卷积神经网络中SPReLU激活函数的优化研究*
2021-09-15吴婷婷许晓东吴云龙
吴婷婷 许晓东 吴云龙
(江苏大学计算机科学与通信工程学院 镇江 212013)
1 引言
随着信息爆炸引发“大数据”时代的到来,海量的文本信息也随之而来,如何从这些浩瀚的文本信息中提取出有价值的文本信息并分类,以及如何提高这些文本信息分类的准确性已成为目前的研究热点和难点。
传统文本分类模型聚焦在特征提取和选择[1]上,常用方法有TF-IDF、词频、互信息等。也有学者认为利用文本的语义信息可以更好地进行文本分类,于是使用语义词典来提取特征并分类[2]。近年来,深度学习(Deep Learning,DL)逐渐发展,深度神经网络(Deep Neural Network)尤其是卷积神经网络(Convolutional Neural Networks,CNN)[3~4]作为近几年来图像处理和语音识别中的研究热点[5],在自然语言处理(Natural Language Processing,NLP)的各个任务中也都取得了显著效果[6]。因此,学者们的研究重心转移到了基于深度神经网络的分类模型上[7]。
深度神经网络文本分类模型[8~9]的性能优越,CNN模型的研究工作受到了学者的高度重视。随着研究的不断深入,学者们发现CNN模型中存在一些问题,例如,CNN模型本身比较复杂,建模过程存在一定难度;由于某些激活函数具有特殊的性质,导致了CNN模型在训练过程中容易出现梯度消失[10]、神经元死亡[11]、均值偏移[12]、收敛速度慢、稀疏表达能力弱等问题[13]。
为了解决上述问题,本文分析研究了几种常用激活函数的特性,并综合ReLU、PReLU、Softplus三种激活函数的优缺点,提出了一种新型激活函数SPReLU。最后,建立基于CNN的文本分类模型,在MR数据集上进行实验,对比这几种激活函数对文本分类模型的准确率和损失函数的影响。
2 常用激活函数及其特性
激活函数是深度神经网络的一个重要特征,它为神经网络提供了非线性建模能力,使网络能够更好地模拟数据特征,从而解决较为复杂的问题;同时,在反向传播过程中,通过激活函数的误差梯度来调整权重和偏置。神经网络中单个神经元的工作机制[15]如图1所示。计算公式为
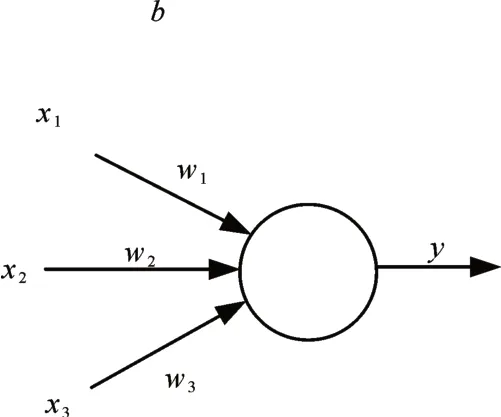
图1 单个神经元的工作机制
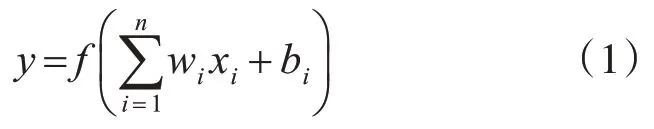
其中,f为激活函数,w为权重,b为偏置。
2.1 Sigmoid激活函数
Sigmoid[14]激活函数是一种光滑连续并且单调递增的S型函数,其数学形式为

Sigmoid函数具有以下特性:首先,函数的值域为0到1,其输出范围有限,输出结果更加稳定,可以用作模型的输出层;其次,该函数的数学表达式简单,求导更加容易。然而,由于Sigmoid函数具有软饱和性,在定义域内处处可导,当x轴无限趋向于正无穷或负无穷时,函数的斜率几乎为0,这种特性造成了梯度的消失;由于该函数是非零均值,影响了梯度的下降,导致了CNN模型在训练时不收敛。
Sigmoid函数图像如图2所示。
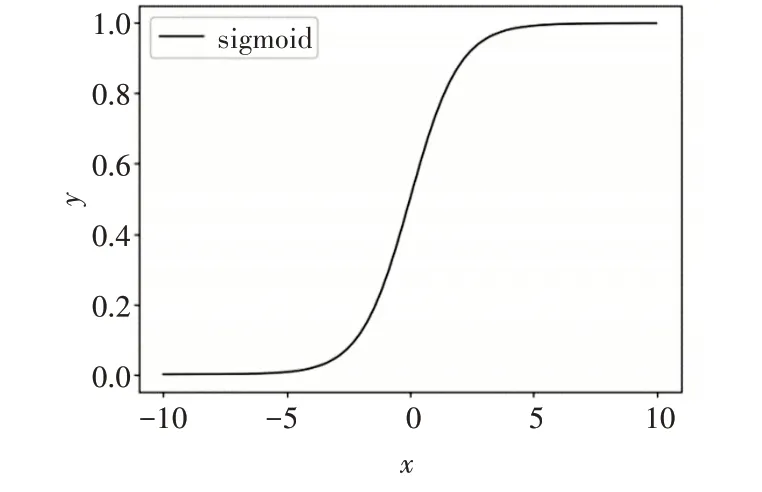
图2 Sigmoid函数图像
2.2 Tanh激活函数
Tanh[16]激活函数是对Sigmoid函数非零均值缺点的改进,输出结果以0为中心,使得模型的收敛更加快速。其数学形式为
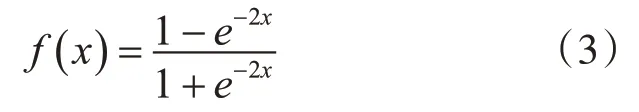
Tanh激活函数虽然对Sigmoid进行了一定的改进,提高了其收敛速度,但是却没有改变Sigmoid函数中由于软饱和性而造成的梯度消失问题。
Tanh函数图像如图3所示。
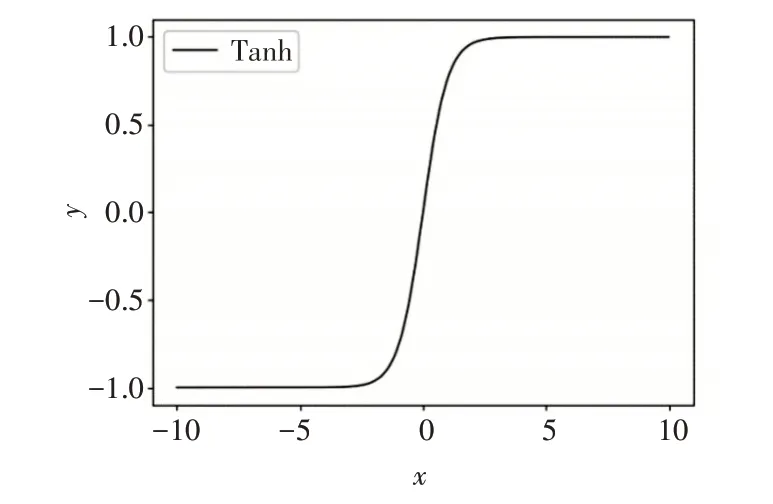
图3 Tanh函数图像
2.3 ReLU激活函数
ReLU[17]激活函数是目前最受学者们欢迎的一种修正型激活函数,它有效地缓解了“S”型激活函数梯度消失的问题,然而却依然存在均值偏移的缺点。其数学形式为

当x≥0时,ReLU函数的输出结果与输入相同,其斜率始终为1,有效地解决了梯度消失的问题;当x<0时,函数硬包和[18],输出结果强制变为0,梯度也始终为0,一定程度上给CNN模型带来了稀疏特性,缓解了过拟合问题;然而,正是由于这种特性,也导致了神经元死亡现象的出现,使得计算的结果不收敛,权重无法更新。
ReLU函数图像如图4所示。
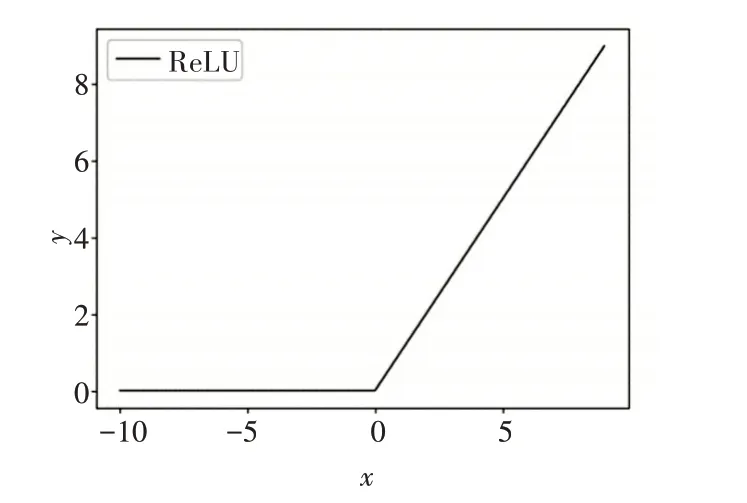
图4 ReLU函数图像
2.4 PReLU激活函数
PReLU[19]激活函数是对ReLU函数的改进,它对负半轴进行修正,有效缓解了神经元坏死问题。其数学形式为
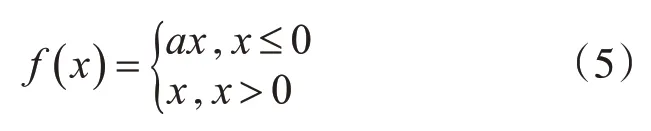
在大于0部分,输出保持与输入相同;小于0部分,其输出结果随参数a的变化而变化。然而,由于其的线性修正特性,使得模型在表达能力上有所欠缺。
PReLU函数图像如图5所示。
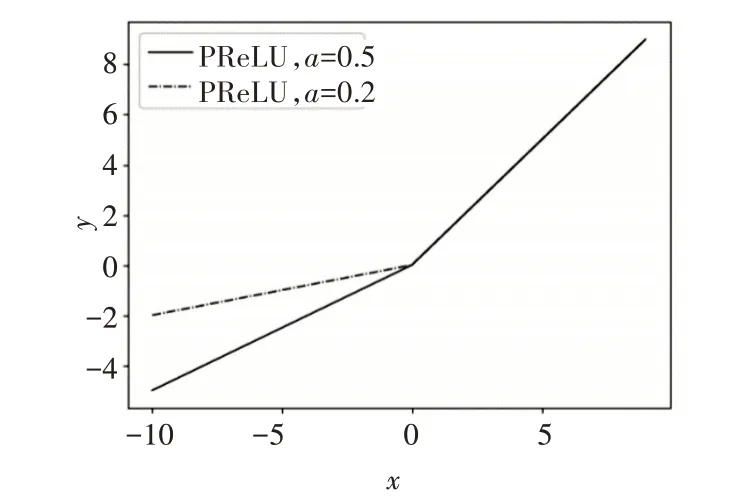
图5 PReLU函数图像
2.5 Softplus激活函数
Softplus[20]激活函数的数学形式为

Softplus激活函数与Sigmoid和Tanh函数相比,能够快速收敛;其次,该函数图像光滑,符合生物神经元特征,可以更好地模拟神经元工作特性。然而,与ReLU和PReLU相比,该函数欠缺稀疏表达能力。
Softplus函数图像如图6所示。
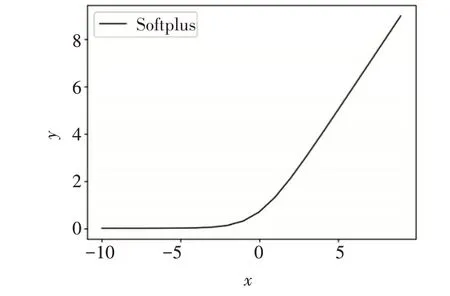
图6 Softplus函数图像
3 改进后的激活函数SPReLU
3.1 SPReLU改进方法
综合ReLU、PReLU和Softplus的特性,本文提出了一种新的激活函数SPReLu,其数学形式为
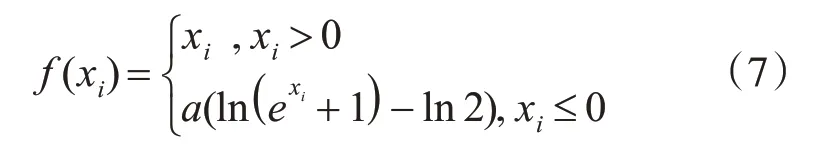
其中,a为随机参数,根据模型实时训练发生变化,最终收敛为适宜的常数。
该函数具有以下特性,当x≥0时,保留了Re-LU的线性特点,输出结果与输入数据保持不变;当x<0时,将Softplus函数的曲线下移ln2个单位,取负半轴曲线并乘上参数a。
SPReLU函数的图像如图7所示。
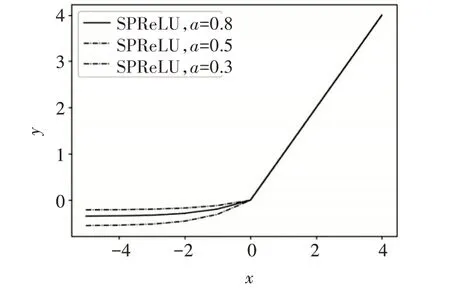
图7 SPReLU激活函数图像
其中,参数a有效地控制了函数的饱和范围,它可以通过反向传播进行训练,并与其他层同时进行优化。某一层ai的梯度为
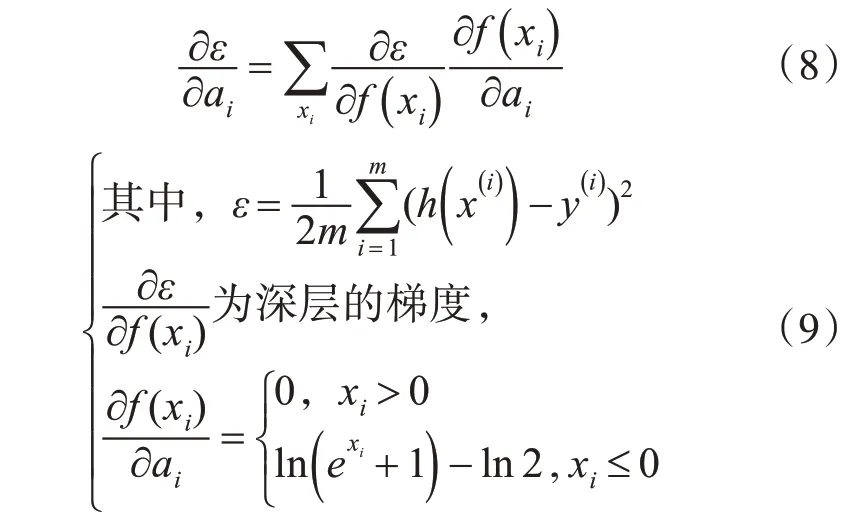
更新ai时采用动量法:
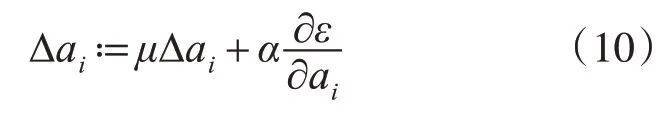
其中,μ是动量系数,α是学习率。
3.2 SPReLU函数性能分析
改进后的SPReLU函数,同时继承了ReLU、PReLU和Softplus函数的优点,主要包含以下几个方面。
1)正半轴继承了ReLU函数,保留了ReLU函数快速收敛的特点,解决了梯度消失的问题。
2)负半轴继承了Softplus的光滑的特性,非线性修正了负半轴数据,增强了CNN模型对样本数据的表达能力;一些负轴的值得以保存,较好地解决了ReLU函数神经元死亡的问题;负半轴增加了参数a,用参数激活函数代替无参数激活函数,有效地控制了函数的饱和范围。
3)最后,与PReLU函数相比,SPReLU函数增加了指数函数,增强了模型的抗噪声能力。
任何改进都不可能做到完全没有缺陷,改进后的SPReLU函数也存在一些不足:
1)相比ReLU函数,SPReLU函数稀疏表达能力在一定程度上降低了。
2)负半轴的指数函数虽然增强了抗噪声能力,但是,与ReLU和PReLU函数相比,增加了模型计算的复杂度。
4 实验结果和分析
4.1 实验环境及数据集
在实验中,采用64位的Windows 8操作系统,基于TensorFlow 1.11.0框架,在PyCharm上进行编码和调试,最后在TensorBoard中展示结果。
为了验证采用SPReLU激活函数的卷积神经网络模型在文本分类中的效果,本文在MR数据集上进行实验。MR数据集是Rotten Tomatoes的Movie Review数据,文件大小为20k,包含10662个句子,一半正面评论一半负面评论,本文使用其中90%的句子进行模型训练,并使用10%的句子模型验证。实验重复进行三次,最终取三次实验结果的平均值作为分析对比的数据。
4.2 实验结果分析
本实验分别使用Sigmoid、Tanh、Softplus、Re-LU、PReLU和SRPeLU几种激活函数进行训练和验证,对比分析各个激活函数对CNN模型分类的准确率和损失函数的影响。
实验结果的准确率曲线和损失函数曲线分别如图8和图9所示。
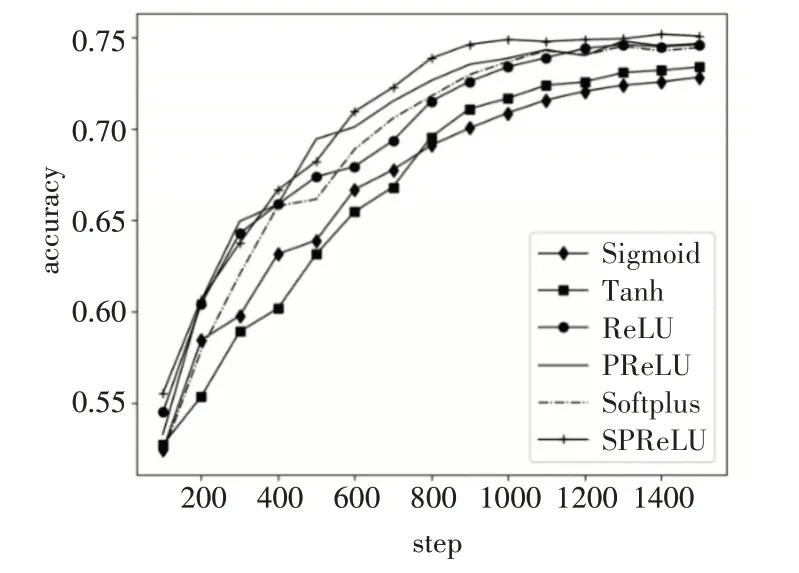
图8 准确率曲线图
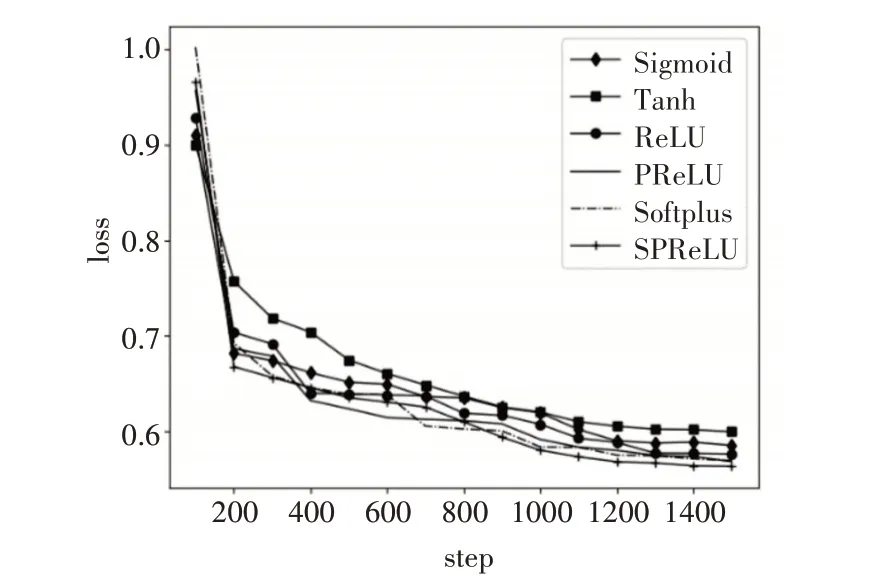
图9 损失函数曲线图
几种激活函数最大准确率和最低误差结果如表1所示。
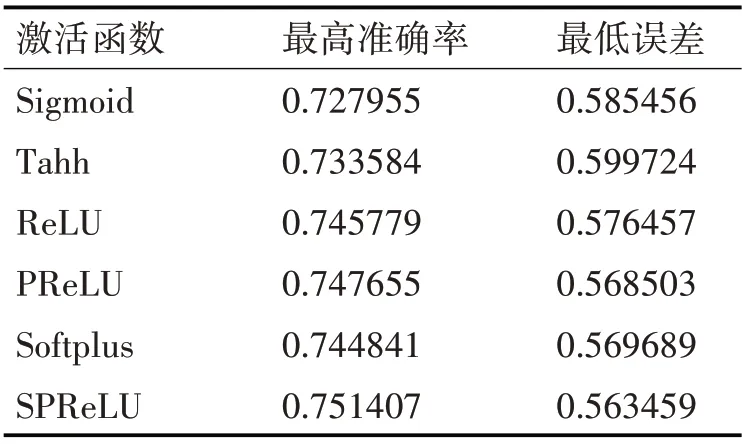
表1 最大准确率和最低误差结果
从图8和图9和表1可以看出,随着Step的不断增加,几种激活函数的准确率逐渐增大,损失函数逐渐减小,最后趋于平缓,准确率基本保持在0.70~0.75之间,损失函数在0.6~0.55之间。由于Sigmoid和Tanh函数本身的饱和特性,导致损失的特征较多,使得这两种函数在准确率和损失函数上都不如其他几种激活函数;Softplus、ReLU和PRe-LU三种激活函数的准确率和损失函数都相差不多;而改进后的SPReLU激活函数在实验中的准确率最高为0.751407,损失函数结果最低为0.559。
在实验过程中,Sigmoid和Tanh函数收敛最慢,前500步左右,PReLU函数的收敛速度相对较快,500步之后,SRPeLU函数的收敛速度逐渐提高,说明负半轴增加的指数函数,提高了模型的抗噪声能力,使得收敛速度加快,最终使得SRPeLU函数收敛最快。因此,相较于常用激活函数,改进后的SRPeLU激活函数结合了几种常用函数的优点,在文本分类中取得了较好的结果。
5 结语
本文针对卷积神经网络出现的梯度消失、均值偏移、稀疏表达能力差等问题,分析常用激活函数特性,并结合ReLU、PReLU、Softplus三种激活函数的特性,构造了一种新型分段函数SPReLU作为激活函数,该函数有效地缓解了梯度消失和神经元死亡等问题,收敛速度快,抗噪声能力强,对样本数据的表达能力更好。实验结果表明,改进后的SPRe-LU函数在性能上优于其他函数,对文本分类模型的准确性有一定的提高。下一步研究工作将对数据集的大小、收敛速度与准确率之间的关联性进行研究,在不同的数据集上进行实验,验证其关联性。
