语音驱动弗格森曲线合成嘴唇动画
2021-09-15张净波杨元维蒋梦月杜李慧
张净波 杨元维 徐 杰 蒋梦月 李 鹏 杜李慧
(1.长江大学地球科学学院 武汉 430100)(2.中国石油管道科技研究中心 廊坊 065000)(3.中国石油天然气集团公司油气储运重点实验室 廊坊 065000)
1 引言
迄今,国内外的许多学者一直致力于研究出一种实时、自然、逼真的嘴唇动画。Terry基于新型贝叶斯网络模型法确定视素和音素信息[1],实现语音驱动模型生成嘴唇动画。文献[2]基于Bernstein-Bézier曲线与唇部运动规律通过构造函数的方法描述动态视位,通过该方法合成的动画相对真实、自然,但当语速较快时易发生跳变。肖叶清等采用肌肉控制模型模拟口型动画,但未考虑到汉语协同发音的特点[3]。Moro等基于神经网络法将声学的特征参数和人脸动画匹配,提出了一种自动克隆的会说话的虚拟人的方法[4]。范鑫鑫等依据输入的语音信号提出了一种嘴唇同步算法,该算法具有较高的准确率和重用性[5]。文献[6]基于HMM(Hidden Markov Model)建立了用于语音音素分类与用于情感分类的层次结构,并实现了语音驱动表情。文献[7]通过改进的最小转换轨迹误差训练对语音特征参数以及口型特征参数同步的方法进行了相关研究,实现了语音驱动口型动画。王跃根据汉语具有协同发音的特点,提出了一种基于汉语协同发音的文本驱动三维口型合成动画,使生成的动画更接近真人的口型[8]。
口型动画的研究虽取得了不少成果,但仍然存在两点问题,其一是MPEG-4标准中提供的嘴唇特征点数量不足,导致合成的嘴唇动画轮廓不自然;其二是语音与动画的映射关系不能做到在时间上完全匹配。针对以上存在的问题,本文提出基于弗格森函数添加特征点的方法,并基于声母韵母建立语音和动画映射,采用线性插值的方法保证语音和动画在时间上同步。其设计思想如图1所示。
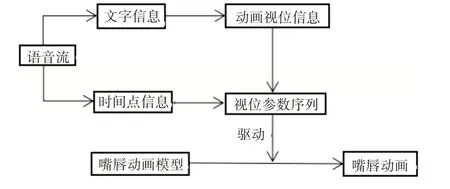
图1 动画生成流程
2 语音信息的提取
语音信息包含语音的文字信息和语音的时间信息。语音的文字信息即语音的内容,本文通过调用百度接口识别出目标段语音包含的文字序列;语音的时间信息指的是单个文字播放时的时间点,本文采用语音端点检测技术获取单个汉字在语音段中的时间片段。
2.1 基于百度接口提取语音文字
百度语音识别接口运用基于多层单向(Long Short-Term Memory,LSTM)的汉语声韵母整体建模技术,并把连接时序分类(Connectionist Temporal Classification,CTC)训练技术嵌入到传统识别建模的框架中,再结合语音识别领域的区分度训练、跨词解码、决策树聚类等技术[9],可以较为理想地实现语音识别。百度将深层卷积神经网络(Deep Convolutional Neural Networks,DCNN)模型与LSTM、CTC结合,降低了语音识别解码的计算量,减少了人为干预。引入了DCNN的概念,使模型在时频域上具有很好的平移不变性,提高了模型抗噪性,错误率相对下降10%,提高了语音识别的性能[10]。
2.2 基于语音端点检测的语音分割
语音端点检测是语音信号处理中的一个重要环节,用来检测语音段中文字间出现的短暂停顿点。将短时能量(Short Term Energy)和短时过零率(Short Term Zero Crossing Rate)结合分析是语音端点检测技术常用的方法[11],本文采用该方法进行语音分割。
一帧语音信号的能量称为短时能量,第n帧短时能量定义为

其中,Qn表示第n帧的短时能量,N表示第n帧中包含的音频采样数量,Sn表示第n个采样的取样值[12]。
一帧语音信号中的信号波形正负号变化的次数称为语音信号的过零率,第n帧的短时过零率定义:
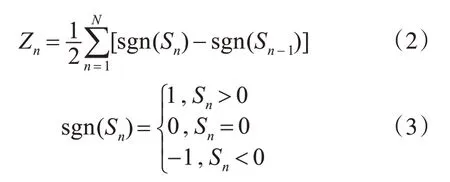
其中,Zn表示第n帧的短时过零率,N表示信号帧长,Sn表示第n个音频的采样值,sgn()表示符号函数,将式(3)带入式(2)中即可得到第n帧的短时过零率。
语音端点检测技术的基本思想是[13]为短时能量与短时过零率分别确定两个门限值,一个为较低的门限值,对音频信号变化相对敏感;另一个为较高的门限值。当高门限值被超过且在接下来的一段时间内低门限值始终被超过,则表明语音信号开始。
例如,对“长江大学欢迎您”这一段语音进行切割,结果如图2所示。
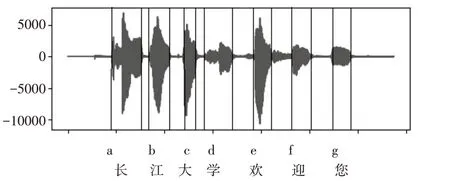
图2 语音分割情况
3 基于弗格森函数刻画嘴唇
弗格森函数是由多段的三次多项式拼接而成的[14],在拼接位置处,不仅函数自身是连续的,而且其一阶导数,二阶导数,曲率也是连续的。因此该函数最大限度的保证了曲线的平滑、连续。
嘴唇动画的生成需要建立相应的特征点。MPEG-4标准中提供的人脸特征点定义参数(Facial Definition Parameters,FDP),如 图3所 示。MPEG-4标准中指定的特征点过于稀疏,不能较为准确地刻画嘴唇运动的诸多细节,需增加特征点的数量以保证动画的真实性。本文将MPEG-4中定义的特征点作为控制点,建立弗格森函数,基于已有特征点的函数关系来增加特征点数量。
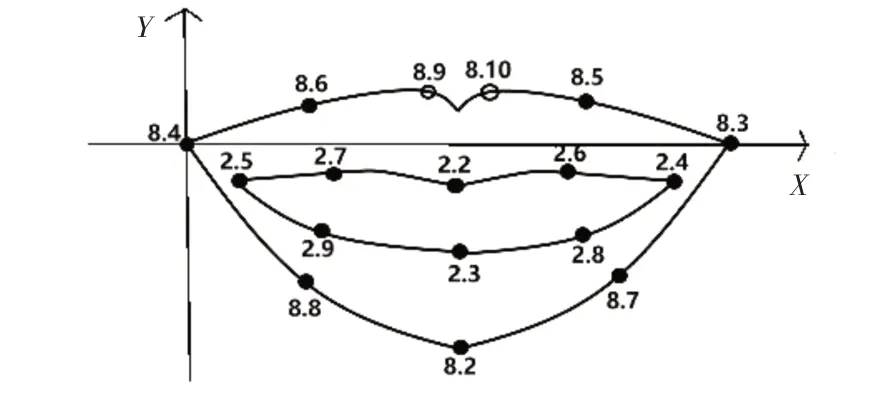
图3 MPEG-4特征点坐标系
本文以左侧嘴角为原点建立的平面直角坐标系,图3中将MPEG-4中的特征点划分为4组,分别为:1)上唇外侧2)上唇内侧3)下唇内侧4)下唇外侧。每组由5个特征点组成(其中嘴角处的特征点上唇下唇共用)。嘴唇在张合运动过程中,各组中各点纵向运动幅度△y存在着相关性。用照相机在说话人的正面对嘴唇进行连续照相,为降低个体嘴唇差异的影响选取了若干名说话人,每个人都发相同的音,对应MPEG-4标准中指定的特征点,计算每个特征点由嘴唇不发音位置到发音位置的位移变化量,取其平均值作为最终的运动比例系数△y,最终得到各个特征点纵向位移变化量(xj,△yj),(j=1,2,…,16)。由每组的5个特征点作为控制点建立弗格森函数,共计建立四组函数。
基于上述求得的函数,确定了特征点纵向位移变化量与横坐标的映射关系,只要输入任意位置的横坐标即可获得该位置纵向位移变化量△y,因此基于该函数可无限增加特征点的数量。综上,本文建立嘴唇特征点运动模型:

其中li(i=1,2,…,n)表示嘴唇曲线运动过程中特征点纵坐标,yi为嘴唇闭合时特征点的纵坐标,△yi表示运动比例系数。R为视位参数(R∈[0,5])。再将所有的特征点用弗格森曲线连接绘制出嘴唇轮廓,通过不断改变R的值即可模拟出整个发音过程嘴唇的动画。本文基于声母韵母建立了语音与动画的映射关系,该映射关系定义了声母韵母对应的视位参数R,具体的定义方法将在下一节中介绍。
4 基于声母韵母语音动画的映射
本文首先基于拼音的声母韵母对语音进行划分,再对划分后的声母韵母建立相应的视位参数。获取视位参数的具体方法:用相机正对说话人的嘴唇照相,计算MPEG-4中指定的特征点在每一个声母韵母的视位坐标(xi,li),参考式(4)及预先定义的运动比例系数△yi获取视位参数R。最终视位参数结果如表1所示。
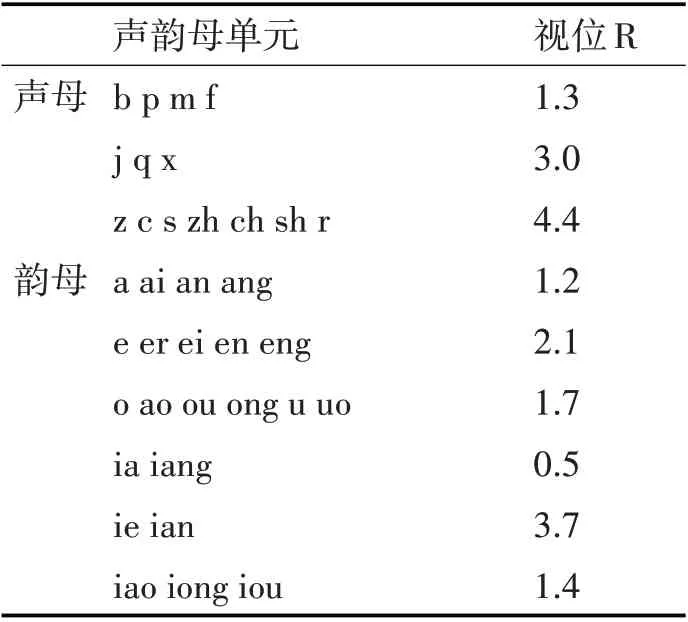
表1 声母韵母视位分类结果(部分)
5 基于线性插值的视位参数过渡
基于声母韵母建立语音与动画的映射的方法获得了视位参数,该视位参数为关键帧的视位参数,而发音动作是连续过程,因此需要在关键帧之间做视位参数的过渡处理[15]。本文基于协同发音中的音素影响因子计算音素发音时刻,然后基于音素发音时刻采用线性插值的方法过渡处理视位参数,保证语音和动画在时间上的同步。
在嘴唇动画中,当前发音的口型除了受当前发音的音素影响外,还受到该音素前后音素的影响。在汉语中元音处于影响地位,辅音处于被影响地位[16]。音节控制模型[17]中定义了元音的影响等级,并给出了量化的影响值,如表2所示,影响等级从1级到4级逐渐递减。影响等级越高(影响因子越大),越容易影响其他音素[18]。
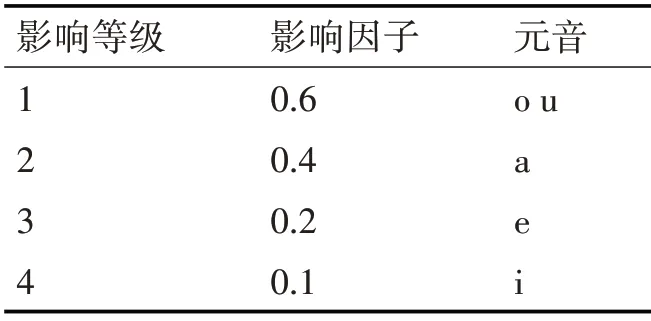
表2 音素影响等级表
影响因子描述了音素间彼此的影响程度,结合音节控制模型计算每个文字中的音素开始发音的时间点,公式如下:
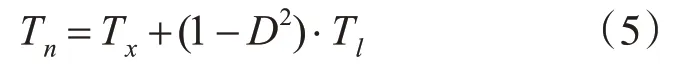
其中Tn表示该文字中第n个音素开始发音的时刻,Tx表示第x个文字的开始时刻,Tl表示该文字发音的持续时间。D表示前一音素对当前音素的影响因子。通过该方法算出语音中每个音素的发音开始时刻。
为了实现任意时刻的动画帧与语音流的同步匹配,本文将关键帧视位参数做线性插值处理生成过渡帧视位参数。过渡帧视位参数插值算法公式如下:
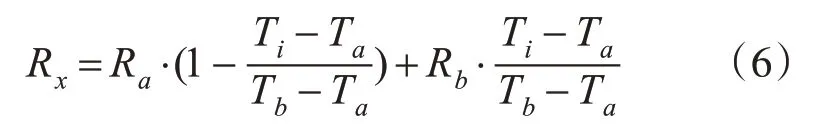
其中Ti表示第i帧动画发音时刻,Rx表示Ti(i∈[a,b])时刻的视位参数,Ra、Rb表示前后关键帧的视位参数。Ta、Tb表示前后关键帧的发音开始时刻。结合式(5)、(6)中即可得到Ti时刻的视位参数。
6 实验及结果分析
6.1 实验设计
为验证本文提出方法的正确性,本文设计三组实验如下。
实验一用无噪声的语音驱动嘴唇曲线,分别测试不同语速条件下生成的嘴唇动画的准确率并对结果加以进行分析。
实验二用“美好长大”四个字的语音驱动嘴唇动画,将本文方法合成的嘴唇动画与真实口型对比,观察对应动画与真实口型的相似度。
实验三将本文方法分别与文献[19]自定义添加特征点法、文献[20]基于唇部子运动与权重函数法生成的嘴唇动画的准确率对比,并对结果进行分析。
6.2 实验评价标准
1)实验一、三评价标准
在发音内容及语速相同的情况下,测量真人嘴唇特征点位移Vreal(i),考虑到个体差异性,取n个人正常发音的嘴唇位移的平均值作为Vreal。计算Vreal与动画嘴唇特征点位移Vanim之差△V,△V与Vreal之比作为动画误差。即:
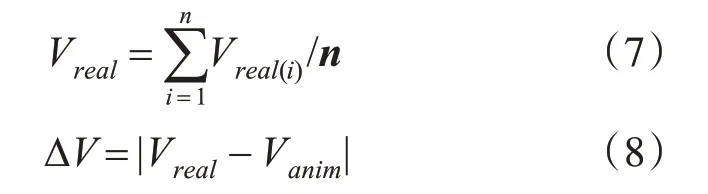
综上,结合式(7)、(8)最终评价准确率标准:
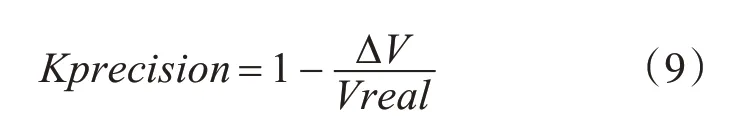
2)实验二评价标准
本实验从嘴唇开合大小、嘴唇形状、是否有病态口型(如嘴唇出现不合理的凹凸)三个方面对嘴唇轮廓效果进行评价。
6.3 实验结果与分析
1)实验一结果如表3所示。
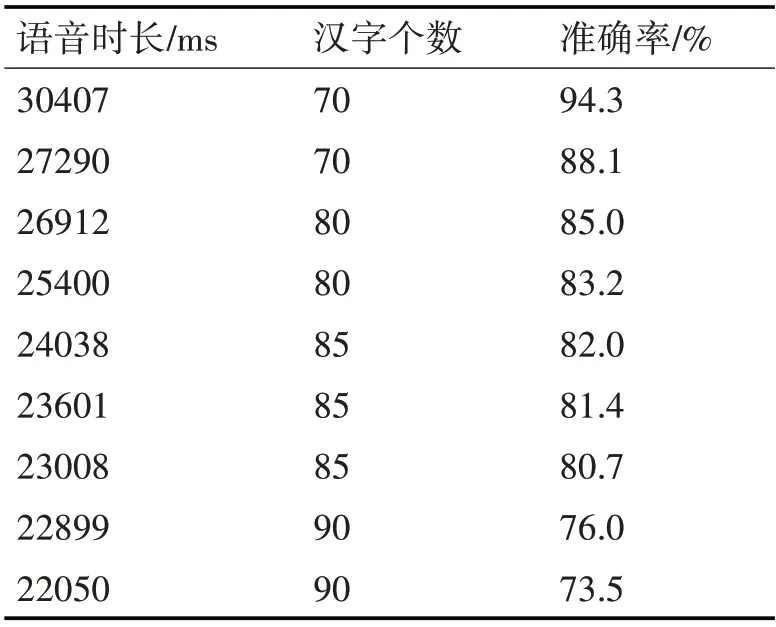
表3 实验结果
由表3可知动画同步匹配准确率的降低趋势大致和语速增加成反比。本文中定义的语音与动画的映射关系不随语速的变化而变化,根据弗格森曲线绘制的嘴唇曲线特征点坐标不随语速的变化而变化,因此导致该情况的发生的主要原因有两个。
(1)当语速加快时语音自身的模糊性会提高,百度语音识别接口的语音模型、声学模型算法的强健性有限,因此识别的偏差会导致动画视位参数序列出现误差。
(2)当语速过快时,语音短时能量与短时过零率变化幅度过小,使分割出现误差,导致动画分配的时间偏差,最终出现动画与时间不同步匹配。
2)实验二结果如图4所示。
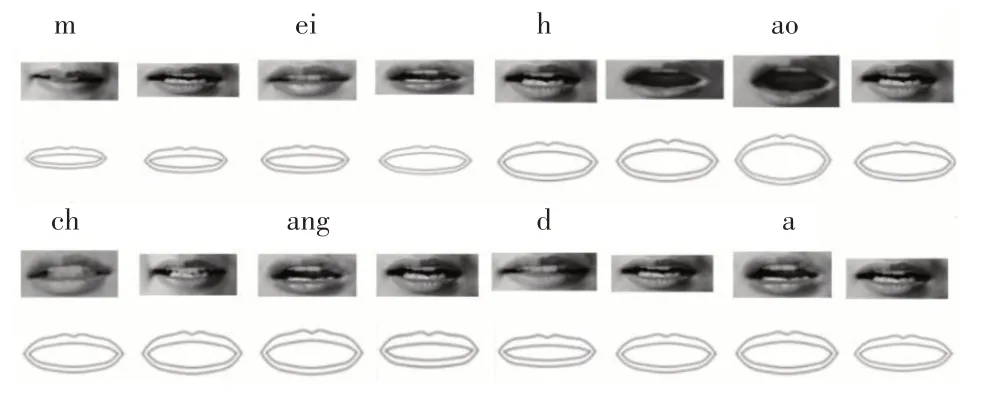
图4 真实口型与本文方法合成的口型动画对比图
与真人的嘴唇图片对比发现,通过本文方法绘制的嘴唇曲线无病态口型,与真实口型相比并未失真,嘴唇开合大小基本与真人保持一致。主要原因如下:
(1)基于弗格森曲线绘制的嘴唇最大限度地使嘴唇曲线曲率变化连续,凹凸程度变化连续,避免出现不自然的凹凸等错误状态。
(2)基于线性插值的方法对口型进行过渡,如“美”,“好”两个字过渡阶段嘴唇直接从“ei”的口型过渡到“h”的口型;而当单独发“h”的音时,嘴唇动作为从闭合到张开。该方法符合人们正常说话时的状态。
(3)本文基于声母韵母建立了语音和动画的映射,通过调节视位参数直接控制了嘴唇开合的大小,保证了嘴唇动画的真实性。
(4)基于弗格森函数从特征点纵向位移变化量的角度定义了各个特征点的位移量之比,再结合嘴唇动画模型从根本上避免了病态口型的出现。
3)实验三结果如表4所示。

表4 实验结果
结果表明,基于函数关系添加特征点法较自定义添加特征点法生成的动画准确率更高。主要原因如下:
(1)文献[19]在原有的MPEG-4特征点的之间自定义添加特征点及特征点上下位移量,人为因素过多导致误差增大;自定义特征点的数量有限,对于细节较多的嘴唇无法真实刻画。
(2)文献[20]建立的权重函数未充分考虑语速对口型的影响;单独的子运动造成了唇部运动缺少真实感,特别是降低了辅音受后接元音的影响。
(3)本文基于MPEG-4特征点建立弗格森函数,可基于函数关系添加数量较多的特征点,使嘴唇轮廓更加逼真;基于函数关系建立了特征点的运动模型,符合嘴唇运动的规律。
7 结语
本文融合了百度语音识别、语音端点检测、弗格森曲线驱动嘴唇动画等方法,完成了语音驱动嘴唇动画的全过程,并且生成的嘴唇动画与语音有良好的匹配效果。在功能的实现过程中,本文基于嘴唇的运动特点,建立了动画模型,嘴唇轮廓在变化过程中光滑,无病态口型出现。然而嘴唇动画的实现是一个复杂的过程,所涉及的变量过多,如语速与嘴唇开合程度的关系,语音大小与嘴唇形状的关系。因此如何将这些变量科学的融合在一起将是我们接下来研究的内容。
