一种抵制对等性攻击的(p,θ)k-匿名模型*
2021-09-15符精晶许晓东
符精晶 许晓东
(江苏大学计算机科学与通信工程学院 镇江 212013)
1 引言
互联网的发展势如破竹,带来了数据的海量增长,大数据时代已经到来。政府、企业等机构在信息化过程中累积了大量的个人数据,这些数据为大数据分析、价值挖掘及信息共享提供了十分有利的资源条件,成为了一种高价值的资产。但是这些数据资源往往涉及个人敏感信息,在对外进行数据发布时,若不经处理直接发布原始数据,极易造成隐私泄露。因此,信息安全领域当前的一个研究热门即是隐私数据脱敏技术,其关键问题在于如何均衡隐私数据安全性及数据可用性。
经过国内外学者的大量研究,目前大致形成了三类隐私保护技术[1]:数据加密,数据失真以及数据匿名化。其中,数据匿名化的通用性强,且能同时兼顾数据的可用性和隐私性,因此其在数据发布的隐私保护中应用最为广泛。
Sweeney[2]等在2002年就已经提出了经典的k-匿名模型,该模型将原始数据表进行分类匿名化处理,使数据表中的每一条记录至少有k-1条与其在准标识符上完全相同的记录,有效地抵制了攻击者的链接攻击(linking attack)[2]。然而,k-匿名没有考虑敏感属性取值的多样性,无法抵御同质攻击等。2006年,Machanavajjhal[3]等针对k-匿名的缺陷,提出了l-diversity模型,该模型保证数据表中每一个等价类的敏感属性至少有l个不同的取值,从而使得被发布的数据表具备抵御同质攻击的能力。同年,Traian TM,Bindu V[4]提出p-sensitive k-匿名模型,在k匿名的基础上,要求每个等价类中不同的敏感属性取值至少为p个,以此确保各等价类中敏感属性的多样化。2007年,Li[5]等提出了t-closeness模型,该模型指定每个等价类中敏感属性值的分布与原始数据表中的分布情况要尽可能的接近。2012年,吴英杰[6]等基于k-匿名算法,利用取整划分函数来划分等价类,减小了等价类的最大规模,优化了等价类平均规模的上界。2017年,王静[7]等针对多敏感属性,为用户进行个性化的敏感数据保护。
目前基于k匿名模型,研究者从匿名组划分、个性化隐私保护、敏感属性约束等多个角度进行了优化,并在不同的环境中取得了一定的效果[8],但仍然存在以下问题:1)对敏感属性的约束大多是通过约束其在等价类中的出现频率及种类个数,没有考虑到敏感属性的等级分类及权重;2)对准标识符和敏感属性之间可能存在的关联关系没有进行深入研究。因此,在p-sensitive k-匿名模型的基础上,本文加入了敏感属性的等级分类,并引入互信息量的概念,提出针对对等性攻击的(p,θ)k-匿名模型,以提高数据发布中隐私信息的安全性。
2 p-sensitive k-匿名模型
2.1 相关概念
给定一个数据表T(ID,QI,SA),ID、QI、SA为三类不同的属性。
1)显标识符(Identifier Attribute,ID):能够唯一确定个体身份的属性,如姓名、身份证号等[9];
2)准标识符(Quasi Identifier Attribute,QI):可以通过联接外部表来推测出个体身份的属性,如年龄、性别等;
3)敏感属性(Sensitive Attribute,SA):涉及到个体不想公开的个人隐私数据的属性,如薪资、疾病等。
定义1(等价类)对于数据表T(ID,QI,SA),等价类是数据表T中具有相同QI取值的所有记录的集合,这些记录在QI上的属性值是不可区分的[10~12]。
定义2(k-匿名)给定数据表T,若表T中每一条记录至少有k-1条与其在QI上完全相同的记录,则称该数据表满足k-匿名。
表1是待发布的原始数据,其中姓名为显标识符,{年龄,性别,邮编}为准标识符,疾病为敏感属性。
表2为表1进行k=2的匿名化后的数据表,经准标识符泛化后形成了3个等价类,每个等价类中除了敏感属性以外的所有属性取值均相等。
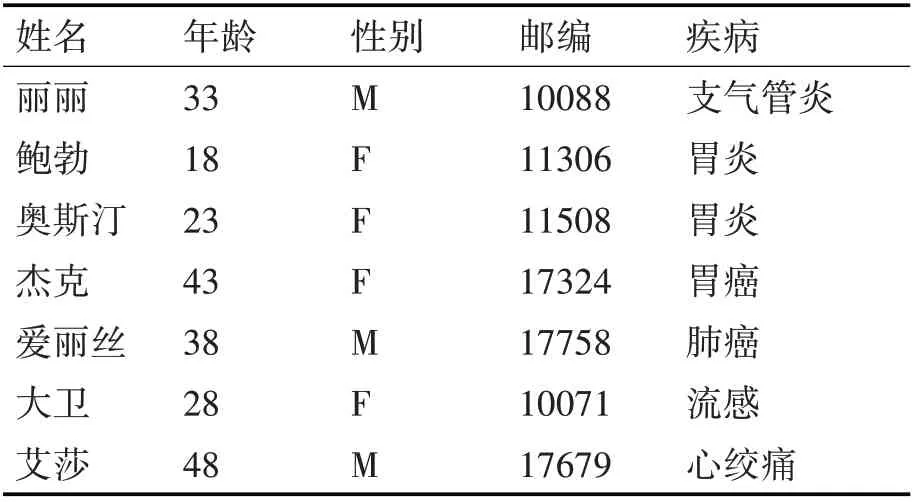
表1 原始数据表
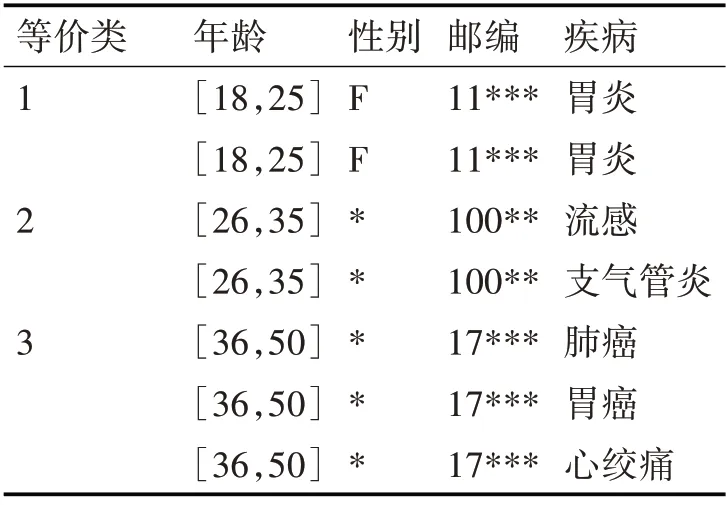
表2 表1经过2-匿名处理后的数据表
若攻击者已知奥斯汀的年龄及邮编,即可推断出他在等价类1中,又因为等价类1中的两个元组具有相同的敏感属性取值,进而可以确定奥斯汀患有胃炎,即遭受了同质攻击。为解决此类问题,可使用p-sensitive k-匿名模型。
定义3(p-sensitive k-匿名)[13]若数据表T满足k-匿名,且T中每个等价类不相同的敏感属性值至少有p(p≤k)个,则称T满足p-sensitive k-匿名。
表3为表2进行p=2、k=2匿名化后的数据表,对元组进行了重新分组和准标识符的重新泛化,解决了同质攻击的问题。
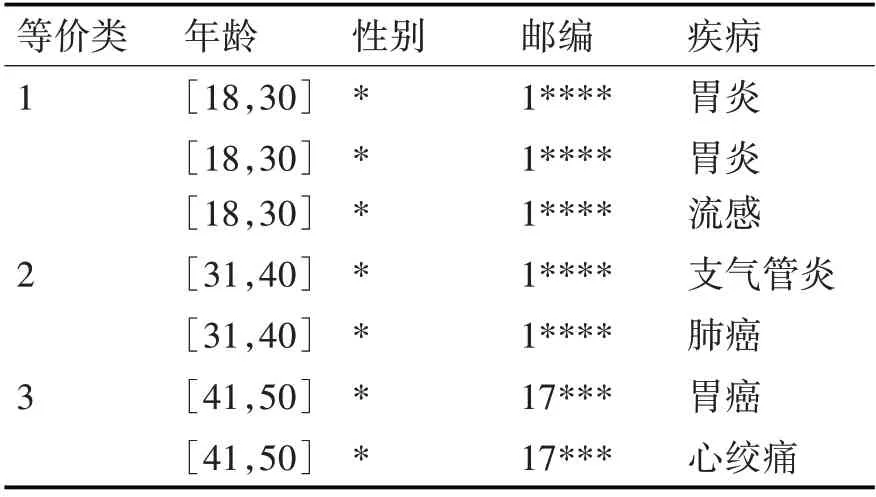
表3 表2经过2-sensitive 2-匿名处理后的数据表
2.2 p-sensitive k-匿名模型的缺陷
虽然p-sensitive k-匿名增加了各等价类中敏感属性值的多样性[14],却仍易遭受对等性攻击。
定义4(对等性攻击)[15]经k-匿名化处理后的数据集T中,某个等价类里所有记录的敏感属性取值的重要程度相同的情况下所遭受的攻击行为。
在表3中,若攻击者已知杰克在等价类3中,则无论是胃癌还是心绞痛,攻击者都能推断出杰克得了比较严重的疾病,即对等性攻击。
3 改进的(p,θ)k-匿名模型
针对p-sensitive k-匿名模型易遭受对等性攻击的问题,本文事先对敏感属性SA进行等级划分,并引入敏感属性权重因子θ对其进行约束,从而减少同种等级SA的取值在同一等价类中出现的频率。此外,本文引入互信息量公式来定量计算准标识符与敏感属性间的关联度,并将其作为对准标识符进一步泛化的依据,从而为数据发布的安全性再添一道屏障。
3.1 相关定义
1)敏感属性值的等级分类
将敏感属性SA按照取值的敏感程度的不同进行等级分类,用D(Lev)表示敏感属性等级值的值域。如表4,将八种疾病进行等级分类后,Lev表示敏感等级,其值越大则敏感级别越高。此时,“疾病”属性所对应的D(Lev)={1,2,3,4}。

表4 敏感属性等级值
定义5(敏感属性层次树)树ST是一棵高度为h的树,从上到下的层次依次为1,2,…,h。叶子结点代表具体的敏感属性值,其上的每一层父结点都是对子结点的泛化。同时规定第h层的所有叶子结点按照敏感等级由小到大排列。如图1,即为疾病的敏感属性层次树。最底层叶子结点为具体的疾病名称,往上则是对不同种类疾病的泛化。
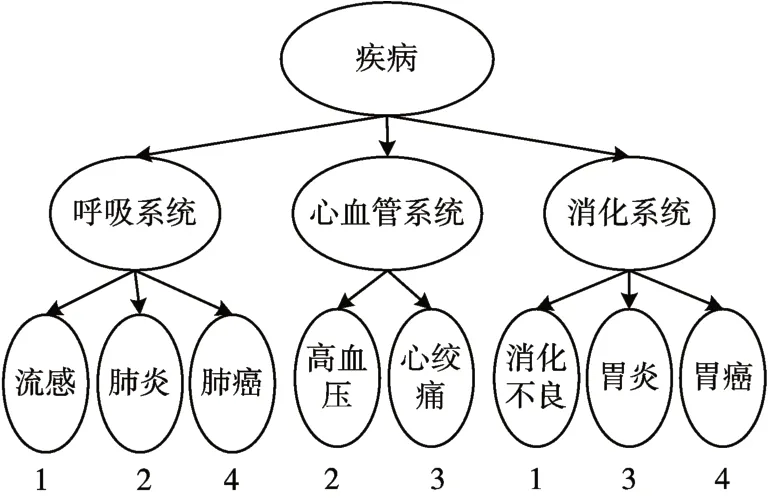
图1 疾病敏感属性层次树
定义6(敏感属性真子树)[15]对于高度为h的敏感属性层次树ST,第i层结点的子结点本身加上该子结点的所有子结点所组成的树,称为第i层结点的真子树。
2)敏感属性权重因子θ
定义7(θ分布约束)给定数据集T、敏感属性SA,若在T中的所有等价类R中,敏感属性等级为Lev的记录频率不超过θ,则称T满足θ分布约束。θ为敏感属性权重因子,由数据发布者指定。
定义8((p,θ)k-匿名)给定数据集T和等价类R,若T满足k-匿名,且每个R中至少存在p(p≤k)个不同的敏感属性值,同时每个R中所有的敏感属性取值符合θ分布约束,则称T满足(p,θ)k-匿名。
表5为加入了敏感属性等级值的原始数据表。表6是表5经过(p,θ)k-匿名(p=2、θ=0.5、k=2)处理后的数据表,表中同一种等级的敏感属性值在同一等价类中出现的频率不超过50%,很好地抵御了对等性攻击。
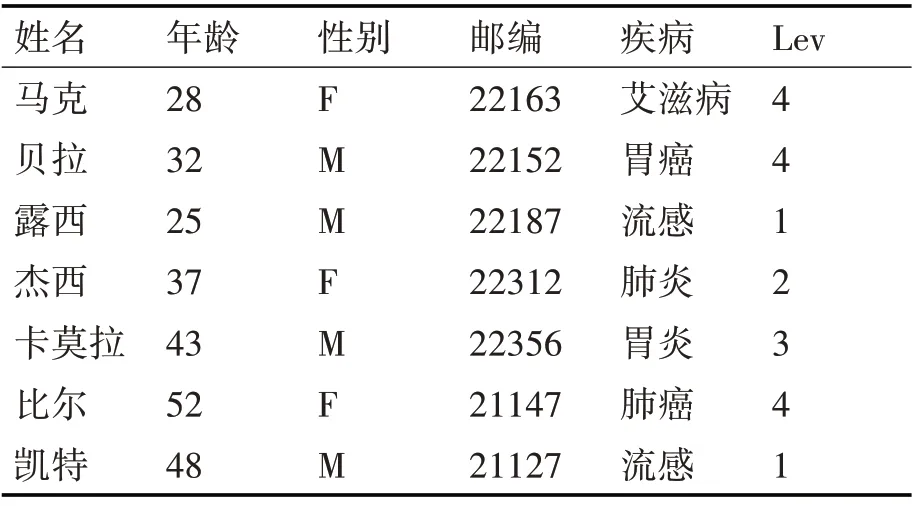
表5 加入敏感属性等级值的原始数据表
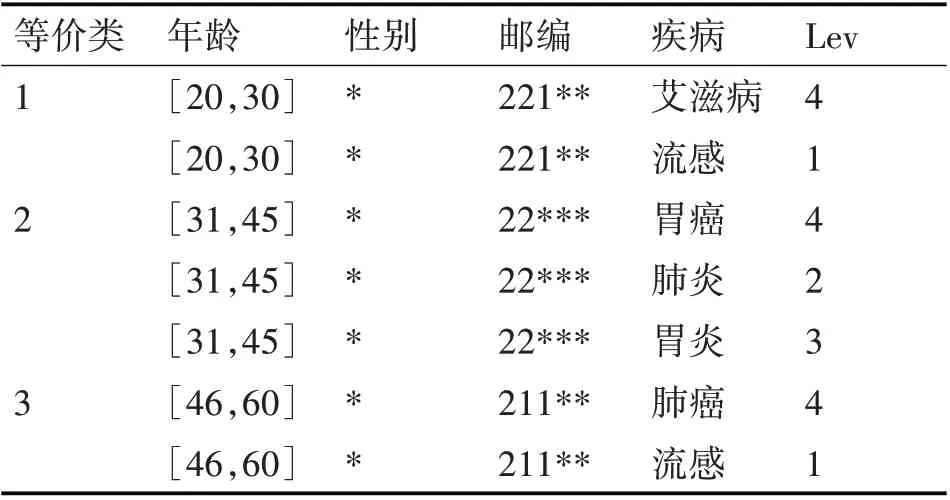
表6 表5经过(2,0.5)2-匿名处理后的数据表
3)互信息量
θ分布约束只对敏感属性的分组排布进行了控制,忽略了准标识符与敏感属性之间可能存在的关联关系,因此本文利用互信息量以定量关系对准标识符进一步泛化。
定义9(互信息量)表示两个事件之间的相关性。本文中是指对于数据集T中的两个属性X和Y来说,当已知其中一个属性的取值集合,另一个属性不确定性减小的程度。属性X与Y的关联度(互信息量)计算公式为
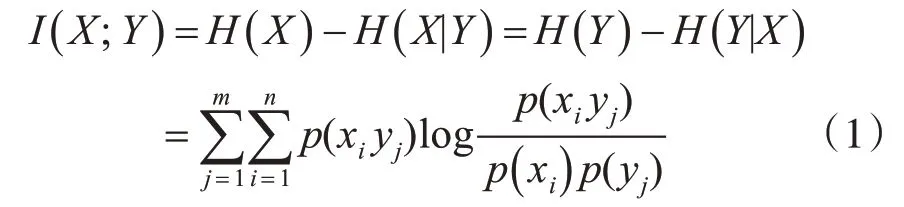
其中H(X)为X的信息熵,其计算公式为
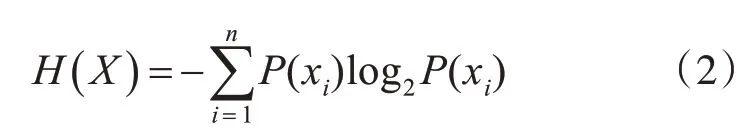
H(X|Y)为条件熵,即已知属性Y的情况下属性X的不确定性,其计算公式为

3.2 算法过程描述
1)元组距离计算公式
(1)数值型属性的距离[16]
给定数据集T,对于数值型属性A,元组ti、tj在A上的取值分别为ti(A)、tj(A),则ti、tj在属性A上的距离公式为
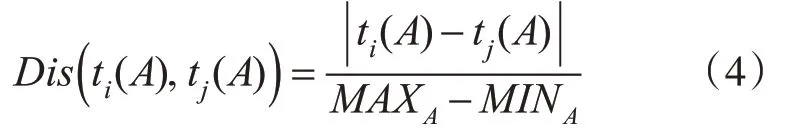
其中,MAXA代表T中数值型属性A所取得的最大值,MINA代表A所取得的最小值。
(2)分类型属性的距离
给定数据集T,对于分类型属性C,元组ti、tj在C上的值分别为ti(C)、tj(C),Tc是分类型属性C的属性泛化树,H(Tc)表示泛化树的高度,∧(ti(C),tj(C))表示ti(C)和tj(C)以泛化树中最小公共祖先为根的子树[18],则元组ti、tj在分类型属性C上的距离公式为
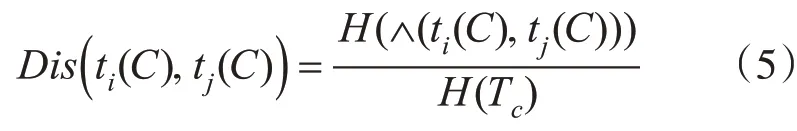
2)敏感属性等级差
定义10(敏感属性等级差)数据表中任意两个元组Ai、Aj的敏感属性等级差为D Lev=|Lev(Asi)-Lev(Asj)|,其中Lev(Asi)为数据表中第i个元组的敏感属性值对应的等级。
3)属性泛化树
定义11(属性泛化树)对于准标识符QI,其值域为Z(Z为有限集)[17],则其属性泛化树为映射函数f:TQI→Z。树中叶子结点为该属性在数据表中各个具体的取值,中间结点为各个层次的泛化值,根结点为最终泛化值。图2是“年龄”属性的泛化树。
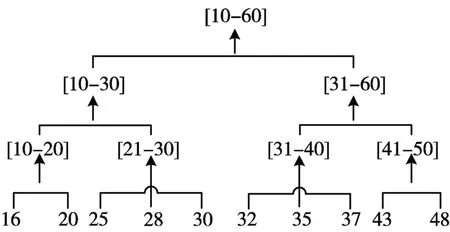
图2“年龄”属性泛化树
4)(p,θ)k-匿名算法的过程描述
输入:原始数据表T,准标识符个数n,匿名参数k、p、θ
输出:满足(p,θ)k-匿名的最终匿名表T"
步骤:
(1)建立敏感属性层次树,将各敏感属性所对应的元组存储至相应的真子树中,并将第一层的m棵真子树按包含敏感属性值的元组个数降序排列,假设真子树集合按降序排列为LT={LT1,LT2,…LTm},初始化等价类集合R={};
(2)选取LT第一个元素的第一条元组A作为初始等价类的质心,按元组个数由多到少从其余m-1棵真子树中,选择与质心按距离升序、D Lev降序(距离为主关键字)排序后的前k-1条元组,与质心构成初始等价类r={A,A1,A2,…,Ak-1}(元组距离用式(4)或式(5)计算,敏感属性等级差用定义10中的公式计算);
(3)计算初始等价类r中各敏感属性等级的频率,若满足θ约束,则最终划分为一个等价类;反之,继续选择记录。将划分好的等价类并入R中,并将其对应元组在原始数据表中删除;
(4)重复执行上述(2)、(3)两个步骤,当整个数据表T已不能形成新的满足(p,θ)k-匿名约束的等价类时停止执行,并将剩余元组插入到与其距离最近的等价类中,将等价类集合R转换成初步匿名数据表T';
(5)对初步匿名表T',计算其所有准标识符Q1、Q2、…Qn与敏感属性SA的互信息量(用式(1)计算);
(7)准标识符泛化完成后,生成最终匿名表T''。
3.3 算法度量指标
1)信息损失量[18]
(1)数值型属性
对某一数值泛化后的区间i,标记其左端点为Li,右端点为Ri。标记该数值属性整个值域的最小值为L,最大值为R,则该数值属性泛化的信息损失量为

(2)分类型属性
对于属性泛化树TQI,其所有叶子结点的个数记为M,对于TQI中的任一结点P,其所有子树的个数记为Mp,则该分类型属性泛化的信息损失量为

2)数据表敏感值的平均识别率[19]
给定一个数据集T和等价类E,T中E的个数为n,s是E中某条记录t的敏感属性值,则T中敏感值的平均识别率ARRT的计算公式为

其中,ARRE表示E中敏感值的平均识别率,其计算公式为
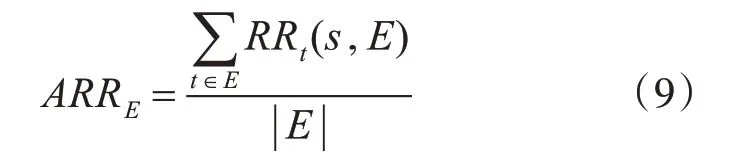
RRt(s,E)表示一条记录的敏感属性值识别率,其计算公式为
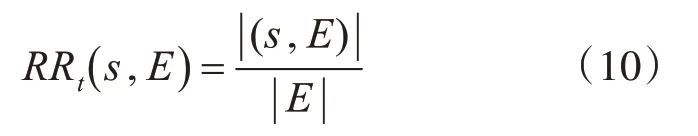
|(s,E)|是等价类E中敏感属性值s的个数,|E|是等价类的大小。
4 实验结果和分析
4.1 实验环境
本文的实验环境为Intel Core i5 8265U 1.8GHz CPU,8GB RAM,Windows 10专业版64位操作系统;实验所用语言为Java,并用Matlab仿真实现。实验数据集:选用UCI的Adult数据集,共有48842条记录,包含14个属性[20],本文将{age,gender,education,race}作为准标识符属性,并增加一列“disease”作为敏感属性,将表4中几种不同等级的“疾病”属性取值随机添加至数据表的每个元组中。此外增加一列“Lev”属性,记录敏感属性值的等级,“disease”与“Lev”的对应关系与表4保持一致。实验重复进行5次,最终取平均值作为分析对比的数据。
4.2 信息损失量比较
由图3知,k值相同时,本文模型较p-sensitive k-匿名模型有更高的信息损失,是因为本文增加了关联度计算来进一步泛化准标识符,但总体上两者的信息损失量相差不多。
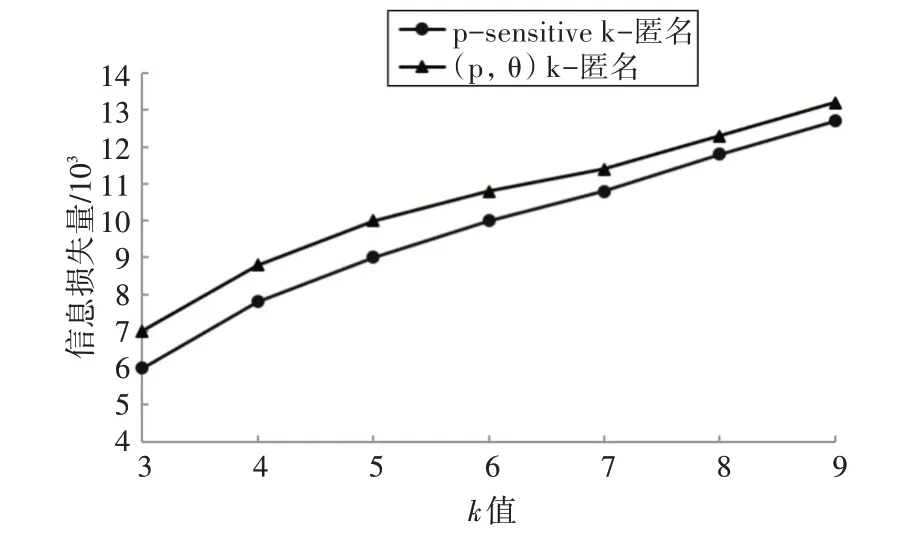
图3 不同k值下信息损失量对比
4.3 敏感值识别率比较
由图4知,k值相同时,本文模型较p-sensitive k-匿名模型有更低的敏感值识别率,即数据发布的安全性更高。这是由于本文模型增加了对敏感属性值的频率约束,同时降低了准标识符与敏感属性间的关联度。
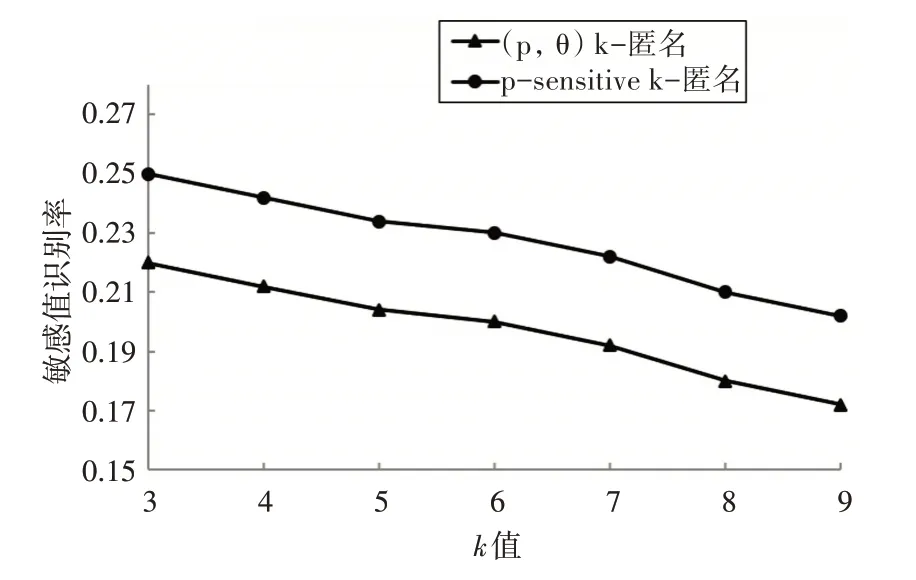
图4 不同k值下敏感值识别率对比
4.4 本文模型的执行时间与θ的关系
由图5知,本文算法的执行时间随θ的增大而减小。因为频率越大,对敏感属性的约束越小,所需执行时间会越少。
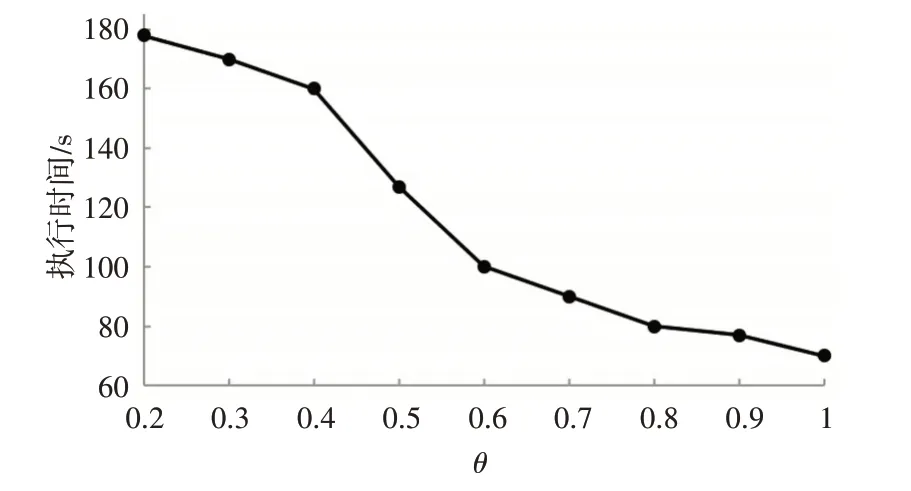
图5 本文模型的执行时间随θ的变化情况
5 结语
本文提出了优化的(p,θ)k-匿名模型,对敏感属性进行等级分类并约束其在等价类中出现的频率,利用互信息量为准标识符的泛化提供依据,从而阻止对等性攻击,有效地减少了个人隐私泄露的概率。实验结果表明,本文的算法虽然损失了部分数据的精度,但获得了更好的数据保密效果,且信息损失仍在可接受范围内。由于本文只考虑了单个敏感属性的情况,因此后续工作将主要对如何抵制多敏感属性的对等性攻击进行研究。
