快堆全堆芯热工流体子通道并行模拟技术研究
2021-09-16蔡银宇董玲玉刘天才胡长军
卢 旭,蔡银宇,董玲玉,刘天才,杨 文,胡长军
(1.北京科技大学 计算机与通信工程学院,北京 100083;2.中国原子能科学研究院 反应堆工程技术研究所,北京 102413)
钠冷快堆是第4代核反应堆中技术最成熟、运行经验最丰富的堆型,在核能可持续发展战略中占有重要地位,其热工流体安全特性的研究是设计研发和安全评审的核心[1]。基于子通道模型的计算模拟方法是研究快堆热工流体特性的重要手段。受计算能力的制约,传统的子通道分析程序一般采用简化的、粗略的模型,不能计算全堆芯而只计算部分典型的子通道,或将1个组件甚至多个组件视为1个子通道[2],所以结果过于粗略,不能精细地反映堆芯的真实状况。随着超算技术的发展和算力不断提升,开展全堆芯精确到每个真实流道的钠冷快堆子通道计算模拟成为研究热点[3-4]。
应用于水堆领域的热工流体子通道分析程序已较为完善,已实现全堆芯精确到每个真实流道最高可扩展到6 280核的并行模拟[2]。但对于钠冷快堆热工流体子通道模拟程序,在模拟的算例规模上大多为几十根棒或几个组件,如Kim等[5]在COBRA-Ⅳ-Ⅰ和MATRA程序的基础上进行了19根棒规模的模拟;Fricano[6]在COBRA-Ⅳ-Ⅰ程序的基础上进行了19根棒的橡树岭国家实验室基准算例、Toshiba 37根棒的算例以及西屋电气61棒算例的模拟;Kikuchi等[7]开发了钠冷快堆子通道模拟软件ASFRE,并进行了37棒算例的验证,最大并行规模是128进程;周志伟等[8-9]为CFR600快堆堆芯设计了热工流体分析及流量优化小规模计算程序。从目前相关研究工作看,距离全堆规模的并行模拟需求还相差甚远,模拟的规模、精度远达不到理想的工程需求,其根本原因除算力的制约之外,全堆芯建模和自适应并行任务划分技术也是实现全堆并行模拟的瓶颈问题。
2015年,Salko等[10]开发了用于压水堆全堆芯精确到每个真实流道的高精细子通道模拟的堆芯自动建模系统,该系统大大简化了用户输入集,同时提供了可用于并行模拟的压水堆全堆芯子通道并行任务划分方法,但目前此方法仅支持组件数等于进程数的并行任务划分。该项目在2017年已着手开发针对快堆的子通道模拟软件[11],但其建模技术尚处于封锁状态。目前并行子通道模拟的任务划分方式并不完善。
本文基于钠冷快堆堆芯的几何特性,抽象出用以描述钠冷快堆堆芯的基础结构,并设计相应的数据结构和算法,实现一种用于钠冷快堆全堆芯精确到每个真实流道的并行子通道模拟的堆芯建模及并行任务划分方法。通过与传统手动建模结果对比证明建模结果的正确性,使用针对快堆模拟修改后的子通道模拟软件CTF[12-13]对建模结果进行验证。
1 钠冷快堆堆芯建模与任务划分
1.1 堆芯的精细建模
钠冷快堆堆芯精确到每个真实流道的子通道划分如图1a所示,快堆堆芯由上百个组件组成,每个组件中有几十到几百根燃料棒,将组件中3根棒围成的1个冷却剂流道划分为1个子通道(边通道、角通道特殊),将每个子通道沿轴向进行分层,每层为1个子通道控制体。建模过程需要描述以下信息:1) 堆芯的映射关系信息。对堆芯中要模拟的对象构建1个唯一标识,并对堆芯中各对象的空间关联关系进行描述;2) 堆芯的几何参数信息。包含描述对象位置的坐标信息,求解控制方程需要的子通道湿周、面积等几何信息。
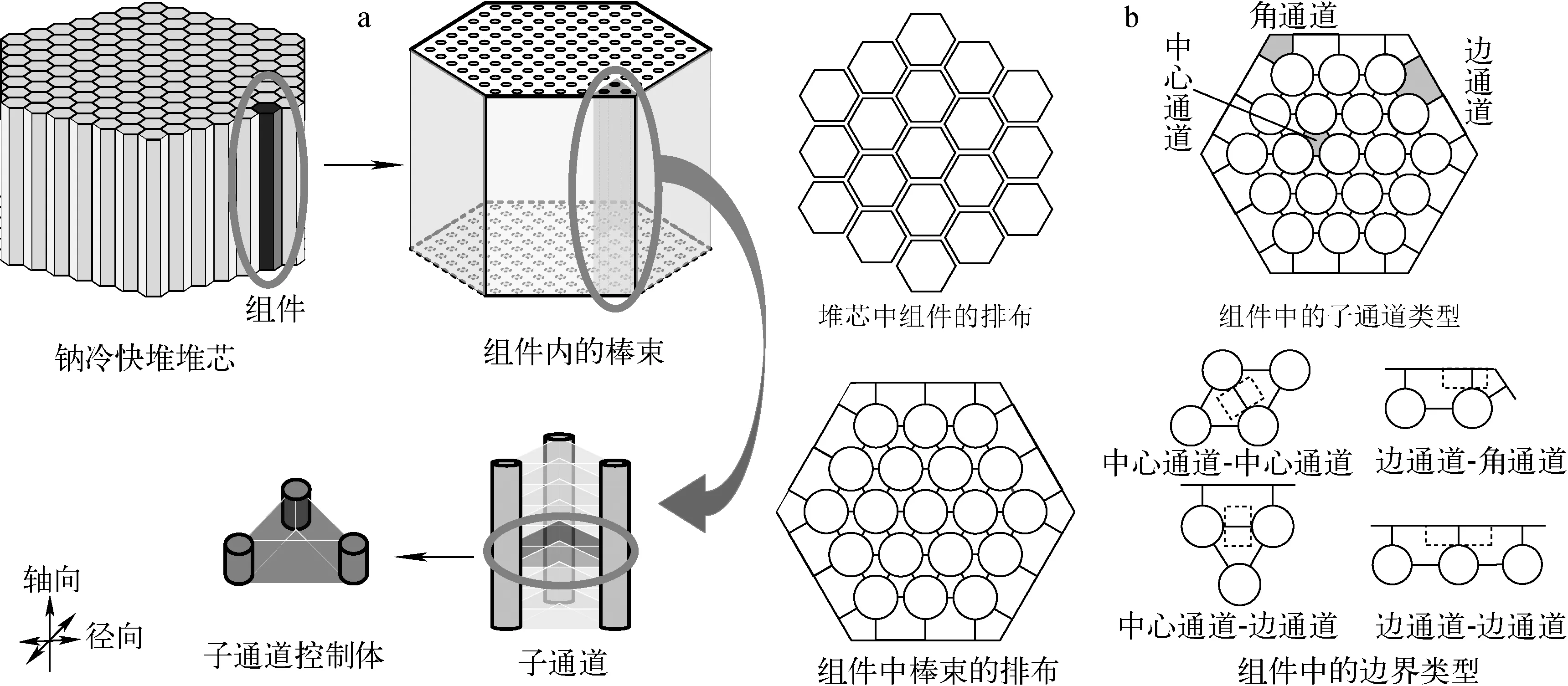
a——堆芯子通道划分;b——堆芯排布及子通道、边界类型图1 快堆堆芯示意图Fig.1 Schematic diagram of fast reactor core
1.1.1堆芯映射关系 如图1b所示,快堆组件为由若干个棒束以六角形排布组成的六角形组件,快堆堆芯由若干六角形组件按一定规则排列而成。
组件和棒束均为快堆堆芯中真实存在的实体,组件和棒束均有燃料组件/棒束、控制组件/棒束两种类型。子通道是在堆芯中人为进行划分的,快堆堆芯组件中在不同位置划分了不同类型的子通道,如图1b所示,包含组件内部类正三角形的中心通道,组件边缘处的边通道和角通道。除此之外,子通道分析方法为了模拟子通道之间流体的横向搅混,还需要在两个相邻的子通道之间划分边界。如图1b所示,根据边界相邻的两个子通道类型的不同可分为两个中心通道形成的边界、中心通道与边通道形成的边界、两个边通道形成的边界、边通道与角通道形成的边界。
对钠冷快堆堆芯的对象进行精确建模,首先需为堆芯中所有的组件、棒束、子通道和边界建立1个唯一标识,标识包括编号和类型,供后续模拟时计算机进行逐个遍历。同时由于相邻组件之间、相邻棒与子通道之间存在热量交换,在模拟时需要每个对象周围相邻的对象的信息,所以需要进一步对对象的空间关联关系进行构建,即记录每个对象周围相邻对象的编号信息。
1.1.2几何参数信息 对堆芯的几何参数信息进行描述,首先需要描述堆芯组件、棒束、子通道、边界的中心坐标,对堆芯关联关系的描述确定了堆芯对象之间空间关联关系,后续需要通过中心坐标来记录各对象在堆芯中的位置信息。确立了对象的空间关联关系和位置信息,接下来需对各对象的形状、大小等信息进行描述,这部分信息主要包括棒束的直径、子通道的湿润周长和面积、边界的长和宽。
1.2 全堆芯的并行任务划分
并行任务划分通过区域分解或功能分解等方式,将整体求解问题分解成一些小的计算任务,使得各小的计算任务能被多个进程或线程同时处理[14-15]。并行任务划分方式直接影响并行程序的可扩展性、并行效率、灵活性等性能。对于子通道模拟,并行任务划分方法需使子通道软件能部署于PC、小型服务器到超算等多种计算系统。
为解决子通道模拟的并行任务划分问题,Salko等[10]提出了将压水堆单个组件划分为1个求解域的并行任务划分方式,这种划分方式要求进程数与组件数相等,限制了软件的可扩展性和灵活性,在单机或只配置少量处理器的小型服务器中无法完成全堆芯的模拟,在拥有众多节点的超算平台上,这种固定的并行策略也难以发挥超算的计算资源优势。
文献[2]提出一种基于堆芯补全图的压水堆并行任务划分方式,此种划分方式可提供灵活的并行任务划分,可扩展性好,但本质上是将堆芯用二维数组进行描述,堆芯为六角形组件的快堆无法用二维数组去对整个堆芯进行描述,所以此种划分方法并不适合于对钠冷快堆进行并行任务划分。
为实现对钠冷快堆全堆芯进行灵活的、可扩展的并行模拟,要求并行任务划分方法既不能局限于组件数与进程数一一对应的限制,同时也应当适用于快堆六角形组件堆芯的特殊几何形状。这要求该方法能根据并行模拟可利用的计算资源提供灵活的并行任务划分结果,使得研究人员能够在PC、小型服务器以及超算等不同的计算平台上都能够完成对钠冷快堆全堆芯的模拟,充分发挥目前我国高性能计算机计算资源的优势。
2 堆芯建模与任务划分的实现
2.1 堆芯的基础结构
本文方法根据快堆的几何结构抽象出用于构建快堆堆芯映射关系的基础结构,如图2所示,主要包含组件基础结构、棒束基础结构、子通道基础结构和边界基础结构。
组件基础结构中中心六角形表示当前组件,周围6个虚线六角形表示当前组件周围的组件位置,对6个位置进行编号,存储对应位置上的组件的全局编号。
棒束基础结构包括中心棒束、角棒束、边棒束。在中心棒束基础结构中实线圆形表示中心棒束,周围6个虚线圆形和类正三角形分别表示棒束周围的棒束和子通道,对其位置进行编号。角棒束、边棒束基础结构由中心棒束基础结构变形而来,如左上角棒束基础结构是由中心棒束基础结构去掉0、1、3号相邻棒束位置和3号相邻子通道位置得到。
子通道基础结构包括Ⅰ型中心通道、Ⅱ型中心通道、边通道和角通道。子通道基础结构中的类正三角形为中心通道,中心通道周围的相邻棒束位置和相邻子通道位置编号如图2所示。需要注意的是,若当前中心通道为Ⅰ型中心通道,则其周围中心通道必为Ⅱ型中心通道。
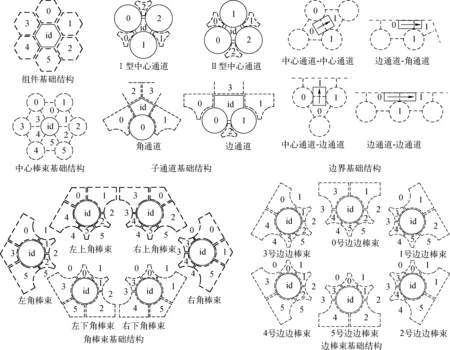
图2 基础结构Fig.2 Basic structure
边界基础结构根据边界类型分为4类,如图2所示。每个边界横跨两个子通道,有1~2个相邻的棒束,对这些相邻位置进行编号。由边界相邻的两个子通道中心点可做1个向量,向量尾部所在子通道为0号、头部为1号,0号相邻棒束位于向量左侧、1号位于向量右侧。对于向量的构建遵循两个中心通道形成的边界向量y大于0,中心通道与边通道形成的边界由中心通道指向边通道,其余情况向量顺时针构建。
2.2 基于基础结构的规则定义
为实现快堆堆芯映射关系的建立,在基础结构的基础上定义了一系列规则,具体内容如下:1) 键位,棒束基础结构中,当前棒束同周围棒束之间连接的短线段表示键位,其编号与对应的相邻棒束编号一致,此概念可以迁移至组件基础结构中;2) 对位和,中心棒束基础结构中,任意1对对角线键位编号之和均为5,即对位和为5,通过此规律可确定棒束间相对位置;3) 共位和,每一个中心通道所占据的周围3个棒束的对应子通道位置编号之和为定值,若该中心通道为Ⅰ型中心通道则该值为6,Ⅱ型则为9;4) 对边和,组件基础结构中,每对边上存在跨组件子通道-子通道关联关系的边通道与其对边之和,共3个;5) 键1~键4规则,按照由内向外逐层逐棒构建棒束-棒束关联关系的方法,每一个待插入的棒束最多与已经构建好的映射图形成4个键,按照成键次序分别命名为键1~键4;6) 键4原理,只有每层最后一个棒束的插入,才会形成键4。
2.3 堆芯映射关系的建立
快堆堆芯中的组件具有相同结构,所以在构建映射关系时为了节省计算量和存储量,通过构建组件级映射关系和堆芯级映射关系来替代对全堆芯所有组件进行详细描述。组件级映射关系描述1个组件内部棒束、子通道、边界的映射关系,单个组件的映射关系可推导出堆芯中任何1个组件内部的映射关系。堆芯级映射将组件当作1个整体,只描述组件间的关系,忽略组件内部结构。
2.3.1组件级映射关系的建立 组件级映射关系的建立负责构建组件内部的棒束-子通道映射和组件内部的边界映射。主要工作是为棒束、子通道、边界进行编号,并对其周围相邻实体进行描述。依据传统习惯对组件内部实体进行编号,从中心开始逐层顺时针编号。每层起点为中心的11点钟方向,并依据先内部子通道、后边通道、再角通道的顺序,如图3a所示。

a——61棒束组件编号结果;b——61组件编号结果图3 手动编号结果Fig.3 Manual number result
首先构建组件内部的棒束-子通道映射,构建时对棒束和子通道的编号同时进行。在最开始映射关系中没有任何实体,之后顺序插入棒束根据棒束插入的位置判断是否产生新的子通道,具体构建过程如图4a所示。之后根据组件内部棒束-子通道映射结果进行组件内部边界映射的构建。在构建时需逐层遍历每一层棒束和子通道,具体构建过程如图4b所示。至此单个组件中所有的映射关系建立完成。

a——组件内棒束-子通道映射;b——组件内边界映射图4 组件级映射关系的建立流程Fig.4 Establishment process of component-level mapping relationship
2.3.2堆芯级映射关系的建立 堆芯级映射关系的建立将1个组件看为1个整体,为每个组件进行编号,同时对组件间的关联关系进行描述,对组件的编号顺序如图3b所示。此部分建立的算法与组件级棒束-棒束映射关系的构建完全一致,前者组件基础结构对应后者中棒束的基础结构,区别在于:1) 组件数目和棒束数目不同;2) 堆芯级映射关系的建立只需建立组件-组件的映射关系。
2.4 堆芯几何参数的求解
2.4.1中心坐标求解 求解中心坐标首先需构建坐标系,本文算法使用的坐标系如图5a所示,求解组件中心坐标时为方便求解,先使用图5b所示坐标系求出局部坐标之后再转化为图5a所示坐标系下的全局坐标。求解组件中心坐标与棒束中心坐标的算法相同,均为先求解轴线上的中心坐标,再求解轴线间中心坐标,区别在于组件数目与棒束数目不同,求解时特征间距不同,组件中心坐标求解完成后需由局部坐标转换为全局坐标。图5a所示坐标系为图5b坐标系顺时针旋转30°得到,假设组件在图5b坐标系的局部坐标为(x1,y1),在图5a坐标系下的全局坐标为(x,y),则由局部坐标转换为全局坐标的公式为:

a——单组件轴线扇区;b——全堆芯轴线扇区图5 坐标系Fig.5 Coordinate system
(ρcos(θ+π/6),ρsin(θ+π/6))
(1)
式中,(ρ,θ)为由组件局部坐标(x1,y1)转换得到的组件极坐标。
以求解棒束中心坐标为例,如图5a所示,根据组件内棒束的位置划分6个轴线和6个扇区。首先按照顺时针方向,依次求解轴线上棒束中心位置坐标,具体步骤为:1) 遍历axis号轴线(若求解1、2轴线,则该轴线编号为2);2) 求解axis号轴线上layer层棒束的编号rod_id=2axis+3(layer-2)(layer-1)-2;3) 求解rod_id棒束相对于组件中1号棒束的偏移量dx=bcos((4-axis)π/3),dy=bsin((4-axis)π/3)(b为相邻棒束中心位置间距);4) 求解rod_id棒束的中心坐标(x,y)=(x0+(layer-1)dx,y0+(layer-1)dy)((x0,y0)为当前组件1号棒束坐标)。
之后按照顺时针方向,根据原点对称原则求解每个扇区棒束中心位置坐标,只需求解1、2、3号扇区棒束中心坐标,4、5、6号扇区棒束与1、2、3号扇区棒束关于1号棒束对称,按照对称原则计算即可。求解扇区内棒束中心坐标时,以棒束所处扇区两边界轴线上的同层棒束坐标为基准,根据定比分点公式求解。至此,所有组件和棒束的中心坐标求解完成。
通过相邻棒束中心坐标求解子通道中心坐标。中心子通道的坐标为3个相邻棒束中心坐标的平均值。求解边通道中心坐标,先选取参照点,如图6a所示,①、②、③为参照点,然后参照点①沿修正向量方向平移相应的距离可得待求解边通道中心坐标,具体流程为:1) 循环遍历所有边通道;2) 计算参照点①的坐标(xc,yc),值为0、1相邻棒束的中心点;3) 通过式(2)计算修正向量du(式中(xch,ych)为3号相邻中心通道的坐标);4) 计算边通道中心坐标(x,y)=(xc,yc)+Ddu/2(D为最外层棒束中心到组件边界的距离)。
(xc-xch,yc-ych)
(2)
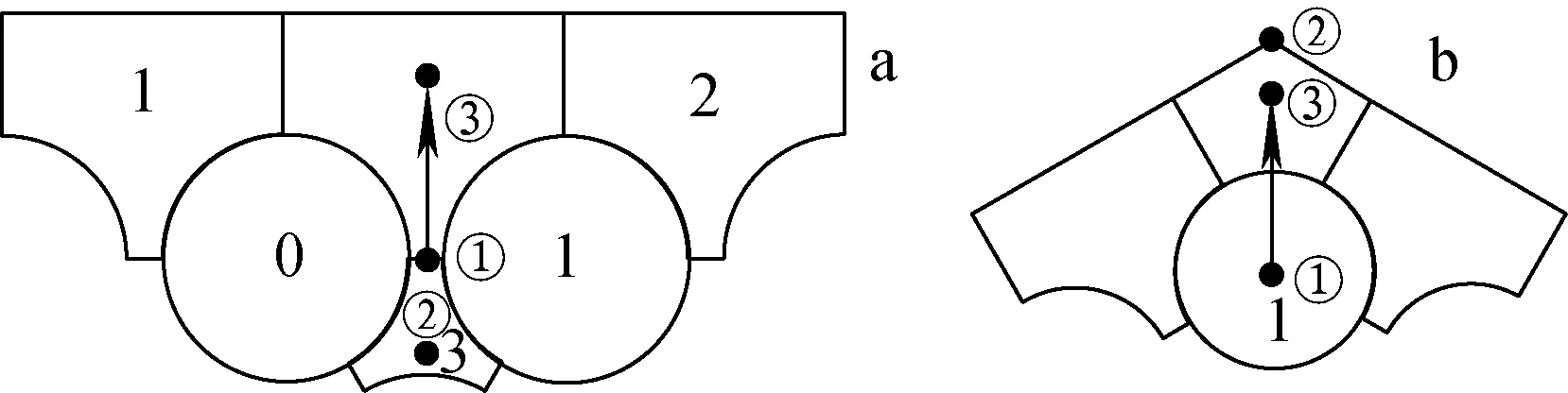
a——边通道参照点;b——角通道参照点图6 参照点示意图Fig.6 Scheme of reference point
之后求解角通道中心坐标。求解角通道坐标的方式与求解边通道坐标的方式相似,区别在于:1) 参照点的选取不同;2) 修正向量的求解不同。角通道参照点的选取如图6b所示,修正向量的求解如式(3)所示。
du=(cos((4-axis)×π/3),
sin((4-axis)×π/3))
(3)
最后求解边界的中心坐标,两个中心通道形成的边界和中心通道与边通道形成的边界中心坐标为相邻两个子通道中心位置的中点处坐标。两个边通道形成的边界和边通道与角通道形成的边界通过参照点沿修正向量方向平移得到,参照点的选取和修正向量的求解与之前相似。
2.4.2子通道湿周和面积的求解 子通道湿周和面积通过已求得的棒束中心坐标求解。假设燃料棒直径为Df,导向管直径为Dg,当前子通道3个相邻位置棒束编号为r0、r1、r2,len(r0,r1)表示r0、r1棒束中心点之间的距离,则中心通道的湿周p和面积a可用式(4)求解:
n≤3
(4)
式中,n为相邻棒束中燃料棒的个数。边通道湿周与面积通过式(5)求解,角通道的湿周与面积通过式(6)求解。
(2-n)Dg),a=Dlen(r0,r1)-
(5)
(6)
2.4.3边界长和宽的求解 最后求解边界的长和宽,通过相邻子通道和棒束中心坐标求解,设length_rod为两个相邻棒束中心点的距离,length_chan为两个相邻子通道中心点的距离,则两个中心通道形成的边界和中心通道与边通道形成边界的长length和宽width通过式(7)进行求解,边通道与边通道形成的边界和边通道与角通道形成的边界通过式(8)进行求解。
length=length_chan,
n≤2
(7)
length=length_chan,
(8)
2.5 全堆芯并行任务划分
为适用于PC、小型集群、超算等不同计算资源的计算平台,全堆芯并行任务划分分为组件级并行任务划分和堆芯级并行任务划分。
当面向超算或大规模集群时采用组件级并行任务划分,以组件中的子通道为单位进行划分,将1个组件中的子通道划分到不同的求解域中,若全堆芯共有N个组件,设定将每个组件划分为n个求解域,则最终全堆芯子通道被划分为nN个求解域。当面向PC或小型集群时采用堆芯级并行任务划分,将1个组件中全部的子通道看作1个整体,以组件为单位进行划分,若全堆芯共有N个组件,设定将n个组件划分到1个求解域,则最终全堆芯子通道被划分为N/n(向上取整)个求解域。两种级别的划分方式在算法实现上是相似的,区别仅在于在划分时遍历的实体不同。每种级别的任务划分均提供两种方法:广度优先划分方法和层次划分方法。
广度优先划分方法的思想是以组件中所有的子通道分别为根节点,以子通道的相邻子通道为子节点构建节点树,之后以广度优先遍历的方式对构建好的树进行遍历与划分,直到划分完1个组件中所有的子通道为止。划分时先划分好1个组件,之后将1个组件的划分结果应用到全堆芯所有组件即完成对于全堆芯子通道的划分,详细流程如图7a所示。
层次划分方法的思想是按照子通道的层次结构进行遍历同时进行求解域的划分。由于本身在对组件、子通道编号时就是逐层向外进行编号,仅需在每一层顺序遍历子通道即可,同时为了使通信最小化,在跨层操作时让同一个求解域的子通道尽量相邻,在跨层时进行特殊操作,详细流程如图7b所示。

a——广度优先划分方法;b——层次划分方法图7 并行任务划分流程Fig.7 Parallel task division process
3 结果分析
3.1 堆芯映射结果
对于堆芯映射结果可分为堆芯组件映射结果和单组件映射结果两部分进行。堆芯组件映射结果以61组件为例进行验证,为便于展示使用随机算法随机抽取5个组件,结果列于表1。表1中id表示当前组件的编号,sa0表示当前组件0号相邻组件的编号,以此类推。将表1中数据与图3b手动编号结果对照。单组件棒束-子通道映射结果以61棒束为例进行验证。为便于展示,通过随机算法随机抽取5个棒束,结果列于表2。表2中sr0表示当前实体的0号相邻棒束,sc0表示当前实体的0号相邻子通道,以此类推。将表2中数据与图3a手动编号划分结果对照,可验证建模结果的正确性。

表1 61组件映射结果Table 1 61 assemblies mapping result

表2 61棒束映射结果Table 2 61 rods mapping result
3.2 方法有效性测试
为验证本文方法的有效性,使用CTF[12-13]对本文方法的堆芯建模结果进行模拟。本文根据CTF需要的输入参数,参考钠冷快堆参数[16-17]设计了相应的六角形组件算例,具体参数设置列于表3。

表3 算例参数设置Table 3 Calculation example parameter setting
该算例组件1轴向层压降列于表4,因算例输入功率、热工参数为平均分布,所以压力场在每个轴向层上是平均分布的,如图8所示。由计算结果可知,CTF可正确地对算例进行模拟,可验证本文方法的有效性。

图8 堆芯压力场分布Fig.8 Core pressure field distribution
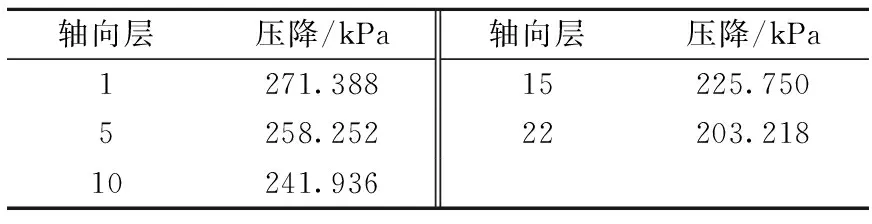
表4 轴向层压降Table 4 Axial pressure drop
3.3 并行效率测试
为验证本文方法的扩展性,在曙光先进计算服务平台上进行了可扩展性研究。由于算例规模较小,单组件中子通道个数较少,所以采用弱扩展性测试。本文设计了两种规模的算例,测试结果列于表5,两种规模算例下的并行效率如图9所示。

表5 算例规模及测试结果Table 5 Scale of calculation example and test result
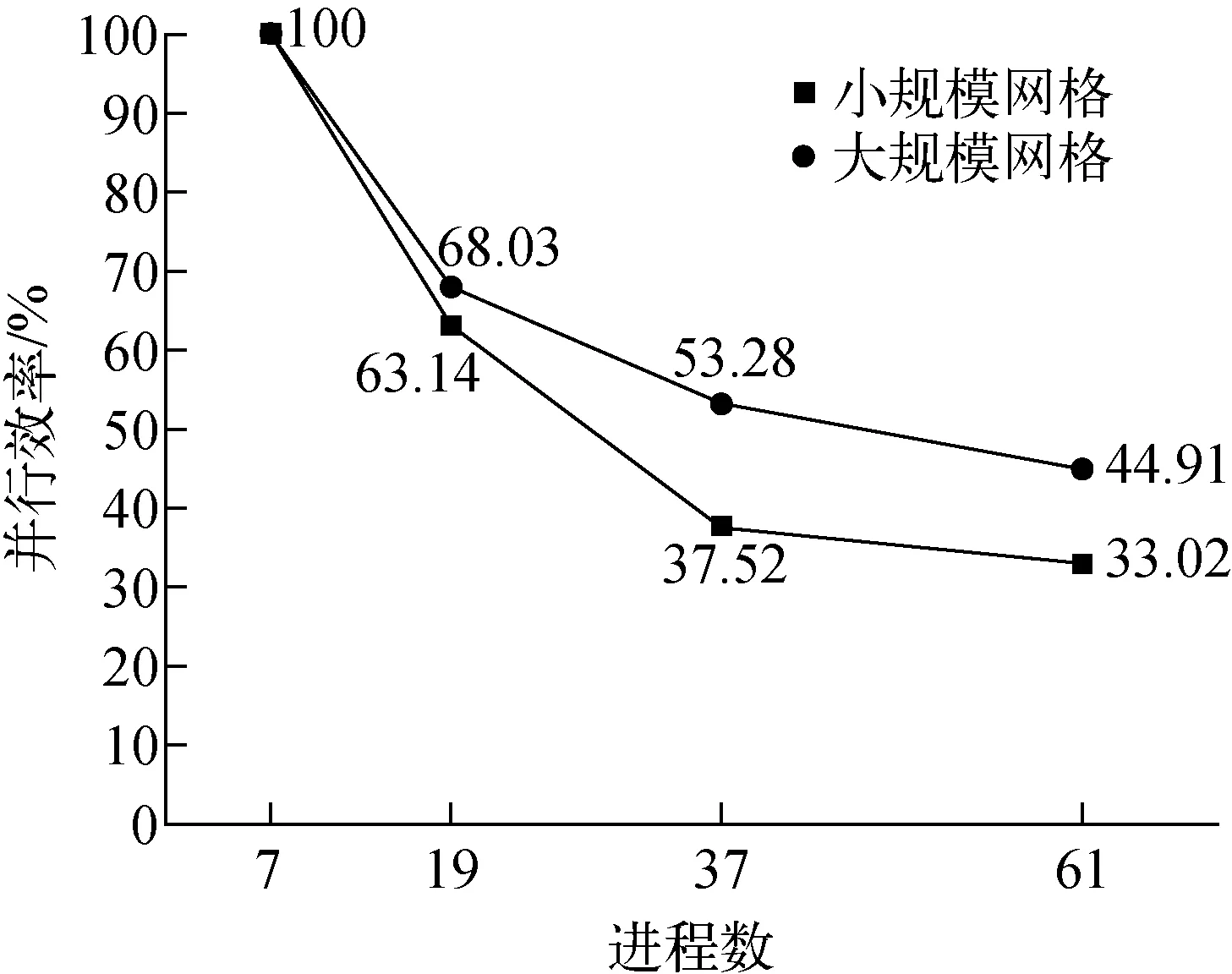
图9 两种网格规模并行效率Fig.9 Parallel efficiency of two grid sizes
在测试时保证两种网格规模的算例在不同进程数下每个进程处理的子通道控制体的个数相同(小规模每进程396,大规模每进程2 250),即每个进程的计算量大致相等。弱扩展性测试随着进程数的增加,子通道控制体的个数随之增加,同时划分的求解域/进程数个数增多会导致通信量的增加,所以在两组测试中随着进程数的增加并行效率会逐渐降低。由于大规模网格每进程的计算量更大,通信量增加带来的影响相对小规模网格更小,所以大规模网格算例并行效率下降的速度小于小规模网格算例。由计算结果可知,最终两种网格规模的并行效率均在33.02%以上,证明了本文方法扩展性良好。
4 总结
本文针对钠冷快堆全堆芯精确到每个真实流道的并行子通道模拟问题提出了一种钠冷快堆全堆芯子通道建模及任务划分方法。根据快堆堆芯的几何结构抽象出用于描述快堆堆芯的基础结构,并为抽象出的基础结构设计了对应的数据结构。在抽象出的基础结构和数据结构的基础上设计了构建全堆芯映射关系的算法,通过与手动编号映射结果进行对比验证了该方法的正确性。设计了求解全堆芯几何参数的算法,通过使用针对快堆模拟修改后的子通道模拟软件CTF对此方法处理的映射结果与参数结果进行模拟,验证了构建堆芯映射和求解堆芯几何参数方法的有效性。同时,为了在PC、小规模集群、超算等不同计算规模平台上进行并行模拟,提出了堆芯级任务划分方式和组件级任务划分方式,实现了对全堆芯子通道自适应的并行任务划分,并通过两种网格规模的算例进行了并行效率测试,最终并行效率均在33.02%以上,证明本文方法的扩展性良好。
在未来工作中将进一步改善并行任务划分方法,使得快堆子通道并行模拟的并行效率进一步提升,同时对本文方法进行并行化处理,使堆芯建模及任务划分过程更加高效。
