一种基于随机森林的扶贫识别办法
2021-09-14陆泽凯王雅瑜谢颖
陆泽凯 王雅瑜 谢颖
[摘 要]2020 年是我国全面建成小康社会的决胜年,我国也进入了决战决胜脱贫攻坚的最后阶段。唯有精确的识别贫困人口,才能推进精准扶贫工作更好地开展。文章以西部内陆省份 G 省 A 市农村地区的调研数据为基础,选取了多个指标,通过随机森林算法来精确识别贫困人口。通过研究发现,随机森林算法在甄别贫困人口中效果好,同时拥有较大的灵活性,能较好适应精准扶贫识别工作。
[关键词]精准扶贫;机器学习;随机森林;评价指标
[DOI]10.13939/j.cnki.zgsc.2021.25.022
1 引言
2018年2月12日,习近平总书记在打好精准脱贫攻坚战座谈会上强调,脱贫攻坚,精准是要义。必须坚持“六个精准”,扶贫扶到点上扶到根上。但是,随着扶贫工作难度的提高,一些缺陷日益突出。一些冒领扶贫款,扶贫名额变成干部“获取民心”的工具、扶贫名额分配不均的情况时有发生。以四川省×县为例,每个村只有十几个指标申请贫困户,却经常达到几百号人甚至几乎全村的人都去申请,这种情况下扶贫名额的分配往往由干部的主观意愿决定。这种情况也不仅仅发生在西部地区,在沿海发达省份广东省 S 市也出现了扶贫不精确、不高效的问题。这些问题与扶贫对象的识别不够精确有紧密关系。而文章以我国扶贫的重要攻坚点西部 G 省 A 市某一农村为研究样本,注重研究一种基于随机森林模型的贫困户精准识别评价体系。
2 随机森林模型
随机森林(Random Forest)是一种集成学习方法,常用于分类、回归和其他机器学习任务[1]。它的原理是在训练时构建大量决策树(Decision Tree),随机森林的每一棵决策树之间是没有关联的,当有一个新的样本进入算法的时候,每一棵决策树都会分别进行一下判断,并各自识别这个样本应该属于哪一类别,然后根据某一类别被选择最多,就预测这个样本为哪一类别,随机森林有效地纠正了决策树拟合的问题。[2]
在统计学中,逻辑回归(Logistic Regression)是最常用的分类算法,因为其易解释性,常常是传统社科文章定量分类的工具[3],然而由于一般的逻辑回归有一定的局限性,通常需要通过增加组合项或高斯项来提高其分类性能,然而添加了各类项式后模型的解释力度却也下降了。同时有研究指出,在较小数据中随机森林分类的效果优于逻辑回归模型,研究中重点是放在模型的精确度上而不是其解释性上,因此文章采用了随机森林的算法,以提高模型的分类性能。
3 问卷清洗
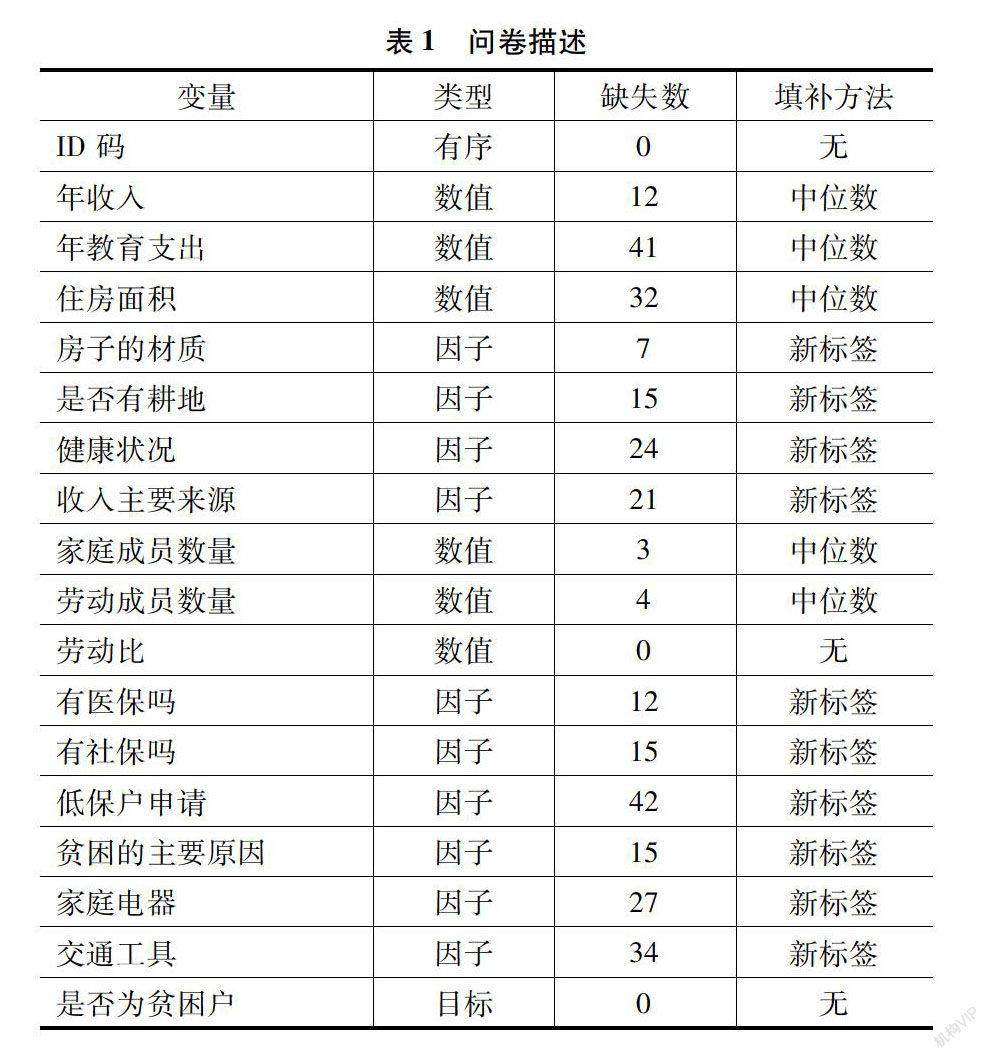
本次调研通过研究人員与 G 省 A 市某农村村委会的沟通,通过该村支部的工作人员分发纸质问卷为主要调查手段,分发了600张问卷,在该村委会的大力支持下共回收问卷 329 份,回收率达到了54%,问卷涵盖了个人情况、家庭情况以及各种社会保险情况共三个方面。
本次问卷调研中是贫困户的对象为 78 人,非贫困户的对象为 251 人,调研中对象的贫困发生率约为 23.7%。由于被调查者问卷填写不规范、对自身信息不确定、不愿公开个人信息等原因,导致问卷中存在一定数量的缺失值,为提高数据的可用性,方便进一步分析问卷数据,本节对问卷问题进行描述并对问卷中的缺失值进行进一步的填补。
由于预测的目标变量——是否为贫困户是村委会提供相应的扶贫数据并没有出现缺失,研究中用的是填补后的家庭成员数量以及劳动成员数量,也不存在缺失值。
研究中对于数值型变量采用了中位数填补法,这是由于扶贫数据的特殊性所致的。扶贫对象和普通人之间往往存在收入、支出等各方面差异悬殊的情况。如果使用平均数填补法容易出现扶贫对象被平均的情况,导致数据失真。而在因子型变量中采用给缺失值贴新标签的方法,则利用了机器学习分类预测的优势,由于目标变量始终是确定的,因此新的标签也可以作为被机器学习使用的特征,比如说在低保户申请上如果不选择回答的人中的目标变量观测值较多的是扶贫对象,他们可能出现难以启齿的现象而选择不回答。那么机器学习也会给这个缺失值标签在扶贫对象的识别上更多的权重。在完成缺失值的填补后就可以利用机器学习算法进行预测了。
4 模型预测效果
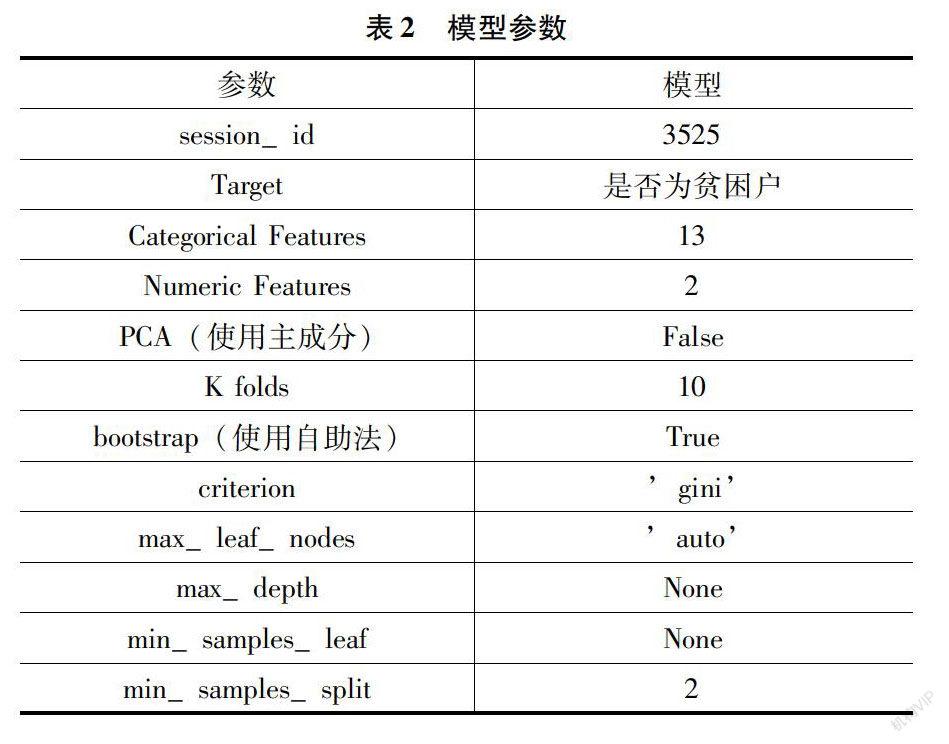
将被调研的人分为两类:第一类是获得精准扶贫补助的贫困户;第二类是未获得精准扶贫补助的非贫困户,通过随机森林算法进行二分类预测。以前面收集到的 G 省 A市所得数据并清理好的数据进行训练,通过随机森林模型预测被调研者是否贫困。数据的自变量是被调研者关于 16 项问卷问题的回答,因变量则为一个是否贫困的标签。算法中会自动将数值型数据进行标准化处理(Standardize),并将因子型变量转换为机器识别的哑变量(Dummy Variable),随机森林的参数如表2所示。
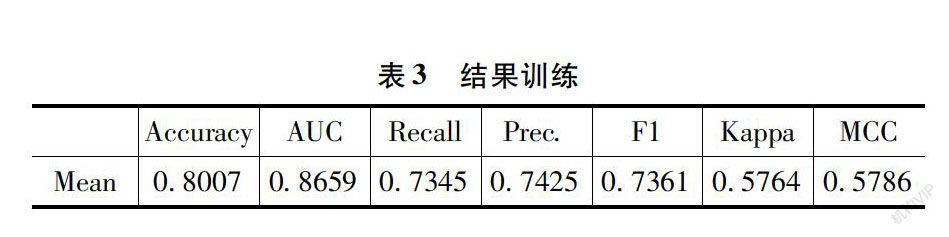
将数据集分为 10 折,其中 9 折作为训练集以建立和优化模型,1 折作为验证集以验证模型在新数据上的表现,并采用自助法训练以克服数据集较小的弱点。根据上面的参数设定随机森林模型训练后得到以下结果,如表3所示。
模型的准确性(Accuracy)达到了 80%,机器学习中最为关注的 ROC 曲线下方的面积大小(AUC)也达到了 86.59%,下图为模型的 ROC 曲线图。其他测量模型适应度的数值也相对比较高。模型的 Kappa值达到了 57.64%,表现出模型一致性较好,模型在各折数据上都表现出较强的鲁棒性(Robust)。综上所述,随机森林模型训练效果较好,能较好识别出贫困人口。之后根据模型给出的结果做出混淆矩阵(Confusion Matrix),如表4所示。可以发现模型在识别错误的两种情况即假阳性和假阴性。假阳性为 52,在模型中表示为错误的将本来不是贫困户的对象给识别为贫困户。假阴性为 14,在模型中表现为将本来是贫困户的识别为非贫困户。现实中,希望的是宁可帮错一个也不能少帮一个。模型还是较好的符合预期,模型后续还可以加入惩罚函数,对假阴性施加惩罚项,以减少识别错误的概率。
