一种融合深度学习与协同过滤的学术论文推荐方法
2021-09-15祝婷
祝 婷
(西安工业大学图书馆,陕西 西安 710021)
学术论文是科研人员在学术研究过程中的重要知识源,然而随着大数据时代的到来,学术论文数量急剧增长,用户在论文数据库中检索论文时,往往会出现信息过载的问题。如何帮助用户从海量论文中获取所需论文,为用户提供推荐服务,对辅助科学研究具有重要意义。常见的学术论文推荐方法包括基于内容的推荐方法、基于关联规则的推荐方法、协同过滤推荐方法以及混合推荐方法,其中协同过滤推荐方法是使用最为广泛且成功的一种推荐方法。除了利用用户对论文的评分计算相似性外,论文本身的语义特征也是不可忽略的重要因素,深度学习技术可以深层次的挖掘论文的隐式特征,因此,将深度学习技术与协同过滤推荐方法相融合已成为新的研究趋势。本文首先对学术论文推荐现状和存在的不足进行了概述,然后介绍了深度学习和协同过滤技术,最后在此基础上提出了一种融合深度学习与协同过滤的学术论文推荐方法,以期为用户提供更为准确的学术论文推荐服务。
1.学术论文推荐概述
1.1 学术论文推荐现状
传统的学术论文推荐方法通常包含基于内容的学术论文推荐、基于关联规则的学术论文推荐、协同过滤学术论文推荐以及混合学术论文推荐等。基于内容的学术论文推荐是通过计算用户和学术论文的向量空间模型,然后比较两者之间的相似性,将与用户相似性较高的学术论文推荐给用户;基于关联规则的学术论文推荐是根据数据挖掘算法获取用户浏览论文数据库生成强关联规则,用户在检索、浏览或下载论文时与强关联规则进行匹配,将匹配的学术论文推荐给用户;协同过滤学术论文推荐是通过用户-论文评分矩阵计算用户之间的相似性,生成目标用户的近邻用户,将近邻用户感兴趣的学术论文推荐给目标用户;混合学术论文推荐方法是为了克服以上推荐方法的缺点,融合其优点,将多种推荐方法相结合形成新的混合推荐方法,与单一推荐方法相比具有更好的推荐效果。
1.2 学术论文推荐存在的不足
基于协同过滤的学术论文推荐未与深度学习技术进行相融合。利用协同过滤技术进行学术论文推荐时,主要是依据用户对学术论文的评分进行推荐,这种推荐方法虽然可以满足用户的基本需求,但是没有对学术论文的语义特征进行分析,致使学术论文推荐的准确度不高,推荐效果不够显著。实际上,除了获取评分数据之外,分析论文本身的语义特征对于学术论文推荐也是至关重要的,论文的语义特征反映了一篇论文的核心内容,而用户是否对某篇论文感兴趣,本质上也是根据论文的核心内容进行判断。常见的学术论文特征提取方法为一种浅层学习方法,该方法无法深层次挖掘学术论文的隐式特征,在一定程度上也限制了推荐的准确性。因此,目前传统的协同过滤论文推荐方法在根据用户评分数据进行推荐时,尚未考虑到深层次的学术论文隐式特征,致使推荐服务不能真正发挥作用,进一步影响用户体验。
2.相关理论
2.1 深度学习技术
深度学习作为机器学习研究领域的一个重要方向,已成为人工智能和大数据发展的热潮,目前已广泛应用于自然语言处理、图像处理、语音识别、机器翻译等领域[1]。它将低层特征通过组合形成更稠密的高层抽象表示,进而实现对数据的复杂特征表示,在这个过程中,避免了传统的机器学习方法中人工构建特征带来的一些问题。随着大数据时代的发展,用户面对的数据更多的是多源异构、复杂多样、无规律的数据,传统的浅层学习方法无法处理这些数据,这种场景下,深度学习方法便显得尤为重要。常见的深度学习方法包括自编码器、受限玻尔兹曼机、卷积神经网络、循环神经网络、深度信念网络等。
2.2 协同过滤技术
协同过滤是目前应用最为广泛的一种个性化推荐方法,它的核心思想是相似的用户具有相同的兴趣爱好。协同过滤推荐方法分为基于用户的协同过滤推荐方法和基于项目的协同过滤推荐方法[2]。基于用户的协同过滤推荐是指在用户-项目评分矩阵中计算用户间的相似性,获得目标用户的近邻用户,然后使用近邻用户的评分来预测目标用户对未评分项目的评分,最后根据预测评分的大小对其推荐。基于项目的协同过滤推荐方法是指在用户-项目评分矩阵中计算项目间的相似性,根据项目相似性预测用户对未评分项目的评分,将预测评分较高的项目推荐给用户。
3.融合深度学习与协同过滤的学术论文推荐
本文在协同过滤推荐的过程中引入论文内容信息,提出一种融合深度学习与协同过滤的学术论文推荐方法。首先,在论文数据库中获取论文数据,如题名、摘要、关键词等,将其向量化表示作为深度学习模型的输入,输出论文的隐式特征表示,在此基础上计算论文间的相似性s1;然后,获取用户行为数据产生用户-论文评分矩阵,通过该矩阵计算论文间的相似性s2;最后,结合以上两种相似性生成最终的论文相似性,根据其相似性大小对用户进行推荐。整个学术论文推荐流程如图1 所示。
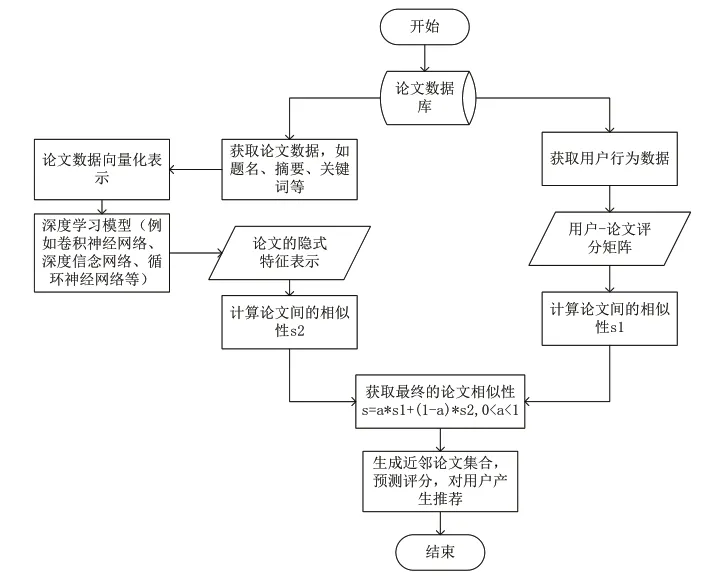
图1 学术论文推荐流程图
3.1 基于深度学习的学术论文特征表示
利用深度学习技术进行学术论文特征表示主要分为以下三个步骤:
3.1.1 数据预处理
首先从论文数据库中爬取论文数据,如题名、摘要、关键词等,对其进行合并操作;然后对合并后的文本进行分词及去停用词,并且规范文本为统一长度,小于统一长度使用0 进行填充,大于统一长度进行截断;最后计算文本中每个词的TF*IDF 值,对其进行排序,选取前n 个词组成词汇库,将每个文本即论文转化为这些词的集合。
3.1.2 向量化表示
由于深度学习模型无法直接处理词或文本,本文使用斯坦福大学已经训练好的语料库GloVe(6B,400K个词汇,包含50、100、200、300d 维的向量表示)来对本文的词进行向量表示,最终可将论文表示为,其中pi 表示论文,表示论文中第n 个词,⊕表示拼接操作。
3.1.3 论文隐式特征表示
将第二步生成的向量作为深度学习模型(可选择卷积神经网络)的输入,首先通过卷积层进行特征提取,可表示为,其中*代表卷积操作,Kj为卷积核,bj为偏置项,f 表示激活函数;然后通过池化层进行维度降低,可表示为;最后通过全连接层汇总组合特征信息,可表示为Z=Z1⊕Z2⊕ …⊕Zn。因此,论文的隐式特征最终表示为y=f(W*Z+b),其中W 为全连接层的权值矩阵,b 为偏置项。
3.2 基于协同过滤的学术论文特征表示
协同过滤论文推荐方法是根据用户对学术论文的评分对其进行特征表示。评分一般分为显示评分与隐式评分,显示评分是指用户对论文进行主动打分,分值一般为0-5,分值越高表明用户对论文的感兴趣程度越高,反之感兴趣程度越低,0 表示用户没有对该论文进行评分。隐式评分是将用户在论文数据库中检索、浏览、下载论文时的行为数据进行转换形成的评分数值。例如用户浏览一篇论文的时间越长代表对其越感兴趣,对应评分数值越高。无论是显示评分还是隐式评分,最终可将每个用户对论文数据库中每篇论文的评分表示为用户-论文评分矩阵,某篇论文获得每个用户的评分即评分矩阵的列向量则为该论文的特征表示。
3.3 融合深度学习与协同过滤的论文相似性计算
获得学术论文的特征向量表示之后,接下来需要计算学术论文间的相似性。常见的相似性算法包括相关相似性、余弦相似性以及修正的余弦相似性[3]。在基于深度学习的学术论文特征表示和基于协同过滤的学术论文特征表示的基础上,使用相似性算法分别计算论文间的相似性,将其表示为s1 和s2,然后加权两者生成最终的论文相似性s=a*s1+(1-a)*s2,(0<a< 1)。
3.4 学术论文推荐
根据加权后的论文相似性数值生成论文相似性矩阵,选取与目标论文较为相似的前k 篇论文作为近邻论文,其集合可表示为nei,则用户i 对论文j 的预测评分可表示为
4.结语
大数据时代背景下学术论文数量急剧增长,为用户提供更精准的论文推荐服务是未来研究发展趋势。本文将深度学习技术与协同过滤推荐相融合,在协同过滤推荐过程中计算论文相似性时,引入基于深度学习的论文相似性,通过加权两种相似性对用户产生推荐。
