中“1”表示正常数据,“0”表示异常数据。 图5 主蒸汽压力异常时段数据情况Fig.5 Data in abnormal period of main steam pressure 锅炉总风量测点异常情况如图6 所示。二次聚类获得的异常数据分布在2 个时间段,分别为03:36:24-04:24:32 和08:48:00-10:06:12,如图中灰色区域所示。图7为异常时间段的数据异常情况,其中“1”表示正常数据,“0”表示异常数据。 图6 锅炉总风量测点对应异常时段Fig.6 Abnormal period corresponding to total air volume measuring point of boiler 图7 锅炉总风量压力异常时段数据情况Fig.7 Data during abnormal period of total air volume and pressure of boiler 为验证本文异常检测方法性能,结合系统各测点异常缺陷单,对比两阶段聚类(GMM+HC)和仅采用一阶段聚类(GMM)的结果,如表2 所示。其中,两阶段聚类方法比仅采用一阶段聚类方法有效降低了异常检测误检率,同时提高检测准确度。 表2 一阶段聚类检测和两阶段聚类检测方法性能对比Tab.2 performance comparison of one-stage cluster detection and two-stage cluster detection methods 为进一步验证本文方法性能,研究多种异常检测方法并采用同一数据集进行对比分析,结合表2 性能对比结果,绘制不同异常检测方法性能对比图,如图8所示。其中基于局部离群点检测(LOF)[9]和基于DBSCAN 检测方法[17]在误检率和准确率方面明显不如本文提出的基于两阶段聚类的异常检测方法。主要在于LOF 检测方法仅依赖于邻域内的密度之比,未充分考虑全局信息即测点之间的联动性;而DBSCAN 检测方法受聚类参数影响较大。本文提出的方法充分考虑各测点间的联动性。 图8 不同异常检测方法性能对比Fig.8 performance comparison of different anomal detection methods 针对现有异常检测方法在机电系统异常检测中存在局限性、误检率高等问题,本文提出基于两阶段聚类的异常检测方法。该算法主要包括数据采集、预处理、两阶段聚类异常检测,通过一次聚类进行初始异常时段筛选,再根据二次聚类进行异常定位,进而达到降低误检率的目的。同时,该方法从无监督学习出发,不需要大量的专业知识经验,仅从最近的历史数据学习,并配合少量的业务经验就可以实现机电系统异常的检测。实验表明,该方法提高了异常检测准确率,有效减少了异常误判的产生。因此,基于两阶段聚类的异常检测方法可以实现精准的快速故障检测,具有良好的应用前景。
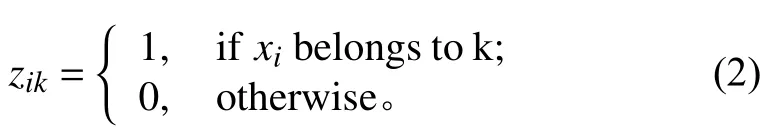

2.2 基于层次聚类的异常检测
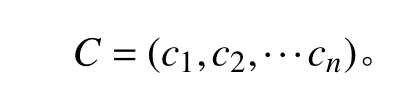
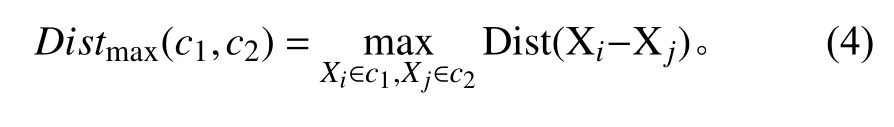
3 实验与评估
3.1 数据获取与准备
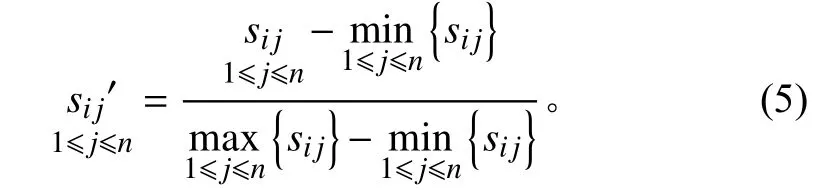
3.2 评价指标


3.3 实验过程与结果讨论
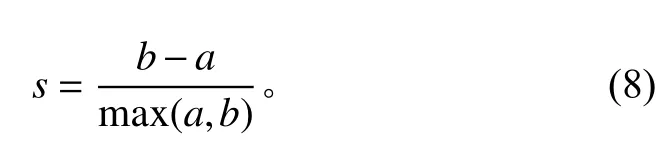
4 结语
